嵌入式实时系统可靠性与容错设计的深度解析报告:从理论模型到现实世界的生存指南
在当今高度数字化的世界中,嵌入式实时系统(Embedded Real-Time Systems, RTS)构成了现代基础设施的隐形骨架。从控制汽车高速行驶时的防抱死制动系统(ABS),到维持重症监护室病人生病体征的医疗仪器,再到决定火星探测器能否安全着陆的导航计算机,这些系统不仅处理数据,更直接操控物理世界。与通用计算机系统不同,嵌入式实时系统的失效(Failure)往往不只是意味着数据的丢失或画
前言:代码与物理世界的生死契约
在当今高度数字化的世界中,嵌入式实时系统(Embedded Real-Time Systems, RTS)构成了现代基础设施的隐形骨架。从控制汽车高速行驶时的防抱死制动系统(ABS),到维持重症监护室病人生病体征的医疗仪器,再到决定火星探测器能否安全着陆的导航计算机,这些系统不仅处理数据,更直接操控物理世界。与通用计算机系统不同,嵌入式实时系统的失效(Failure)往往不只是意味着数据的丢失或画面的卡顿,而是可能导致财产的巨额损失、环境的灾难性破坏,甚至人类生命的终结 。
第一章 可靠性的基本图谱:定义、范畴与失效的本质
1.1 什么是“失效”?——重新定义系统的死亡
在探讨如何让系统“可靠”之前,必须先精确定义什么是“失效”(Failure)。在讲义的起始部分
,失效被描述为一种可能发生在系统任何部位的事件——从感知外部世界的传感器,到执行物理动作的致动器,再到进行逻辑判断的计算组件 。
在嵌入式系统的语境下,失效并非总是二元的“工作”或“损坏”。它包含了更广泛的频谱:
-
功能性失效:系统无法完成规定的功能,例如按下开关灯不亮。
-
性能失效:系统虽然完成了功能,但未达到性能指标,例如汽车刹车虽然生效了,但制动距离超过了安全标准。
-
时序失效:在实时系统中,正确的动作如果在错误的时间发生,即为失效。例如,安全气囊在碰撞后 5 秒才弹出,虽然它“弹出”了,但对于乘客而言,系统已经彻底失效 。
失效的根源同样多种多样。讲义中列举了包括压力(Stress)、热量(Heat)、电流电压浪涌(Current/Voltage Surges)、软件漏洞(Software Bugs)以及意外的临界输入(Unexpected Critical Inputs)等因素 。这些因素可以被归类为物理层面的硬失效(Hard Failure)和逻辑层面的软失效(Soft Failure)。
讲义第三页展示了失效来源的层级结构。我们可以将其想象为一个倒金字塔:底层是物理环境的压力(如高温导致芯片电子迁移),中层是硬件组件的退化(如电容干涸),顶层则是软件逻辑在特定输入下的崩溃。这种层级关系表明,可靠性是一个跨越物理学、电子学和计算机科学的综合学科。
1.2 时间的随机性:失效时间(Time-to-Failure)
为了量化可靠性,工程学引入了“失效时间”(Time-to-Failure, TTT)的概念
。这是一个随机变量,取值范围通常在 [0,∞)[0, \infty)[0,∞) 。
这里的“时间”是一个广义概念。对于大多数电子设备,它指的是运行时长(小时);但对于汽车,TTT 可能代表行驶里程(公里);对于继电器或键盘按键,TTT 代表的是动作次数(Cycles)。为了统一叙述,本报告主要以“时间”作为度量单位。
在这个框架下,我们不再问“这个设备什么时候坏?”,而是问“这个设备在时间 ttt 之前坏的概率是多少?”。这种思维方式的转变是理解可靠性工程的第一步——从决定论转向概率论。
1.3 核心概率指标:f(t)f(t)f(t)、F(t)F(t)F(t) 与 R(t)R(t)R(t)
为了回答关于寿命的终极问题,数学家们引入了三个核心函数。理解这三个函数的关系,是掌握可靠性分析的关键(Slide 5, 9, 10)。
| 符号 | 名称 | 数学定义 | 物理含义与直觉类比 |
|---|---|---|---|
| f(t)f(t)f(t) | 概率密度函数 (Probability Density Function) | f(t)=dF(t)dtf(t) = \frac{dF(t)}{dt}f(t)=dtdF(t) | “死亡点名册”:它描述了在 ttt 时刻那一瞬间,系统发生失效的密集程度。就像人口统计图中,描述“80岁去世的人口比例”那个波峰。 |
| F(t)F(t)F(t) | 累积失效分布函数 (Cumulative Distribution Function) | F(t)=P(T≤t)=∫0tf(τ)dτF(t) = P(T \le t) = \int_{0}^{t} f(\tau) d\tauF(t)=P(T≤t)=∫0tf(τ)dτ | “死亡名单”:描述了到时间 ttt 为止,总共有多少比例的系统已经失效。它是一个单调递增函数,从 0 增加到 1。F(t)F(t)F(t) 越大,不可靠性越高(Unreliability)。 |
| R(t)R(t)R(t) | 可靠性函数 (Reliability Function) | R(t)=P(T>t)=1−F(t)R(t) = P(T > t) = 1 - F(t)R(t)=P(T>t)=1−F(t) | “生存名单”:描述了系统能活过时间 ttt 的概率。它是一个单调递减函数,从 1(出厂时都是好的)逐渐降到 0(最终都会坏)。 |
