Spring AI系列之RAG(检索增强生成)从原理到实战指南
选择RAG的场景• 需要实时更新的知识(如新闻、股价)• 数据量庞大且频繁变动• 需要解释性强的应用场景(可溯源到具体文档)• 预算有限,无法承担微调成本选择Fine-tuning的场景• 需要改变模型行为风格(如特定语气、格式)• 领域知识非常固定且通用模型表现极差• 对延迟敏感(RAG需要额外检索时间)
本文详细介绍了基于Spring AI的RAG技术,涵盖RAG核心架构、Embedding与相似度计算、Spring AI+Milvus实战实现、文本分割策略、检索优化技巧及效果评估。文章解决了LLM的知识截止、幻觉问题等缺陷,提供了完整代码示例和优化策略,帮助开发者构建高效的检索增强生成系统。
Spring AI系列之RAG(检索增强生成)从原理到实战指南
在LLM(大语言模型)时代,如何让AI既拥有通用能力又具备专业知识?RAG技术给出了完美答案。本文将基于Spring AI生态,深入剖析RAG的核心原理、实现细节与优化策略。
一、为什么需要RAG?
在深入了解RAG之前,我们需要先认识传统LLM的局限性:
| 缺陷类型 | 具体表现 | RAG解决方案 |
|---|---|---|
| 知识截止 | 模型知识有截止日期,无法获取最新信息 | 实时检索外部知识库 |
| 幻觉问题 | 自信地生成看似合理但实际错误的内容 | 基于检索到的真实信息生成 |
| 上下文限制 | 长文本处理能力有限 | 只检索最相关的上下文片段 |
| 领域专业度 | 通用模型缺乏垂直领域深度知识 | 外挂专业领域知识库 |
比喻理解:如果将LLM比作一个"高中毕业生",那么:
- • Fine-tuning(微调) = 让他花7年时间去医学院学习,然后成为医生
- • RAG = 给他配备了一群专业主任医师作为顾问,遇到问题时先咨询专家再作答
二、RAG核心架构解析
2.1 整体工作流程
RAG的工作流程可以分为两大阶段:离线索引(Indexing) 和 在线检索生成(Retrieval & Generation)。
RAG论⽂:https://arxiv.org/pdf/2312.10997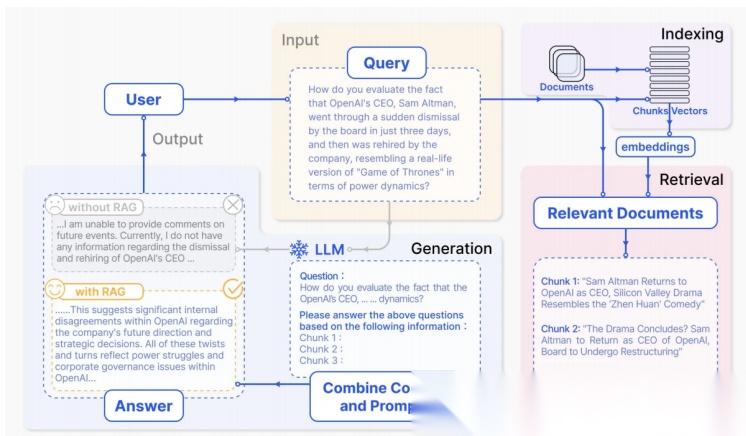
在这里插入图片描述
中文版本:
在这里插入图片描述
详细流程说明:
-
- 索引阶段(离线):
- • 文档加载:从PDF、Word、Excel等格式中提取文本
- • 文本分割(Chunking):将长文档切分为适当大小的片段
- • 向量化(Embedding):使用Embedding模型将文本转为向量
- • 存储:存入Milvus、Redis等向量数据库
-
- 检索阶段(在线):
- • 查询向量化:将用户问题转换为向量
- • 相似度匹配:在向量空间中查找最相似的Top-K个片段
- • 重排序(Reranking):(可选)对检索结果进行精排
-
- 生成阶段:
- • 上下文组装:将检索到的片段作为"已知信息"注入Prompt
- • LLM推理:模型基于提供的上下文生成答案
2.2 关键技术:Embedding与相似度计算
什么是Embedding?
