向量数据库及与Agent的关系
简单来说,向量数据库是一种专门用来存储、索引和查询“向量”的数据库。1. 什么是向量?在AI领域,向量是高维空间中的一组数字(坐标)。我们可以将任何非结构化的数据(如文本、图像、音频)通过“嵌入模型”转化为这种数字列表。“猫”这个词可能被转化成这样一个几百维的向量。这个向量的核心价值在于语义表示。在向量空间里,含义相近的词(如“猫”和“宠物”)在空间中的距离会非常接近;含义无关的词(如“猫”和“宪
第一部分:什么是向量数据库?
简单来说,向量数据库是一种专门用来存储、索引和查询“向量”的数据库。
要理解它,需要拆解三个关键点:
1. 什么是向量?
在AI领域,向量是高维空间中的一组数字(坐标)。我们可以将任何非结构化的数据(如文本、图像、音频)通过“嵌入模型”转化为这种数字列表。
-
例子: “猫”这个词可能被转化成
[0.2, -0.4, 0.7, ..., 0.1]这样一个几百维的向量。 -
意义: 这个向量的核心价值在于语义表示。在向量空间里,含义相近的词(如“猫”和“宠物”)在空间中的距离会非常接近;含义无关的词(如“猫”和“宪法”)则会相隔很远。
2. 它和传统数据库有什么不同?
-
传统数据库(SQL等): 擅长精确匹配。例如:“查询年龄等于25岁的用户”。如果关键词拼错一个字,或者问“青少年”,就查不到了。
-
向量数据库: 擅长相似性搜索(近似搜索)。例如:“查询和‘可爱的毛茸茸动物’这句话意思最相近的10张图片”。它不关心关键词,只关心语义。
3. 它的核心工作原理?
向量数据库建立了一种特殊的索引结构(如HNSW,即分层可导航小世界图),这种结构使得在海量(十亿级)向量中快速找到“最近邻居”变得极其高效。它不像传统数据库那样一行行扫描,而是通过计算向量间的距离(余弦相似度、欧氏距离等)来检索。
第二部分:什么是Agent?
Agent(智能体)可以理解为一个能独立思考、并能使用工具来完成复杂目标的程序。
它不仅仅是生成文字的大模型,还具备一个关键的循环:感知 -> 规划 -> 行动。
-
感知: 接收用户的指令或环境的变化。
-
规划: 大模型作为“大脑”,将大目标拆解成小步骤。例如,用户说“帮我策划周末去海边的行程”,Agent会拆解为:查天气、查酒店、规划路线、生成行李清单。
-
行动: 调用外部工具来执行步骤。例如,调用天气API、调用订票API、甚至调用代码解释器写一段绘图代码。
第三部分:向量数据库与Agent的关系
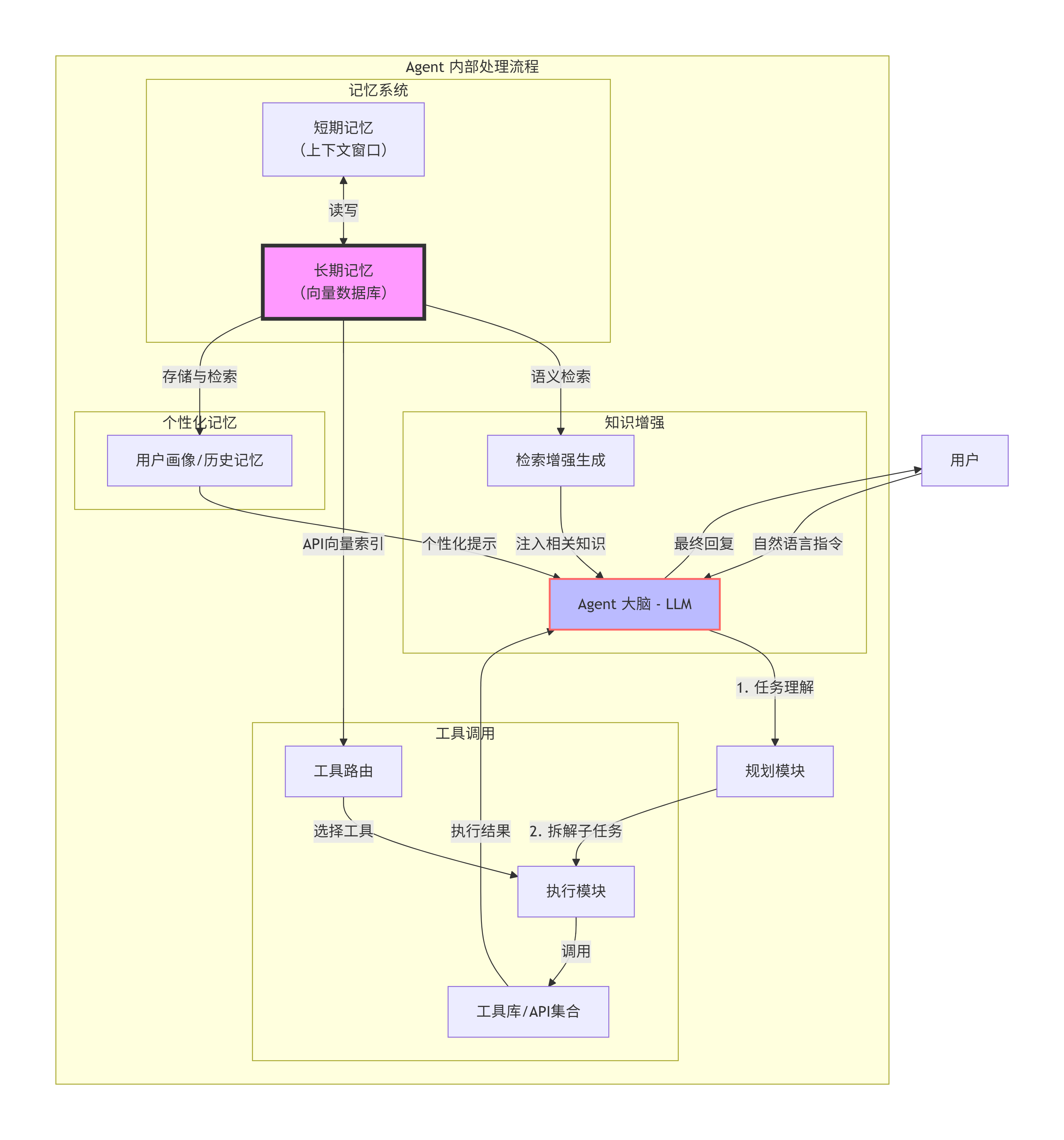
作用1:知识记忆与检索增强(RAG)—— 外挂大脑
-
痛点:大模型训练数据有截止日期,且无法包含企业私有文档。
-
图谱位置:
LTM→RAG→Agent -
机制:Agent收到问题后,先将问题向量化,从向量数据库中检索最相似的知识片段(如产品手册、法律条文、历史报告),将这些片段拼接到提示词中,让模型基于最新/私有信息回答。
-
效果:解决幻觉问题,使Agent具备领域专家能力。
作用2:工具选择与API路由 —— 技能索引
-
痛点:当Agent可调用的工具成百上千时,无法将全部工具描述塞入上下文。
-
图谱位置:
LTM→ToolRouter→Executor -
