
从被动唤醒到主动守望:基于AI Agent的智能任务架构实践
摘要:随着AI应用深入发展,AIAgent正从被动问答向主动服务演进。文章以"小高老师AIAgent"为例,剖析了智能任务系统的架构设计:通过分层抽象实现任务管理(交互层、管理层、执行层、基础设施层),采用"分身"部署策略分离实时对话与异步任务,构建事件驱动+时间触发的混合调度机制。系统支持周期性、监测性和长耗时三类任务,通过消息队列削峰、多级缓存优化和熔断

在LLM驱动的应用进入深水区后,开发者们发现:即便Agent再聪明,如果它只能停留在“你问我答”的被动模式,就永远无法触达“私人助理”的核心体验。
从OpenAI的ChatGPT Tasks到百度的“心响”产品、腾讯元宝定时任务,行业正在形成一个共识——AI Agent必须具备处理异步、长耗时、且可订阅任务的能力。本文将分享AI Agent团队在“小高老师 AI Agent”中如何构建一套可感知、可交互、可管理的智能任务框架,探讨从技术选型到架构演进的全链路迭代。
范式演进:从“定时提醒”到“智能订阅”
行业风向:AI Agent的“离线进化”
传统的定时任务(Cron Job)是僵化的,它只能在固定时间触发固定逻辑。随着大语言模型(LLM)的成熟,智能任务系统已成为AI应用的核心竞争点。
从OpenAI的ChatGPT Tasks到xAI的Grok Tasks,再到Manus的Scheduled Tasks以及百度推出的“心响”产品,各大厂商纷纷布局基于AI Agent的智能任务能力。
虽然产品命名各异,但其核心逻辑高度一致:将原本需要用户手动输入的提示词(Prompt),转化为可在预定时间或周期内自动运行的工作流。
这意味着即使用户处于离线状态,任务也会在云端自动执行,并在完成后通过通知系统将结果(如摘要、提醒)精准推送到用户面前。
逻辑重构:从时间驱动到事件感知
传统的定时任务仅是“时间点”的触发,而基于AI Agent的智能任务则实现了逻辑上的质变。
如果将任务的触发时机由简单的“时间设定”扩展为由“事件变更”驱动,系统便进化为基于AI Agent的智能订阅任务。相比于传统模式,智能订阅任务具备三大核心优势:
-
事件驱动(Event-Driven):不仅支持Cron表达式的时间触发,更支持外部数据(如油价波动、天气预警)的变化触发,灵活性显著提升。
-
智能判断:利用大模型的语义理解能力,系统可以对复杂的触发条件进行逻辑判断,而非简单的阈值匹配。
-
高度个性化:用户可以通过自然语言直接定义任务,系统自动解析并构建个性化的监测流。
核心画像:智能任务的三大分类
在“小高老师AI Agent”的实践中,我们根据任务触发的时机与复杂度,将其划分为三个维度:
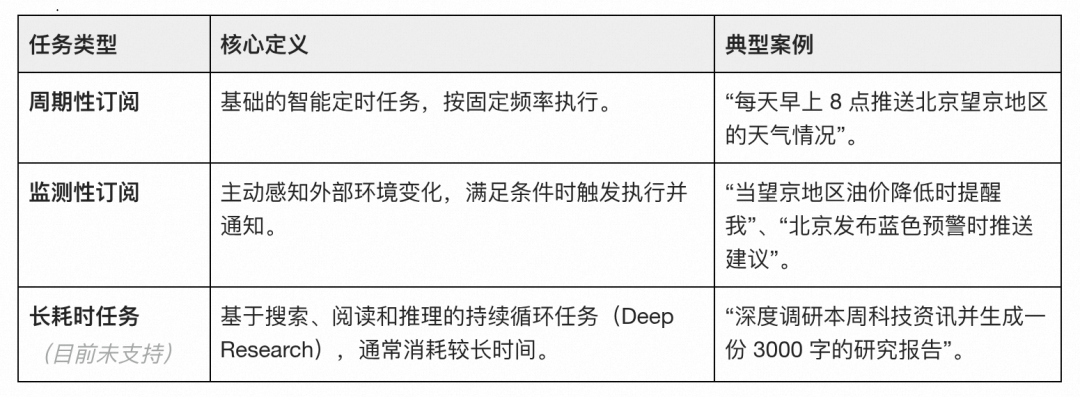
周期性订阅预期业务价值:提升用户粘性,通过订阅高频刚需场景,提升用户拉端、对话点击率;
监测性订阅预期业务价值:驱动精准转化,直接触达用户决策时刻,提升高价值信息的点击率。
工程挑战:从愿景到落地的“最后一公里”
要构建一个承载百万级用户的智能任务架构,必须直面以下技术挑战:
-
全链路闭环体验:需要打通从“意图创建、生命周期管理、异步执行到结果通知”的完整链路,且必须支持长耗时任务的断点重试机制。
-
高并发下的稳定性:例如,当百万级用户同时订阅了“早8点天气提醒”时,如何在瞬间洪峰下保证任务执行的吞吐量与稳定性?如何处理长耗时任务间的资源抢占?