Embedding是将文本、图像等转换为高维向量的技术。语义相似的文本在向量空间中的距离更近。
例如,⼆维空间中的向量可以表示为 (𝑥,𝑦),即表示从原点 (0,0) 到点 (𝑥,𝑦) 的有向线段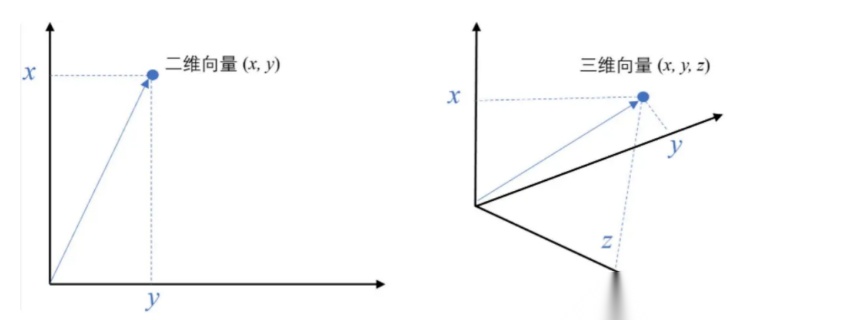
在这里插入图片描述
-
- 将⽂本转成⼀组浮点数:每个下标 i ,对应⼀个维度
-
- 整个数组对应⼀个 n 维空间的⼀个点,即⽂本向量叫
Embeddings
- 整个数组对应⼀个 n 维空间的⼀个点,即⽂本向量叫
-
- 向量之间可以计算距离,距离远近对应语义相似度⼤⼩
"这个多少钱" → [0.1, 0.5, -0.7, ..., 0.25]"这个什么价格" → [0.12, 0.4, -0.3, ..., 0.3] ← 距离近(语义相似)"给我报个价" → [0.15, 0.3, -0.2, ..., 0.3] ← 距离近(语义相似)"我想要这个" → [0.8, -0.1, 0.4, ..., -0.1] ← 距离远(语义不同)
```
在这里插入图片描述
**相似度计算方法**:
1. 1. **余弦相似度(Cosine Similarity)**
* • 衡量两个向量方向的相似性,值域[-1, 1]
* • 适合文本语义匹配,不受向量长度影响
* • 公式:
2. 2. **欧氏距离(Euclidean Distance)**
* • 衡量向量空间的实际距离
* • 公式:
* • 值越小越相似
具体选哪种方法?
* • **欧式距离**:如果更侧重于向量的实际距离,且向量的尺度相对一致时,更适合用欧式距离
* • **余弦相似度**:更适用于比较文本、关键词向量等场景。因为这些场景向量的方向比他们的模长更重要

在这里插入图片描述
三、实战:基于Spring AI + Milvus实现RAG
------------------------------
### 3.1 环境准备
**依赖配置(Maven)**:
```plaintext
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-openai</artifactId></dependency><dependency> <groupId>io.milvus</groupId> <artifactId>milvus-sdk-java</artifactId> <version>2.2.10</version></dependency>
配置信息:
# OpenAI配置(用于Embedding和Chat)spring.ai.openai.api-key=your-api-keyspring.ai.openai.embedding.api-key=your-api-keyspring.ai.openai.embedding.base-url=https://api.openai-hk.com# Milvus配置milvus.host=localhostmilvus.port=19530
3.2 核心代码实现
步骤1:创建向量集合
public void createCollection() { List<FieldType> fieldTypes = Arrays.asList( // 主键ID FieldType.newBuilder() .withName("id") .withDataType(DataType.Int64) .withPrimaryKey(true) .withAutoID(true) .build(), // 向量字段(1536维,对应text-embedding-3-small) FieldType.newBuilder() .withName("feature") .withDataType(DataType.FloatVector) .withDimension(1536) .build(), // 原始文本 FieldType.newBuilder() .withName("instruction") .withDataType(DataType.VarChar) .withMaxLength(65535) .build(), // 答案内容 FieldType.newBuilder() .withName("output") .withDataType(DataType.VarChar) .withMaxLength(65535) .build() ); CreateCollectionParam createParam = CreateCollectionParam.newBuilder() .withCollectionName("springai_rag") .withFieldTypes(fieldTypes) .build(); client.createCollection(createParam); // 创建IVF_FLAT索引,加速检索 CreateIndexParam indexParam = CreateIndexParam.newBuilder() .withCollectionName("springai_rag") .withFieldName("feature") .withIndexType(IndexType.IVF_FLAT) .withMetricType(MetricType.L2) .build(); client.createIndex(indexParam);}
步骤2:数据向量化与存储
