Vibe Coding - Boris Cherny使用Claude Code的最佳实践
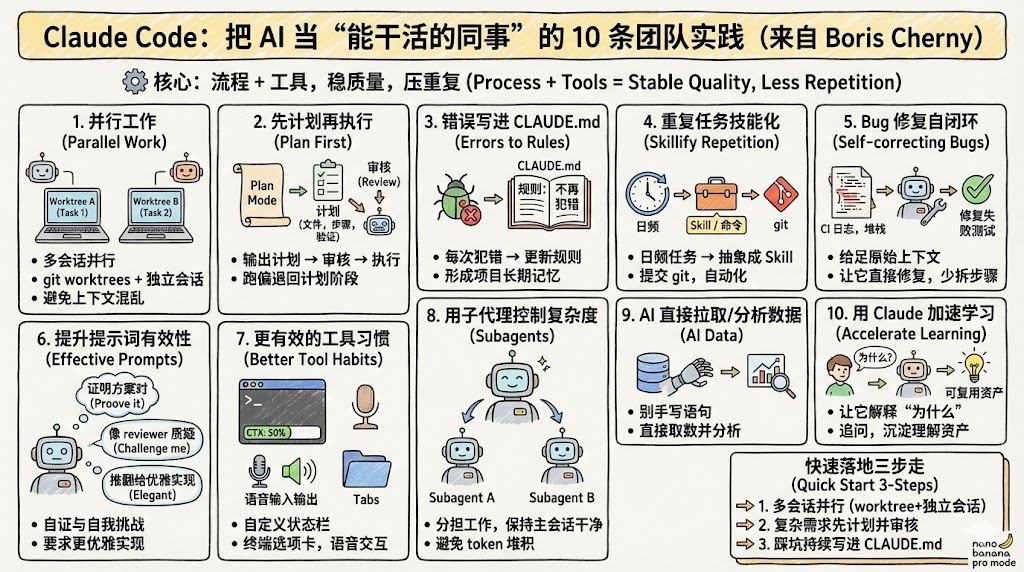
本文总结了10条高效使用Claude Code的方法,核心思路是通过结构化流程提升AI编程的稳定性和复用性。建议采用多worktree并行处理任务,复杂任务先制定计划并审核,将错误经验沉淀为项目规则文档,重复任务技能化,利用子代理分解复杂度。同时强调给AI完整上下文分析问题,通过质疑、证明等提示方式提高输出质量,并利用AI加速学习新代码库。这套方法通过流程化管理和知识沉淀,可显著减少重复错误,提高
文章目录
- 引言:为什么你用 AI 写代码总觉得“不稳”?
- 先给结论:这套方法在解决什么问题?
- 主体一:用并行替代上下文切换(worktrees + 会话隔离)
- 主体二:复杂任务必须从 Plan Mode 开始(计划 + 审核 + 偏离回退)
- 主体三:把错误沉淀进 `CLAUDE.md`(把教训变成项目规则)
- 主体四:超过一次的任务直接技能化(把重复劳动变命令)
- 主体五:Bug 修复尽量交给 Claude 自己(给全量上下文)
- 主体六:提示词怎么写才更像“工程协作”(逼它自证)
- 主体七:工具层面的细节优化(上下文可视化、终端、语音)
- 主体八:用 subagents 控制复杂度(让主会话永远清爽)
- 主体九:用 AI 直接拉取和分析数据(少写“手写语句”)
- 主体十:用 Claude 加速学习(把一次修改变成可复用资产)
- 一套可直接照搬的团队工作流(把 10 条串起来)
面向读者:有一定工程经验的开发者、技术负责人、研究/平台工程师。
主题一句话:别把 Claude Code 当“写代码的聊天框”,要把它当成“可并行的工程助手”,配合 worktree、计划评审、项目规则文件和子代理,才能稳定提效、少翻车。
引言:为什么你用 AI 写代码总觉得“不稳”?
很多团队第一次上 AI 编程工具,都会遇到三个典型问题:
- 1)任务一多就乱,聊着聊着上下文就脏了;
- 2)写得快但返工多,尤其是改动一大就容易偏离目标
- 3)同样的坑反复踩,换个人、换次对话又重来一遍。
接下来我们基于Claude Code 创建者 Boris Cherny 分享了团队在真实工程环境中使用 Claude Code 的 10 条做法。核心思路很一致:用流程和结构对抗不确定性,让模型的输出更可控、更可复用。
先给结论:这套方法在解决什么问题?