-
系统的可扩展性:面对不断涌现的个性化诉求,架构需要支持灵活扩展复杂任务类型,快速适配不同的工具集与数据源。
技术笔记
智能任务的本质是异步化与Agent状态的持久化。
它将AI从一个“对话窗口”释放出来,变成了一个在后台24小时运行的逻辑引擎。
架构设计:分层抽象与“分身”部署实践
通用框架抽象:智能任务系统的四层架构模式
为了实现可扩展且高可用的智能任务系统,我们借鉴了事件驱动架构(EDA)与工作流编排的思想,将系统抽象为四个核心层级:
-
交互层(Interaction Layer):作为用户意图的入口。主 Agent 负责实时理解用户的自然语言指令,通过 CoT(思维链)推理定义任务参数,并提供任务创建与管理的交互界面。
-
管理层(Management Layer):系统的“指挥部”。由任务管理服务(TaskManager)负责任务的全生命周期管理(CRUD)、调度策略(定时或事件驱动)以及状态的持久化,确保任务定义与执行逻辑解耦。
-
执行层(Execution Layer):系统的“动力舱”。任务 Agent 专门负责异步执行具体的任务逻辑,包括调用外部工具(如天气、油价)及生成最终的通知内容。
-
基础设施层(Infrastructure Layer):提供底层支撑。利用消息队列(Kafka/RocketMQ)实现流量削峰,通过 Redis 进行状态缓存,并利用监控系统保障链路透明。
“分身”部署:在线同步与离线异步的彻底分离
应对高并发挑战的关键在于职责分离原则(Separation of Concerns),即实现主Agent与任务Agent的“分身”部署。
1. 资源“分身”部署
在传统的单体Agent架构中,长耗时的异步任务往往会占用大量系统线程,导致用户的实时对话请求出现卡顿。
通过“分身”部署,我们将在线同步流程与离线异步流程物理隔离:
-
主Agent(在线分身):部署在高性能在线业务集群,专注于极速响应用户的 Query,优先级最高,确保用户“随叫随到”的交互心智。
-