深度解析:R(t)R(t)R(t) 与 F(t)F(t)F(t) 的互补关系 指出了 R(t)R(t)R(t) 和 F(t)F(t)F(t) 的互补性质:R(t)+F(t)=1R(t) + F(t) = 1R(t)+F(t)=1 。 这意味着在任何时刻,一个设备要么是“活的”(Reliable),要么是“死的”(Failed)。这听起来是废话,但在系统设计中,我们往往通过计算 F(t)F(t)F(t)(比如计算并联系统中所有组件都失效的概率)来反推 R(t)R(t)R(t),因为计算“全死”往往比计算“至少有一个活”要简单得多。
想象两条曲线在坐标轴上。一条从左上角(1.0)出发,像滑梯一样滑向右下角(0),这是 R(t)R(t)R(t);另一条从左下角(0)出发,像爬坡一样升向右上角(1.0),这是 F(t)F(t)F(t)。它们在任意时间点 ttt 的纵坐标之和永远等于 1。这两条曲线的交点通常代表了系统的中位寿命。
1.4 平均故障时间(MTTF)与方差
除了概率函数,工程师还需要单一数值指标来快速评估系统。
-
MTTF (Mean Time To Failure):即期望寿命 EEE。它是 f(t)f(t)f(t) 的重心,或者是 R(t)R(t)R(t) 曲线下的面积。
MTTF=∫0∞R(t)dt\text{MTTF} = \int_{0}^{\infty} R(t) dtMTTF=∫0∞R(t)dt -
方差 (σ2\sigma^2σ2):描述了失效时间的离散程度

。如果方差很大,说明产品质量参差不齐——有的能用十年,有的明天就坏。对于工业级嵌入式系统,低方差(一致性)往往比高 MTTF 更重要,因为可预测性是维护的基础 。
第二章 瞬时故障率与指数分布:无记忆的咒语
2.1 故障率函数 λ(t)\lambda(t)λ(t) 的物理意义
在可靠性工程中,最容易被误解的概念莫过于故障率(Failure Rate / Hazard Rate),通常记为 λ(t)\lambda(t)λ(t) 或 h(t)h(t)h(t)。 
λ(t)=f(t)R(t)\lambda(t) = \frac{f(t)}{R(t)}λ(t)=R(t)f(t)
为什么不能直接用 f(t)f(t)f(t)?
这是一个极其关键的洞察。
-
f(t)f(t)f(t) 是站在 t=0t=0t=0 的视角看未来。比如,“一个刚出生的婴儿在 80 岁那年去世的概率”是非常低的,因为他首先得活过前 79 年。
-
λ(t)\lambda(t)λ(t) 是站在 ttt 时刻的视角看当下。它问的是:“假设该组件已经成功活到了时间 ttt,那么它在下一瞬间(t+Δtt + \Delta tt+Δt)立即失效的概率密度是多少?”
直观类比:人类的死亡率
对于一个 100 岁的老人:
-
f(100)f(100)f(100) 很小:因为 100 年前出生的人里,极少有人能活到今天。
-
λ(100)\lambda(100)λ(100) 很大:因为对于一个已经 100 岁的老人来说,他在接下来一年内去世的风险极高。
λ(t)\lambda(t)λ(t) 衡量的是“当下的危险程度”,或者说是“死神收割幸存者的速度”。
2.2 常数故障率(CFR)模型
在电子嵌入式系统中,最常用的假设是**常数故障率(Constant Failure Rate, CFR)**模型,即 λ(t)=λ\lambda(t) = \lambdaλ(t)=λ(常数)。
这意味着,不管设备已经运行了多久,它在下一秒失效的概率始终不变。
基于 λ(t)=λ\lambda(t) = \lambdaλ(t)=λ,我们可以推导出可靠性函数
:
R(t)=e−λtR(t) = e^{-\lambda t}R(t)=e−λt
这就是著名的指数分布(Exponential Distribution)。
2.3 无记忆性(Memoryless Property):电子元件的永葆青春
指数分布拥有一个独特的性质——无记忆性
。 数学表达为:
P(T>t+s∣T>t)=P(T>s)P(T > t + s | T > t) = P(T > s)P(T>t+s∣T>t)=P(T>s)
深度解析与案例:光通用的错觉
想象你在等公交车。如果公交车的到来服从指数分布(虽然现实中不完全是),那么不管你已经等了 10 分钟还是 1 小时,你“还需要再等 5 分钟”的概率是一模一样的。过去等待的时间就像没发生过一样,不会增加公交车下一秒出现的概率。
在嵌入式硬件中,这个性质解释了为什么许多电子元器件(如电阻、电容、半导体芯片)在正常使用期内被视为“永远年轻”。
-
案例:一个连续运行了 5 年的服务器 CPU,和一个刚拆封的全新 CPU。如果它们都处于正常工作环境且未进入磨损期,那么它们在明天烧毁的概率是相同的。
-
原因:电子元件的失效通常由随机的外部事件触发(如宇宙射线导致的单粒子翻转、随机的电压尖峰),而不是内部的机械累积损伤。既然是随机“意外”,那么之前没出意外并不代表之后更容易出意外,反之亦然。
警告:无记忆性只适用于电子元件的“正常寿命期”。一旦进入“磨损期”(如电解电容电解液干涸、芯片内部电迁移导致导线变细),无记忆性失效,故障率 λ(t)\lambda(t)λ(t) 会迅速上升。
2.4 案例计算:多核系统的生存概率



场景:一个多核 CPU 系统,其中单个核心的寿命 TTT 服从指数分布,故障率 λ=0.2\lambda = 0.2λ=0.2(假设单位是每小时,虽然这个数值对于现代 CPU 过大,仅做教学示例)。
问题:该核心在第 2 小时内(即 1<T<21 < T < 21<T<2)失效的概率是多少?