这 10 条建议可以归成四类能力建设:
- 并行化:用多个 worktree + 多个会话,让“多任务”变成“多线程”,减少切换污染。
- 计划驱动:复杂任务先 Plan Mode,计划还要被另一个会话审核;偏离就回退到计划。
- 记忆外置:把踩坑写进
CLAUDE.md,形成项目级长期记忆,降低重复错误率。 - 复杂度隔离:用 subagents 把工作分解,保持主会话干净,避免 token 堆积导致质量下降。
接下来我会按“怎么做、为什么、怎么落地”把它写成一套可执行的工程玩法。
主体一:用并行替代上下文切换(worktrees + 会话隔离)
团队会同时开启多个 git worktrees,每个 worktree 对应一个独立 Claude 会话,每个会话只做一件事,避免在单一对话中频繁切换任务造成上下文污染。
为什么这招有效?
因为“上下文污染”不是玄学:当你在一个对话里同时聊 A bug、B 功能、C 重构,模型会把互不相关的约束混在一起,最后输出看似合理但经常“跑题”。
怎么落地(推荐的工作方式)
你可以把 worktree 当成“任务沙盒”:
worktree/feat-login:只做登录功能worktree/bug-1234:只修一个失败测试worktree/refactor-api:只做 API 重构
每个 worktree 对应一个 Claude 会话,避免“同一个会话既当产品经理又当测试又当架构师”。
主体二:复杂任务必须从 Plan Mode 开始(计划 + 审核 + 偏离回退)
复杂需求不要直接写代码,要先让 Claude 输出清晰执行计划(改哪些文件、分几步、如何验证、如何回退);计划通常会被另一个会话审核,通过后再执行;一旦偏离就退回计划阶段。
可以直接照抄的 Plan 模板
把“计划”写得像工程任务单:
- 目标:一句话描述要达成的行为变化
- 影响范围:涉及哪些模块/文件/接口
- 步骤拆解:按可提交的粒度分 3–8 步
- 验证方式:单测、集成测、回归点、性能/安全检查
- 回退方案:如果失败,怎么最小化回滚
两会话审核怎么做?
- 会话 A(执行者):产出 Plan
- 会话 B(审稿人):按 reviewer 的口吻挑刺:遗漏的边界条件、测试缺口、潜在破坏性变更
这样做的价值是:把“模型自嗨”变成“模型互审”,至少能多一层保险。
主体三:把错误沉淀进 CLAUDE.md(把教训变成项目规则)
每次 Claude 出错,都会要求它更新 CLAUDE.md,把这次错误变成明确规则;文档会持续收敛模型行为,显著降低重复错误率,形成项目级长期记忆。
这其实是在做“工程化的提示词管理”
你在对话里说一百遍“不准改 public API”,不如在项目根目录有一条固定规则:
- “任何变更不得修改
public/*下导出的类型;如需变更,必须走 v2 版本并补迁移文档。”
下一次换人、换会话、甚至换模型,规则仍然在仓库里。
CLAUDE.md 建议写什么(可直接用)
按“禁止、偏好、流程”三类写:
- 禁止:不要做什么(例如不要改格式化规则、不要引入新依赖)
- 偏好:怎么做更好(例如优先用现有 util、遵循某种目录结构)
- 流程:必须走哪些步骤(例如必须补测试、必须更新 changelog)
每次出错都要更新它,靠迭代把模型行为“收敛”。
主体四:超过一次的任务直接技能化(把重复劳动变命令)
凡是每天重复超过一次的任务,会被抽象成 skill 或命令并提交到 git,让重复劳动自动化。
“技能化”的本质
不是神秘的 AI 魔法,而是把“你每次都要解释一遍的步骤”写成固定入口,让团队复用同一套操作。
适合技能化的例子
- 新增一个 API endpoint 的脚手架:目录、路由、校验、测试模板
- 修复失败测试的标准流程:拉日志、定位、最小修复、补回归
- 生成变更说明:按约定格式输出 release note
只要你发现自己“今天又讲了同一遍”,就值得技能化。
