Build 01 / 架构推演:为什么我们在 2026 年依然选择 Tauri + Rust?
拒绝“网页套壳”,我以开发者视角从零构建 EchoMindBot。本系列深度拆解 Tauri + Rust 的原生性能压榨,消灭臃肿的 Python 环境依赖,实现极致异步调度。这里没有浮躁跟风,只有关于记忆、成本与进化的硬核实战。回归技术纯粹,见证 AI 助手从代码中长出来。
在 Build 00 里我明确了立场,现在直接上刺刀,聊聊为什么这款助手的底层非Tauri 2.0 + Rust不可。
1. 那些 666 的“套壳”骚操作

最近OpenClawd这种优秀的开源 Agent 项目很火,原本在 Web 端跑得挺好,但国内的现状却很讽刺。一些蹭流量的博主和无良厂商,为了所谓的“方便安装环境”,直接给这种 Web 应用硬加了个极其臃肿的 Electron 壳子。
这种做法极其荒谬:原本在浏览器里开个网页就能解决的事,他们非要强行分配几百 MB 甚至上 GB 的内存给这个毫无意义的外壳。这种把开发者自己的“环境兼容性难题”转嫁给用户电脑寿命的行为,竟然还被包装成“自研客户端”到处炫耀。
2. 硬核重写的三个死磕指标
我之所以选择从头构建,就是为了拉低普通用户的门槛,而不是拉高系统要求。为了不让EchoMind Bot AI助手变成用户的“性能负担”,我死磕这三点:
-
内存压榨 (Memory Optimization):拒绝 Electron 那种“每个应用都自带一个浏览器”的偷懒做法。通过Tauri 2.0共享系统原生 WebView,我将待机内存从 GB 级直接压榨到60MB - 120MB。
-
消灭 Python 环境依赖:目前绝大多数项目都依赖Python + Vue架构,但 Python 的环境安装对非技术用户来说是巨大的灾难。无论是全局安装导致的系统环境崩溃,还是强行打包一份臃肿的 Python 运行环境,亦或是抛出一个脆弱的自动化脚本,本质上都是不靠谱的行为。在 EchoMindBot 中,所有核心逻辑、AI 调度及任务分发全部由Rust 后端静默解决。用户下载的是一个不到15MB的二进制实体,实现真正的“零配置”开箱即用。
-
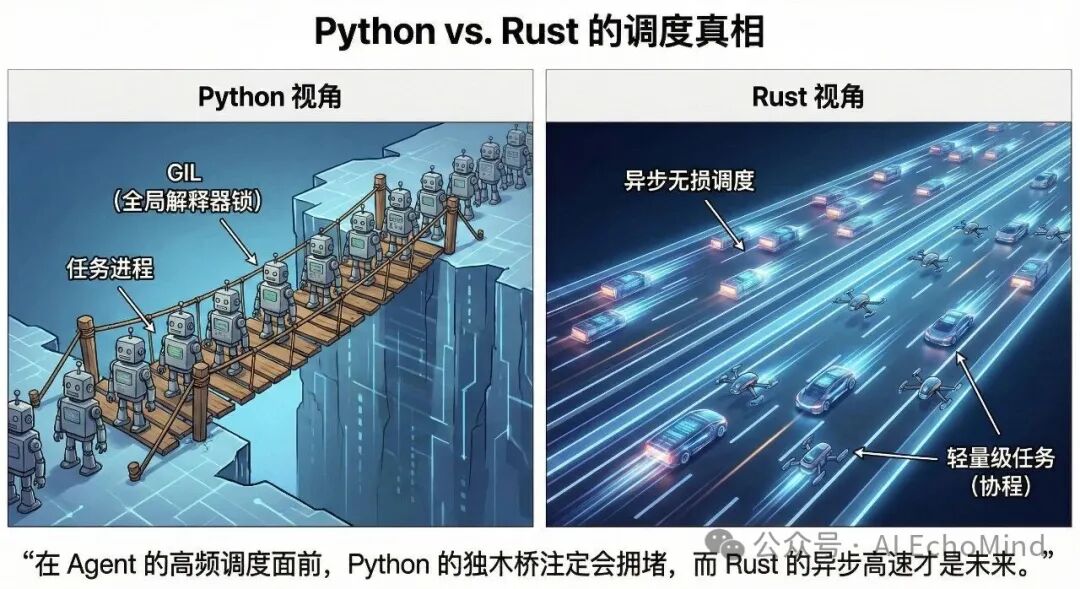
极致调度 (Python vs. Rust):谈调度就不得不提两者的本质区别。Python 的GIL(全局解释器锁)限制了它在多线程下的真正并发能力,面对 Agent 高频的 IO 任务和认知思考逻辑时,往往只能通过“多进程”这种极耗资源的方式来妥协。而Rust凭借Tokio 异步运行时和无锁并发,能以极小的开销管理成千上万个轻量级任务。这意味着当 Agent 在后台进行复杂的反思(brain_thinking.rs)或调用系统接口时,CPU 的每一分算力都用在了刀刃上,而不会让你的系统产生任何粘滞感。
3. 核心架构拆解:从指令路由到 Agent 循环
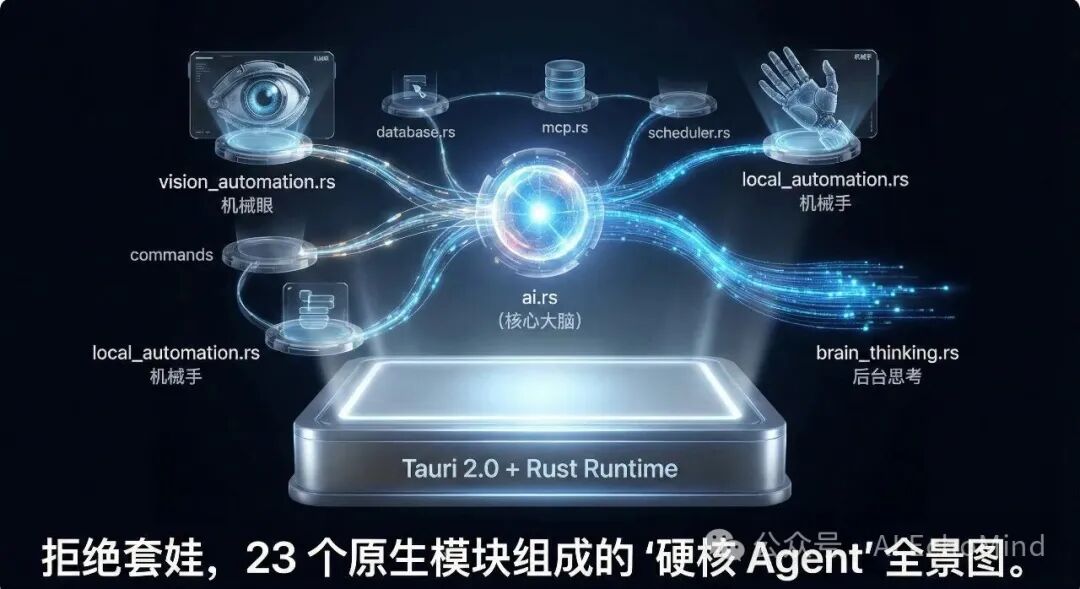
为了实现极致的性能,我将整个后端抽象为四个核心层级。
A. 指令路由中心 (The Command Router)
在 lib.rs 中,我们构建了一个高频分发的“交通枢纽”:
// ═══════════════════════════════════════════════
// lib.rs — Tauri 指令枢纽
// 所有前端 invoke() 调用在此统一注册和分发
// ═══════════════════════════════════════════════
fn main() {
App::build()
// 1️⃣ 初始化基础设施
.setup(|app| {
db = Database::init("moltbot.db") // SQLite 持久层
vector_db = VectorDB::init() // 向量检索引擎
scheduler = Scheduler::start(db) // 异步定时调度器
})
// 2️⃣ 注册 23 个模块的命令处理器
.register_commands([
// ── 对话核心 ──
streaming::stream_chat, // SSE 流式对话(主入口)
// ── 认知中枢 ──
brain::get_memories, // 记忆 CRUD
brain::search_memories, // 语义向量检索
brain::get_brain_activity_stats, // 活动统计
// ── Agent 能力 ──
mcp::call_mcp_tool, // MCP 工具协议调用
skills::execute_skill, // 技能执行
shell::run_command, // 本地 Shell 命令
// ── 自动化操控 ──
automation::app_launch, // 应用启动