任务Agent(离线分身):部署在独立的计算集群。它不直接处理用户请求,而是从消息队列中消费任务实例,按需进行横向扩容,即便后台正在处理百万级的天气推送,也不会影响前台用户的正常聊天。
2. 状态机驱动:任务生命周期的闭环管理
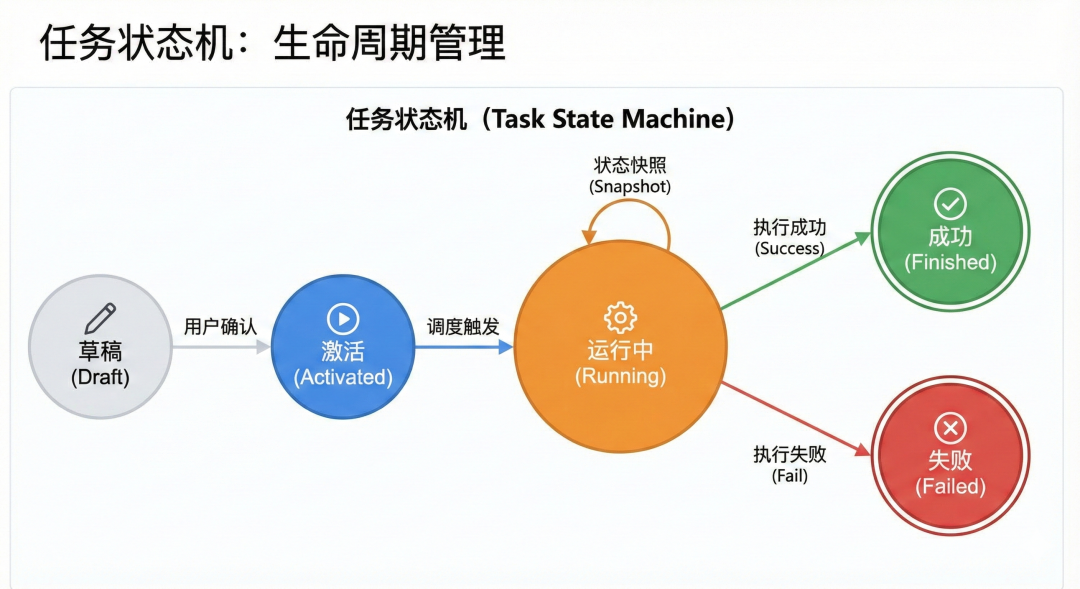
为了支撑任务的可追踪性,任务管理服务通过一套严密的状态机模型对任务进行管控。从用户在前端点击“开启订阅”开始,任务经历“创建、激活、调度、执行、回写、推送”的全链路闭环:
-
主Agent生成任务草稿并展示任务确认卡片。
-
用户激活任务后,任务管理将其转化为待执行实例投递至消息队列。
-
任务Agent异步消费消息,执行过程中不断回写状态,确保任务执行可观测、可追溯。
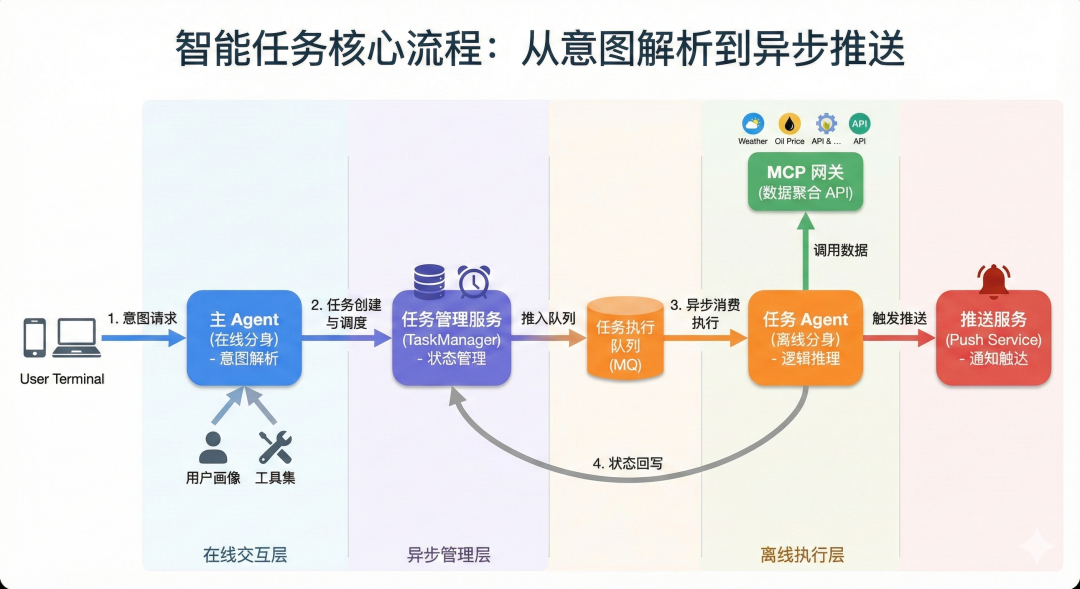
核心流程:从意图解析到异步推送
系统整体的运行逻辑可以概括为一个高效的流水线:
-
用户终端发起需求,主Agent结合用户画像与工具集解析意图。
-
任务管理服务持久化任务配置,并根据触发时机(定时或事件)将任务推入任务执行队列。
-
任务Agent接收指令,通过MCP网关调用底层聚合数据API获取实时信息,并根据推理结果触发推送服务。
-
执行结果最终回写至管理服务,完成状态更新。
技术笔记
智能任务架构设计的精髓在于“把复杂留给后台,把简单交给用户”。
通过主从Agent的分工协作,不仅解决了资源争抢的工程难题,更在百万级并发的挑战下,实现了Agent从“工具”向“私人助理”的体验跃迁。
核心链路:任务的“生命之旅”
任务管理流程是连接用户抽象意图与底层物理执行的关键桥梁,确保任务在复杂的全生命周期中始终处于受控状态。
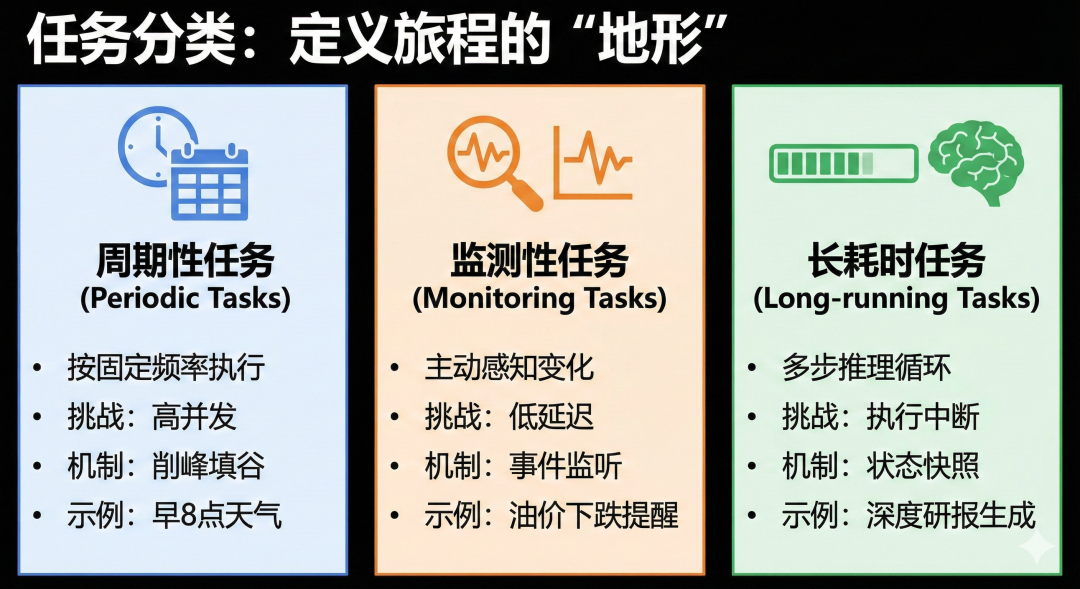
任务分类:定义旅程的“地形”
在出发之前,系统首先需要识别任务的属性。根据触发时机与复杂度,我们将任务旅程划分为三条不同的路径:
-
周期性任务(Periodic Tasks):如“每天早8点推送天气”。其技术挑战在于高并发场景下的削峰填谷与资源隔离,避免百万级任务同时触发导致系统雪崩。
