向量数据库在AI中的应用
向量数据库是一种专门设计用于存储和检索向量数据(高维数值数组)的数据库系统。与传统的关系型数据库不同,它针对高维向量数据的特性进行了优化,能够高效处理数十万甚至数百万维度的数据。例如,一段"关于人工智能的论文摘要"可能被转换为768维的向量,其中每个维度都编码了特定的语义特征。
向量数据库在AI中的应用
概念与原理
向量数据库是一种专门设计用于存储和检索向量数据(高维数值数组)的数据库系统。与传统的关系型数据库不同,它针对高维向量数据的特性进行了优化,能够高效处理数十万甚至数百万维度的数据。其核心工作原理是:
- 将非结构化数据(如文本、图像、音频)通过深度学习模型转换为向量表示(即嵌入向量)
- 使用专门的索引结构和算法存储这些向量
- 利用相似度搜索技术来快速查找相似项
例如,一段"关于人工智能的论文摘要"可能被转换为768维的向量,其中每个维度都编码了特定的语义特征。
核心技术
嵌入模型
- 文本嵌入:BERT、RoBERTa、Sentence-BERT等模型,可将句子/段落转换为向量
- 图像嵌入:ResNet、VGG、CLIP等模型,提取视觉特征向量
- 多模态嵌入:如OpenAI的CLIP模型可同时处理文本和图像
索引结构
- 近似最近邻(ANN)算法:平衡精度与效率
- IVF(反向文件索引):先聚类再搜索
- Annoy(近似最近邻库):基于树的索引
- 局部敏感哈希(LSH):通过哈希函数将相似项映射到相同桶中
- 分层可导航小世界(HNSW):基于图的算法,支持高效层级搜索
- 乘积量化(PQ):将高维空间分解为低维子空间的笛卡尔积
距离度量
- 余弦相似度:衡量向量方向相似性,适合文本
- 欧氏距离:计算向量间的直线距离,适合空间数据
- 内积:考虑向量大小和方向,常用于推荐系统
- Jaccard相似度:适用于稀疏向量
主要应用场景
1. 语义搜索与推荐系统
电商平台应用示例:
- 将商品描述、用户浏览历史转换为向量
- 实时计算用户偏好向量与商品向量的相似度
- 返回最相似的Top K商品作为推荐
内容平台实现细节:
- 使用BERT模型将文章标题和内容编码为向量
- 建立向量索引
- 用户搜索时,将查询语句同样编码为向量
- 执行向量相似度搜索返回相关文章
案例:Spotify音乐推荐
- 将每首歌曲的特征(节奏、音调、风格等)编码为向量
- 用户收听历史形成用户偏好向量
- 通过向量相似度发现潜在喜欢的歌曲
- 每日为4亿用户生成超过10亿次推荐
2. 多模态检索
医疗影像检索实现流程:
- 医生输入文本描述:"左肺上叶3cm磨玻璃结节"
- 文本编码为向量
- 在包含数百万医学影像向量的数据库中搜索
- 返回相似病例的CT图像及诊断报告
时尚搜索技术细节:
- 使用多模态模型(如CLIP)同时处理图像和文本
- 支持"上传图片+文字描述"的混合查询
- 可搜索:"与这张外套图片相似,但长度到膝盖的款式"
3. 大语言模型增强
知识检索增强LLM的完整流程:
# 伪代码示例
def augmented_generation(user_question):
# 将用户问题编码为向量
query_vector = embed(user_question)
# 在向量数据库中搜索最相关的3个文档
relevant_docs = vector_db.search(
query_vector,
top_k=3,
distance_threshold=0.7
)
# 构建增强提示
augmented_prompt = f"参考信息:\n{relevant_docs}\n\n问题:{user_question}"
# 生成最终回答
response = llm.generate(augmented_prompt)
return response
实际应用优势:
- 减少LLM的幻觉回答达40-60%
- 知识更新只需更新向量数据库,无需重新训练模型
- 支持引用来源,提高回答可信度
4. 异常检测与安全
网络安全应用:
- 将网络流量行为特征编码为向量
- 建立正常行为向量基准
- 实时检测偏离基准的异常向量
- 可发现新型攻击模式,误报率低于传统规则系统
工业检测案例:
- 汽车零部件生产线拍摄每个产品图像
- 提取图像特征向量
