从零开始:打造支持多工具调用的MCP Chat Agent,附完整代码教程
随着大模型能力的提升,单纯的对话已经无法满足实际工程需求。越来越多的场景需要模型具备调用外部工具、访问系统能力、执行复杂任务的能力。提供了一种统一、标准化的方式,让模型可以通过协议调用外部工具;LangGraph则用于构建可控、可追踪的 Agent 推理流程;Chainlit提供了一个轻量但功能完整的 Web Chat UI,非常适合 Agent 场景。支持 MCP 多工具调用支持 Ollama
本文详细介绍如何搭建完整的MCP Chat Agent系统,支持多工具调用、Ollama/OpenAI双模型后端、流式输出、Web UI和多轮对话状态持久化。通过LangGraph实现Agent流程控制,MCP管理工具协议,Chainlit提供轻量级Web界面,帮助开发者快速构建具备工具调用能力的智能Agent系统。
前言
随着大模型能力的提升,单纯的对话已经无法满足实际工程需求。越来越多的场景需要模型具备 调用外部工具、访问系统能力、执行复杂任务 的能力。
MCP(Model Context Protocol) 提供了一种统一、标准化的方式,让模型可以通过协议调用外部工具; LangGraph 则用于构建可控、可追踪的 Agent 推理流程; Chainlit 提供了一个轻量但功能完整的 Web Chat UI,非常适合 Agent 场景。
本文将介绍如何从零搭建一个:
- 支持 MCP 多工具调用
- 支持 Ollama / OpenAI 两种模型后端
- 支持流式输出
- 支持 Web UI(Chainlit)
- 支持多轮对话与状态持久化
的完整 MCP Chat Agent。
效果图

一、整体架构说明
系统整体架构如下:
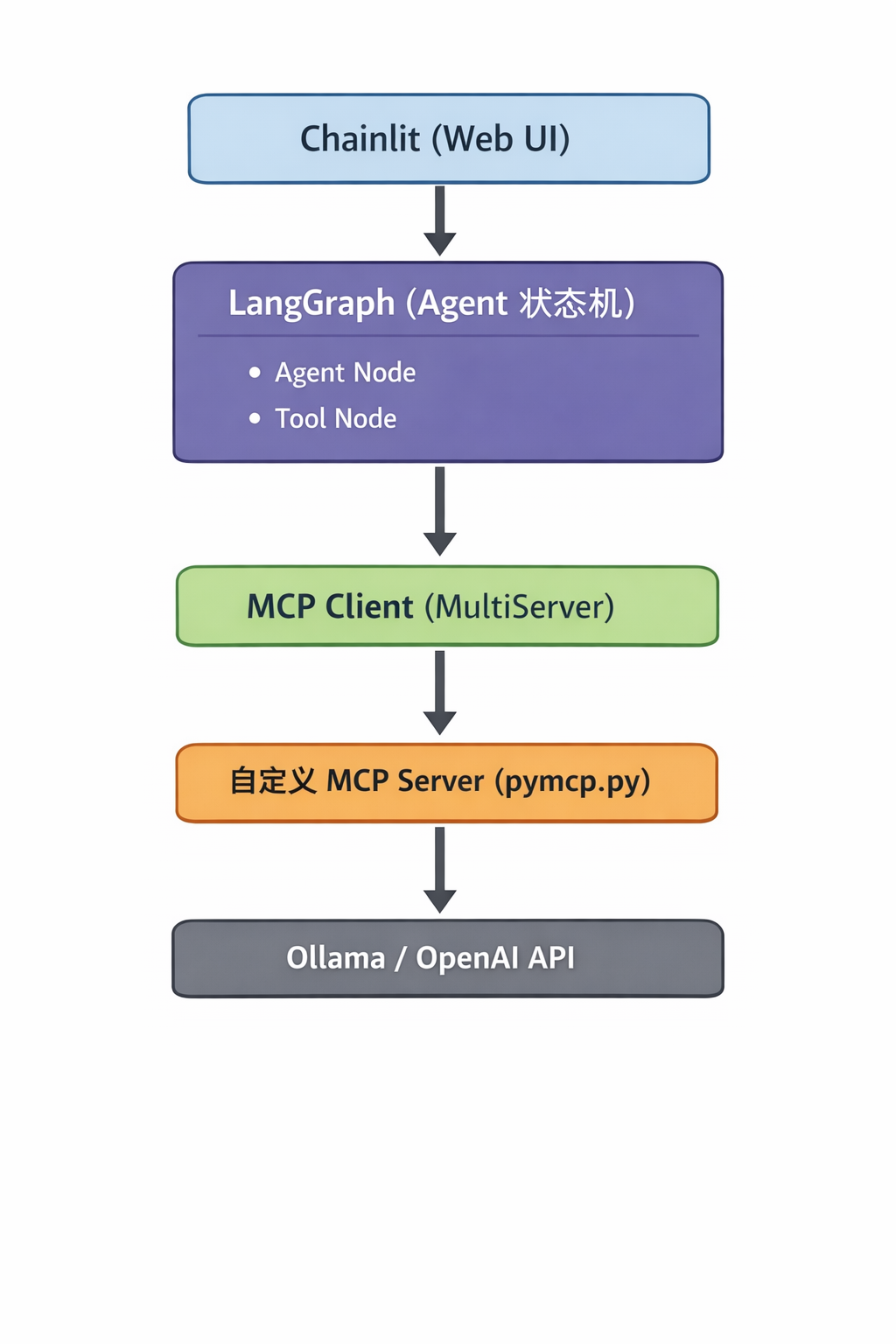
Chainlit 负责 UI 与用户交互; LangGraph 负责 Agent 的执行流程与工具调度; MCP 负责工具协议与进程管理; Ollama / OpenAI 提供模型推理能力。
二、环境准备
1. 安装 Ollama 并拉取模型
ollama pull qwen2.5:7b
确认模型已加载:
ollama list
2. 安装 Python 依赖
pip install \
chainlit \
langchain-ollama \
langchain-openai \
langgraph \
langchain-mcp-adapters
三、MCP 配置说明(mcp.json)
示例 mcp.json:
{
"mcpServers":{
"my_tools":{
"command":"/usr/bin/python3",
"args":[
"/home/user/langchain-mcp-demo/pymcp.py"
]
}
}
}
说明:
- MCP Server 通过
stdio启动 - LangChain 会自动拉起、管理子进程
- 不需要手动启动 MCP Server
四、核心 Agent 实现(LangGraph + MCP)
1. Agent State 定义
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
classState(TypedDict):
messages: Annotated[list, add_messages]
该 State 用于在 LangGraph 中维护对话消息历史。
2. MCP Agent 实现
import asyncio
import json
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.graph import StateGraph, START
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
classMCPAgent:
def__init__(self, backend: str = "ollama"):
if backend == "ollama":
self.llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.7,
streaming=True,
)
else:
self.llm = ChatOpenAI(
model="qwen3-30b-a3b-instruct-2507",
temperature=0.7,
api_key="sk-xxxxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
streaming=True,
)
withopen("mcp.json", "r", encoding="utf-8") as f:
cfg = json.load(f)
client = MultiServerMCPClient({
name: {
"transport": "stdio",
"command": s["command"],
"args": s["args"]
}
for name, s in cfg["mcpServers"].items()