-
监测性任务(Monitoring Tasks):如“油价下跌5%提醒我”。这类任务依赖外部条件的实时变更,需要强大的事件监听与低延迟处理能力。
-
长耗时任务(Long-running Tasks):如“生成本周旅游攻略”。这类任务涉及多步推理,必须具备状态快照机制,确保在执行中断后能从断点恢复。
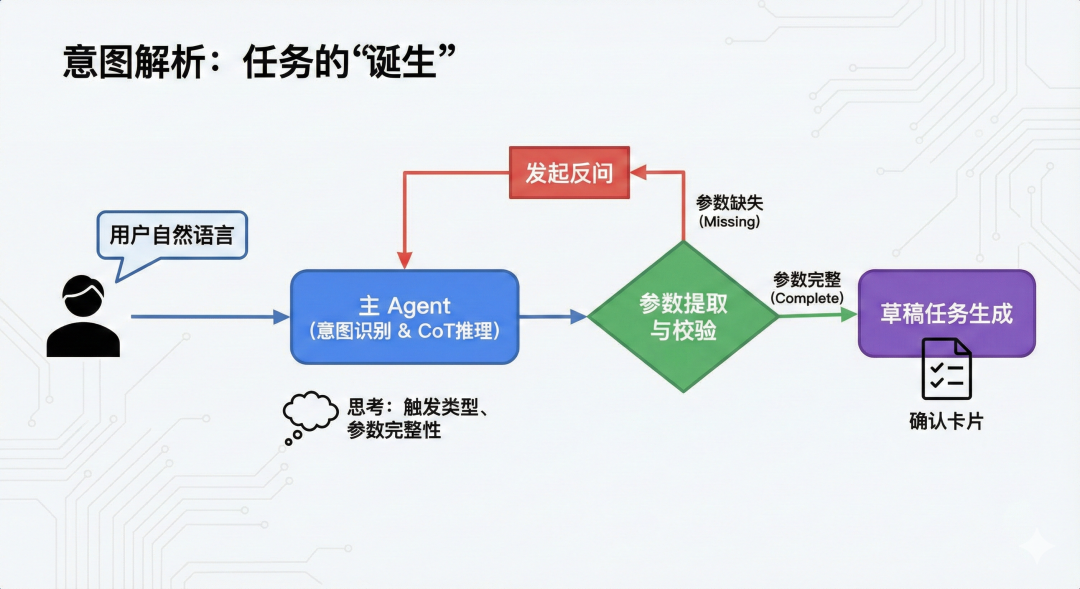
意图解析:任务的“诞生”
任务的起点是主Agent对自然语言的深度理解。我们采用基于CoT(思维链)推理的多轮对话式定义模式:
-
意图识别与CoT推理:主Agent并不直接提取参数,而是先进行“思考”。例如,识别关键词、判定触发类型(Cron 或 Event)、校验参数完整性。
-
参数提取与校验:通过CoT提取时间、地点等核心槽位。若参数不全(如未说明城市),Agent会发起反问:“请问您需要订阅哪个城市的天气?”。
-
草稿任务生成:参数校验通过后,任务管理服务生成一个任务并渲染卡片给用户。这种“确认后再开启”的设计,极大提升了用户对AI行为的确定性感知。
任务实例化与调度:入库与“待命”
一旦用户确认开启订阅,任务便进入了实例化阶段,遵循严谨的状态机模型:
-
生命周期管理:任务状态会在“草稿、激活、运行中、成功/失败”之间流转。这种模式借鉴了主流任务调度框架(如 XXL-Job)的设计,确保了状态的持久化。
-
差异化调度策略:
-
周期性调度:通过分布式CronJob将触发事件投递至消息队列。
-
监测性调度:通过EventBus(事件总线)监听外部API的变更。当多源数据异构无法统一时,系统会退化为短周期轮询模式(Polling),在实时性与基础效果间取得平衡。
-
状态快照(Snapshot):对于复杂的长耗时任务,调度器会配合执行器定期记录“检查点”,为后续的断点重试提供基础保障。
-
技术笔记
任务的“生命之旅”本质上是语义柔性与工程刚性的结合。
通过前端 CoT 的灵活理解与后端状态机的严密调度,我们让 Agent 具备了在云端长时间自主运行的能力,真正实现了从“单次对话”向“持续服务”的跨越。