@Autowiredprivate EmbeddingModel embeddingModel;public void insertData(List<FaqItem> items) { for (FaqItem item : items) { // 1. 文本向量化 float[] embeddings = embeddingModel.embed(item.getInstruction()); // 2. 构建插入参数 List<InsertParam.Field> fields = new ArrayList<>(); fields.add(new InsertParam.Field("feature", Collections.singletonList(embeddings))); fields.add(new InsertParam.Field("instruction", Collections.singletonList(item.getInstruction()))); fields.add(new InsertParam.Field("output", Collections.singletonList(item.getOutput()))); // 3. 插入Milvus InsertParam insertParam = InsertParam.newBuilder() .withCollectionName("springai_rag") .withFields(fields) .build(); client.insert(insertParam); }}
步骤3:RAG检索与生成
@Testvoid ragTest() { String userQuestion = "预算8000元以内,适合深度学习的笔记本电脑推荐"; // 1. 向量化查询 float[] queryEmbedding = embeddingModel.embed(userQuestion); // 2. 向量检索Top-3 SearchParam searchParam = SearchParam.newBuilder() .withCollectionName("springai_rag") .withMetricType(MetricType.L2) .withTopK(3) .withVectors(Collections.singletonList(queryEmbedding)) .withVectorFieldName("feature") .withOutFields(Arrays.asList("instruction", "output")) .build(); SearchResults results = client.search(searchParam).getData(); List<RowRecord> records = new SearchResultsWrapper(results).getRowRecords(); // 3. 构建上下文 StringBuilder context = new StringBuilder(); for (RowRecord record : records) { context.append("Q: ").append(record.get("instruction")).append("\n"); context.append("A: ").append(record.get("output")).append("\n\n"); } // 4. 构建增强Prompt String enhancedPrompt = String.format(""" # 角色设定 你是资深数码产品顾问,擅长根据用户需求推荐笔记本电脑。 请严格基于以下商品库信息回答,不要推荐库中不存在的商品。 # 商品库信息(Top-3匹配结果): %s # 用户需求: %s # 回答要求: 1. 先分析用户需求(用途、预算、性能要求) 2. 从商品库中推荐1-2款最合适的,说明理由 3. 如果商品库中没有匹配项,请明确告知"暂无符合要求的商品" 4. 最后可简要补充选购建议(非强制) """, context, userQuestion); // 5. 调用LLM生成 String answer = chatClient.prompt(enhancedPrompt).call().content(); System.out.println(answer);}
四、RAG优化策略与痛点解决
4.1 文本分割的艺术(Chunking Strategy)
文本分割是影响RAG效果的关键因素,常用策略对比:
| 分割策略 | 实现方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 固定字符数 | 每N个字符切分 | 简单高效 | 可能切断语义 | 对上下文连续性要求不高的场景 |
| 滑动窗口 | 固定大小+重叠部分 | 保留上下文衔接 | 数据冗余,存储增加 | 需要连贯性的长文档 |
| 递归字符 | 按标点优先级切分(先句号→逗号→空格) | 保持语义完整 | 实现复杂 | 专业文档、论文 |
| 基于语义 | 使用NLP模型判断语义边界 | 最优语义保留 | 计算成本高 | 高精度要求的知识库 |
最佳实践:
- • 结合文档结构(Markdown标题、PDF段落)进行分层切分
- • chunk大小建议:256-512 tokens(根据embedding模型调整)
- • 设置适当的重叠(overlap)保持上下文连贯
4.2 检索优化的进阶技巧
1. 混合检索(Hybrid Search)
结合关键词检索(BM25)和向量检索,兼顾精确匹配和语义理解:
// 伪代码示例List<Document> keywordResults = keywordSearch(query);List<Document> vectorResults = vectorSearch(query);List<Document> hybridResults = rerank(merge(keywordResults, vectorResults));
2. 重排序(Reranking)
使用专门的交叉编码器(Cross-Encoder)模型对Top-K结果进行精排:
- • 先使用向量检索召回Top-20
- • 使用重排模型计算问题与文档的相关性分数
- • 取Top-3作为最终上下文
3. 查询重写(Query Rewriting)
对用户的模糊查询进行扩展和澄清:
- • 原查询:“这个多少钱?”
