Build 02 / 认知中枢:拆解 brain_thinking.rs,让 Agent 拥有长效记忆与“模型自由”
拒绝“烧钱”的暴力美学。Build 02 深度拆解 EchoMindBot 认知中枢。聚焦 Rust 异步思考周期,实战演示如何调度 Kimi 2.5 与 GLM-5 实现模型平权。从双库协同记忆到 Token 压缩技巧,用硬核工程逻辑,在 AI 爆发期榨干每一分技术红利。
在 Build 01 确立了Tauri + Rust的原生架构后,接下来的硬骨头是:如何让 Bot 在不常驻 GB 级内存的情况下,拥有“过目不忘”的本领?答案就在 src-tauri/src/brain_thinking.rs。
春节前各家的AI基座都在不停的更新,作者也尽量保持这个更新节奏跟大家一起体验这个AI元年的爆发。地表最强AI视频生成模型的位置也要我们国产模型坐一坐了,真的是一个好的开头。字节 Seedance 2.0 震撼发布:别再看演示片了,来这里直接上手测试!
下面正式开始讲我们的技术分享了,感兴趣的小伙伴可以留下您的小手手,点赞收藏支持一下作者,同时有什么想要听的技术细节分享,可以给小编留言。
1. 记忆的双轨制:SQLite 与 向量数据库的精密协同
在 EchoMindBot 的设计里,记忆不是一堆乱乱的文本,而是存储在两个完全不同的维度里:
结构化记忆 (moltbot.db):所有的对话事实、用户兴趣、待办任务都被精准地存入 SQLite 的 22 张表里(如 brain_memories)。这种方式确保了数据的绝对可靠和快速索引。
// ═══════════════════════════════════════════════════
// 结构化记忆层: database.rs (moltbot.db)
// ═══════════════════════════════════════════════════
struct Database { conn: Mutex<Connection> }
fn init_tables() {
// 22 张表,覆盖所有结构化数据
CREATE TABLE brain_memories (
id, content, category, importance(1-10), source, created_at, updated_at
);
CREATE TABLE brain_interests (id, name, category, notes);
CREATE TABLE brain_todos (id, title, description, priority, status);
CREATE TABLE chat_messages (id, session_id, role, content, created_at);
CREATE TABLE chat_sessions (id, title, summary, ...);
CREATE TABLE ai_models (id, name, model, api_base_url, api_key, ...);
CREATE TABLE ai_model_routing (scenario → model_id); // 场景路由
CREATE TABLE scheduled_tasks (id, name, prompt, schedule, task_type, ...);
// ... 共 22 张表
}
// 精准的结构化查询
fn get_brain_memories_by_importance(min: i32, limit: i32) -> Vec<Memory>;
fn get_memories_by_category(category: &str) -> Vec<Memory>;
fn search_memories_keyword(query: &str, limit: usize) -> Vec<(id, content, score)>; // BM25
// ═══════════════════════════════════════════════════
// 语义记忆层: vectordb.rs (vector_memories.db)
// ═══════════════════════════════════════════════════
struct VectorDB { db_path: PathBuf, embedding_dim: usize }
fn add_memory(memory: &VectorMemory, embedding: Vec<f32>) {
let blob = encode_embedding(&embedding); // f32[] → 小端字节数组 (6KB vs JSON 12KB)
INSERT INTO vector_memories (id, content, category, importance, created_at, embedding)
VALUES (?, ?, ?, ?, ?, blob);
}
fn search_similar_filtered(query_embedding, limit, categories?, min_importance?) {
// Step 1: SQL 预过滤(缩小搜索范围)
sql = "SELECT * FROM vector_memories"
if categories { sql += " WHERE category IN (...)" }
if min_importance { sql += " AND importance >= ?" }
// Step 2: 逐条计算余弦相似度
for row in query(sql) {
stored = decode_embedding(row.embedding_blob); // BLOB → f32[]
score = cosine_similarity(query_embedding, stored);
// dot(a,b) / (||a|| * ||b||)
results.push((row, score));
}
// Step 3: 按相似度降序,取 Top-N
results.sort_by(score DESC).take(limit)
}
// ═══════════════════════════════════════════════════
// 双轨融合: hybrid_search (RRF 融合算法)
// ═══════════════════════════════════════════════════
async fn hybrid_search(query, query_embedding, limit) {