计算过程:
-
概率密度函数:f(t)=0.2e−0.2tf(t) = 0.2 e^{-0.2t}f(t)=0.2e−0.2t
-
积分计算:
P(1<T<2)=∫120.2e−0.2tdt=e−0.2−e−0.4≈0.8187−0.6703=0.1484P(1 < T < 2) = \int_{1}^{2} 0.2 e^{-0.2t} dt = e^{-0.2} - e^{-0.4} \approx 0.8187 - 0.6703 = 0.1484P(1<T<2)=∫120.2e−0.2tdt=e−0.2−e−0.4≈0.8187−0.6703=0.1484 -
结论:该核心有约 14.8% 的概率在第 1 到第 2 小时之间失效。
这个例子展示了如何利用 f(t)f(t)f(t) 直接计算特定时间段内的风险。对于嵌入式系统设计者,这种计算用于评估关键任务(如火箭发射后的最初几分钟)的成功率。
第三章 威布尔分布与浴缸曲线:描述真实的一生
虽然指数分布(CFR)简化了计算,但现实世界是复杂的。大多数产品的一生并非总是保持恒定的故障率。这就引出了更通用的模型——威布尔分布(Weibull Distribution)和浴缸曲线(Bathtub Curve)。
3.1 浴缸曲线:从摇篮到坟墓
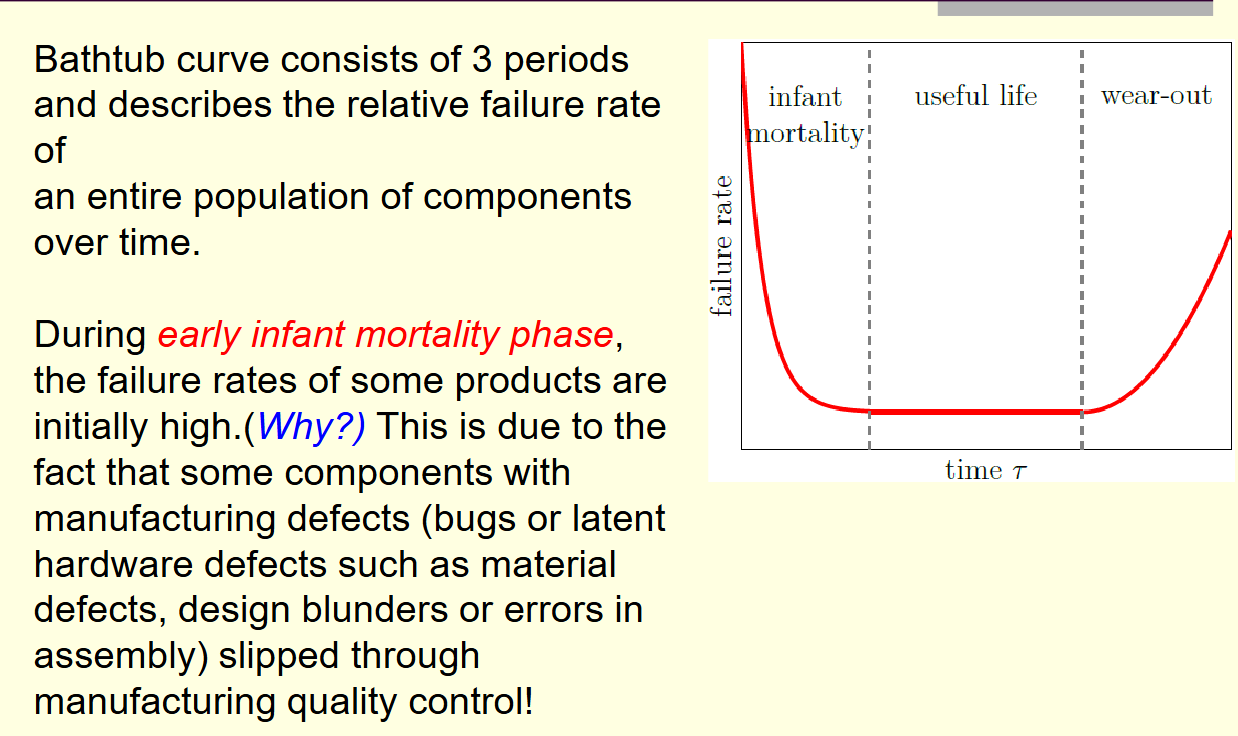

它描绘了产品生命周期中故障率 λ(t)\lambda(t)λ(t) 的三个典型阶段 。
| 阶段 | 英文名称 | 故障率趋势 | 现实世界的解释与应对策略 |
|---|---|---|---|
| 第一阶段 | Infant Mortality (婴儿夭折期) | 递减 (DFR) | 特征:产品刚出厂时故障率极高,但随时间迅速下降。 原因:制造缺陷、焊接不良、材料杂质、安装错误。就像新生儿免疫系统未建立,容易夭折。 嵌入式策略:老化测试 (Burn-in)。在出厂前,让设备在高温高压下运行一段时间。目的是让那些注定要死在“婴儿期”的次品在工厂里就坏掉,而不是到了客户手里才坏。熬过这段时间的幸存者,就是健康的“壮年”设备。 |
| 第二阶段 | Useful Life (正常寿命期) | 常数 (CFR) | 特征:故障率低且恒定,曲线平坦。 原因:制造缺陷已被剔除,磨损尚未开始。失效主要由随机的外部应力(Stress)引起,如雷击、操作失误、意外跌落。 嵌入式策略:这是系统设计的核心区域,适用指数分布模型。设计目标是尽可能延长这一阶段,并在此期间提供随机故障的容错机制(如冗余备份)。 |
