[深度解读] Yann LeCun 的 JEPA 世界模型
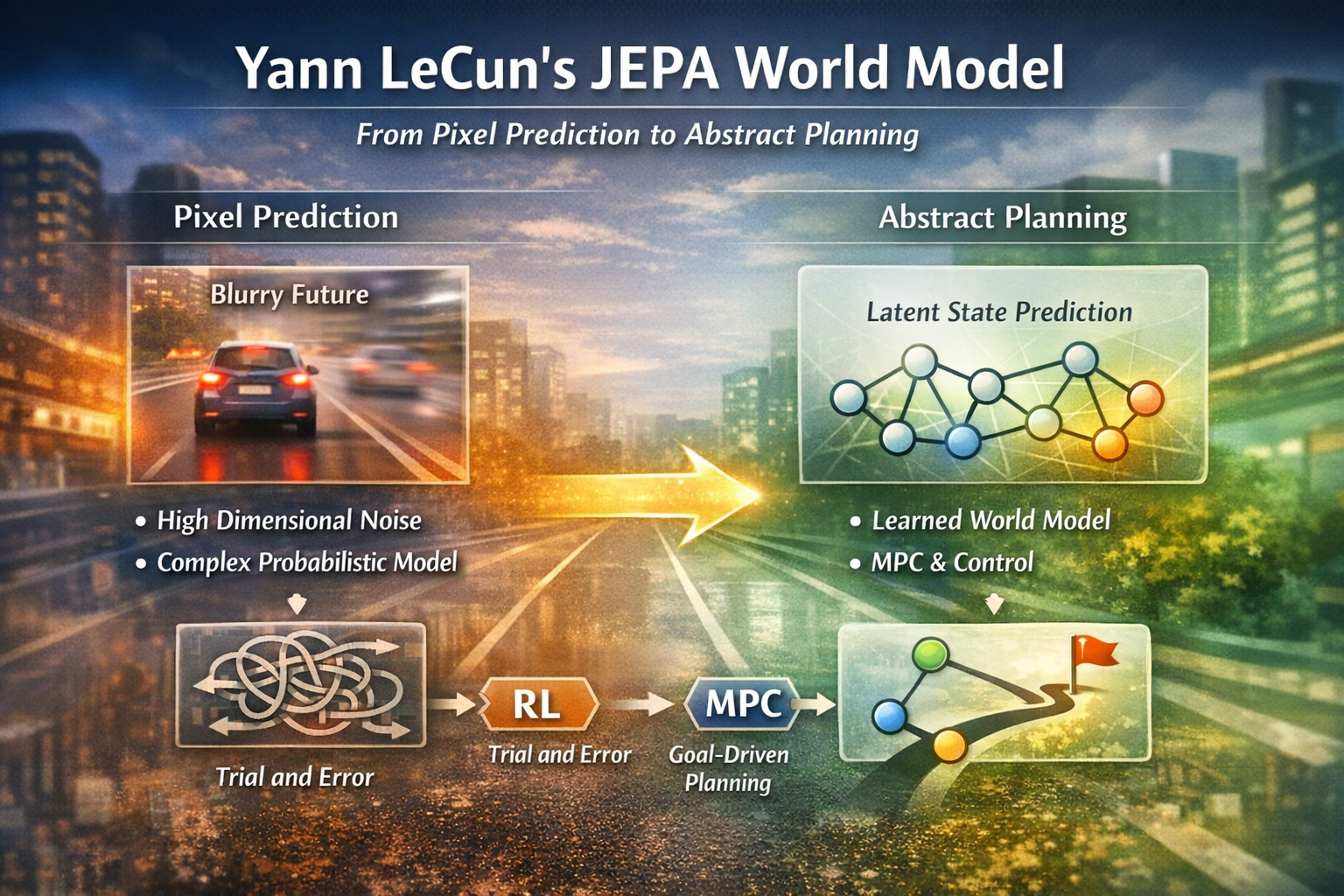
LeCun 在《Training World Models》中主张:世界模型不应追求像素级视频预测,因为真实世界只“部分可预测”,像素空间的高维细节既难以建模又常与决策无关,生成式方法还被迫学习复杂的概率分布与无关细节,导致长时推演不稳定。JEPA 的核心是把预测目标提升到抽象表征空间:对观测 (x) 编码得 (S_x),在给定动作 (a) 时预测未来的表征 (S_y=Pred(S_x,a))。这
Yann LeCun 的 JEPA 世界模型:为什么反对像素级视频预测,以及它如何把“决策”从试错拟合改造成可控规划
本文基于 Yann LeCun 在 World Model Workshop 的 slides《Training World Models》(2026-02-04)进行系统解读,并在此基础上给出一套可复用的工程化理解框架:世界模型(World Model)的核心价值不在“生成未来观测”,而在“在抽象表征空间里推演动作后果,并在目标与约束下选择动作”。
1. 为什么 LeCun 一上来就“炮轰”生成式视频预测?
