开源世界模型的探索和调研
JEPA用于构建用于物理世界的推理型世界模型JEPA是杨立昆提出的AI架构,联合嵌入预测架构(Joint Embedding Predictive Architecture)。JEPA不直接在像素或词(token)空间进行预测和生成,在更高层、抽象潜在表示空间中进行预测。JEPA包含两个主要部分:Encoder和Predictor,Encoder负责将输入数据,比如一段视频的两帧图像,分别映射到两
LLM语言模型解决的是语义层面的压缩和推理,预测下一个 token。
世界模型解决更根本的问题,真正理解时间与空间,并预测下一帧、下一个行动。
世界模型在交互性、实时性、长时记忆和物理合理性这四点上都需要更进一步。
这里对已有世界模型进行调研和探索。
V-JEPA 2
github项目链接如下
https://github.com/facebookresearch/vjepa2
内容介绍
JEPA用于构建用于物理世界的推理型世界模型
JEPA是杨立昆提出的AI架构,联合嵌入预测架构(Joint Embedding Predictive Architecture) 。
JEPA不直接在像素或词(token)空间进行预测和生成,在更高层、抽象潜在表示空间中进行预测。
JEPA包含两个主要部分:Encoder和Predictor,Encoder负责将输入数据,比如一段视频的两帧图像,分别映射到两个潜在向量。预测器则负责根据其中一个潜在向量(代表“源”视图),来预测另一个潜在向量(代表“目标”视图)。
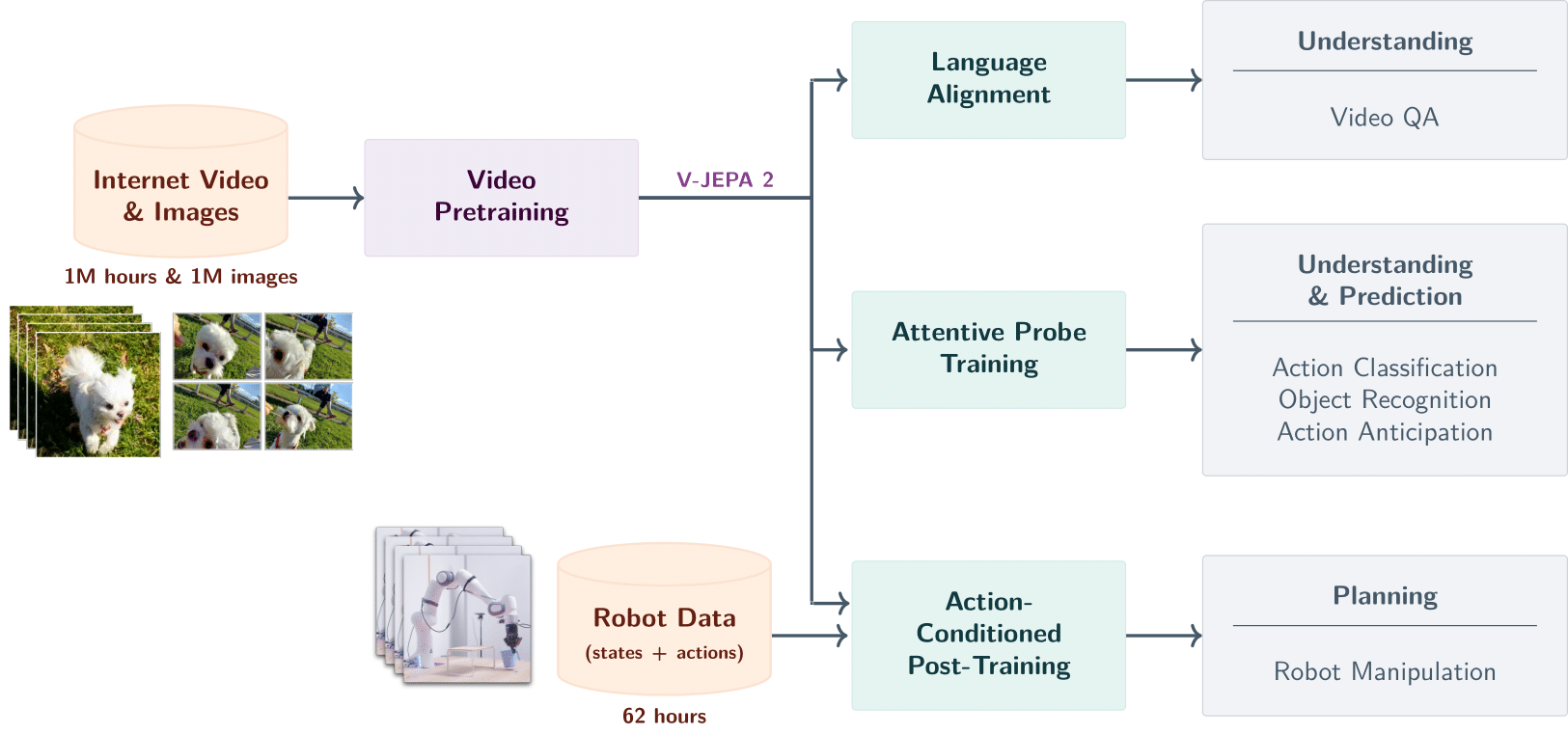
V-JEPA 2进一步聚焦于世界模型的预测与规划能力,目标是让AI在真实物理环境中进行高效决策,服务于机器人控制、自动驾驶等任务。