| 第三阶段 | Wear-out (磨损期) | 递增 (IFR) | 特征:故障率随时间急剧上升。 原因:物理老化。绝缘层氧化、机械部件疲劳、焊点裂纹、电池化学物质耗尽。 嵌入式策略:预防性维护 (Preventive Maintenance)。在进入此阶段前更换设备。对于无法维护的系统(如卫星),这意味着任务寿命的终结。 |
3.2 威布尔分布:数学界的“变形金刚”



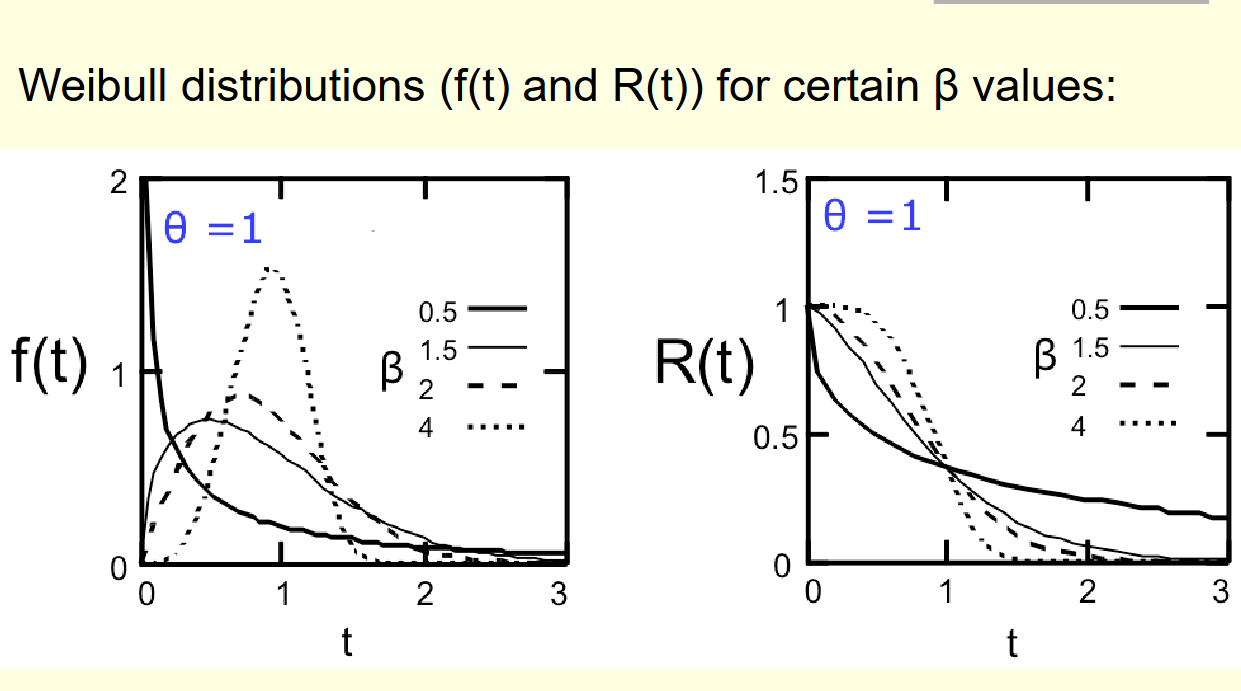
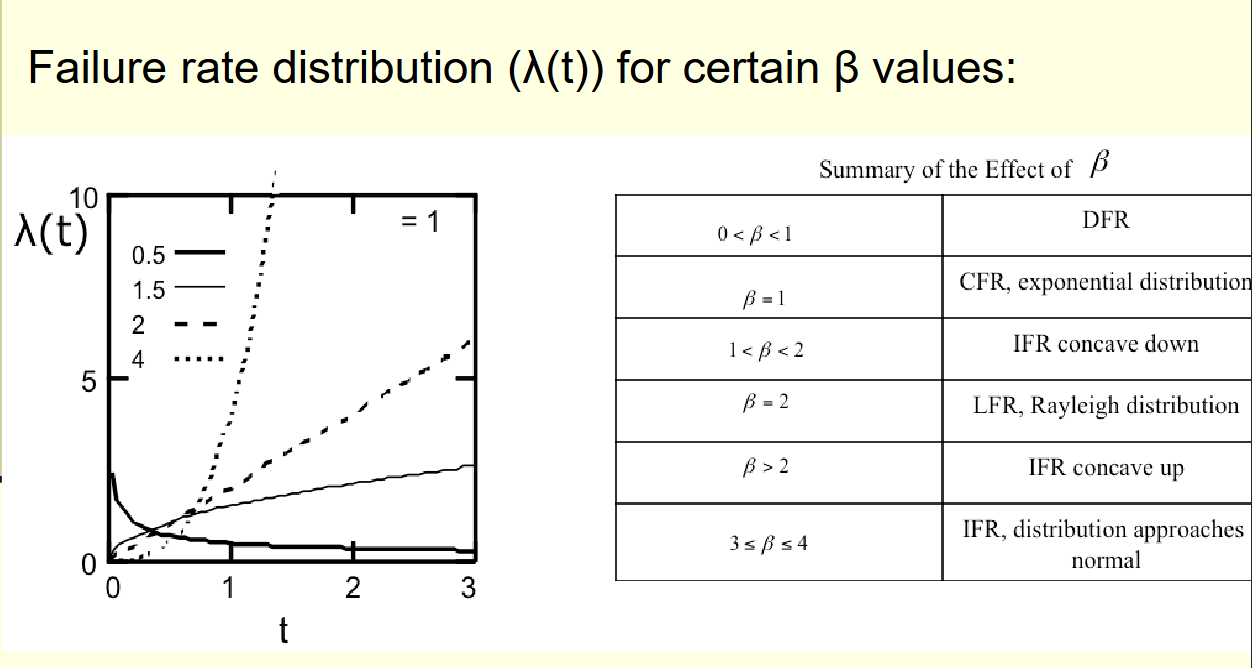
为了用一个统一的数学公式描述上述三个截然不同的阶段,工程师使用了威布尔分布。 其核心在于形状参数 β\betaβ (Shape Parameter),它像一个旋钮,决定了故障率曲线的走向 。
λ(t)=βθ(tθ)β−1\lambda(t) = \frac{\beta}{\theta} (\frac{t}{\theta})^{\beta-1}λ(t)=θβ(θt)β−1
-
当 β<1\beta < 1β<1 时:故障率随时间下降。
- 含义:系统“越用越结实”。这精确描述了婴儿夭折期。随着时间推移,次品被淘汰,剩下的都是高质量产品。
-
当 β=1\beta = 1β=1 时:故障率是常数。
- 含义:威布尔分布退化为指数分布。公式变为 λ(t)=1/θ=const\lambda(t) = 1/\theta = \text{const}λ(t)=1/θ=const。这描述了正常寿命期。
-
当 β>1\beta > 1β>1 时:故障率随时间上升。
- 含义:系统“越用越脆弱”。这描述了磨损期。β\betaβ 值越大,磨损越剧烈(如机械疲劳通常 β≈3∼4\beta \approx 3\sim4β≈3∼4)。
讲义展示了一组不同 β\betaβ 值的曲线。可以看到,通过调整 β\betaβ,威布尔分布可以模拟浴缸曲线的左端(下滑线)、中间(水平线)和右端(上扬线)。这种灵活性使其成为可靠性工程中最强大的建模工具。
3.3 现实案例:为什么硬盘总是坏在保修期外?
通过浴缸曲线和威布尔分布,我们可以理解厂商制定保修期的逻辑。厂商通常会将保修期设定在“正常寿命期”的末尾,即“磨损期”开始之前。
-
