LangChain的应用开发(一)
摘要:本文介绍了LangChain框架的开发环境配置(Pycharm+Python+JDK+SpringAI)及其核心架构组成,重点讲解了AI大模型连接和提示词模板的应用。内容包括:1) LangChain三大组件包的功能区分;2) 大模型连接的标准参数配置;3) 字符串和聊天两种提示词模板的使用方法;4) 输出解析器实现结构化输出的四种技术方案(with_structured_output、JS
开发环境: Pycharm-2025版+ Python-3.11 + JDK-17 + SpringAI(1.0.0-M7)- Spring-boot(3.44) langchain
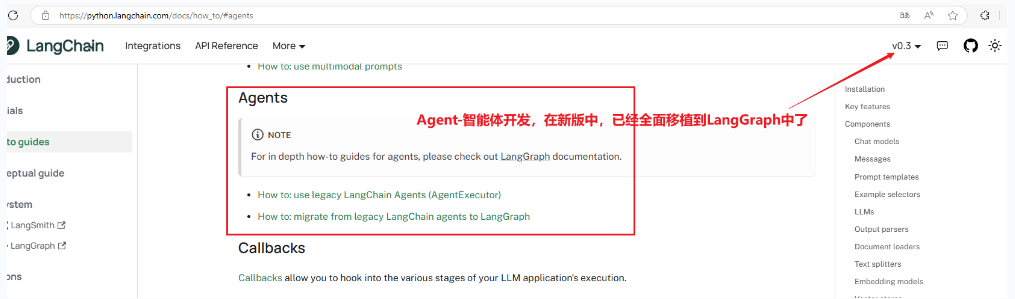
架构
LangChain作为一个框架由多个包组成。
- langchain-core
该包包含不同组件的基本抽象以及将它们组合在一起的方法。 核心组件的接口,如大型语言模型、向量存储、检索器等在此定义。 此处未定义任何第三方集成。 依赖项故意保持非常轻量级。
- langchain
主要的 langchain 包含链、代理和检索策略,这些构成了应用程序的认知架构。 这些不是第三方集成。 这里的所有链、代理和检索策略并不特定于任何一个集成,而是适用于所有集成的通用策略。
- langchain-community
此包包含由 LangChain 社区维护的第三方集成。 关键的合作伙伴包被单独列出(见下文)。 这包含了各种组件(大型语言模型、向量存储、检索器)的所有集成。 此包中的所有依赖项都是可选的,以保持包尽可能轻量。
1、连接AI大模型 和 提示词模板
小爱AI的注册地址:https://xiaoai.plus/register?aff=3TIp
一、连接AI大模型
LangChain不托管任何聊天模型,而是依赖于第三方集成。官网如下:
https://www.langchain.com.cn/docs/integrations/chat/
在构建ChatModels时,我们有一些标准化参数:
- model: 模型名称
- temperature: 采样温度
- timeout: 请求超时
- max_tokens: 生成的最大令牌数
- stop: 默认停止序列
- max_retries: 请求重试的最大次数
- api_key: 大模型供应商的API密钥
- base_url: 发送请求的端点
一些重要事项需要注意:
- 标准参数仅适用于公开具有预期功能的参数的大模型供应商。例如,一些大模型供应商不公开最大输出令牌的配置,因此在这些大模型供应商上无法支持max_tokens。
- 标准参数目前仅在具有自己集成包的集成上强制执行(例如 langchain-openai、langchain-anthropic 等),在 langchain-community 中的模型上不强制执行。
二、提示词模板
提示词模板有助于将用户输入和参数转换为语言模型的指令。 这可以用于指导模型的响应,帮助其理解上下文并生成相关且连贯的基于语言的输出。
提示词模板的输入是一个字典,其中每个键表示要填充的提示词模板中的变量。
有两种类型的提示词模板:
字符串提示词模板
这些提示词模板用于格式化单个字符串,通常用于更简单的输入。 例如,构造和使用 PromptTemplate 的一种常见方式如下:
|
Python |
In-context Learning(ICL)作为一种新的自然语言处理范式逐渐崭露头角。ICL 的核心思想是:通过提供少量示例作为上下文,让大模型直接从中学习并做出预测。这一方法不仅省去了传统监督学习中繁琐的训练过程,还为大模型的应用开辟了新的可能性。
聊天提示词模板
这些提示词模板用于格式化消息列表。这些“模板”本身由一系列模板组成。 例如,构建和使用 ChatPromptTemplate 的一种常见方式如下:
|
在上述示例中,当调用此 ChatPromptTemplate 时,将构造两个消息。 第一个是系统消息,没有变量需要格式化。 第二个是 HumanMessage,将由用户传入的 topic 变量进行格式化。
消息占位符
此提示词模板负责在特定位置添加消息列表。 在上面的 ChatPromptTemplate 中,我们看到如何格式化两个消息,每个消息都是一个字符串。 但是如果我们希望用户传入一个消息列表(历史消息),并将其插入到特定位置呢? 这就是需要使用 MessagesPlaceholder。
|
这将生成一个包含两个消息的列表,第一个是系统消息,第二个是我们传入的 HumanMessage。后面的消息就是我 和AI 大模型对话过程中的历史消息。 这对于将消息列表插入到特定位置非常有用。
|
2、输出解析器和结构化输出
输出解析器 :负责获取模型的输出并将其转换为更适合下游任务的格式。 在使用大型语言模型生成结构化数据或规范化聊天模型和大型语言模型的输出时非常有用。
大型语言模型能够生成任意文本。这使得模型能够适当地响应广泛的 输入范围,但对于某些用例,限制大型语言模型的输出 为特定格式或结构是有用的。这被称为结构化输出。
例如,如果输出要存储在关系数据库中, 如果模型生成遵循定义的模式或格式的输出,将会容易得多。 最常见的输出格式将是JSON, 尽管其他格式如YAML也可能很有用。
.with_structured_output()
为了方便,一些LangChain聊天模型支持.with_structured_output()方法。 该方法只需要一个模式作为输入,并返回一个字典或Pydantic对象。 通常,这个方法仅在支持下面描述的更高级方法的模型上存在, 并将在内部使用其中一种。它负责导入合适的输出解析器并 将模式格式化为模型所需的正确格式。
|
Python |
SimpleJsonOutputParser
一些模型,例如 Mistral、OpenAI, Together AI 和 Ollama, 支持一种称为 JSON 模式 的功能,通常通过配置启用。启用时,JSON 模式将限制模型的输出始终为某种有效的 JSON。

|
Python |
工具调用
对于支持此功能的模型,工具调用 可以非常方便地生成结构化输出。它消除了 关于如何最好地提示模式的猜测,而是采用内置模型功能。
它的工作原理是首先将所需的模式直接或通过 LangChain 工具 绑定到 聊天模型,使用 .bind_tools() 方法。然后模型将生成一个包含 与所需形状匹配的 args 的 tool_calls 字段的 AIMessage。工具调用是一种通常一致的方法,可以让模型生成结构化输出,并且是默认技术 用于 .with_structured_output() 方法,当模型支持时。
|
Python |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)