优势
V-JEPA 2支持长时程规划(Long Horizon Planning),如机器人抓取、避障行走;
实验表明其规划速度比基于扩散的Cosmos快15倍以上。
V-JEPA 2支持Action Classification、Object Recognition、Action Anticipation、Video QA等下游任务,表明其学习到了丰富的物理规律与因果结构。
模型轻量,可在边缘设别部署,支持WebAssembly,便于集成至浏览器或机器人控制系统。
LargeWorldModel
github项目链接如下
https://github.com/LargeWorldModel/lwm
内容
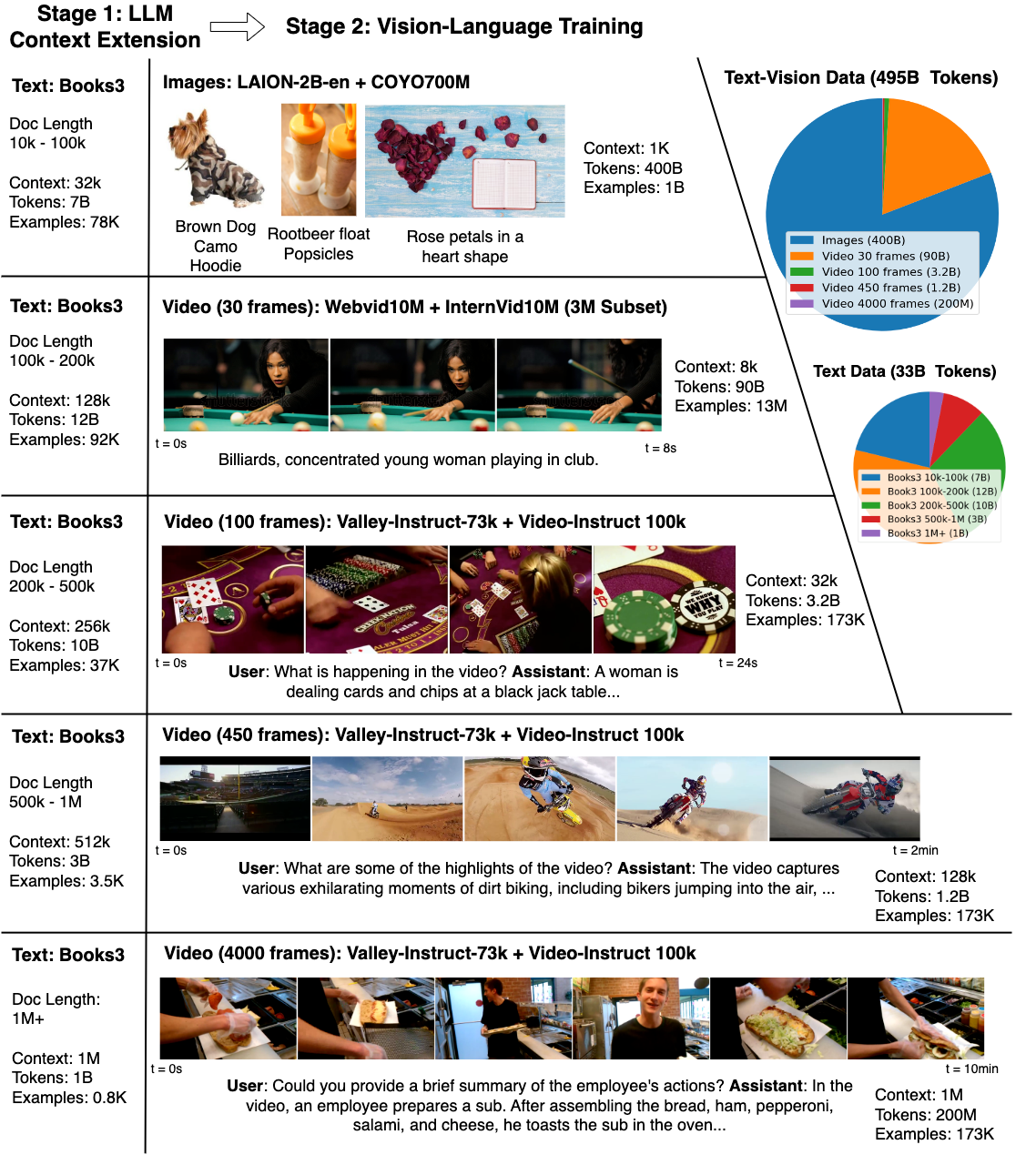
Large World Model (LWM)是一种通用的大上下文多模态自回归模型。
LWM基于 Transformer架构,并通过RingAttention扩展了处理长序列的能力。
在大量多样化长视频和书籍数据上进行训练,能够实现语言、图像和视频的理解与生成。
优势
LWM有如下优势
1)大上下文处理能力
支持处理长序列数据(如长时间视频或长文档),适合需要大量上下文信息的任务。
2)多模态能力
同时支持文本、图像和视频的输入与输出,能够进行跨模态的理解和生成。
3)高效训练技术
使用 RingAttention(一种高效的注意力机制扩展技术)来优化长序列训练,降低计算成本。
4) 广泛的应用场景
适用于视频分析、长文档理解、跨模态生成(如视频描述、故事生成等)任务。
WoW
以下是github项目链接
https://github.com/wow-world-model/wow-world-model