如果在“婴儿期”坏了,厂商通过退换货处理(通常比例不高,因为有出厂老化测试)。
-
如果在“正常寿命期”坏了,这是随机小概率事件,厂商承担得起。
-
一旦进入“磨损期”(β>1\beta > 1β>1),故障率指数级上升。厂商通过数据分析精确计算出这个时间点(例如 3 年),并在此之前结束保修,从而规避了大规模赔付的风险。这并非阴谋,而是统计学的应用。
第四章 系统级可靠性:从孤岛到整体
单个组件的可靠性是基础,但现代嵌入式系统是由成千上万个组件构成的复杂网络。如何计算整体的可靠性?这取决于组件之间的连接逻辑


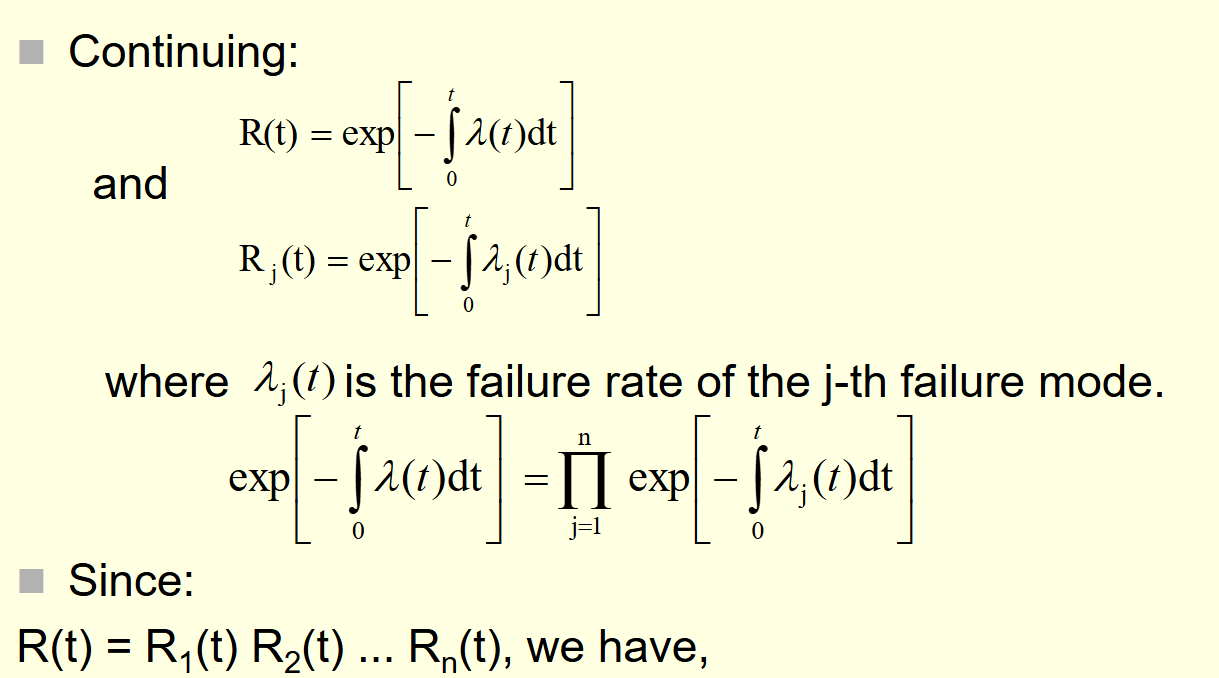

4.1 串联系统 (Series System):短板效应的极致
在串联系统中,任何一个组件的失效都会导致整个系统的失效。这是最脆弱的结构,也是最常见的设计陷阱 。
-
逻辑:系统正常 = 组件A正常 AND 组件B正常 AND…
-
可靠性公式:
Rsystem(t)=R1(t)×R2(t)×...×Rn(t)R_{system}(t) = R_1(t) \times R_2(t) \times... \times R_n(t)Rsystem(t)=R1(t)×R2(t)×...×Rn(t) -
故障率叠加:在指数分布假设下,串联系统的总故障率是所有组件故障率之和。
λsystem=λ1+λ2+...+λn\lambda_{system} = \lambda_1 + \lambda_2 +... + \lambda_nλsystem=λ1+λ2+...+λn
残酷的现实案例: 假设一个系统由 100 个组件组成,每个组件的可靠性都高达 99.9%(已经非常优秀)。 系统的可靠性 = 0.999100≈0.9050.999^{100} \approx 0.9050.999100≈0.905。 如果组件增加到 1000 个,系统可靠性将暴跌至 36.736.7%36.7。 这就是为什么复杂的嵌入式软件(包含数百万行代码)如此难以保持稳定——每一行代码都在逻辑上与其他代码串联,任何一个微小的 Bug(如丰田汽车刹车系统中的一个变量溢出)都可能导致系统崩溃 。
4.2 并联系统 (Parallel System):冗余的力量
为了对抗串联系统的脆弱性,工程师引入了并联系统,即冗余(Redundancy)。 在并联系统中,只有当所有组件都失效时,系统才失效。只要有一个组件活着,系统就能运行 。