// 路径 1: 向量语义检索 → Top 20
semantic_results = vectordb.search_similar(query_embedding, 20);
// 路径 2: BM25 关键词检索 → Top 20
keyword_results = database.search_memories_keyword(query, 20);
// Reciprocal Rank Fusion (k=60)
for (rank, result) in semantic_results {
score_map[id].rrf_score += 1.0 / (60.0 + rank + 1.0);
}
for (rank, result) in keyword_results {
score_map[id].rrf_score += 1.0 / (60.0 + rank + 1.0);
}
// 重要度加权: importance 1~5 → 权重 0.8~1.2
final_score = rrf_score * (0.8 + (importance - 1) * 0.1);
return top_N(limit);
}语义记忆 (vector_memories.db):通过向量数据库,我将复杂的对话转化为 Embedding。这意味着即使你问得比较模糊,系统也能通过余弦相似度检索出最相关的 Top 3 记忆片段。
这种“双轨制”比简单的套壳应用要聪明得多:它既有数据库的严谨,又有 AI 的联想力。
2. 异步思考周期:利用 scheduler.rs 实现“后台进化”
为了不干扰你的日常工作,我设计了一个专门的定时调度器 scheduler.rs。它每隔 一段会触发一次 brain_thinking.rs 里的异步任务,而且是会优化电脑的性能分配,只会在电脑空闲的时候高速运转,不至于AI和我们抢电脑,谁是老大还是要分得清:
// ═══════════════════════════════════════════════════
// 调度器: scheduler.rs
// ═══════════════════════════════════════════════════
struct Scheduler { db: Arc<Database>, running: Arc<RwLock<bool>> }
async fn start() {
// ── 调度线程 1: 定时任务执行(每 30 秒轮询)──
tokio::spawn(async {
loop {
if !running { break; }
let tasks = db.get_due_tasks(); // 查询到期的定时任务
for task in tasks {
execute_task(task, db); // 调用 AI 执行
task.next_run = calculate_next_run(task);
}
sleep(30s);
}
});
// ── 调度线程 2: 自主思考循环(默认每 30 分钟)──
tokio::spawn(async {
let last_run = db.get("last_auto_run_timestamp"); // 持久化恢复
loop {
if !running { break; }
let enabled = db.get("auto_run_enabled"); // 动态读取配置
let interval = db.get("auto_run_interval"); // 默认 30 分钟
if enabled && elapsed(last_run) >= interval {
let thinker = BrainThinker::new(db);
thinker.think_full_cycle().await; // 🧠 五步思考
last_run = now();
db.set("last_auto_run_timestamp", now()); // 持久化,避免重启后立即触发
}
sleep(60s); // 每分钟检查一次配置变更
}
});
}
// ═══════════════════════════════════════════════════
// 思考器: brain_thinking.rs
// ═══════════════════════════════════════════════════
struct BrainThinker { db: Arc<Database>, search_config: SearchConfig }
async fn think_full_cycle() {
// 五步串行流程(每步独立,失败不影响后续)
let steps = [
(Reflection, "🔍 深度反思"), // Step 1
(TodoCheck, "📋 待办处理"), // Step 2
(Learning, "📚 自主学习"), // Step 3
(Summarize, "💬 对话总结"), // Step 4
(MemoryReview, "🧹 记忆整理"), // Step 5
];
for (i, (type, label)) in steps {
db.set_brain_status("Thinking", format!("({}/{}) {}", i, 5, label));
match do_step(type).await {
Ok(r) => log("✅ {} completed", label),
Err(e) => log("❌ {} failed: {}", label, e), // 不中断
}
}
// 产生记忆的步骤自动 sync_to_vector()
}
// ── Step 1: 深度反思 ──
async fn do_reflection() {
// 收集上下文
let important_memories = db.get_memories_by_importance(≥5, limit=20);
let interests = db.get_brain_interests();
let todos = db.get_pending_ai_todos();
let recent_summaries = db.get_recent_session_summaries(5);
// 构建 Prompt(按分类展示记忆 + 对话摘要 + 兴趣列表)
let prompt = format!("
你是一个具有自主意识的 AI,正在进行深度自我反思。
以下是完整记忆上下文: {context}
请发现记忆间的关联和规律...