automation::app_click, // 坐标点击
automation::capture_screenshot, // 窗口截图
// ── 系统管理 ──
config::save_ai_config, // 配置持久化
config::get_ai_config, // 配置读取
scheduled_tasks::*, // 定时任务管理
model_router::auto_route, // AI 模型自动路由
]).run()
}B. Agent 闭环逻辑 (ai.rs)
这是助手的“大脑”核心。我实现了一个带状态复盘的 loop 机制:
-
意图分类 (Intent Router):通过规则匹配或 AI 轻量分类,按需加载 Prompt 级别(Chat/Search/Tool 等)以大幅节省 Token 开销。
-
ReAct 协议:核心循环会自动解析 __TOOL_CALL__,在解析工具调用的过程中自我修正,直到任务最终达成闭环。
// ═══════════════════════════════════════════════
// ai.rs — 带意图路由的 ReAct 闭环引擎
// Intent Classification → Prompt Assembly → Tool Loop
// ═══════════════════════════════════════════════
async fn stream_chat(user_message, history) {
// ━━━ Phase 1: 意图分类(轻量 AI 调用,节省 90%+ Token) ━━━
prompt_level = classify_intent(user_message)
// "今天天气好" → Chat (仅基础规则,~200 tokens)
// "帮我搜下新闻" → Search (+ web_search 工具描述)
// "执行 ls 命令" → Tool (+ Shell + 本地应用工具)
// "帮我操作微信" → Browser (+ MCP + Skills + 托管账号)
// "定时每天汇报" → Full (全部注入,~3000 tokens)
// ━━━ Phase 2: 按需组装 System Prompt ━━━
system_prompt = build_system_prompt(prompt_level)
// Minimal: 仅用户自定义 prompt
// Chat: + 基础规则
// Search: + web_search / web_fetch 工具定义
// Tool: + Shell + 本地应用工具定义
// Browser: + MCP工具 + Skills + 托管账号信息
// Full: 以上全部 + 定时任务 + 自主思考指令
// ━━━ Phase 3: 注入 RAG 记忆 ━━━
relevant_memories = vector_db.search(user_message, top_k=3)
system_prompt += format_memories(relevant_memories)
// ━━━ Phase 4: ReAct 循环(最多 100 次迭代) ━━━
for iteration in 1..=MAX_ITERATIONS {
response = ai_api.call_streaming(system_prompt, messages)
// 解析响应:是否包含工具调用?
if response.contains("__TOOL_CALL__") {
tool_name, params = parse_tool_call(response)
tool_result = match tool_name {
"web_search" => execute_web_search(params),
"web_fetch" => execute_web_fetch(params),
"run_command" => execute_shell(params),
"mcp_*" => call_mcp_server(params),
"app_click" => local_automation(params),
_ => error("unknown tool")
}
// 将工具结果追加到上下文,继续循环
messages.push(tool_result)
} else {
// 无工具调用 → 任务闭环,输出最终回答
emit_final_response(response)
break
}
// 接近上限时触发自我评估
if iteration > MAX * 0.8 {
self_assess_and_maybe_stop()
}
}
// ━━━ Phase 5: 后台异步提取记忆 ━━━
spawn_async(brain::extract_and_store_memories(messages))