-
逻辑:系统正常 = 组件A正常 OR 组件B正常 OR…
-
不可靠性公式(计算失效概率更容易):
Fsystem(t)=F1(t)×F2(t)×...×Fn(t)F_{system}(t) = F_1(t) \times F_2(t) \times... \times F_n(t)Fsystem(t)=F1(t)×F2(t)×...×Fn(t)
Rsystem(t)=1−∏i=1n(1−Ri(t))R_{system}(t) = 1 - \prod_{i=1}^{n} (1 - R_i(t))Rsystem(t)=1−i=1∏n(1−Ri(t))
冗余的魔力:
假设两个组件 A 和 B,可靠性都是 90%(R=0.9,F=0.1R=0.9, F=0.1R=0.9,F=0.1)。
-
串联:可靠性 0.9×0.9=0.810.9 \times 0.9 = 0.810.9×0.9=0.81(降低了)。
-
并联:失效概率 0.1×0.1=0.010.1 \times 0.1 = 0.010.1×0.1=0.01。可靠性 1−0.01=0.991 - 0.01 = 0.991−0.01=0.99(显著提升!)。
通过简单的复制,我们将一个平庸的系统(90%)变成了高可靠系统(99%)。
4.3 K-out-of-N 系统:民主与鲁棒性的平衡
现实中,全并联(1-out-of-N)往往过于昂贵或技术上不可行。例如,一架四引擎飞机,虽然一个引擎也能飞,但可能飞不远。更常见的模型是 K-out-of-N:在 N 个组件中,至少有 K 个正常工作,系统才能成功 。
-
案例:航天飞机的计算机
航天飞机使用 5 台计算机。其中 4 台运行相同的软件,进行多数表决(Voting)。只要有 3 台(3-out-of-4)达成一致,就执行指令。这种设计既利用了冗余,又引入了“表决机制”来屏蔽错误数据的干扰。 -
案例:RAID 5 存储系统
由 N 块硬盘组成,数据和校验信息分散存储。允许任意 1 块硬盘损坏((N−1)(N-1)(N−1)-out-of-NNN),数据依然完整。但如果坏 2 块,数据就丢了。
计算复杂度:
K-out-of-N 系统的可靠性计算涉及二项分布累加。
Rsystem=∑i=kn(ni)Ri(1−R)n−iR_{system} = \sum_{i=k}^{n} \binom{n}{i} R^i (1-R)^{n-i}Rsystem=i=k∑n(in)Ri(1−R)n−i