LeCun 在 slides 中用极强语气写道:“Generative Architectures DO NOT Work for Images and video”,理由集中在四点:世界只部分可预测、预测模型应能表达多种未来、在高维连续域显式概率模型不可 tractable、生成模型必须预测世界每一个细节(包括无关细节)。
这几句话可以翻译成非常工程化的诊断:
- 长期预测的敌人是“细节”:视频/传感器数据的高维细节包含大量不可预测扰动(光照噪声、纹理、动态背景、微小随机事件),这些细节对“决策正确性”往往并非必要,但生成式模型被迫为它们买单。
- 多解未来会让像素级生成不可控地膨胀:你要么输出一个“平均未来”(典型表现为模糊),要么引入潜变量/采样来覆盖多模态未来,但这会把训练、推理与评估都带进更重的概率建模负担。
- 高维连续概率的 tractability 是硬约束:即便忽略“是否能生成得更像”,当你把目标设为“学习真实世界未来分布”,你就进入一个在高维连续域里天然代价极高、难以验证的领域。
LeCun 还用“像素级视频预测会变糊(blurry)”作为直观例子,说明即使做得对,生成目标也容易把模型导向“在均方误差意义下更合理”的平均解,而非可用于决策的抽象结构。
因此,他给出一句非常明确的转向:“My solution: Joint-Embedding Predictive Architecture”。
2. JEPA 的关键切换:从“预测 y”变为“预测 y 的抽象表征”
LeCun 在“Generative vs Joint Embedding”页把分界线画得很清楚:
- Generative:预测的是 y 本身(包含所有细节,含无关细节)。
- Joint Embedding:预测的是 y 的抽象表征(abstract representation)。
- 结论:JEPA 能“抬升抽象层级”,生成式架构不会。
这一页是理解整套 slides 的第一把钥匙。它意味着:
世界模型不该被定义为“未来像素的生成器”,而应被定义为“抽象状态的可预测动力学”。
LeCun 给出的世界模型最简形式化也非常直接:
给定观测 (x),计算其抽象表征 (S_x)。给定动作 (a),预测未来观测 (y) 的抽象表征 (S_y)。并满足:
Sy=Pred(Sx,a) S_y = Pred(S_x, a) Sy=Pred(Sx,a)
这行公式看似简单,但它把整个问题从“生成”转成了“状态空间动力学”:
- Encoder:把观测映射到 latent state(状态表征)。
- Predictor/Dynamics:把“状态 + 动作”映射到“下一状态”。
- 训练信号:在表征空间对齐,而不是在像素空间重建。
3. 表征(Sx, Sy)到底是什么?不是“漂亮的 latent”,而是“可预测的相关变量”
很多读者会立即追问:表征不也是学出来的吗?那它凭什么“抽象”?LeCun 在 slides 里用“传统科学建模”给出答案:
传统科学建模的做法是:寻找一个允许预测的抽象状态表示;从观测/测量中抽取状态向量;预测干预/实验导致的结果。
然后他说出 JEPA 的核心原则:
无关且不可预测的信息会从表征中被消除;表征包含使预测成为可能的信息。
这句话的工程含义非常强:它是在定义一个“表征学习的目标函数方向”——不追求“信息最大化”,而追求“与预测/规划相关的信息保留”。如果把它写成更直白的原则:
- 表征不是越丰富越好;对于长期推演,表征需要“足够”但不需要“过度”。
- 表征需要可预测性;不可预测的成分越多,rollout 漂移越快。
- 表征需要任务相关性(至少是可用于后续目标函数的相关性);否则规划即便准确也无从选择。
这也解释了一个你在阅读时容易产生的“震撼点”:
像素级预测不一定成立;更重要的是,它并不一定是世界模型该优化的目标。
4. 真正的范式切换:从“预测动作”到“评估后果并选择动作”
许多读者第一次接触 world model 会陷入一个误区:世界模型是不是也要像 policy 一样直接输出动作?