- • 重写后:“iPhone 15 Pro Max 256GB 官方售价是多少?”
4.3 RAG痛点与解决方案
基于《Seven Failure Points When Engineering a Retrieval Augmented Generation System》的总结:
| 痛点类别 | 具体表现 | 解决方案 |
|---|---|---|
| Missing Content | 知识库中没有答案 | 设置兜底回复;持续扩充知识库 |
| Missed Top Ranked | 正确答案未进入Top-K | 调整similarity阈值;引入重排序 |
| Not in Context | 检索到内容但与问题无关 | 优化文本分割;提升向量模型质量 |
| Wrong Format | 需要JSON但返回了文本 | Prompt中明确输出格式示例;使用结构化输出 |
| Incomplete | 答案只覆盖问题部分 | 引导模型逐步思考(CoT);拆分复杂问题 |
| Not Extracted | 上下文中有答案但模型未提取 | 优化Prompt模板;增强上下文标识 |
五、RAG效果评估(RAGAS)
RAGAS(Retrieval-Augmented Generation Assessment)是评估RAG系统的标准框架,核心指标:
5.1 检索质量指标
-
- Context Relevancy(上下文相关性)
- • 衡量检索到的上下文与问题的相关程度
- • 计算公式:相关句子数 / 总句子数
-
- Context Recall(上下文召回率)
- • 衡量检索结果是否包含回答问题所需的所有信息
- • 基于标准答案(Ground Truth)进行判断
5.2 生成质量指标
-
- Faithfulness(忠实性)
- • 评估生成答案是否基于检索到的上下文,而非幻觉
- • 值越高,模型"编造"内容越少
-
- Answer Relevancy(答案相关性)
- • 衡量答案与问题的直接相关程度
评估数据集格式:
{ "question": "预算8000元以内,适合深度学习的笔记本电脑推荐", "contexts": [ "机械革命翼龙15 Pro配备RTX4060显卡,支持CUDA加速,售价7499元", "联想拯救者Y7000P 2024款搭载i7-14650HX和RTX4060,售价8499元超出预算", "轻薄本不适合深度学习,缺乏独立显卡" ], "answer": "推荐机械革命翼龙15 Pro,配备RTX4060显卡支持CUDA加速,价格7499元符合预算", "ground_truths": ["机械革命翼龙15 Pro,RTX4060,7499元"]}
六、总结与展望
RAG vs Fine-tuning 选择指南
选择RAG的场景:
- • 需要实时更新的知识(如新闻、股价)
- • 数据量庞大且频繁变动
- • 需要解释性强的应用场景(可溯源到具体文档)
- • 预算有限,无法承担微调成本
选择Fine-tuning的场景:
- • 需要改变模型行为风格(如特定语气、格式)
- • 领域知识非常固定且通用模型表现极差
- • 对延迟敏感(RAG需要额外检索时间)
未来趋势
-
- Agentic RAG:结合ReAct模式,让模型自主决定何时检索、检索什么
-
- 多模态RAG:支持图片、音频、视频的检索增强
-
- Graph RAG:结合知识图谱,处理复杂的多跳推理问题
参考资料:
- • Spring AI官方文档
- • 《Seven Failure Points When Engineering a Retrieval Augmented Generation System》
- • Milvus向量数据库最佳实践
通过本文,你应该已经掌握了RAG技术的完整链路:从文档切分、向量化存储,到相似度检索和Prompt增强。在实际项目中,建议先从简单的关键字检索+向量混合方案开始,逐步引入重排序、查询重写等优化策略。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)