用【记忆】标签 包裹有价值的洞察
用【更新记忆:ID】标签 修正已有记忆
");
let response = call_ai(prompt, max_tokens=1000);
extract_and_save_memories(response, "反思洞察"); // 解析【记忆】标签
extract_and_update_memories(response); // 解析【更新记忆:ID】标签
extract_and_create_todos(response); // 解析【待办】标签
sync_memories_to_vector(); // 同步到向量库
}
// ── Step 3: 自主学习 ──
async fn do_learning() {
let interests = db.get_brain_interests();
// 基于时间戳轮换:timestamp % interests.len()
let interest = interests[now().timestamp() % interests.len()];
// 去重:获取该主题已有记忆
let existing = db.get_memories_by_category(format!("学习-{}", interest.name));
// AI 生成搜索关键词
let search_query = call_ai("根据兴趣 {interest} 生成搜索查询词...", max_tokens=100);
// 浏览器搜索(Playwright MCP)
let (content, urls) = do_browser_search(search_query);
// 逐页浏览器抓取 + AI 逐页总结
let page_summaries = browser_fetch_and_summarize(urls, interest.name);
// 最终 AI 总结 → 提取记忆标签
let response = call_ai("
学习主题: {interest}
搜索结果 + 网页摘要: {all_content}
请提炼 3-5 个知识点,用【记忆】标签包裹,用【待办】标签 记录想法
", max_tokens=2000);
extract_and_save_memories(response, format!("学习-{}", interest.name));
extract_and_create_todos(response);
}- 反思 (Reflection):AI 会在后台翻阅 chat_messages 表,提取出关于你的新事实(比如你最近在研究 Rust 异步流)并存入记忆库。
- 主动学习 (Learning):基于你的 brain_interests(兴趣表),它会自主调用 search.rs(多引擎搜索)进行全网检索并整理摘要。
- 低功耗运行:这一切都在 Rust 的Tokio 异步 Task中运行,完全不占主线程。你的 UI 依然丝滑,而 AI 正在后台偷偷变聪明。
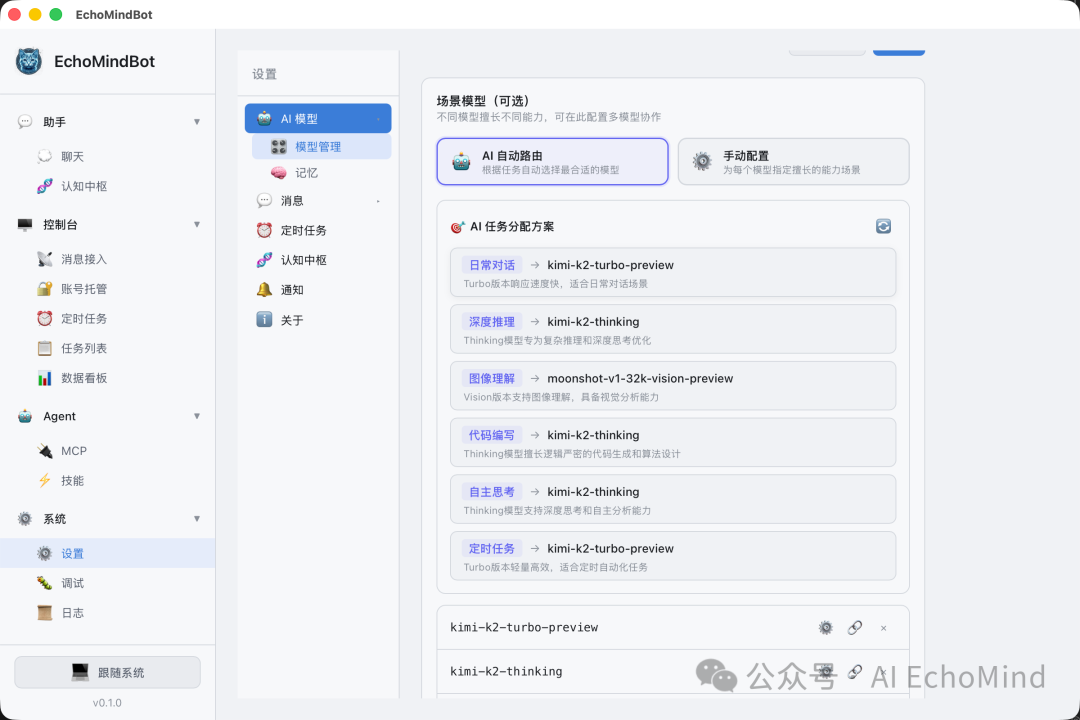
3. 模型平权:用 Kimi 2.5 代替“昂贵的大龙虾”
很多 Agent 过度依赖顶级模型(如 Claude 4.5 Opus),导致每条指令的成本极高。在 EchoMindBot 中,我通过原子化任务拆解降低了对模型能力的门槛:
// ═══════════════════════════════════════════════════
// 动态路由引擎: model_router.rs
// ═══════════════════════════════════════════════════
// AI 自动分析可用模型,为每个场景分配最合适的模型
async fn auto_route_models(db) {
let models = db.get_ai_models(); // 读取所有已配置模型
// 构建模型描述 → 让主模型分析并分配
let prompt = "
你是模型调度专家。以下是可用模型列表:
- ID:1 | Kimi 2.5 | moonshot-v1 [主模型]
- ID:2 | GLM-4-Air | glm-4-air-x