高效的任务执保障:系统级“自愈”
智能任务的执行环境极具不确定性。为了确保任务在云端能够稳健运行,我们从调度策略、通信模式以及容错机制三个维度构建了全方位的保障体系。
任务触发器:前置“轻调度”与预处理
任务执行实例在进入任务Agent之前,会先经过一个关键的触发器(Trigger)层。这一层的作用类似于“前哨站”,负责对任务进行精细化的预处理:
-
优先级动态排序:并非所有任务都按时间顺序执行。系统会根据业务价值进行编排,例如“油价调价提醒”等高价值、时效性强的任务会被赋予高优先级,优先抢占计算资源执行。
-
动态参数注入:在消费消息的瞬间,触发器会完成参数模板的替换、个性化数据的追加以及来源标识的补全。这确保了任务Agent接收到的是最完整、最实时的上下文信息。
-
执行状态记录:触发器会详细记录每一轮执行的开始时间、重试次数等元数据,为后续的故障回溯提供数据支持。
异步消息队列:高并发场景下的“避风港”
在处理如“百万级用户早 8 点天气推送”这种瞬时洪峰场景时,传统的同步调用会面临巨大的压力。通过对比,选择异步消息队列消费模式作为核心通信手段:
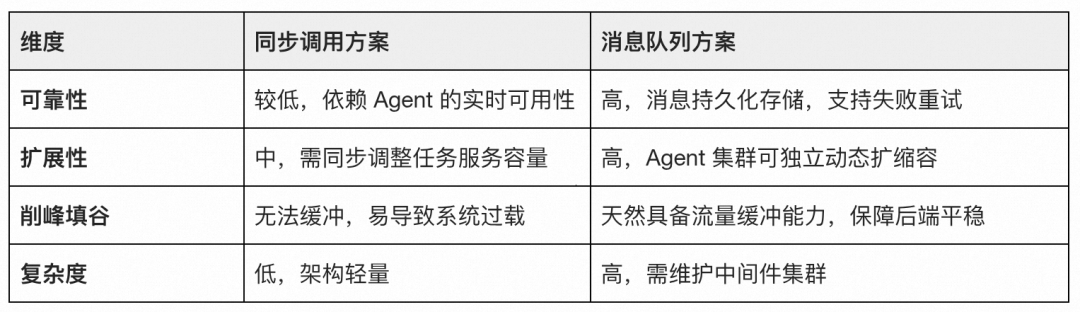
通过消息队列方案,我们将任务的“产生”与“执行”彻底解耦,即便在突发流量下,系统也能通过积压消息的方式保护后端Agent集群不被瞬间击垮。
多级重试策略:基于指数退避的容错模式
面对不可避免的执行失败,我们设计了一套重试策略模式,将错误进行分级处理:
-
分级响应:
-
瞬时错误(如网络瞬时抖动):立即触发重试,上限3次。
-
临时错误(如外部API限流):进入指数退避流程。
-
永久错误(如参数解析非法):直接标记失败,不再重试,防止资源浪费。
-
-
指数退避算法:失败后不会立即再次请求,而是按照10s、20s、40s的间隔递增延迟,有效避免了因频繁重试引发的“重试风暴”和下游系统压力。
-
幂等性保障:利用任务ID+具体执行实例ID作为唯一键,确保在多次重试下,用户绝不会收到重复的推送内容。
