01-从零构建LangChain知识体系通俗易懂!!!
目录
🔧 核心知识点:LCEL(LangChain Expression Language)
从零构建 LangChain 知识体系(小白友好·比喻版)
📌 引言
你现在站在一片名为“大模型应用”的森林前。LangChain 不是森林本身,而是一张详细的地图 + 一套实用的工具。要读懂这张地图,你需要先认识森林里的基本元素——我们从最底层开始。
第一层 · 地基:LLM 与它的基本语言
1. 大脑:LLM(大语言模型)
比喻
一个读过全人类所有书籍的超级实习生。知识渊博,反应快,但有两个致命缺点:
-
必须你发指令,它才动;
-
毕业后新出的书它没读过,会理直气壮地瞎编。
专业定义
LLM 是通过海量文本训练出的深度学习模型,核心能力是“文字接龙”——根据上文预测最可能的下文。
📌 在 LangChain 中:所有应用的最后执行者,是整个体系的发动机。
2. 交流介质:Prompt 与 Token
比喻
-
Prompt = 你发给实习生的工作指令单。写清楚“你是谁、要做什么、按什么格式交”,结果就精准;写得模糊,结果随机。
-
Token = 实习生阅读时的最小信息颗粒。中文 1 个字 ≈ 1~2 个 Token,英文 1 个单词 ≈ 0.75 个 Token。每条指令和回复都按 Token 数收费,所以指令要精简。
专业定义
Prompt 是用户输入的全部文本,可包含指令、上下文、示例、格式约束。Token 是模型计费与上下文窗口的基本单位。
📌 在 LangChain 中:提供 PromptTemplate 管理提示词,支持 tiktoken 精确计费,帮你省钱。
3. 空间语言:Embedding(嵌入)
比喻
给每个词、每句话标上经纬度坐标。
-
“苹果”和“香蕉”坐标很近(水果);
-
“苹果”和“手机”稍远(但有关联);
-
“苹果”和“相对论”极远。
计算机从此能计算坐标距离来判断语义相似度。
专业定义
Embedding 是将文本映射到高维空间向量的技术。语义越相似,向量夹角越小(余弦相似度越高)。
📌 在 LangChain 中:统一封装各种 Embedding 模型(OpenAI、Cohere、HuggingFace等),用于后续的语义检索。
🔧 补充知识点:向量数据库
比喻
一个专门按语义坐标排书的图书馆。
普通图书馆按书名首字母排序,你要找“和这本书观点相似的其他书”得人工翻半天;向量图书馆里,每本书的位置就是它的语义坐标,你拿一本书站在馆中央,系统一秒就能找出离你最近的那几本。
专业定义
向量数据库(Chroma、Pinecone、Weaviate、PGVector)专门存储 Embedding 向量,并提供高效的近似最近邻搜索(ANN)。
📌 在 LangChain 中:VectorStore 接口对接各类向量库,RAG 流程中的检索环节就在这里发生。
第二层 · 核心模式:RAG(检索增强生成)
4. 开卷考试:RAG
比喻
普通 LLM = 闭卷考试,全靠背诵记忆,没背过的就瞎编。
RAG = 开卷考试,看到题目后先冲到图书馆(知识库)翻到相关段落,夹在卷子里,再动笔作答。
优点:答案有据可查,能回答新知识,大幅减少幻觉。
专业定义
RAG = Retrieve(检索) + Augment(增强) + Generate(生成)
-
用户问题 → Embedding 向量
-
向量数据库检索 Top-K 相关文本块
-
文本块拼入 Prompt → 发给 LLM
-
LLM 参考资料生成最终答案
📌 在 LangChain 中:这是最主流、最成熟的应用模式,LangChain 提供了整套乐高积木。
🔧 补充知识点:文档加载器 & 文本分割器
比喻
-