主体五:Bug 修复尽量交给 Claude 自己(给全量上下文)
给 Claude 完整原始上下文(CI 日志、堆栈、讨论记录),直接说“修复失败的测试”,而不是拆步骤逐步操作;并指出 Claude 在复杂日志和系统问题上的整体分析能力往往更强。
这条对很多人是反直觉的
很多人怕 AI 乱改,所以喜欢“手把手”让它改一行、跑一次。结果你付出了大量上下文组织成本,还把模型的全局分析能力压没了。
更好的提问方式(示例)
你可以把输入整理成一个“故障包”丢给它:
- 失败测试名称 + CI 链接/日志关键片段
- 堆栈、错误信息、最近相关提交
- 你怀疑的模块和原因(可选)
然后一句话目标:“让该测试在 CI 通过,并解释根因与修复点。”(对应原文“直接说修复失败的测试”)
主体六:提示词怎么写才更像“工程协作”(逼它自证)
三种很好用的提示方式:
- “证明这个方案是对的”、
- “像 code reviewer 一样质疑我”、
- “现在全部推翻,给我更优雅的实现”
核心是不断逼迫 AI 自证正确性。
可以把它当成三个“角色开关”
- 证明模式:要求给出推理链路、边界条件、失败场景
- 质疑模式:让它找你方案的漏洞
- 重构模式:不纠结小修小补,直接求更优雅实现
这三种切换,能显著减少“看似对但其实缺测试/缺边界”的输出。
主体七:工具层面的细节优化(上下文可视化、终端、语音)
自定义状态栏可视上下文长度和 git 分支,使用终端选项卡,语音输出;并强调语音永远比打字快。
这里的关键不是“酷”,而是减少摩擦
- 上下文长度可视化:能提醒你什么时候该分会话、该收敛输入
- git 分支提示:减少“改错分支/看错环境”的低级错误
- 终端选项卡:让“拉日志、跑测试、看差异”更顺手
- 语音:适合在你要描述复杂意图、但懒得打字时(原文明确强调语音效率)
主体八:用 subagents 控制复杂度(让主会话永远清爽)
使用 subagents 分担工作,保持主会话上下文干净,避免 token 堆积导致质量下降。
一个常见的 subagent 分工例子
- 主会话:只负责目标、验收标准、最终合并决策
- 子代理 1:读代码、画出调用链、找修改点
- 子代理 2:设计测试用例、补回归
- 子代理 3:检查风格、依赖、潜在破坏性变更
这样主会话不会被“阅读笔记”和“日志垃圾”淹没。
主体九:用 AI 直接拉取和分析数据(少写“手写语句”)
用 AI 直接拉取和分析数据,“再也不写手写语句”。
落地建议(工程视角)
你可以把它理解为:让 AI 帮你生成查询、聚合、对比口径,然后你负责确认指标定义和结果可信度。
尤其在排查线上问题时,“快速把数据口径写出来并跑通”能节省大量时间。
主体十:用 Claude 加速学习(把一次修改变成可复用资产)
启用解释型输出,让 Claude 讲清“为什么这样改”,并通过反问和示例补全认知,把一次修改转化为可复用的理解资产。
这条对团队最有长期价值
你不是要 AI 替你写一辈子代码,而是要它帮你把陌生代码库、陌生模块快速吃透。
每次合并前,让它把“改动动机、关键权衡、替代方案”讲一遍,你的认知会沉淀得更快。
一套可直接照搬的团队工作流(把 10 条串起来)
下面是一套“从接需求到合并”的最小闭环,你可以按周试运行:
- 建立 worktree:每个任务一个 worktree + 一个 Claude 会话,只做一件事。
- 复杂任务先 Plan:输出步骤、验证、回退;用第二会话做计划审核。
- 执行时保持主会话干净:阅读/调研/测试设计丢给 subagents。
- Bug 修复给全量上下文:CI 日志 + 堆栈 + 讨论记录,一句“修复失败测试”。
- 合并前做“自证”:用“证明方案正确”“像 reviewer 质疑我”等提示强制自检。
- 复盘写
CLAUDE.md:每次翻车都写规则;重复任务技能化并提交到 git。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)