国产大模型春节血战!GLM-5 + DeepSeek新版 + MiniMax M2.5 同一天炸场,老外看傻了
摘要:2026年2月11日,中国AI领域迎来“春节前集体爆发”,智谱AI、DeepSeek和MiniMax三大头部厂商几乎同时发布重磅升级:GLM-5(745B参数MoE架构,Coding/Agent性能超Claude Opus 4.6)、DeepSeek新版(1M超长上下文+2025年5月知识截止)和MiniMax M2.5(轻量高效、本地可跑)。
2026年2月11日,中国AI圈直接上演了一场“春节前集体发车”大戏。短短24-48小时内,三大头部玩家几乎同时放大招:智谱AI正式推出GLM-5、DeepSeek悄然灰度新版模型、MiniMax上线M2.5。这波操作让不少开发者直呼“内卷到飞起”“国产AI春晚提前开演”,甚至有海外网友调侃“中国AI Hunger Games开打了”。
今天我们来全面盘点这三款新模型的亮点、实测反馈、潜在影响,以及为什么说2026春节是中国大模型真正“起飞”的节点。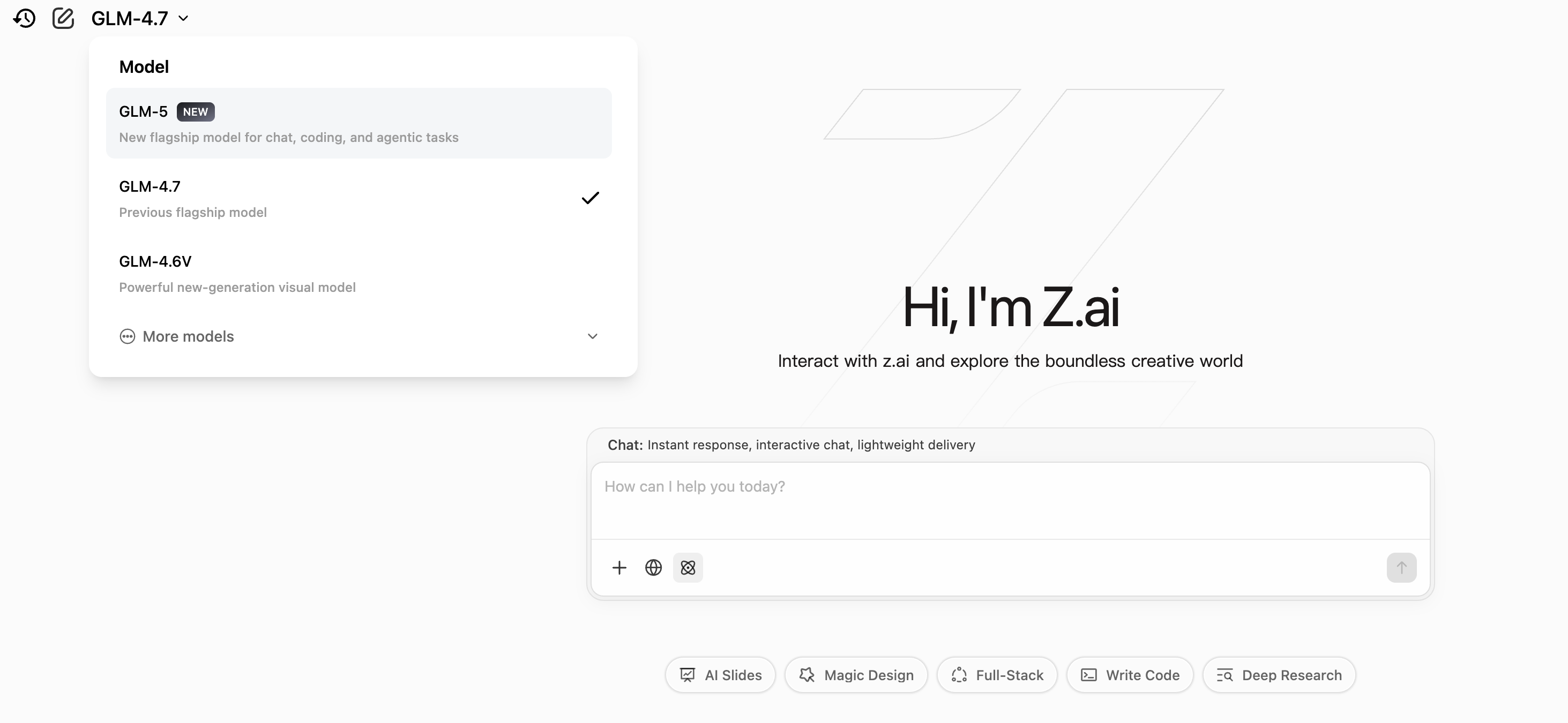
1. 智谱AI GLM-5:正式王炸,Coding & Agent直逼Claude Opus 4.6
- 发布时间:2026年2月11日正式发布(部分用户提前通过“Pony Alpha”在OpenRouter体验)
- 核心参数与亮点:
- 745B总参数(MoE架构,仅40B活跃),推理效率高
- 强项:复杂Coding、多步Agent任务、长上下文处理
- 基准表现:AICodeKing等多项Coding benchmark超越Claude Opus 4.6和GPT-5.3 Codex;在部分指标上也超过Gemini 3 Pro
- 开源:官方确认开源(具体许可待跟进)
- 国内芯片适配:使用华为Ascend等国产芯片训练/推理
- 体验地址:chat.z.ai(网页/客户端均已升级)
- 社区反馈(来自X实时热议):
- “GLM-5在多步Agent任务上接近Claude Opus 4.5,价格却只有1/10”
- “Pony Alpha偷偷上OpenRouter直接冲榜一,太狠了”
- “香港IPO后直接放大招,Zhipu这是要all in海外?”