技术笔记
通过触发器的预处理、消息队列流量缓冲以及状态快照的断点恢复,我们为 AI Agent打造了一套可靠的“自愈”系统,使其能够在无人值守的情况下,稳健地完成每一项用户嘱托。
性能与稳定性保障:让 Agent “长跑”不掉线
稳定性与性能是智能任务系统的“底盘”。我们通过多级缓存策略减少冗余计算,利用MCP协议标准化工具调用,并辅以熔断限流与全链路监控,构建了高可用的执行环境。
多级缓存:告别冗余调用
AI任务往往涉及频繁的外部API调用(如天气、油价数据)和复杂的模型推理。为了提升性能并大幅降低成本,我们设计了多级缓存策略:
-
本地缓存与分布式缓存协同:
-
本地缓存:使用高性能框架,存储极高频访问的数据,实现微秒级响应,减少网络开销。
-
分布式缓存:利用Redis存储跨实例共享的任务状态和结果,保证数据一致性。
-
-
精细化的TTL设计:缓存失效时间(TTL)与任务周期严格对齐。例如,天气或油价任务的缓存通常设为24小时,支持自适应调整,确保数据时效性与成本的最佳平衡。
-
缓存预热机制:基于任务历史执行模式的预测,在高峰时段(如早8点天气推送)触发前提前预热核心数据,将首次执行延迟降至最低。
优化收益:
-
成本降低:利用结果缓存,日均减少了约30%的API调用。
-
响应提速:核心业务数据的获取延迟从秒级降至50ms以内,确保了任务在极短的窗口期内完成分发。
MCP协议:工具调用的标准化与插件化
为了支撑海量的个性化任务诉求,Agent必须能够灵活调用各类工具。我们引入了MCP(Model Context Protocol)协议作为工具层的核心规范:
-
接口统一化与动态注册:通过MCP网关,所有外部工具均被抽象为标准接口。这使得新工具的接入无需重启服务,实现了真正的插件化模式。
-
跨平台适配:MCP协议让Agent能够无缝对接多源异构数据,无论是内部API还是第三方服务,都能以统一的语义上下文进行交互,极大提升了工具链的扩展性。
熔断限流:在高并发浪潮中稳住阵脚
面对突发流量或外部服务崩溃,系统必须具备自我保护能力。
-