文档加载器 = 能把 PDF、网页、数据库、PPT 等各种格式的资料统一变成 A4 白纸的工具。
-
文本分割器 = 把整本厚书切成若干篇独立短文,每篇讲一个子主题。切得太碎,上下文丢失;切得太长,容易超 Token 窗口。
专业定义 -
DocumentLoader:从不同源加载文档为 LangChain 标准Document对象。 -
TextSplitter:按字符数、Token 数、递归结构等策略将长文档切块,常用RecursiveCharacterTextSplitter。
📌 在 LangChain 中:这是 RAG 的预处理流水线,直接影响检索质量。
🔧 补充知识点:索引(历史概念)
早期 LangChain 曾将文档、Embedding、检索器封装为 Index 对象,现在已逐渐被 VectorStore + Retriever 取代,但理解其思想仍有帮助——索引就是对知识库的“目录+书签”。
第三层 · 开发框架:LangChain
5. 乐高工具箱:LangChain
比喻
一套专门为 LLM 应用设计的乐高套装。
-
盒子里有各种标准积木:模型调用、提示词模板、检索器、记忆模块……
-
积木接口通用,可以把 OpenAI 积木拔下来,插上 Llama 积木,代码几乎不用改。
-
还配了一本说明书(LCEL 语法),教你如何用
|符号把积木快速拼成流水线。
专业定义
LangChain 是一个开源开发框架,提供组件化、可编排的抽象,用于构建从简单链到复杂代理的 LLM 应用。
📌 生态位置:底座,LangGraph、LangServe、LangSmith 都生长于此。
🔧 核心知识点:LCEL(LangChain Expression Language)
比喻
传统拼接积木要用胶水(Python 代码手写每一步调用),LCEL 则是积木自带的磁吸接口。
你只需要写:chain = prompt | model | output_parser
数据就会自动流过每一块积木,代码极简,且原生支持流式、异步、重试。
专业定义
LCEL 是一种声明式语言,利用 | 管道操作符合并 LangChain 可运行对象(Runnable),底层自动构建执行图。
📌 在 LangChain 中:当前官方首推的链式写法,几乎所有新功能都优先支持 LCEL。
🔧 补充知识点:输出解析器(Output Parser)
比喻
实习生交回来的报告可能是口头大白话,你需要他按表格填写。输出解析器就是那个把口头语转换成结构化 Excel 的转换员。
专业定义OutputParser 将 LLM 的文本输出解析为指定格式(JSON、列表、日期、Pydantic 对象等)。
📌 在 LangChain 中:与 Prompt 配合,一个负责规范指令,一个负责解析结果,共同保证 LLM 输出可用。
🔧 补充知识点:回调(Callback)
比喻
流水线上每个工位都装了一个摄像头+传感器,每当有工件经过、处理完成、出错时,系统就会自动记录日志、发送告警或刷新大屏。
专业定义
回调机制允许你在链/代理执行的各个阶段(开始、结束、出错、流式生成)插入自定义逻辑。
📌 在 LangChain 中:用于日志、监控、LangSmith 追踪、自定义流式输出等。
第四层 · 高级编排:LangGraph 与代理能力
6. 复杂流程图:LangGraph
比喻
普通 LangChain 链是单向传送带,从 A 到 B 到 C,不能回头。
LangGraph 则是一张无限自由的流程图白板——你可以画循环(模型调用工具→拿到结果→再思考→再调工具)、分支(根据情况走不同路径)、甚至多个 AI 角色互相辩论。它更像一个真实的决策大脑。
专业定义
LangGraph 是基于状态图(StateGraph)的编排框架,用于构建有状态、多轮、多代理、可中断恢复的复杂 LLM 应用。
