MiroThinker
MoriFlow提出MiroThinker v1.0开源研究代理框架,通过增强交互能力而非单纯扩大模型规模来提升性能。该框架支持256K上下文窗口和600次工具调用,采用强化学习优化决策,结合近时上下文管理策略。研究发现交互扩展能有效纠正推理错误,但存在工具冗余使用、思维链过长及多语言混合等局限。实验表明交互深度是提升研究代理能力的第三维度,为智能体发展提供了新方向。相关工作包括代理基础模型和深度
实现框架:MoriFlow
github:MiroThinker
论文:https://arxiv.org/pdf/2511.11793
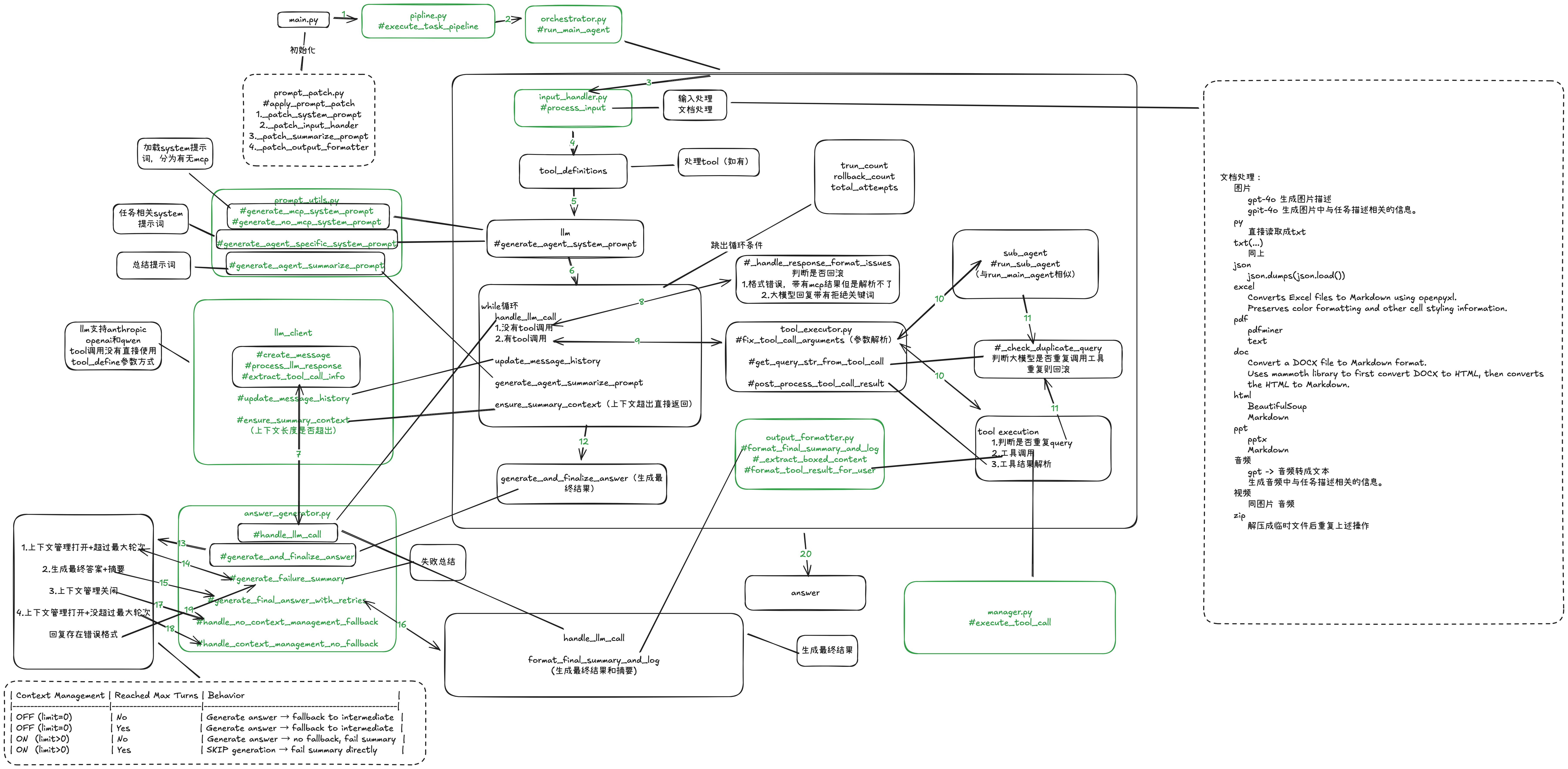
代码精读:
论文内容:
摘要
搜索Agent 工具增强推理 + 信息检索
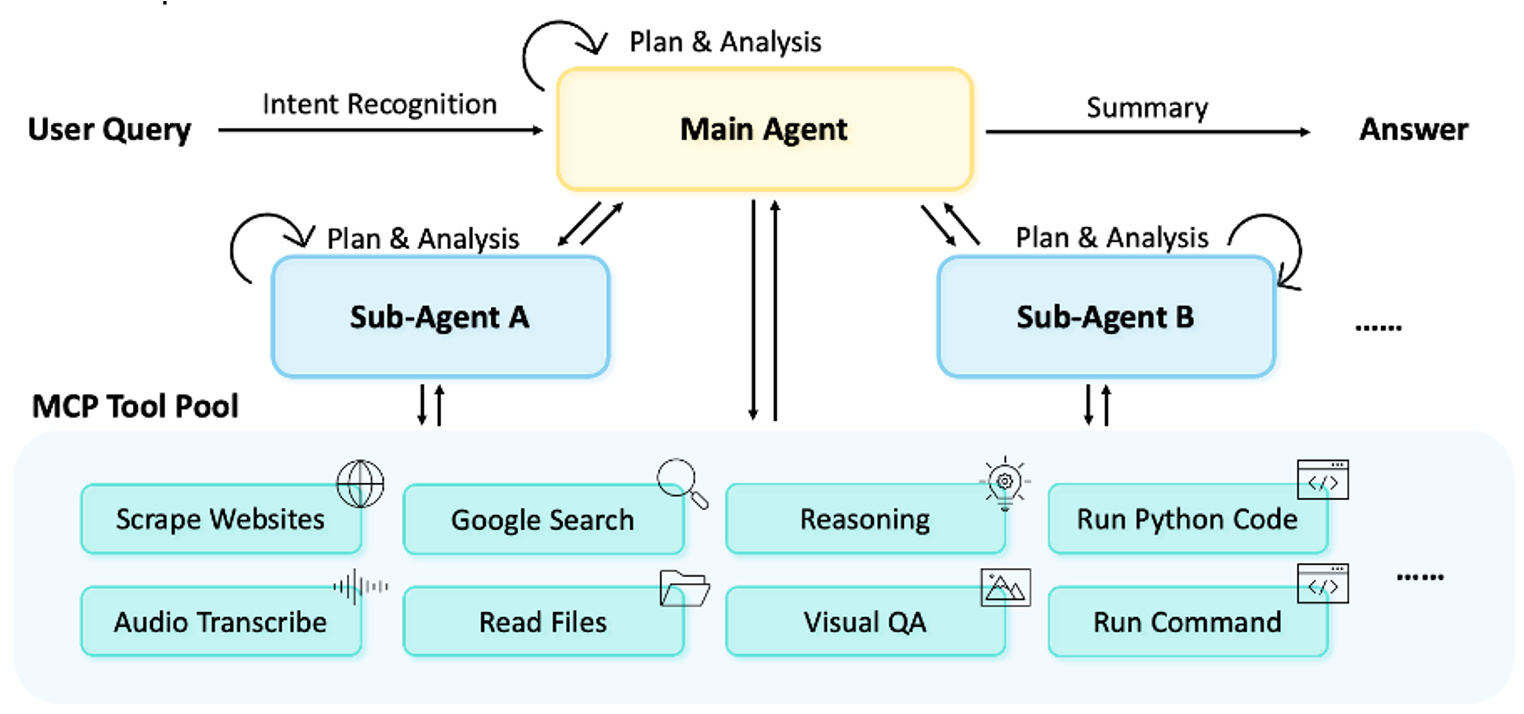