智能限流:触发器根据系统当前水位自定义资源位限流,限制每秒执行的任务数量。当系统负载过高时,会自动开启自适应限流,优先保障高优任务的执行。
-
熔断与降级:当某个外部工具(如第三方油价API)调用失败率达到阈值时,系统会触发自动熔断,快速失败并返回降级后的默认值或缓存数据,防止级联故障导致整个Agent集群瘫痪。
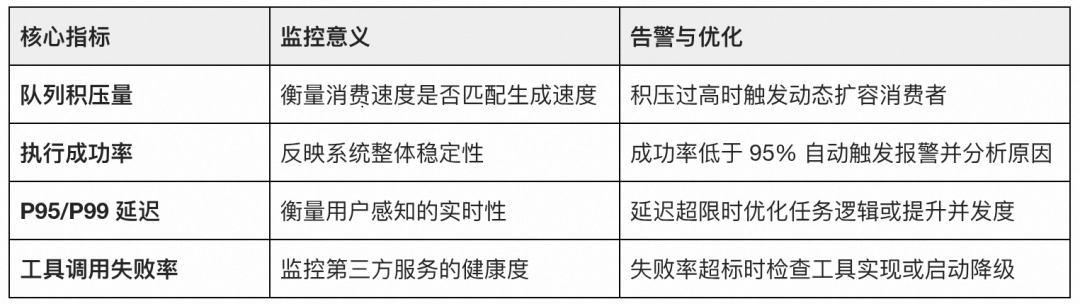
全链路监控:构建系统的“数字看板”
可观测性是性能优化的“眼睛”。我们基于指标(Metrics)、日志(Logs)与追踪(Traces)三大支柱,构建了严密的监控告警体系:
技术笔记
性能优化永无止境,但稳定性永远是系统级服务的第一要义。
实践中的挑战与解决方案:
工程细节里的“魔鬼
架构图上的优美线条,在面对真实的高并发与网络波动时,需要极其强悍的容错能力来支撑。
环境隔离:解决“邻居太吵”的问题
在初期尝试中,将主Agent与任务Agent混合部署,结果发现任务执行会瞬间吞掉CPU和线程池,导致体验卡顿。
-
物理隔离方案:我们最终将任务Agent独立部署到专属的集群中,并设置了严格的资源配额(Quota)。
-
网络与数据解耦:两套集群拥有独立的服务发现机制和日志存储,确保即便后台任务全量过载,前台的即时对话依然丝滑。
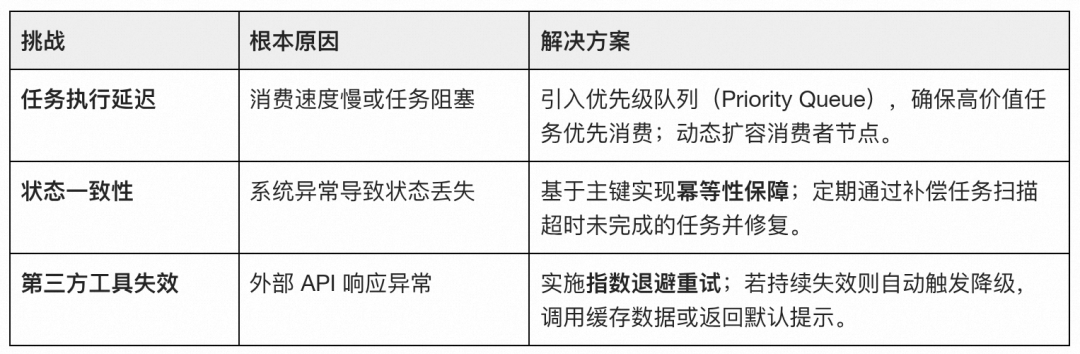
常见痛点与“锦囊妙计”
在实际运行中,我们总结了一套应对突发状况的解决方案:
总结与未来展望
核心价值复盘:从“冰冷的工具”到“暖心的助理”
通过这套架构,我们不仅实现了技术上的突破,更赋予了AI Agent “主动性”:
-
业务价值:AI能够主动挖掘用户深层意图,在油价降价、天气突变等关键时刻自主行动,实现了从“被动回复”到“拟人化关怀”的质变。
-
架构价值:沉淀了一套分层解耦、差异化调度的通用AI任务框架,为未来承载更多复杂场景打下了坚实底座。
在“小高老师AI Agent”上线智能任务后,我们通过实验放量观察到了业务反馈:在使用订阅功能的用户中,次日任务页面打开率达到60+%,用户从“偶尔提问”转变为“长期依赖”。Agent 不再是被动回复的搜索框,而是变成了24小时在线的守护者。