📌 生态位置:逐步取代旧版 AgentExecutor,成为 LangChain 官方主推的代理工作流引擎。
🔧 核心知识点:代理(Agent)
比喻
之前的所有模式,LLM 都只是一个指令执行者,你说一步它动一步。
代理模式则让 LLM 变成了小主管——你给它一个最终目标,它自己思考需要几步、每一步需要调用什么工具、拿到结果后下一步做什么。
专业定义
代理(Agent)利用 LLM 的推理能力,动态决定调用哪些工具以及如何解析工具返回的结果,循环直至任务完成。
📌 在 LangChain 中:LangGraph 是构建自定义代理的最灵活方式,也兼容旧版 Agent 概念。
🔧 核心知识点:工具(Tools)
比喻
给小主管配备的各种专用仪器:计算器(数学)、搜索引擎(查资料)、代码解释器(写代码跑结果)、数据库查询器(取业务数据)。
专业定义
工具是代理可以调用的外部函数,通常包含名称、描述、参数 schema,以及实际执行逻辑。
📌 在 LangChain 中:你可以用 @tool 装饰器快速将任意 Python 函数封装为工具,也可以使用预置工具库(如 TavilySearchResults)。
🔧 核心知识点:记忆(Memory)
比喻
小主管的记事本,记着刚才聊了什么、已经做了哪些步骤、用户偏好的格式。没有记事本,每次对话都是“初次见面”,上下文一片空白。
专业定义
记忆模块负责在多轮对话或代理多步执行中保存、管理、检索历史信息。
📌 在 LangChain 中:BaseMemory 有多种实现(ConversationBufferMemory、ConversationSummaryMemory、VectorStoreRetrieverMemory 等),LangGraph 则通过全局 State 实现更灵活的记忆。
第五层 · 对外服务:LangServe
7. 外卖窗口:LangServe
比喻
你用 LangChain 做了一道拿手好菜(AI 应用),但只能在自己厨房(本地 Python 环境)里尝。
LangServe 就是给这道菜开的外卖窗口——自动生成菜单(API 文档)、接受网上下单(HTTP 请求)、支持外卖小哥实时看到烹饪进度(流式响应)。
专业定义
LangServe 是一个将 LangChain 对象(链、可运行程序)部署为生产级 REST API 的工具,基于 FastAPI,一行代码添加路由,自动处理输入输出校验、OpenAPI 文档。
📌 生态位置:部署层,解决“代码写好了,怎么给别人用”的问题。
第六层 · 观测与迭代:LangSmith
8. 监控与质检:LangSmith
比喻
应用上线后,你不能拍脑袋说“效果还行”。
LangSmith = 全程监控摄像头 + 质检实验室 + 驾驶舱仪表盘。
-
每次运行的所有中间步骤都被录像(追踪),随时回放找 Bug;
-
攒一批测试题,批量跑分(评估),新旧版本哪个好,数据说话;
-
线上流量、错误率、成本实时可见(监控),用户点踩的数据自动回流。
专业定义
LangSmith 是一个 LLM 应用全生命周期管理平台,提供调试追踪、数据集测试、自动化评估、生产监控、人工标注等功能。
📌 生态位置:运维与迭代层,免费额度够用,付费提供企业级私有化。
完整知识体系总览
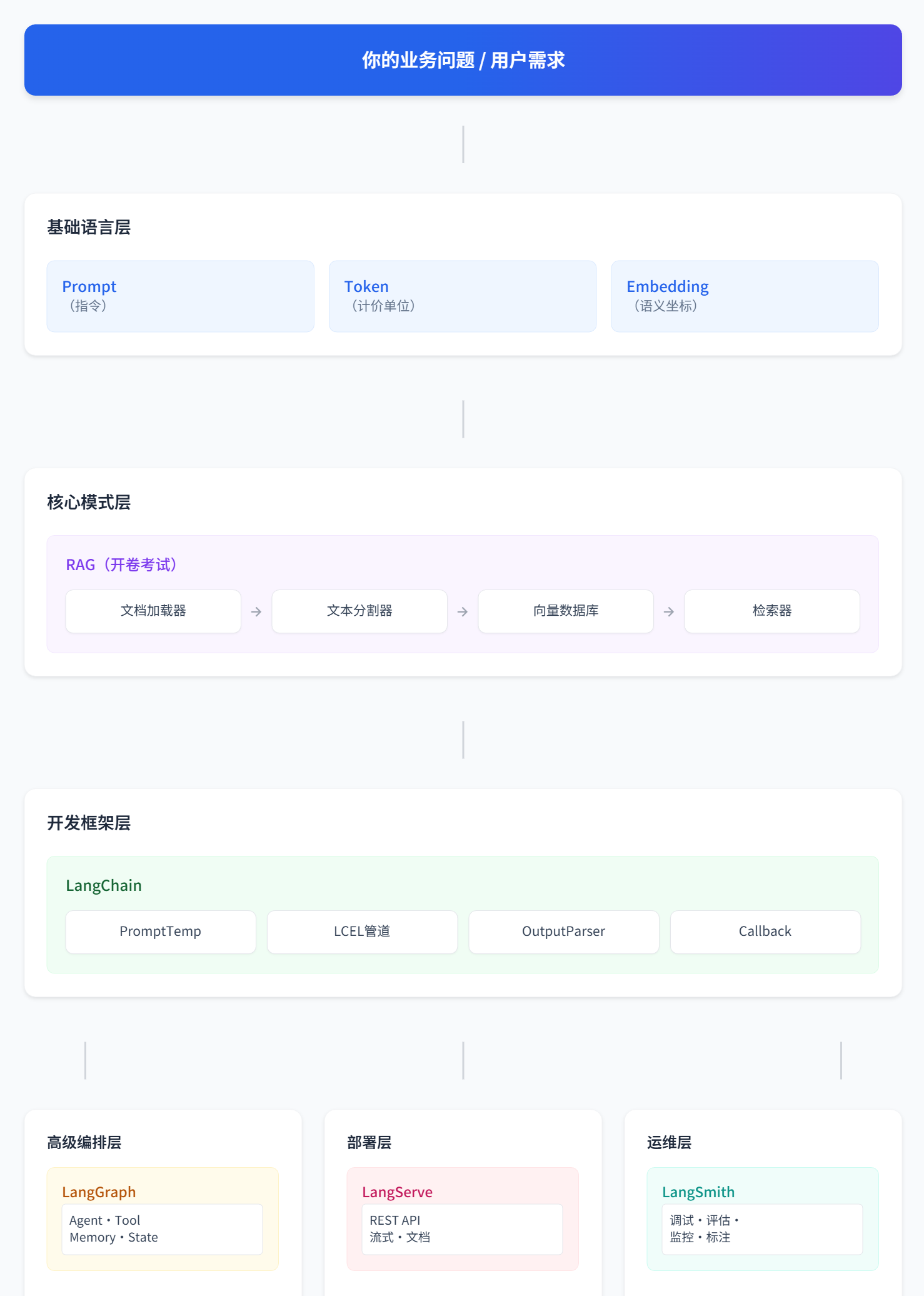
最后的话
你现在手里已经握着整张 LangChain 知识地图。每个概念就像一个岛屿,你不需要一次登陆所有岛——从 RAG 这个最大、最繁华的岛开始,代码写起来了,其他岛自然会出现在你的航线里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)