1.与之前的agent通过增加模型尺寸和上下文长度不同,增加agent和环境的交互能力
2.LLM test-time scaling可能在长思维链下存在退化风险,交互过程中利用环境反馈和外部知识获取来纠正错误和优化轨迹。
3.通过强化学习,该模型实现了高效的交互扩展:拥有256K上下文窗口,每项任务可执行多达600次工具调用,支持持续的多回合推理和复杂的现实研究工作流。
相关工作
AFM
agent基础模型:决策、工具调用、交互能力。多数为:代码或者是搜索agent模型。
Deep Research Models
复杂推理、长上下文、检索密集型任务。
代理工作流 (agentic workflow)
mirothinker1.0 :ReAct paradigm in single agent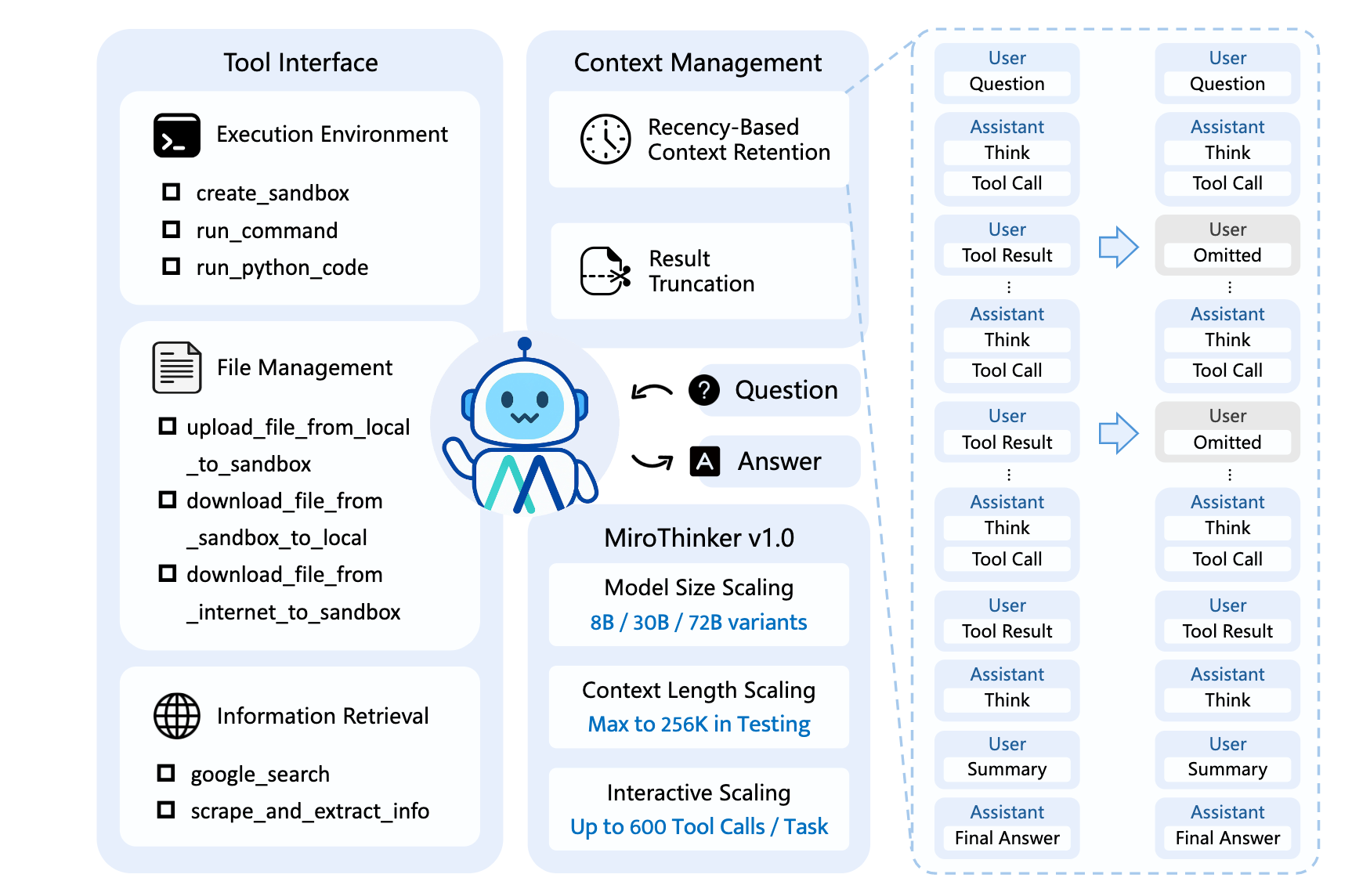
上下文管理
在256k的上下文窗口中实现600次工具调用
近时上下文保留:只保留近期的工具调用结果。并且工具结果也会被截断。