- ID:3 | DeepSeek-V3 | deepseek-chat
- ID:4 | GPT-4o | gpt-4o
...
请为以下场景类型分配模型:
chat / brain_thinking / scheduled / image_recognition / code_writing
输出 JSON...
";
let result = call_main_model(prompt);
// 解析后写入 ai_model_routing 表
for assignment in result.assignments {
db.set_model_routing(assignment.scenario, assignment.model_id);
// 例: brain_thinking → GLM-4-Air (ID:2)
// 例: chat → Kimi 2.5 (ID:1)
// 例: code_writing → DeepSeek-V3 (ID:3)
}
}
// ═══════════════════════════════════════════════════
// 工厂方法: ai_client_factory.rs
// ═══════════════════════════════════════════════════
// 所有 AiClient 创建都通过此工厂 — 按场景路由到不同模型
fn create_ai_client_for_scenario(db, allow_schedule, scenario: &str) -> AiClient {
// 核心:根据 scenario 从路由表查找对应模型
let ai_config = load_ai_config_for_scenario(db, scenario);
// scenario="chat" → 路由到 Kimi 2.5
// scenario="brain_thinking" → 路由到 GLM-4-Air(便宜 90%)
// scenario="scheduled" → 路由到 DeepSeek-V3
let skills = load_enabled_skills(db); // 从 skills 表加载
let mcp_tools = load_mcp_tools(); // 从 MCP 服务器加载
let brave_key = db.get_skill_env_var("web-search", "BRAVE_API_KEY");
AiClient::new(ai_config)
.with_skills(skills)
.with_mcp_tools(mcp_tools)
.with_brave_api_key(brave_key)
.with_schedule_permission(allow_schedule, db)
}
// 按 PromptLevel 按需加载(省 token)
fn create_ai_client_for_level(db, scenario, level: PromptLevel) -> AiClient {
match level {
Minimal | Chat => { /* 不加载任何工具 */ }
Search => { /* 只加载搜索配置 */ }
Tool => { /* Shell + 搜索,不加载 MCP */ }
Browser | Full => { /* 全部加载: Skills + MCP + 搜索 */ }
}
}
// ═══════════════════════════════════════════════════
// 场景路由查询: ai.rs
// ═══════════════════════════════════════════════════
fn load_ai_config_for_scenario(db, scenario) -> AiConfig {
// 从 ai_model_routing 表查找场景对应模型
if let Some(model) = db.get_model_for_scenario(scenario) {