目前该功能正在逐步放量中,后续小伙伴们就可以在高德地图app中小高老师对话中体验到该功能~
对话页创建任务端侧效果图:
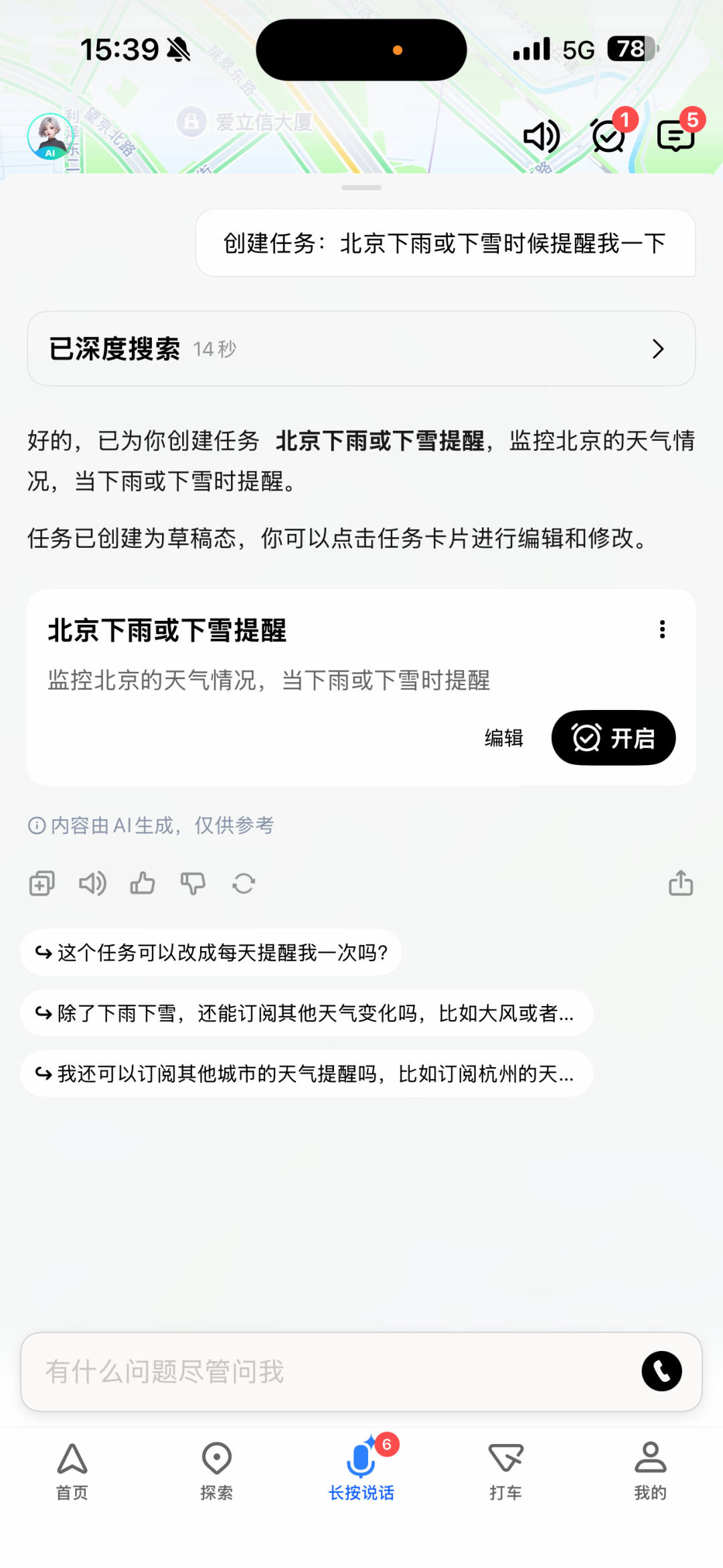
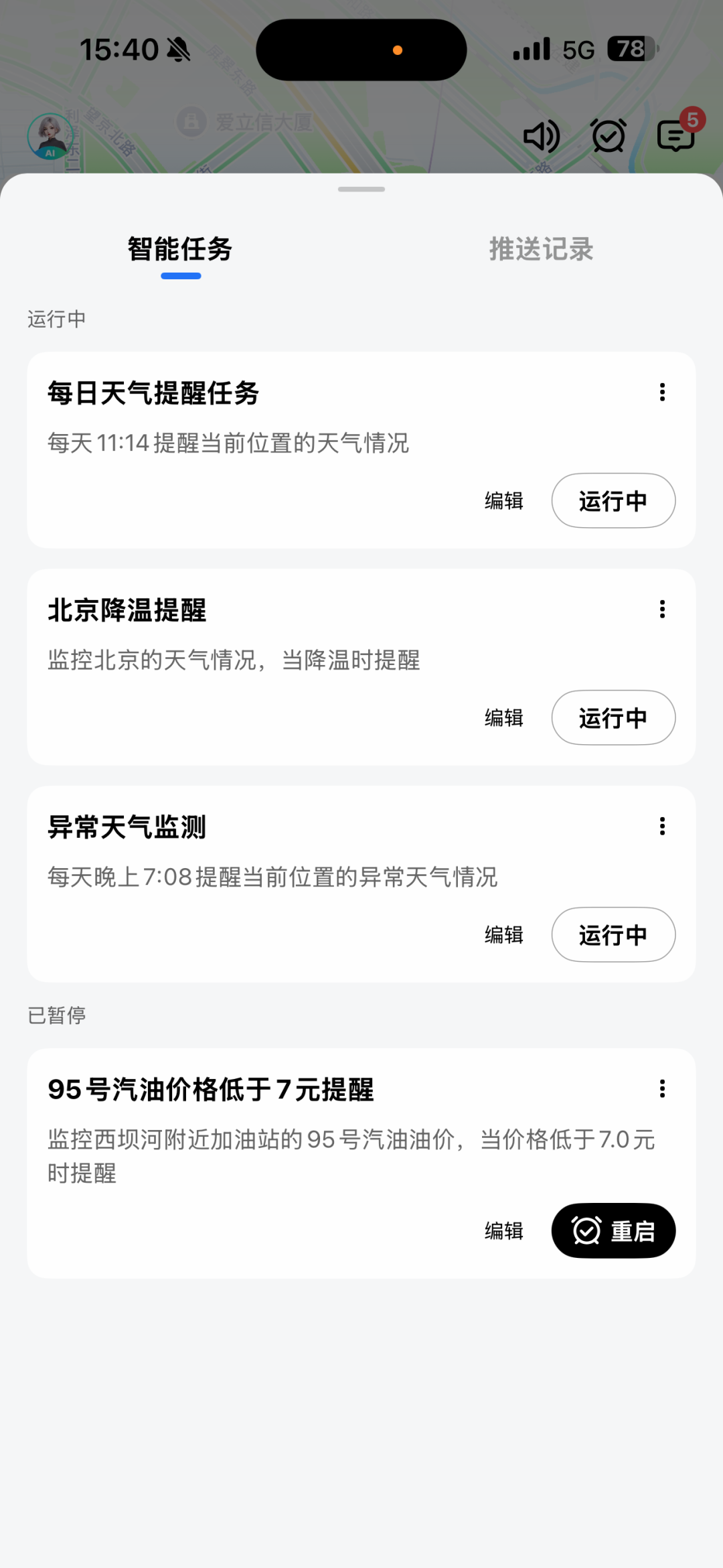
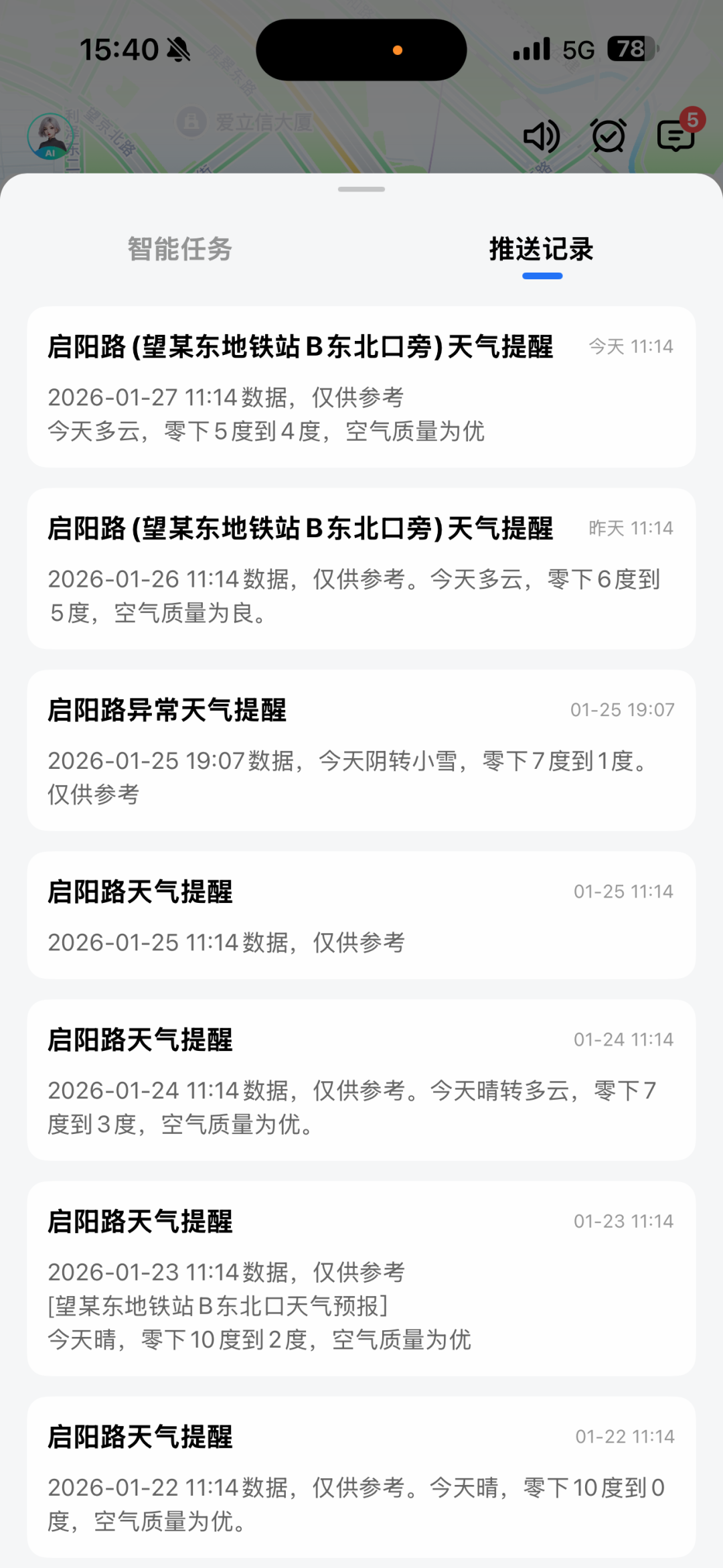
点击对话页顶部右侧小闹钟查看任务和任务推送情况:
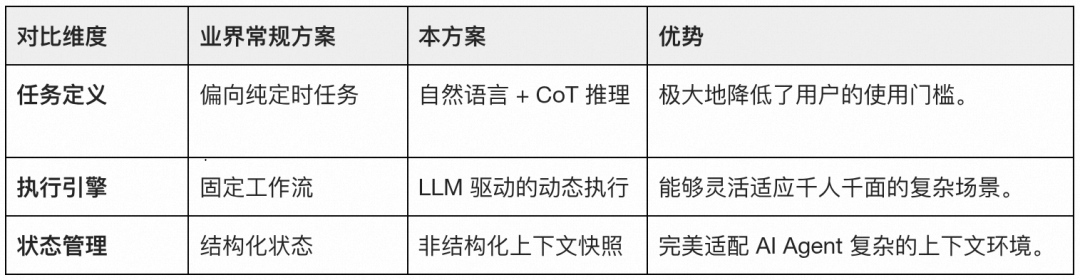
行业对比
与市面上如百度“心响”等产品相比,我们的方案在灵活性上更具优势:
未来航向:更智能、更高效
我们的征途才刚刚开始,未来的优化方向将聚焦于:
-
AI 驱动的任务规划(Planning):支持带条件分支、循环执行的复杂任务逻辑,例如“发现降温 -> 自动查询附近展馆 -> 匹配用户空闲时间 -> 发起预约”。基于用户反馈和历史数据,智能调整任务执行优先级;实现任务执行效果的自动评估和优化。
-
实时性与智能化运维:优化事件监听机制以降低感知延迟;利用AI进行异常检测与自动扩容,实现真正的“零人工干预”运维;用户体验提升:支持任务执行过程的实时反馈,提供任务执行的可视化展示等。
结语
智能任务架构的设计,本质上是在平衡算法的“灵性”与工程的“刚性”。通过抽象通用框架、具体落地实践和细节优化三个层次的阐述,该方案为AI Agent任务系统提供了通用能力底座,兼顾用户体验与系统扩展性,成功让AI Agent具备了在云端独立“长跑”的能力。
在实际落地过程中,深刻体会到:架构设计需要平衡通用性与具体性,既要抽象出可复用的模式,也要考虑实际业务场景的特殊性。未来,我们将继续探索AI Agent在任务调度、资源优化等方面的应用,推动智能任务系统向更加智能化、自动化的方向发展。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取