数据构建
1.多文档的QA对合成
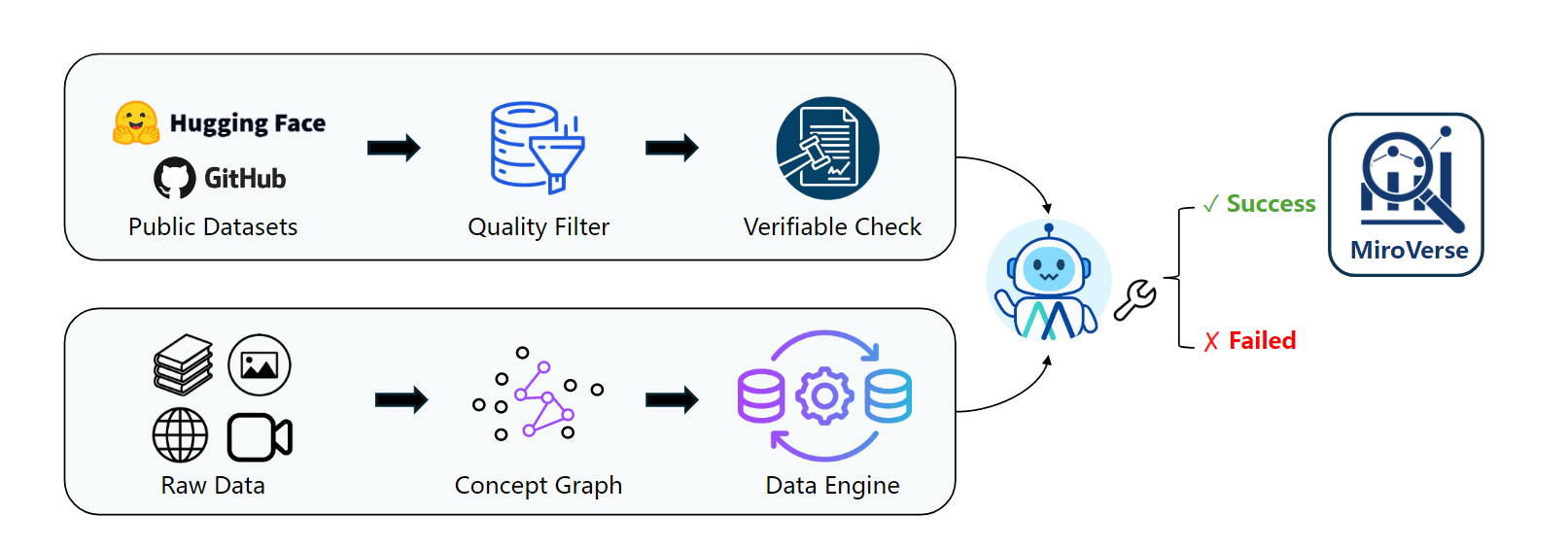
2.代理轨迹合成
训练
基于qwen2.5和qwen3
Agentic Supervised Fine-tuning
模型学习模仿涉及多跳推理和工具使用的专家轨迹。
Agentic Preference Optimization
进一步优化决策。
Agentic Reinforcement Learning
使智能体能够发现创造性的解决方案,并通过直接互动和探索适应多样化的现实环境。
局限
交互式扩展下的工具使用质量:agent偏向于使用工具,有些使用工具决策是冗余的。
过长的思维链:强化学习往往促使模型产生更长的响应以提高准确性,这可能导致推理链过长、重复且难以阅读。这反过来又会减慢任务完成速度,降低用户体验。
语言混合:对于非英语输入,模型的回答可能表现出多语言混合。例如,当用户查询为中文时,模型的内部推理或中间输出可能包含英语和中文元素的混合,可能导致中文表现不佳。
有限的沙盒能力:该模型尚未完全熟练掌握代码执行和文件管理工具的使用。它偶尔可能生成导致沙盒超时的代码或命令,或滥用代码执行工具读取网页或PDF,这些任务本应由专门的网页爬虫工具高效处理。
结论
我们介绍了 MiroThinker v1.0,这是一款开源研究代理,通过模型、上下文和交互式扩展推进工具增强推理。通过将扩展到交互维度,MiroThinker 展示了研究能力不仅随着模型更大或上下文更长而提升,还能通过更深更频繁的代理与环境交互来实现纠错和知识获取。我们的实验展示了交互式扩展在不同基准测试中可预测的收益,确立了交互深度作为构建下一代研究代理的第三个关键轴。我们希望 MiroThinker 为进一步探索交互尺度智能智能提供了坚实的基线和开放平台。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)