- 与合格品向量库比对
- 可识别微小缺陷,准确率达99.2%
性能优化技术
1. 混合检索策略
分阶段检索流程:
1. 粗召回阶段:
- 使用HNSW快速检索
- 返回Top 1000候选
2. 精确重排序:
- 对Top 1000进行精确距离计算
- 使用GPU加速运算
- 返回最终Top 10结果
3. 结果融合:
- 结合语义相似度和其他业务指标
- 生成最终排序列表
2. 量化压缩
PQ量化示例:
- 原始向量:1024维float32(4KB)
- 分割为8个子向量(每个128维)
- 对每个子空间进行k-means聚类(如256个中心点)
- 存储时只需8个uint8索引(8B)
- 压缩比达500:1,精度损失<5%
3. 硬件加速
GPU优化技术:
- 批量处理查询(100-1000个查询同时执行)
- 使用Tensor Core加速矩阵运算
- 优化内存访问模式
- 典型加速效果:比CPU快50-100倍
主流产品对比
| 产品名称 | 开发公司 | 核心特点 | 典型应用场景 |
|---|---|---|---|
| Pinecone | Pinecone | 全托管服务,简单API,支持命名空间隔离 | 推荐系统、语义搜索、初创企业快速部署 |
| Milvus | Zilliz | 开源可扩展,插件丰富,支持分布式部署 | 多模态检索、大规模AI应用、企业自建方案 |
| Weaviate | Weaviate | 内置ML模型,图数据库能力,支持混合搜索 | 知识图谱、企业搜索、复杂关系查询 |
| Qdrant | Qdrant | Rust编写,高性能,内存优化出色 | 实时推荐、广告投放、低延迟场景 |
实施挑战与解决方案
挑战1:维度灾难
具体表现:
- 数据稀疏性:在1000维空间中,数据点极其分散
- 距离失效:所有点对距离趋于相同
- 计算复杂度:索引构建时间呈指数增长
解决方案:
-
降维技术:
- PCA(主成分分析)保留95%方差
- UMAP/t-SNE非线性降维
- 自动编码器学习紧凑表示
-
分层处理:
- 先降维到128维进行粗筛选
- 对候选集使用原始维度精排
-
算法优化:
- 使用HNSW等对高维友好的算法
- 采用近似计算容忍一定误差
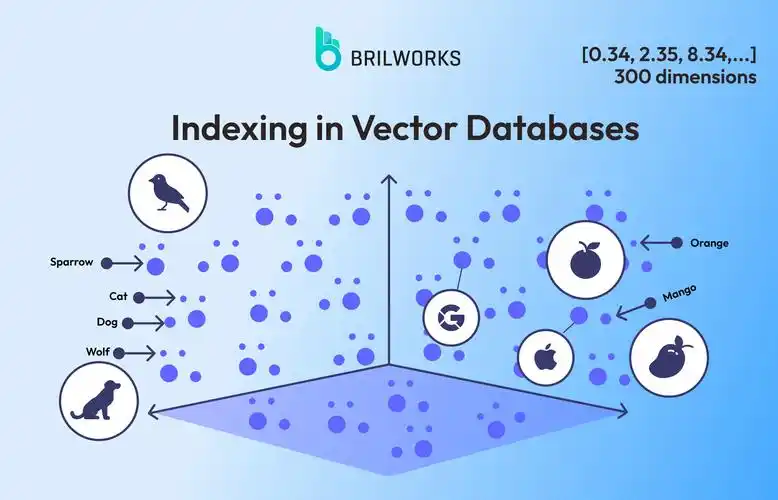
关于相似度的算法
相似度算法是数据挖掘、信息检索和机器学习等领域的重要基础技术,主要用于衡量两个对象之间的相似程度。根据应用场景和数据类型的差异,存在多种不同的相似度计算方法:
-
欧氏距离(Euclidean Distance) 最常用的距离度量方法,适用于连续数值型数据。计算公式为: d(x,y) = √(Σ(xi-yi)²) 示例:在二维空间中计算两点(1,3)和(4,7)的欧氏距离: √[(1-4)²+(3-7)²] = 5
-
余弦相似度(Cosine Similarity) 常用于文本相似度计算,衡量两个向量间的夹角余弦值: cosθ = (A·B)/(||A||·||B||) 应用场景:文档相似性比较、推荐系统等
-
Jaccard相似系数 适用于集合数据,计算交集与并集的比例: J(A,B) = |A∩B|/|A∪B| 示例:比较用户A和B的购买商品集合
-
编辑距离(Edit Distance) 用于字符串相似度计算,衡量将一个字符串转换成另一个字符串所需的最少编辑操作次数 应用场景:拼写检查、DNA序列比对等
-
皮尔逊相关系数(Pearson Correlation) 衡量两个变量之间的线性相关性,取值范围[-1,1] 计算公式:cov(X,Y)/(σX·σY)
-
曼哈顿距离(Manhattan Distance) 也称为城市街区距离,计算各维度绝对差之和: d(x,y) = Σ|xi-yi| 适用于高维数据计算
在实际应用中,选择哪种相似度算法需要考虑:
- 数据类型(数值型、分类型、文本等)
- 数据维度
- 计算效率要求
- 对异常值的敏感度
- 具体业务需求
例如在电商推荐系统中,可能同时使用余弦相似度计算用户偏好相似度,用Jaccard系数计算用户购买行为相似度,最后进行加权融合。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)