LeCun 的系统图明确表明:不是。世界模型的价值在于对动作后果进行推演,然后通过优化/搜索选择动作。
他给出的“规划/推理”循环结构非常典型:使用梯度下降、动态规划、蒙特卡洛树搜索等方法优化动作序列;反复调用 (Pred(s,a)) 推演未来状态;用代价函数 (C(s[t])) 评估轨迹;最终 Actor 只输出第一个动作(或前几个动作)执行。
这一段如果用一句话概括,就是:
动作不是“被预测出来”的,而是“被选择出来”的。
这句话非常关键,因为它把“世界模型路线”与“端到端 policy 路线”的根本差异讲清楚了:
- Policy 路线(System-1):学一个映射 a=π(s)a=\pi(s)a=π(s),一次前向传播给动作。
- World Model 路线(System-2):学一个后果函数 s^t+1=Pred(st,at)\hat s_{t+1}=Pred(s_t,a_t)s^t+1=Pred(st,at),通过推演与优化在轨迹层面选动作。
LeCun 还把“规划/推理系统”的模块拆得很清晰:Perception(表征,可结合记忆)、World Model(推演动作序列)、Task Objective(到目标的差异)、Guardrail Objective(不可违反的安全项)、Operation(寻找最优动作序列)。
5. MPC 是什么?为什么 LeCun 认为世界模型路线天然走向 MPC
在控制与机器人领域,MPC(Model Predictive Control)是一个非常成熟的思想:在每个时刻用模型预测未来若干步,优化一段动作序列,只执行第一步,然后滚动重算。LeCun 的 System-2 图基本就是 MPC 的现代学习版:模型由训练得到(learned world model),代价由目标与约束定义(task + guardrail),求解器用优化或搜索实现。
工程上可以把它写成一个极简闭环:
- 当前观测 (x_t) → 状态表征 st=Enc(xt)s_t = Enc(x_t)st=Enc(xt)
- 枚举/采样候选动作序列 at:t+H−1(i){a^{(i)}_{t:t+H-1}}at:t+H−1(i)
- rollout:s^(i)∗t+k+1=Pred(s^(i)∗t+k,at+k(i))\hat s^{(i)}*{t+k+1} = Pred(\hat s^{(i)}*{t+k}, a^{(i)}_{t+k})s^(i)∗t+k+1=Pred(s^(i)∗t+k,at+k(i))
- 打分:J(i)=∑k=1H(TaskCost(s^t+k)+λ⋅Guardrail(s^t+k))J^{(i)} = \sum_{k=1}^{H} \big(\text{TaskCost}(\hat s_{t+k}) + \lambda \cdot \text{Guardrail}(\hat s_{t+k})\big)J(i)=∑k=1H(TaskCost(s^t+k)+λ⋅Guardrail(s^t+k))
- 选择最优序列,执行第一步动作 (a_t^*),下一时刻重复
这一套机制天然把可控性与安全约束放到系统中心:因为约束是打分函数的一部分,而不是事后修补。
6. “编译 System-2 到 System-1”:从强但慢的规划,到快而可部署的策略
如果读者只看到 MPC,很容易产生一个现实担忧:规划太贵,如何部署?LeCun 直接给出工程落点:Compiling System-2 into System-1,并类比 amortized inference:系统执行 Mode-2(规划)得到最优动作序列,把这些最优动作当作监督目标训练 policy 模块 (A(s));训练好后,policy 可用于 Mode-1 快速反应或用来初始化 Mode-2。
这一段极其关键,因为它给出一个现实世界常用的组合策略:
- 训练/离线阶段:用世界模型 + 规划产生“高质量行为数据”(最优动作序列)。
- 部署/在线阶段:用 policy 快速输出动作;必要时触发规划兜底。
这也解释了为什么在很多系统里,world model 的第二大用途不是“直接控制”,而是“改进 policy 学习”:它提供了一种高质量的行为生成机制。
7. 为什么他要引入 EBM(Energy-Based Model):因为推理与规划本质是优化
LeCun 在“World Models in Psychology”页写得很直接:feed-forward propagation 不足以支持复杂推理;复杂推理需要优化目标;每个计算问题都可约化为优化;这包括所有推理与规划问题。
于是他把整个推理/规划框架置于 EBM 语义之下:通过能量/打分函数表达“什么是好”,再通过优化过程寻找低能量解。