})
self.tools = asyncio.run(client.get_tools())
self.llm = self.llm.bind_tools(self.tools)
self.graph = self._build_graph()
def_agent(self, state: State):
return {"messages": [self.llm.invoke(state["messages"])]}
def_build_graph(self):
g = StateGraph(State)
g.add_node("agent", self._agent)
g.add_node("tools", ToolNode(self.tools))
g.add_edge(START, "agent")
g.add_conditional_edges("agent", tools_condition)
g.add_edge("tools", "agent")
return g.compile(checkpointer=MemorySaver())
说明:
- MCP 工具通过
bind_tools注入模型 - LangGraph 使用
tools_condition自动判断是否调用工具 - MemorySaver 用于多轮对话状态保存
五、Chainlit Web UI 集成
1. 会话启动事件
import chainlit as cl
@cl.on_chat_start
asyncdefon_start():
cl.user_session.set("agent", MCPAgent("ollama"))
cl.user_session.set("thread_id", "default")
await cl.Message(
content="MCP Chat Agent 已启动"
).send()
2. 消息处理(流式输出 + 工具提示)
@cl.on_message
asyncdefon_message(message: cl.Message):
agent = cl.user_session.get("agent")
thread_id = cl.user_session.get("thread_id")
msg = cl.Message(content="")
await msg.send()
asyncfor event in agent.graph.astream_events(
{"messages": [("user", message.content)]},
config={"configurable": {"thread_id": thread_id}},
version="v2",
):
etype = event["event"]
if etype == "on_chat_model_stream":
chunk = event["data"]["chunk"]
if chunk.content:
msg.content += chunk.content
await msg.update()
elif etype == "on_tool_start":
await cl.Message(
content=f"调用工具:{event['name']}",
author="tool"
).send()
elif etype == "on_tool_end":
await cl.Message(
content="工具执行完成",
author="tool"
).send()
3. 完整代码
import chainlit as cl
import asyncio
import json
import os
from typing import Annotated, TypedDict
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.graph import StateGraph, START
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph.message import add_messages
# ================== 配置 ==================
OPENAI_API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxx"
OPENAI_API_BASE = "https://dashscope.aliyuncs.com/compatible-mode/v1"
MCP_JSON_PATH = "/home/langchain-mcp-demo/mcp.json"
classState(TypedDict):
messages: Annotated[list, add_messages]
classMCPAgent:
def__init__(self, backend: str = "ollama"):
# -------- 模型选择 --------
if backend == "ollama":