GLM-5被视为智谱的“DeepSeek时刻”,尤其在Coding和自主Agent领域,性价比直接拉满。
2. DeepSeek 新版:1M上下文 + 知识到2025年5月,程序员的梦中情机
- 发布时间:2026年2月10-11日灰度/大面积推送(App更新到1.7.4后可见)
- 核心升级:
- 上下文窗口:从128K暴增到1M tokens(接近10倍提升,可一次性塞入《三体》三部曲级别文本)
- 知识截止:2025年5月(比之前版本大幅更新)
- 核心能力跃升:编程、复杂推理、美学判断、物理模拟等都有明显进步;速度快、价格低
- 体验地址:chat.deepseek.com(需更新客户端/网页版,可能分批推送)
- 社区反馈:
- “直接扔整个monorepo进去分析,1M上下文真的香爆”
- “知识到2025年5月,编程和长文档处理直接起飞”
- “这波更新后,DeepSeek又一次把性价比天花板拉高”
DeepSeek一贯的风格:不声张,先灰度测,然后直接碾压。1M上下文让它在长代码审查、大文档总结、复杂项目重构上极具竞争力。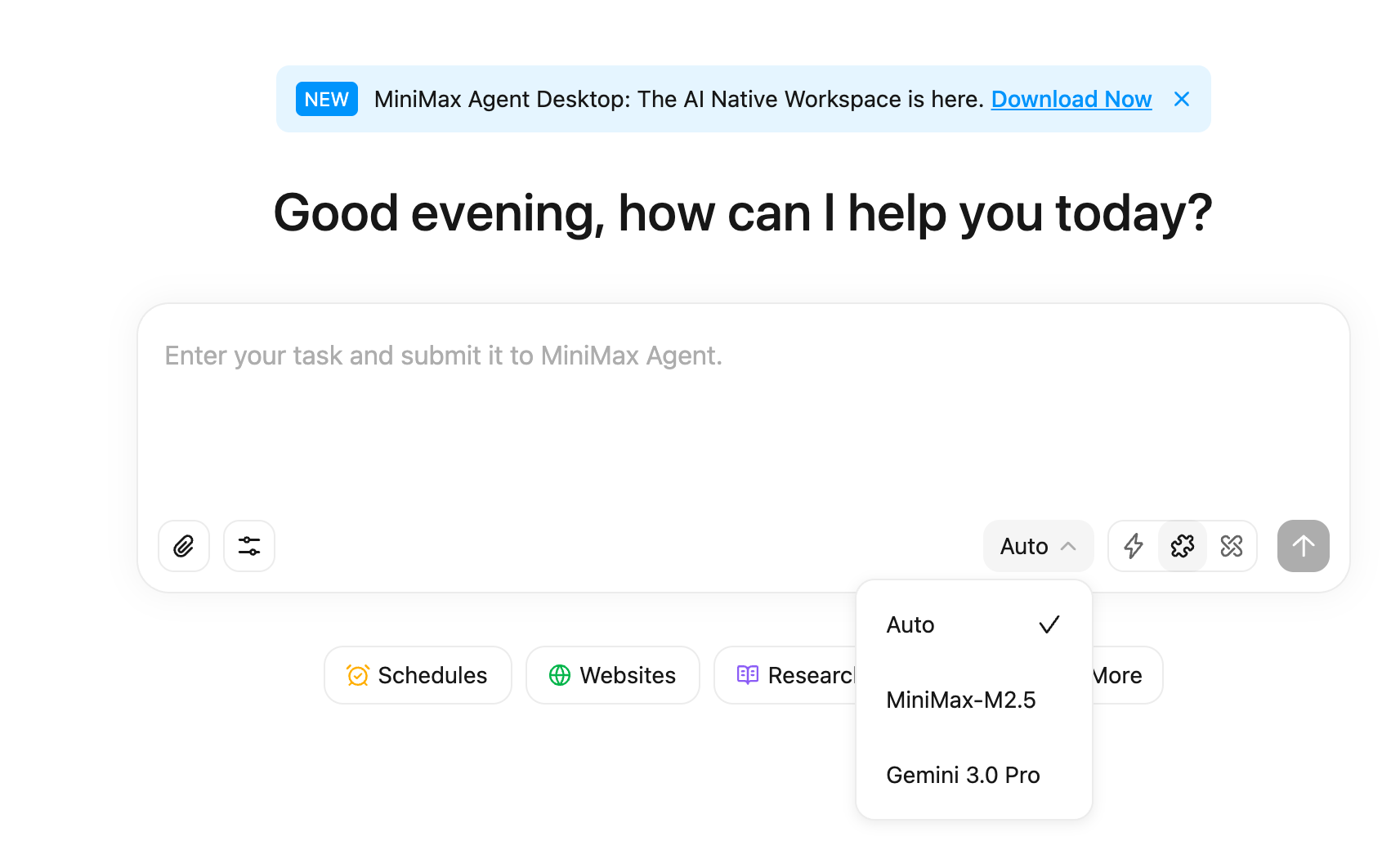
3. MiniMax M2.5:体积小、价格低、Agent/编程强,Mac Mini都能本地跑?
- 发布时间:2026年2月10-11日(海外Agent网站已上线,国内产品同步出现)
- 核心亮点:
- 旗舰升级版,综合能力传闻接近/部分匹敌Claude Opus 4.6
- 强项:编程、智能体(Agent)、多模态理解
- 体积相对精简(社区传闻Mac Mini可流畅跑,适合本地/边缘部署)
- 价格极低:API调用成本在国产模型中继续保持地板级
- 体验地址:agent.minimax.io(网页/桌面端即时可用)
- 社区反馈:
- “MiniMax M2.5今天突然杀到,Agent能力炸裂”
- “编程和工具调用又强又便宜,开发者福音”
- “三大巨头同一天发车,春节前内战正式开打”
