【大模型学习推理】 profile 学习
SGLang 服务器接收到一个请求,并将其与其他请求批处理后,在一个采用张量并行的多 GPU 环境中,执行 Qwen3-MoE 模型的一个 Transformer 层的计算。关键步骤是:调度与分发:SGLang 调度器将请求交给一个 Tensor Parallelism Worker。进入模型层:代码执行进入 Qwen3-MoE 模型的一个 Decoder Layer。MoE 路由与通信。
https://ui.perfetto.dev
W S D A 四个健。
当然,我非常了解这个过程。
这张图是使用性能分析工具(如 PyTorch Profiler)生成的火焰图(Flame Graph),它详细展示了 SGLang 在执行一个深度学习模型推理请求时的函数调用栈和各部分耗时。
这张图揭示了 SGLang 内部一个非常具体且高度优化的工作流程。让我为你一步步解析这个过程,从上到下,从宏观到微观:
总体解读
这张图捕捉的是 SGLang 服务器在处理一个推理请求的瞬间,特别是模型前向传播(forward pass)的部分。整个流程从 Python 的多进程管理开始,经过 SGLang 的请求调度,最终深入到具体的模型计算和底层的 CUDA 内核调用。
核心模型: 从调用栈中的 qwen3_moe.py 和 Qwen3MoeModel_0 可以明确看出,当前运行的是一个 Qwen3 的 MoE (Mixture of Experts) 模型。这是理解后续通信和计算流程的关键。
下面是详细的分解:
1. SGLang 服务器与调度层 (最上层)
multiprocessing/process.py: 表明 SGLang 服务器是作为一个独立的进程运行的,由 Python 的multiprocessing模块启动和管理。sglang/srt/managers/scheduler.py: 这是 SGLang 的核心——请求调度器。它的run_scheduler_process和event_loop_overlap函数负责接收用户请求,将它们智能地批处理(batching),然后分发给模型执行。run_batch: 明确表示调度器正在处理一个批次的请求。sglang/srt/managers/tp_worker.py:tp_worker指的是 Tensor Parallelism (张量并行) Worker。这说明模型被切分到多个 GPU 上运行。这个 worker 负责处理分配给它的那一部分计算任务。
小结: 一个请求进入了 SGLang 服务器,被调度器放入一个批次,然后交给了负责其中一个 GPU 的张量并行工作进程。
2. 模型执行与模型架构层 (中间层)
sglang/srt/model_executor/model_runner.py: 这是模型执行器,它接收到批处理任务后,调用 PyTorch 模型的forward方法。sglang/srt/models/qwen3_moe.py: forward: 调用进入了特定于 Qwen3 MoE 模型 的forward实现。nn.Module: Qwen3MoeModel_0: Profiler 追踪到了Qwen3MoeModel这个 PyTorch 模块的实例。nn.Module: Qwen3MoeDecoderLayer_0: 进一步深入到模型的一个解码器层(Decoder Layer)。大语言模型就是由很多这样的层堆叠而成的。
小结: 执行流程已经进入了模型内部,正在计算一个 Transformer 解码器层。
3. MoE 模型特有的通信与计算层 (关键细节)
这是这张图最核心、最能体现 SGLang 优化的部分,专门针对 MoE 架构:
sglang/srt/models/qwen3_moe.py(752): forward: 这很可能是在 MoE 层的 MLP (前馈网络) 部分。在 MoE 中,每个 Token 不会经过所有的 MLP “专家”(Experts),而是被一个门控网络(Gating Network)路由到少数几个专家。sglang/srt/layers/communicator.py: 通信器层!这是 MoE 和张量并行的关键。prepare_mlp: 准备 MLP 计算。在 MoE 中,这可能包括计算门控值,确定每个 Token 要发往哪个专家。_gather_hidden_states_and_residual: 这个函数名暗示了需要进行通信。因为不同的专家可能位于不同的 GPU 上,所以需要将发往特定专家的 Token 的隐状态(hidden_states)从各个 GPU 收集(Gather) 起来。