self.llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.7,
streaming=True,
)
else:
self.llm = ChatOpenAI(
model="qwen3-30b-a3b-instruct-2507",
temperature=0.7,
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE,
streaming=True,
)
# -------- 加载 MCP --------
withopen(MCP_JSON_PATH, "r", encoding="utf-8") as f:
mcp_config = json.load(f)
client_config = {
name: {
"transport": "stdio",
"command": s["command"],
"args": s["args"],
}
for name, s in mcp_config["mcpServers"].items()
}
client = MultiServerMCPClient(client_config)
self.tools = asyncio.run(client.get_tools())
self.llm = self.llm.bind_tools(self.tools)
self.graph = self._build_graph()
def_agent(self, state: State):
return {"messages": [self.llm.invoke(state["messages"])]}
def_build_graph(self):
g = StateGraph(State)
g.add_node("agent", self._agent)
g.add_node("tools", ToolNode(self.tools))
g.add_edge(START, "agent")
g.add_conditional_edges("agent", tools_condition)
g.add_edge("tools", "agent")
return g.compile(checkpointer=MemorySaver())
# ================== Chainlit 生命周期 ==================
@cl.on_chat_start
asyncdefon_start():
# 默认用 Ollama,你也可以加 UI 选择
cl.user_session.set("agent", MCPAgent(backend="ollama"))
cl.user_session.set("thread_id", "default")
await cl.Message(
content="🤖 MCP Chat Agent 已启动(支持工具调用)"
).send()
@cl.on_message
asyncdefon_message(message: cl.Message):
agent: MCPAgent = cl.user_session.get("agent")
thread_id = cl.user_session.get("thread_id")
msg = cl.Message(content="")
await msg.send()
asyncfor event in agent.graph.astream_events(
{"messages": [("user", message.content)]},
config={"configurable": {"thread_id": thread_id}},
version="v2",
):
etype = event["event"]
if etype == "on_chat_model_stream":
chunk = event["data"]["chunk"]
if chunk.content:
msg.content += chunk.content
await msg.update()
elif etype == "on_tool_start":
await cl.Message(
content=f"🛠️ 正在调用工具:**{event['name']}**",
author="tool"
).send()
elif etype == "on_tool_end":
await cl.Message(
content="✅ 工具执行完成",
author="tool"
).send()
六、运行方式
chainlit run test.py
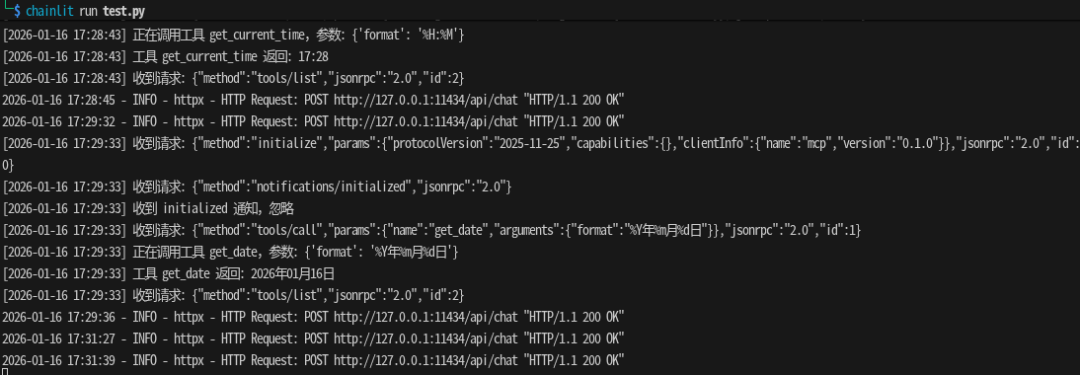
浏览器访问:
http://localhost:8000

支持功能:
- 流式模型输出
- MCP 工具自动调用
- 工具调用过程可视化
- 多轮对话上下文保持
参考文章
从零到一:用 Python 构建 MCP Server,基于 LangChain 的 Agent 与工具调用实战 [1]
创作不易,记得点赞、收藏、加关注!