他还明确指出:概率模型是 EBM 的特例,能量类似未归一化的负 log 概率;使用 EBM 的原因是它在打分函数与学习目标的选择上更灵活。
对工程读者来说,这部分最重要的不是“概率与能量谁更哲学”,而是两个直接结论:
- 不必把世界模型绑定到显式概率建模:高维连续域里显式概率会很重。
- 把目标函数(task/guardrail)做成可优化的打分函数:这是让规划可控、可验证的关键。
8. 训练侧的硬问题:塌缩(collapse)与为什么他更偏向 regularized methods
JEPA 属于 joint embedding 家族,这类方法的最大训练风险之一是塌缩(collapse):表征退化成常量,使“对齐” trivially 成立但失去信息。LeCun 在 EBM 架构对比里明确指出:joint embedding architecture CAN COLLAPSE;生成式 latent-variable 架构也可能 collapse;prediction/regression 没有 collapse 问题。
他把 EBM 训练方法分为两类,并强调对比式方法在高维下扩展性差:
- Contrastive methods:压低训练样本能量、抬高对比样本能量,但“scales very badly with dimension”。
- Regularized methods:通过正则最小化可取低能量的空间体积(从结构上限制低能量区域),从而减少塌缩风险。
同时他强调 loss 需要塑造能量面:数据点低能量,数据密度之外高能量。
工程层面可理解为:
当负样本构造成本太高时,用结构与正则把解空间“收紧”是更可规模化的路径。
9. 长时域推演为什么必须分层:Hierarchy 不是装饰,是稳定性的来源
LeCun 明确提出:世界模型应是多层级模型与表征体系。低层做短期预测,保留细节,但不适合长程;高层做长程预测,表征细节更少,但更稳定、更能做准确的长期预测(即使细节更少)。
这条主张直接击中“为什么不做像素级世界模拟”的核心:
长期规划所需的是稳定的抽象变量,而不是逼真的细节渲染。
从工程实践看,分层往往意味着:
- 高层 latent:低频、长时域、任务推进(规划/推理)。
- 低层 latent:高频、短时域、动作执行(控制/追踪)。
并通过蒸馏或分层控制把两者连接起来。
10. 世界模型与 RL(尤其 PPO)的关系:一体两面,但不是同一条路
读者常见的一个直觉是:RL 也是为长时目标提出的,为什么现实里看起来反而“短回路更好用”?这里需要把“目标函数的长时性”与“学习机制的有效性”分开:
- RL(如 PPO)形式化目标确实是最大化长期回报,但在 model-free 设定下,长时域会让 credit assignment、探索与样本效率变得非常困难。
- 世界模型路线试图把长时依赖显式化:用模型 rollout 把未来影响前移到评估环节,把决策变成优化/搜索问题。
因此,更精确的对齐方式是:
- PPO/Policy RL:直接学习策略映射 (a=\pi(s)),适合环境相对稳定、反馈较密、可规模采样的任务。
- World Model + MPC:学习后果函数 (\hat s_{t+1}=Pred(s_t,a_t)),适合强约束、长时域、交互昂贵或危险的任务;并通过蒸馏把规划能力压缩进可部署策略。
LeCun 还在生成式 SSL 页强调:生成式预测适合文本等离散符号序列,但不适合高维连续、带噪数据(图像、视频、传感器、科学测量)。
这进一步强化了他的分工建议:生成式在离散域(文本)很好,连续世界的“可规划模型”应走 JEPA/表征预测路线。
11. 世界模型真正的落地分水岭:Objective / Guardrail 才是核心难点
如果读者只记住一句工程结论,应该是这句:
Pred(s,a) 只提供“如果这样做会怎样”;真正决定系统质量上限的是“怎样算好、怎样算不安全”——也就是 Task Objective 与 Guardrail Objective。
LeCun 在模块化结构里将二者明确区分:Task objective 衡量到 goal 的差异;Guardrail objective 是不可变安全项。
这并非“概念优雅”,而是工程必需:没有 guardrail 的规划系统一旦开始优化,就会系统性寻找漏洞;而“安全约束”如果只靠 reward shaping 或事后规则拦截,往往难以在长时域里稳定工作。
从工程落地角度,Objective/Guardrail 往往来自三类来源(成熟度由低到高):
- 手写目标与约束:最快上线、可控、可审计。
- 学习一个 cost/critic:覆盖隐性目标与复杂风险,减少规则堆叠。