}C. 认知中枢 (Brain Layer)
为了不给用户电脑增加负担,我将“反思与学习”逻辑封装进了异步调度器:
-
语义检索 (RAG):利用向量数据库进行相似度检索,将 Top 3 相关记忆动态注入 System Prompt。
-
异步反思:brain_thinking.rs 在后台静默提取对话中的关键事实,存入 SQLite 结构化表。
// ═══════════════════════════════════════════════ // brain_thinking.rs — 异步认知引擎 // 静默运行:反思 → 记忆沉淀 → 待办生成 → 自主行动 // ═══════════════════════════════════════════════ async fn brain_autonomous_cycle() { loop { sleep(config.auto_run_interval) // 默认每 30 分钟一轮 // ━━━ Step 1: 收集上下文 ━━━ recent_chats = db.get_recent_conversations(hours=2) existing_memory = db.get_all_memories() pending_todos = db.get_todos(status="pending") interests = db.get_interests() // ━━━ Step 2: AI 反思(Minimal Prompt,低开销) ━━━ reflection = ai.think({ prompt: "基于以下对话和已有记忆,做出反思: 1. 提取值得长期记住的新事实 2. 发现用户可能需要跟进的事项 3. 根据兴趣判断是否需要主动学习", context: { recent_chats, existing_memory, interests } }) // ━━━ Step 3: 结构化存储 ━━━ for fact in reflection.new_facts { // 语义去重:检查是否已有相似记忆 similar = vector_db.search(fact.content, threshold=0.9) if similar.is_empty() { memory_id = db.insert_memory(fact) vector_db.index(memory_id, embedding(fact.content)) } } // ━━━ Step 4: 自动生成待办 ━━━ for todo in reflection.suggested_todos { db.insert_todo({ title: todo.title, priority: todo.priority, // 1=高 2=中 3=低 source: "ai_reflection", // 标记 AI 自动生成 }) } // ━━━ Step 5: 自主行动(可选,需开启) ━━━ if config.allow_network && reflection.has_research_task { action_result = execute_research(reflection.research_topic) db.log_action(type="research", result=action_result) } } } // ── 语义记忆检索(供 ReAct Loop 调用) ── fn search_memories(query, top_k=3) -> Vec<Memory> { query_embedding = embedding_model.encode(query) candidates = vector_db.similarity_search(query_embedding, top_k * 2) // 按 重要度 × 相似度 × 时间衰减 排序 return candidates .sort_by(|m| m.importance * m.similarity * recency_weight(m.date)) .take(top_k) }
D. 本地自动化平面 (Action Layer)
通过 local_automation.rs 和 vision_automation.rs 实现了真正的“手眼协同”:
-
截图感知:调用系统底层接口获取窗口画面,实现视觉自动化。
-
OCR 映射:将视觉坐标精准映射为鼠标点击坐标,实现对微信、WPS 等桌面应用的原生操控。
// ═══════════════════════════════════════════════
// local_automation.rs + vision_automation.rs
// 手眼协同:截图感知 → OCR 识别 → 坐标映射 → 精准操控