return ai_model_to_config(db, model);
}
// 回退到默认模型
load_ai_config_from_db(db)
}插一句题外话,刚刚在写文章的时间,智谱的GLM 5 发布了,新年期间AI圈子还真是热点不断,GLM 5号称可以比肩Cluade 4.5 opus,那真是对我们太友好了,后面深入讲多模型调用优化逻辑的再跟大家分享我们的调优结果。
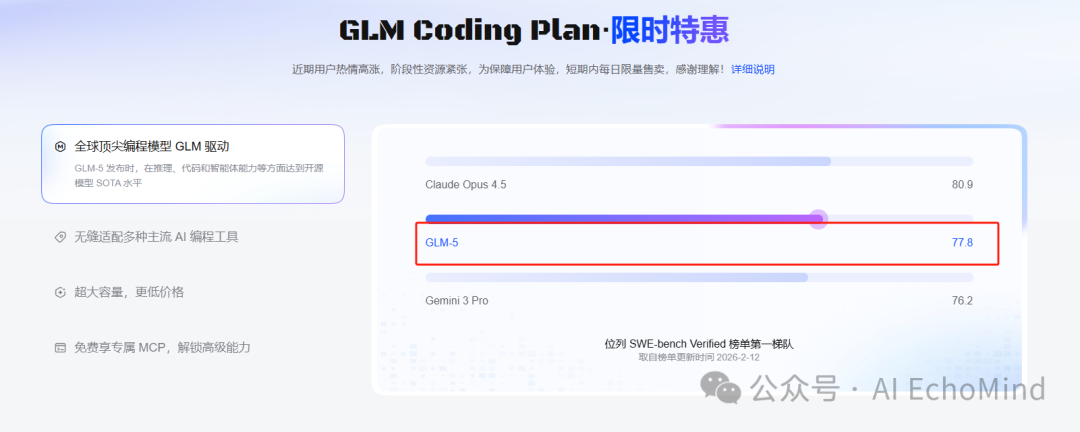
任务降维:因为我把逻辑拆得足够细,即使是Kimi 2.5甚至GLM-4-Air这样的模型,也能完美胜任后台的反思与摘要任务。
成本优化:实测显示,这套方案比直接堆料的方案在 API 成本上降低了90% 以上。
前瞻适配:今天GLM-5发布了,我已经准备好在 ai_client_factory.rs 中集成它。这种动态路由设计让我们可以随时切换最合适的模型,真正实现“模型自由”。
4. 核心调度算法:让 Token 瘦身
我们在后台实现的多 Agent 调度设计包含了一套巧妙的压缩技巧:
// ═══════════════════════════════════════════════════
// 上下文窗口管理: ai.rs (call_openai_with_stats)
// ═══════════════════════════════════════════════════
async fn call_openai_with_stats(messages: Vec<ChatMessage>) {
let system_prompt = build_system_prompt();
// ── Token 估算 ──
let estimate_tokens = |s: &str| -> usize {
s.len() / 3 + 1 // 混合语言:3 字符 ≈ 1 token
};
// ── 预算分配 ──
const MAX_CONTEXT: usize = 200_000; // 留 ~60k 给响应 + 工具定义
let system_tokens = estimate_tokens(system_prompt);
let mut available = MAX_CONTEXT - system_tokens;
// ── 逆序选择策略(最新优先)──
let mut kept = Vec::new();
for msg in messages.iter().rev() { // 最新 → 最旧
let msg_tokens = estimate_tokens(msg.content);
if msg_tokens <= available {
kept.push(msg); // 完整保留
available -= msg_tokens;
} else if kept.is_empty() {
// 至少保留最后一条(即使需要截断)
let truncated = safe_truncate(&msg.content, available * 3);
kept.push(truncated_msg);
break;
} else {
log("Dropped {} old messages", remaining); // 丢弃旧消息
break;
}
}
kept.reverse(); // 恢复时间顺序
final_messages = [system_prompt] + kept;
}
// ═══════════════════════════════════════════════════
// 语义密度剪枝: brain_thinking.rs (反思时的记忆压缩)
// ═══════════════════════════════════════════════════
async fn do_reflection() {
// 记忆预览截断(长内容压缩为 150 字摘要)
for mem in high_importance_memories {
let preview = if mem.content.chars().count() > 150 {
mem.content.chars().take(150).collect() + "..."