内容
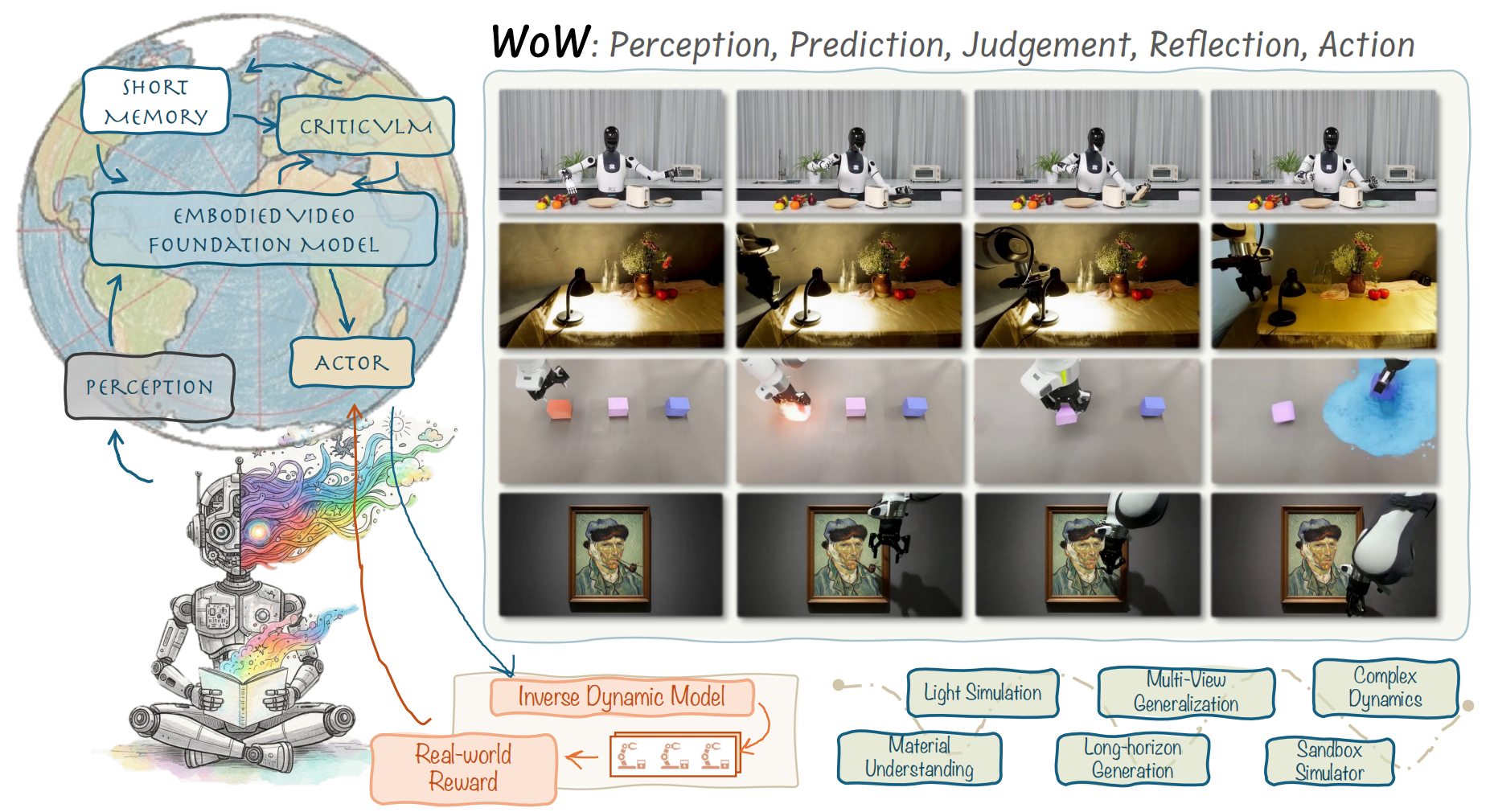
WoW拥有140亿参数的生成式世界模型,通过200万个真实机器人互动轨迹进行训练的。
训练数据涵盖了5275个不同任务和12种不同类型机器人,模型通过体验无数次物理互动,真正学会了重力、碰撞、惯性等物理定律。
其SOPHIA框架(Self-Optimizing Predictive Hallucination Improving Agent),当生成一个预测视频时,框架仔细检查视频是否符合物理规律,发现问题后会给出具体的修改建议,让模型重新生成更合理的视频,类似于强化学习的过程。
其建立WoWBench基准测试,包含606个测试样本。其实验结果显示,WoW在指令理解方面达到96.53%准确率,在物理定律理解方面达到80.16%准确率。
WoW不仅能预测,还能将预测转化为实际的机器人动作指令。
优势
1)从被动观察到主动探索,重新定义世界模型
传统世界模型主要关注状态预测,就像一个能够预测下一帧画面的系统。
WoW则更像一个完整认知系统,包含了感知、预测、判断、反思和行动五个核心环节。
2)自优化预测幻觉改进智能体 - SOPHIA框架
生成器能够快速生成对未来的预测视频。批评家系统会仔细检查这个预测是否符合物理定律。
批评家经过专门训练,能够识别各种物理错误,比如物体穿墙、违反重力定律、或者不合理的碰撞效果。当批评家发现问题时,生成详细反馈。改进器会根据这些反馈重新调整输入指令,让生成器产生更合理的预测。这个过程会反复进行,直到生成的视频既视觉逼真又物理合理。
3)Flow-Mask逆动力学模型
Flow-Mask逆动力学模型(FM-IDM)负责将视觉想象转化为具体的动作指令,即改进器。
FM-IDM分析当前状态和预期状态之间的视觉差异,利用光流技术来理解物体是如何移动的。
FM-IDM能够推断出机器人需要执行什么样的动作才能实现这种状态转换。如果预测视频显示一个杯子从桌子左边移动到右边,FM-IDM就能计算出机器人手臂需要如何移动来完成这个任务。
reference
---
vjepa2
https://github.com/facebookresearch/vjepa2
LargeWorldModel
https://github.com/LargeWorldModel/lwm
World Model on Million-Length Video And Language With Blockwise RingAttention
https://arxiv.org/abs/2402.08268
RTFM: A Real-Time Frame Model
https://www.worldlabs.ai/blog/rtfm
Building World Models with Neural Physics
https://hub.baai.ac.cn/view/45280
Wow world model
https://github.com/wow-world-model/wow-world-model
WoW: Towards a World omniscient World model Through Embodied Interaction
https://arxiv.org/abs/2509.22642
北京大学首创WoW世界模型:让AI真正理解物理世界的革命性突破

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)