这体现了工程设计中的权衡(Trade-off):增加 NNN 可以提高可靠性,但同时也增加了成本、重量和功耗(SWaP - Size, Weight and Power)。
第五章 状态依赖系统与马尔可夫分析:动态修复的艺术
当系统具有修复能力(Repairable Systems)或者组件之间存在复杂的依赖关系时(例如,备用组件只有在主组件坏了之后才启动,存在切换延迟),简单的串并联公式就失效了。这时,我们需要更强大的工具——马尔可夫模型(Markov Models)。
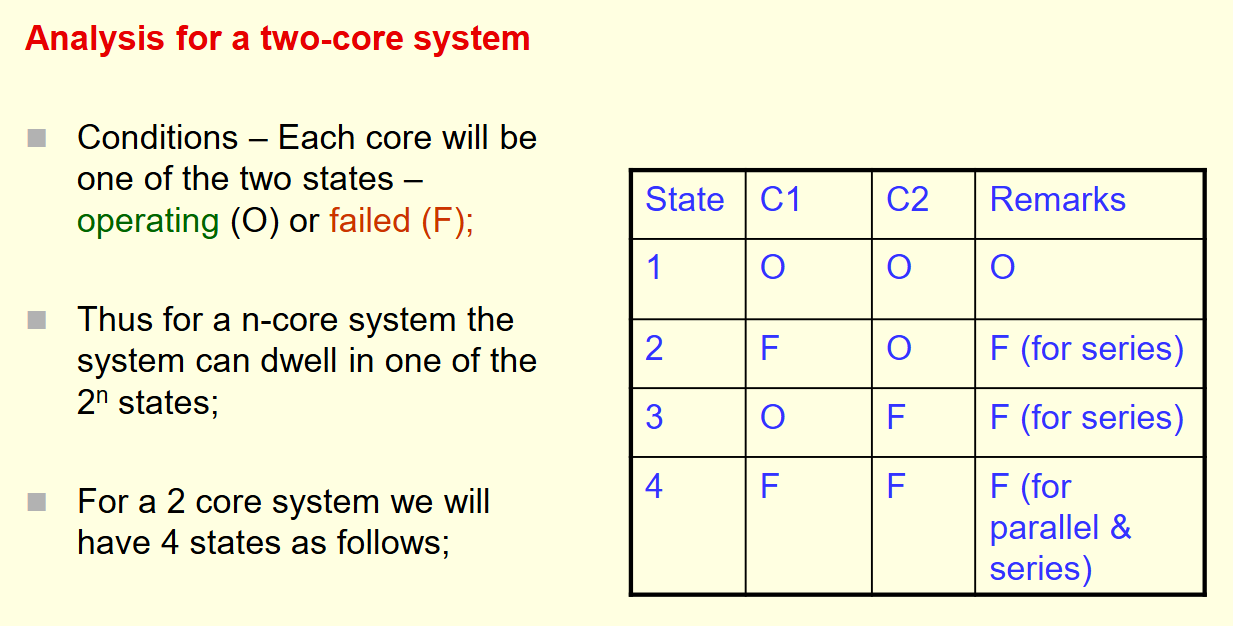


在这里插入图片描述


5.1 马尔可夫链的核心思想
马尔可夫模型将系统抽象为一系列状态(States)和状态转移(Transitions)。 核心假设依然是无记忆性:系统下一刻变成什么状态,只取决于当前处于什么状态,与它是怎么变成当前状态的无关 。
讲义展示了一个双组件系统的状态转移图。圆圈代表状态,箭头代表转移。
-
状态 1 (2 Good):两个组件都好。
-
状态 2 (1 Failed):坏了一个。
-
状态 3 (System Failed):两个都坏了,系统崩溃。
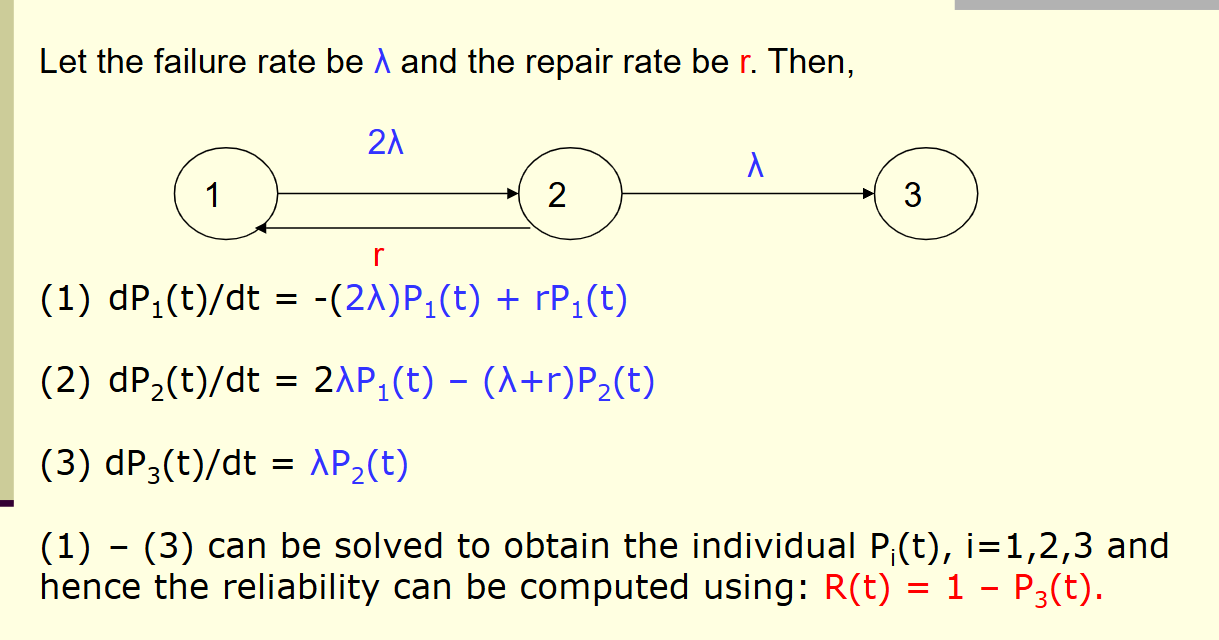
5.2 引入维修率(Repair Rate, μ\muμ 或 rrr)
在不可修复系统中,状态只能从“好”流向“坏”,像水往低处流。
但在可修复系统中,我们引入了维修率 μ\muμ,这是逆流而上的力量。
微分方程组的构建:
通过分析流入和流出每个状态的概率流,我们可以建立一组微分方程。
以状态 2(坏了一个)为例:
-
流入:从状态 1 坏一个进来(速率 2λ2\lambda2λ)。
-
流出:
-
又坏了一个,去往状态 3(速率 λ\lambdaλ)。
-
修好了这一个,回到状态 1(速率 μ\muμ)。
-
dP2(t)dt=2λP1(t)−(λ+μ)P2(t)\frac{dP_2(t)}{dt} = 2\lambda P_1(t) - (\lambda + \mu) P_2(t)dtdP2(t)=2λP1(t)−(λ+μ)P2(t)
这个方程不仅是数学符号,它揭示了运维的本质:系统的稳定性是“失效速度”与“修复速度”博弈的动态平衡。
5.3 案例:为什么重启能解决 90% 的问题?