机制:将所有工具的功能描述(如API文档)转化为向量存入数据库。用户请求到来时,Agent将意图向量化,检索出最匹配的少数几个工具,再精确调用。
-
效果:使Agent能动态扩展工具集,即插即用,无需重新训练。
作用3:长期记忆与个性化 —— 用户记忆体
-
痛点:大模型每次对话都是独立的,记不住用户偏好、历史行为。
-
图谱位置:
LTM↔Profile→Agent -
机制:每次交互后将关键信息(如用户兴趣、禁忌、历史决策)向量化存入数据库。下次同一用户出现时,Agent自动检索该用户画像,调整回复风格和推荐策略。
-
效果:实现千人千面的持续对话体验,Agent拥有“记性”。
作用4:任务规划与推理辅助 —— 案例联想
-
痛点:复杂任务的规划依赖过往成功经验。
-
图谱位置:
LTM↔Planner -
机制:存储历史成功解决的任务轨迹(如“如何预订跨国行程”的完整步骤链)。新任务到达时,Planner检索相似案例,参考或复用已有方案,避免从零推理。
-
效果:提升规划效率,使Agent具备经验学习能力。
第四部分:传统数据库 vs. 向量数据库——角色分界
为了更清晰地理解为什么必须是“向量”数据库,我们对比一下Agent系统中两类数据库的分工:
| 维度 | 传统数据库(SQL/NoSQL) | 向量数据库 |
|---|---|---|
| 存储对象 | 结构化数据(订单、用户信息、配置) | 非结构化语义(文档、图片、对话历史) |
| 查询方式 | 精确匹配、关键词、范围查询 | 语义相似度、模糊搜索 |
| 在Agent中的作用 | 事务记录:记录谁买了什么、日志存储 | 认知记忆:理解含义、联想、类比 |
| 典型交互 | “查询用户ID=10086的余额” | “找一段和当前问题意思最接近的对话” |
总结:传统数据库负责Agent的业务数据,向量数据库负责Agent的认知数据——二者共同构成Agent完整的存储体系。
第五部分:向量数据库如何从根本上改变Agent能力
我们可以从记忆类型的角度来理解这一跃迁:
-
无记忆:仅靠提示词 → 单次对话,用完即焚。
-
有短期记忆:靠上下文窗口 → 可多轮对话,但窗口有限,且无法跨会话。
-
有长期记忆:靠向量数据库 → 海量、持久、语义可检索,这是自主智能体与聊天机器人的分水岭。
向量数据库将Agent从“应试者”变成了“研究者”:
-
应试者:只能凭大脑死记硬背(训练参数)。
-
研究者:遇到问题立刻查阅文献(向量检索),然后综合输出。
第六部分:未来演进——向量数据库即Agent的操作系统
随着Agent应用普及,向量数据库正在从“附属组件”向“核心基础设施”演进:
-
记忆即服务:Agent之间的记忆可以共享、继承。
-
反思与迭代:Agent定期总结长期记忆中的高频问题,自我微调。
-
多模态记忆:同时存储文本、图像、音频向量,实现跨模态联想。
结语
-
如果把Agent比作一个正在成长的数字生命,那么:
-
大模型是大脑皮层,负责实时思考;
-
向量数据库是海马体,负责将经验转化为长期记忆;没有向量数据库的Agent,是转瞬即逝的流星;拥有向量数据库的Agent,才能成为持续进化的智慧体。
-
传统数据库是记事本,负责记录事实清单。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)