- 偏好学习/反事实学习:当目标难形式化但偏好数据可得时,用 reward model 驱动规划。
注意:这三类并非互斥;现实系统通常是“规则兜底 + learned cost 扩展 + 偏好微调”的组合。
12. 失败模式清单:为什么很多 World Model 系统“论文很美,上线很差”
要让读者对世界模型路线建立正确预期,必须把失败模式讲清楚。以下五类问题最常见,也最致命:
12.1 表征塌缩或表征无效
症状:训练 loss 看起来很漂亮,但 planning 完全无效;不同输入输出几乎同一 latent。
根因:joint embedding 架构天然可能 collapse。
12.2 Planner 钻模型漏洞(model exploitation)
症状:在模型内评估极优,落到真实环境却失败。
根因:模型偏差(model bias)+ 优化器会系统性利用偏差。
应对:短 rollout 优先、真实数据持续校正、对不确定区域降权/拒绝、加入行为先验与约束。
12.3 Objective/Guardrail 定义错误或漂移
症状:模型推演不错,但动作选择仍然不靠谱。
根因:打分函数不等价于真实目标,或部署分布变化导致 cost 失效。
LeCun 将 guardrail 视为“immutable objective terms that ensure safety”,这其实暗示:安全项需要更强的稳定性与可验证性。
12.4 多步 rollout 误差爆炸
症状:一步预测误差可接受,多步 rollout 很快漂移。
根因:误差累积 + 缺少层级抽象与纠偏机制。
LeCun 提出多层级表征与模型正是为长时域稳定性服务。
12.5 计算预算失控
症状:规划质量很好,但延迟与算力不可接受,无法上线。
应对:限制 horizon、限制候选数、用 CEM/采样型 MPC、把规划蒸馏成 policy(System-2 → System-1)。
13. 一个可复用的工程化“决策范式地图”
把整套内容压缩为一张决策选型地图,读者就能快速判断自己该走哪条路线:
13.1 什么时候更偏 Policy RL(如 PPO)
- 环境相对平稳(训练分布≈部署分布)
- 反馈较密或 shaping 容易
- 可规模采样(仿真便宜、交互安全)
- 低延迟强约束(必须毫秒级决策)
13.2 什么时候更偏 World Model + MPC
- 强约束、安全敏感(需要轨迹级 guardrail)
- 长时域、稀疏目标(需要 lookahead)
- 在线交互昂贵/危险(需要用算力换样本)
- 可容忍一定推理成本(或可蒸馏成 policy)
13.3 现实最佳实践:两者组合
- 用世界模型做规划产生高质量行为 → 监督训练 policy(编译 System-2 到 System-1)
- 在线默认 policy 快速输出,遇到高风险/高不确定触发 MPC 兜底
- 用真实反馈持续校正世界模型与 cost(避免自嗨)
14. 结语:LeCun 的 JEPA 不是“另一个模型”,而是一种重组智能体的方式
这组 slides 的价值,不在于提供某个“一键复现”的网络结构,而在于把智能体架构的重心从“生成细节”迁移到“抽象状态 + 目标优化 + 安全约束”:
- 生成式预测在文本等离散符号序列上很强,但对高维连续、噪声数据不适合作为统一范式。
- JEPA把预测目标上移到抽象表征,剔除无关且不可预测的信息,使长期推演更可行。
- 推理与规划被明确归约为“优化目标”的过程,而不是一次前向传播。
- MPC/规划成为动作选择的核心机制:动作不是预测出来的,是在目标与 guardrail 下优化出来的。
- 部署现实通过“编译 System-2 到 System-1”解决:用规划结果训练策略网络,使系统既强又快。
如果说“生成式路线”的胜利叙事是“更像真的未来”,那么 LeCun 的路线叙事是:更像一个会做决定的智能体——它不必画出每一个像素,却能在抽象层推演后果,在安全约束下选择动作,并把规划能力压缩成可部署的策略模块。
附:可直接引用的“核心观点摘录”
- 生成式视频预测作为世界模型主干会被“细节与概率负担”拖垮;JEPA 用抽象表征预测替代像素预测。
- 世界模型的形式化核心是:Sy=Pred(Sx,a)S_y = Pred(S_x, a)Sy=Pred(Sx,a),预测的是未来状态的表征,而不是未来观测本身。
- 动作不是被预测出来的,而是通过 rollout + objective(含 guardrail)被选择出来的;这天然对应 MPC。
- 规划强但慢,因此需要把 System-2 的最优动作蒸馏成 System-1 的策略网络以实现可部署。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)