引用链接
).send()
六、运行方式
------
```plaintext
chainlit run test.py
[外链图片转存中…(img-zbOxTc1z-1770711592958)]
浏览器访问:
http://localhost:8000
[外链图片转存中…(img-IYIbFDzx-1770711592958)]
支持功能:
- 流式模型输出
- MCP 工具自动调用
- 工具调用过程可视化
- 多轮对话上下文保持
普通人如何抓住AI大模型的风口?
为什么要学习大模型?
在DeepSeek大模型热潮带动下,“人工智能+”赋能各产业升级提速。随着人工智能技术加速渗透产业,AI人才争夺战正进入白热化阶段。如今近**60%的高科技企业已将AI人才纳入核心招聘目标,**其创新驱动发展的特性决定了对AI人才的刚性需求,远超金融(40.1%)和专业服务业(26.7%)。餐饮/酒店/旅游业核心岗位以人工服务为主,多数企业更倾向于维持现有服务模式,对AI人才吸纳能力相对有限。
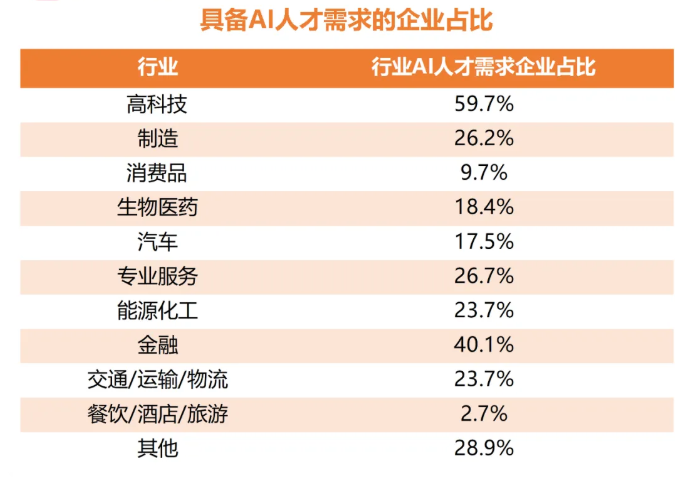
这些数字背后,是产业对AI能力的迫切渴求:互联网企业用大模型优化推荐算法,制造业靠AI提升生产效率,医疗行业借助大模型辅助诊断……而餐饮、酒店等以人工服务为核心的领域,因业务特性更依赖线下体验,对AI人才的吸纳能力相对有限。显然,AI技能已成为职场“加分项”乃至“必需品”,越早掌握,越能占据职业竞争的主动权
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可

部分资料展示
一、 AI大模型学习路线图
这份路线图以“阶段性目标+重点突破方向”为核心,从基础认知(AI大模型核心概念)到技能进阶(模型应用开发),再到实战落地(行业解决方案),每一步都标注了学习周期和核心资源,帮你清晰规划成长路径。

二、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

三、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

四、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献206条内容
已为社区贡献206条内容

所有评论(0)