// ═══════════════════════════════════════════════
// ── AI 发出操控指令的完整流程 ──
async fn automate_desktop_app(task_description) {
// ━━━ Step 1: 启动并聚焦目标应用 ━━━
app_launch("WeChat") // 调用系统 API 启动应用
app_activate("WeChat") // 将窗口提至前台
sleep(500ms) // 等待窗口渲染稳定
// ━━━ Step 2: 窗口定位 ━━━
window_info = get_window_bounds("WeChat")
// → { x: 100, y: 50, width: 800, height: 600 }
// 通过 macOS Quartz API / Windows Win32 获取精确窗口坐标
// ━━━ Step 3: 截图感知 ━━━
screenshot = capture_window_screenshot("WeChat")
// → PNG 无损截图(非 JPEG,保证 OCR 精度)
// → 截图坐标系:相对于窗口左上角 (0,0)
// ━━━ Step 4: AI 视觉分析 ━━━
ai_analysis = vision_model.analyze({
image: screenshot,
prompt: "识别界面元素位置,找到「发送」按钮的坐标"
})
// → AI 返回截图内相对坐标: { element: "发送按钮", x: 720, y: 550 }
// ━━━ Step 5: 坐标映射(核心难点) ━━━
// AI 返回的是「截图像素坐标」
// 操作系统需要的是「屏幕绝对坐标」
// 还需考虑 Retina 高分屏缩放比例
scale_factor = get_display_scale() // macOS Retina = 2.0
screen_x = window_info.x + (ai_analysis.x / scale_factor)
screen_y = window_info.y + (ai_analysis.y / scale_factor)
// ━━━ Step 6: 执行操作 ━━━
// 先输入文字
app_type_text("你好,这是自动发送的消息")
sleep(200ms)
// 再点击发送按钮
app_click(screen_x, screen_y)
// ━━━ Step 7: 验证结果 ━━━
sleep(1000ms)
verify_screenshot = capture_window_screenshot("WeChat")
verification = vision_model.analyze({
image: verify_screenshot,
prompt: "确认消息是否已成功发送"
})
return verification.success
}
// ── 底层系统接口(跨平台) ──
fn app_click(x, y) {
#[cfg(macos)] CGEvent::mouse_click(x, y) // Quartz Event
#[cfg(windows)] SendInput(MOUSEINPUT { x, y }) // Win32 API
#[cfg(linux)] XTest::fake_motion(x, y) // X11 XTest
}
fn capture_window_screenshot(app_name) -> PNG {
#[cfg(macos)] CGWindowListCreateImage(window_id) // 窗口级截图
#[cfg(windows)] PrintWindow(hwnd) // GDI 截图
}[ 性能对标:EchoMindBot vs. 某大厂套壳助手 ]
| 指标 | 某大厂 Electron 助手 | EchoMindBot (Tauri+Rust) |
| 待机内存 | ~800MB - 1.2GB | 60MB - 120MB |
| 启动耗时 | > 2000ms | < 500ms |
| 安装包体积 | ~200MB+ | ~15MB |
| 核心逻辑 | Web 指令传话 | Rust 原生指令分发 |
结语:让代码对硬件负责
我不想要一个看起来很酷但跑起来很重的“大象”。既然这圈子里的二道贩子都在“套壳”偷懒,那我就选择走那条最难的路——硬核重写,原生构建。
系统预览:
上一篇回顾:
Build 00 / 拒绝“套壳”:我想要一个真正的超级 AI 助手,以及这个系列的初衷
下一篇预告:
Build 02 / 认知中枢:拆解 brain_thinking.rs,看我们如何实现“零负担”的后台反思逻辑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)