马尔可夫模型告诉我们,如果要提高系统的可用性(Availability,即系统处于工作状态的概率),有两种路径:
-
降低 λ\lambdaλ(买更贵的硬件,写更好的代码)。
-
提高 μ\muμ(修得更快)。
在现实中,将 λ\lambdaλ 降低一倍可能需要数百万美元的研发投入。但通过设计良好的看门狗定时器(Watchdog Timer)实现自动重启,或者采用热插拔技术,可以将 μ\muμ 提高几个数量级(从人工维修的几小时缩短到自动重启的几秒)。
这就是为什么现代嵌入式系统(如云服务器、路由器)极其强调可恢复性(Recoverability)。一个经常出错但能在毫秒级恢复的系统,往往比一个很少出错但一出错就停机几天的系统更可靠。
真实场景映射:
-
汽车 ECU:当检测到软件死锁时,看门狗强制复位微控制器。这是马尔可夫图中从“故障态”瞬间跳回“初始态”的体现。
-
数据中心:Kubernetes 集群中,当一个 Pod 挂掉(λ\lambdaλ 事件),系统自动拉起一个新的 Pod(μ\muμ 事件),维持了服务的高可用。
第六章 软件与硬件可靠性的殊途同归
在嵌入式系统中,软件和硬件紧密耦合,但它们的失效逻辑有着本质区别。
6.1 软件失效的独特性
| 特征 | 硬件失效 | 软件失效 |
|---|---|---|
| 根本原因 | 物理退化、制造缺陷、环境压力 | 设计错误(Bug)、需求模糊、复杂性 |
| 时间特性 | 浴缸曲线(有磨损期) | 无磨损。软件不会因为运行久了而“生锈” |
| 冗余效果 | 有效。备用硬件可以接管工作。 | 无效(同构冗余)。如果主系统因 Bug 崩溃,备用系统运行同样的代码,会在同样的输入下同时崩溃。 |
| 修复方式 | 更换部件 | 打补丁(Patch)或重启 |
6.2 经典灾难案例分析:当软件杀死系统
案例一:阿丽亚娜 5 号 (Ariane 5) —— 昂贵的整数溢出
1996年,欧洲航天局的 Ariane 5 火箭在发射 37 秒后自毁 。
-
故障复盘:惯性基准系统(SRI)试图将一个 64 位浮点数(水平偏差)转换为 16 位有符号整数。由于 Ariane 5 的速度比前代 Ariane 4 快得多,该数值超过了 16 位整数的上限(32767),导致整数溢出异常。
-
容错设计的失败:系统设计了双重冗余(SRI-1 和 SRI-2)。这本该是并联系统。然而,由于两个 SRI 运行的是完全相同的软件(同构冗余),SRI-1 崩溃后,切换到 SRI-2,SRI-2 在接收到相同传感器数据的那一瞬间也发生了同样的溢出崩溃。
-
教训:对于软件,同构冗余是零冗余。真正的可靠性需要N版本编程(N-Version Programming),即让两个团队用两种语言(如 Ada 和 C)分别实现同一功能,以避免共因故障(Common Mode Failure)。
案例二:火星探路者号 (Mars Pathfinder) —— 隐蔽的优先级反转
1997年,火星探路者号登陆火星后频繁发生系统重启 。
-
故障复盘:这是一个经典的**优先级反转(Priority Inversion)**问题。
-
一个低优先级任务(气象数据采集)获取了总线互斥锁。
-
一个高优先级任务(总线管理)试图获取该锁,被迫等待。
-
此时,一个中优先级任务(通信)抢占了 CPU,导致低优先级任务无法运行,锁迟迟无法释放。
-
高优先级任务超时,看门狗判定系统死锁,触发全局重启。
-
-
修复:NASA 工程师通过从地球发送补丁,开启了 VxWorks 操作系统中的**优先级继承(Priority Inheritance)**功能,解决了这个问题。
-
启示:嵌入式实时系统的可靠性不仅关乎代码逻辑正确,更关乎时间确定性(Temporal Determinism)。
案例三:丰田汽车暴冲门 —— 堆栈溢出的梦魇
2000年代,丰田汽车因意外加速导致大规模召回。NASA 的调查发现其代码中存在大量违反 MISRA-C 标准的写法,包括滥用全局变量和深层递归,最终导致堆栈溢出(Stack Overflow),使得 CPU 的程序计数器(PC)乱跳,绕过了刹车优先逻辑 。 这再次证明,在嵌入式系统中,代码质量就是安全屏障。
第七章 迈向可靠性感知的系统设计
基于上述理论与教训,讲义提出了**可靠性感知设计(Reliability-Aware Design)**的理念。这不是事后的补救,而是在设计阶段就将可靠性纳入核心约束。
7.1 异构计算与容错架构
为了解决 Ariane 5 的同构失效问题,现代关键系统(如波音 777 飞控)采用了异构计算。
-
硬件异构:使用不同厂商的 CPU(如 Intel + AMD + ARM),防止特定批次的硬件缺陷。
-
软件异构:不同团队开发,甚至使用形式化验证(Formal Verification)来从数学上证明代码的正确性。
7.2 动态规划与成本优化
讲义最后提到的“Cost Constraints”是一个现实问题。我们不能无限制地增加冗余。 工程师使用**动态规划(Dynamic Programming)**算法,在给定的成本(或重量、功耗)预算下,寻找最优的冗余组合 。
-
问题模型:我有 100 美元预算,应该给 CPU 加个备份,还是给电源加个备份?
-
决策依据:看哪个组件的 λ\lambdaλ 最高,且并联后的可靠性增益(Marginal Gain)最大。这实际上是一个背包问题(Knapsack Problem)的变种。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)