MiniMax一贯低调猛,M2.5在体积-性能-价格三角区打出了极致平衡,尤其适合智能体和开发场景。
三强快速对比表(基于当前公开信息 & 社区初步实测)
| 维度 | GLM-5 (智谱) | DeepSeek 新版 | MiniMax M2.5 |
|---|---|---|---|
| 发布状态 | 正式发布 | 灰度/大面积推送 | 产品中上线/海外Agent可用 |
| 上下文窗口 | 长上下文(具体待官方) | 1M tokens | 中长上下文(具体待测) |
| 知识截止 | 较新(具体待官方) | 2025年5月 | 较新 |
| 强项 | Coding / 多步Agent | 长文档 / 编程 / 推理 | Agent / 编程 / 性价比 |
| 参数规模 | 745B (MoE 40B active) | 未公布(高效MoE) | 相对精简 |
| 价格/效率 | 高性价比 | 地板价 + 超快 | 极低 + 本地友好 |
| 社区热度 | ★★★★★ (Coding benchmark炸) | ★★★★☆ (1M上下文神器) | ★★★★☆ (突然杀出) |
为什么这波“春节血战”这么猛?背后逻辑
- 香港IPO后冲刺:智谱 & MiniMax刚在港交所上市,急需用硬实力证明估值。
- 春节前抢热度:中国科技公司传统“年前冲KPI”,今年直接演变成三巨头互卷。
- 全球竞争白热化:Claude Opus 4.6、GPT-5.3 Codex已出,国产必须跟上甚至超车。
- 开源+低价策略:用性价比和开发者生态反超海外封闭模型。
结语 & 展望
48小时内三款旗舰级模型集体上线,这在AI历史上都罕见。接下来几天,字节Doubao 2.0、阿里Qwen 3.5、腾讯混元等很可能继续跟进——2026春节档,注定是中国大模型的“高光时刻”。
你已经测过哪一款了?编程最强的是谁?1M上下文真香吗?欢迎评论区battle~
AI内卷,永不停止。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)