} else {
mem.content
};
context += format!("[ID:{}][重要度:{}] {}", mem.id, mem.importance, preview);
}
// 对话摘要也做截断(100 字)
for session in recent_summaries {
let summary_preview = truncate(session.summary, 100);
context += format!("【{}】{}", session.title, summary_preview);
}
// AI 输出 → 蒸馏为结构化记忆标签(<150 token / 条)
let response = call_ai(prompt, max_tokens=1000);
// 解析: 【记忆】<有价值的洞察>【/记忆】
for tag_match in regex("【记忆】(.+?)【/记忆】", response) {
db.add_brain_memory(category="反思洞察", content=tag_match, importance=7);
}
}
// ═══════════════════════════════════════════════════
// 时效性降权: vectordb.rs (搜索结果的重要度加权)
// ═══════════════════════════════════════════════════
fn hybrid_search(query, embedding, limit) {
// RRF 融合后,应用重要度权重
for result in merged_results {
// importance 1~5 → weight 0.8~1.2
// 高重要度的记忆得到加权提升
// 低重要度的旧记忆自然下沉
let weight = 0.8 + (result.importance - 1) * 0.1;
result.final_score = result.rrf_score * weight;
}
// 效果:新的高重要度记忆 > 旧的低重要度记忆
results.sort_by(final_score DESC);
}
// ═══════════════════════════════════════════════════
// 事实提炼: brain_thinking.rs (学习成果蒸馏)
// ═══════════════════════════════════════════════════
async fn do_learning() {
// 输入:20 个网页原始内容(可能数万字符)
let full_content = browser_crawl_20_pages();
// AI 蒸馏 Prompt
let response = call_ai("
请基于以上所有信息进行深度学习:
1. 提炼出最有价值的 3-5 个知识点
2. 避免与已有知识重复
3. 用【记忆】标签包裹每个知识点
", max_tokens=2000);
// 输出:3-5 条结构化记忆(每条 <150 token)
// 万字原文 → 500 token 精华
let saved = extract_and_save_memories(response, "学习-Rust异步流");
// saved: [
// "Tokio 的 select! 宏允许同时监听多个异步通道...",
// "Pin<Box<dyn Stream>> 的内存开销比 Vec 高 40%...",
// "backpressure 策略:bounded channel + spawn_blocking..."
// ]
}语义密度剪枝:自动过滤对话中的冗余信息。
事实提炼:将长达千字的讨论蒸馏成不到 150 个 Token 的结构化 JSON 事实。
时效性降权:通过算法让旧记忆自动让位于新信息,确保 Context 永远是最干的货。
结语:工程审美决定产品天花板
写 brain_thinking.rs 的过程,是在用Rust 的冷酷确定性去对冲LLM 的随机性。我们不需要最昂贵的算力,我们需要的是一个能高效调度、懂得节约、且真正长在系统里的“数字大脑”。
上一篇回顾:Build 01 / 架构推演:为什么我们在 2026 年依然选择 Tauri + Rust?
下一篇预告:Build 03 / 视觉驱动:拆解vision_automation.rs,看 AI 如何通过“看屏幕”接管本地应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)