4. 高度优化的底层融合操作 (最底层)
sglang/srt/layers/layernorm.py: forward_with_allreduce_fusion: 这个函数名信息量巨大。它表明 SGLang 将 LayerNorm 计算与一个 All-Reduce 通信操作进行了融合(Fusion)。All-Reduce 是分布式计算中常用的操作,用于在所有并行的进程(GPU)之间聚合数据(例如,对梯度或激活值求和/平均)。将计算和通信融合成一个 CUDA Kernel 可以极大地减少 GPU 和 CPU 之间的交互开销,提升性能。<built-in method flashinfer_allreduce_residual_rmsnorm ...>: 这是真正的性能优化点。SGLang 调用了一个底层的、用 C++/CUDA 编写的融合内核 (Fused Kernel)。这个内核一次性完成了:- flashinfer: 利用了 FlashInfer 库(一个高性能的推理库)。
- allreduce: 分布式通信。
- residual: 残差连接。
- rmsnorm: RMS Normalization(一种 LayerNorm 的变体)。
flashinfer/comm/trtllm_ar.py: 从路径可以看出,这个通信融合功能可能借鉴或使用了来自 NVIDIA TensorRT-LLM 的 All-Reduce (ar) 实现,这代表了业界顶级的性能。cudaLaunchKernelExC: 这是最终的 CPU 调用,它向 GPU 发射(Launch)一个计算内核。这个条的长度通常代表了 GPU 执行该内核所花费的时间,是整个流程中主要的计算瓶颈。
总结与核心过程
一言以蔽之,这个过程描绘了:
SGLang 服务器接收到一个请求,并将其与其他请求批处理后,在一个采用张量并行的多 GPU 环境中,执行 Qwen3-MoE 模型的一个 Transformer 层的计算。
关键步骤是:
- 调度与分发:SGLang 调度器将请求交给一个 Tensor Parallelism Worker。
- 进入模型层:代码执行进入 Qwen3-MoE 模型的一个 Decoder Layer。
- MoE 路由与通信:在 MoE 的 MLP 部分,SGLang 的通信层准备将 Token 的隐状态(hidden states)发送到不同 GPU 上的“专家”那里。
- 执行融合内核:SGLang 没有分步执行 LayerNorm、残差连接和 All-Reduce 通信,而是调用了一个名为
flashinfer_allreduce_residual_rmsnorm的、高度优化的融合 CUDA 内核。这个内核(可能利用了 TensorRT-LLM 的技术)一次性在 GPU 上完成了所有这些操作。 - GPU 计算:
cudaLaunchKernelExC是将这个繁重的计算任务真正交给 GPU 的最后一步。
这张图完美地展示了 SGLang 不仅仅是一个简单的模型包装,而是一个深度优化的推理引擎,它能够针对复杂的模型架构(如 MoE)和分布式环境(如张量并行)进行底层的算子融合和通信优化,从而达到极高的性能。
学习flashinfer_allreduce_residual_rmsnorm
Google 搜到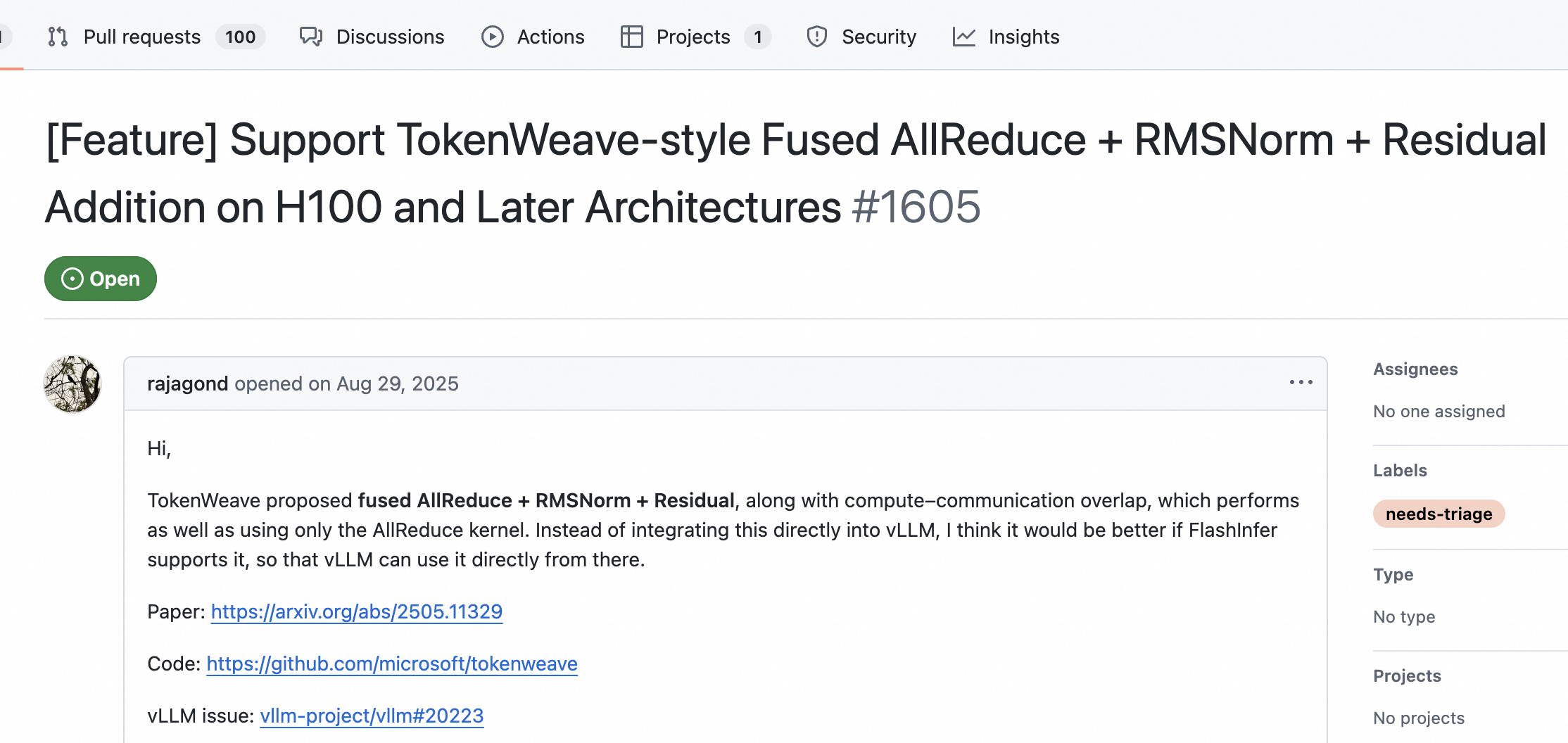
学习tokenweave
https://github.com/flashinfer-ai/flashinfer/issues/1605
https://github.com/microsoft/tokenweave/tree/main

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)