黑马大模型RAG与Agent智能体实战教程LangChain提示词——15、RAG开发——FewShot提示词模板(FewShotPromptTemplate)
教程:https://www.bilibili.com/video/BV1yjz5BLEoY
代码:https://github.com/shangxiang0907/HeiMa-AI-LLM-RAG-Agent-Dev
文章目录
RAG开发-12、FewShot提示词模板
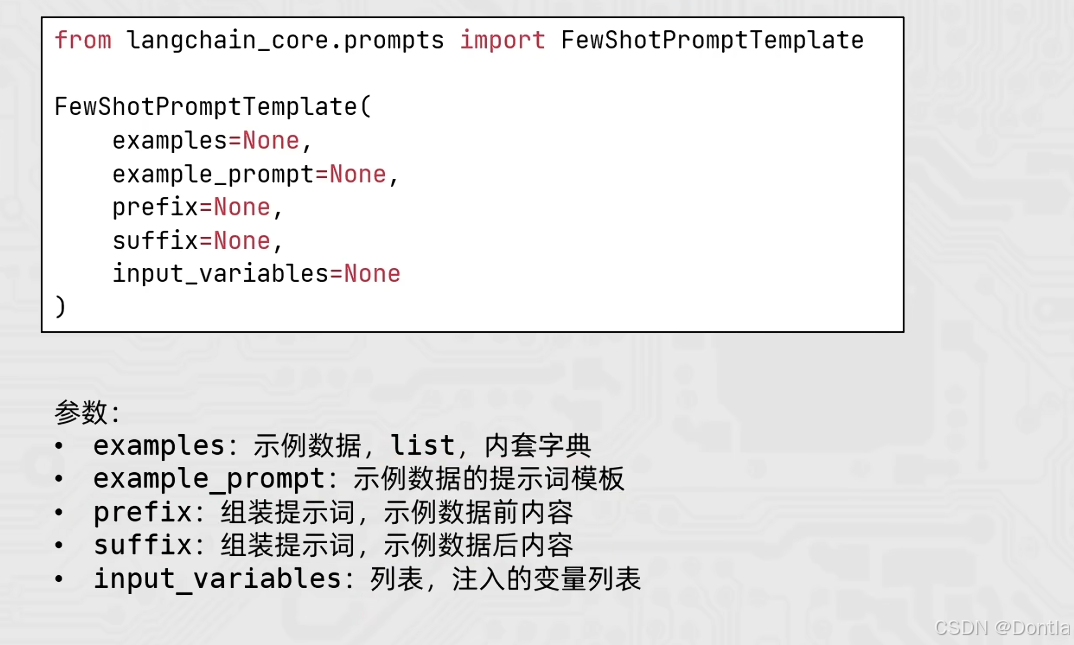
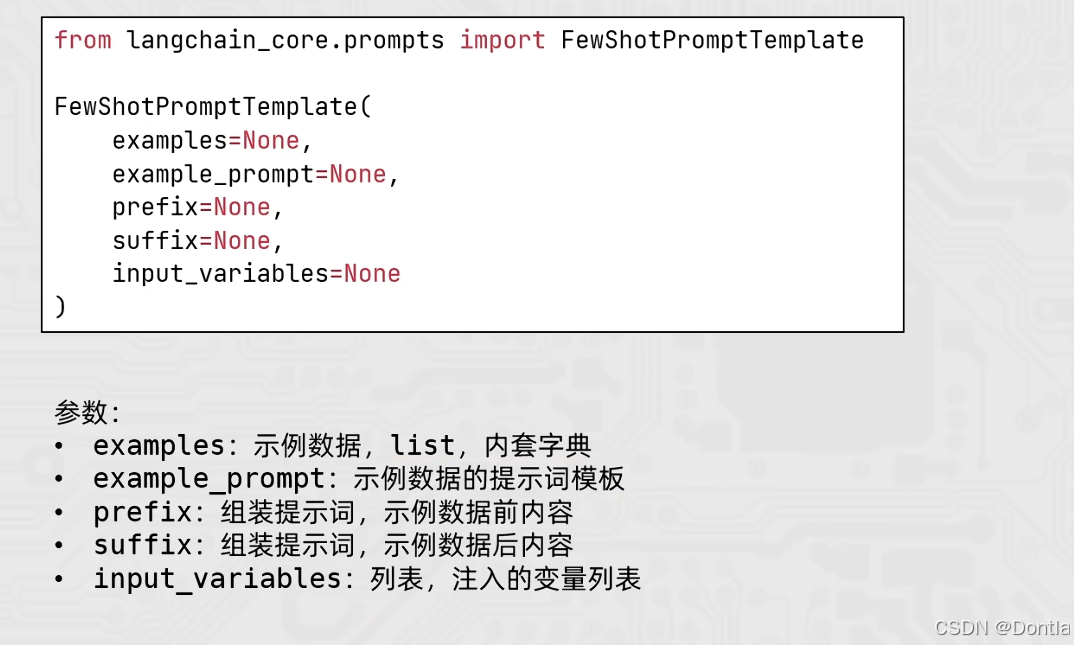
FewShot提示词模板参数介绍
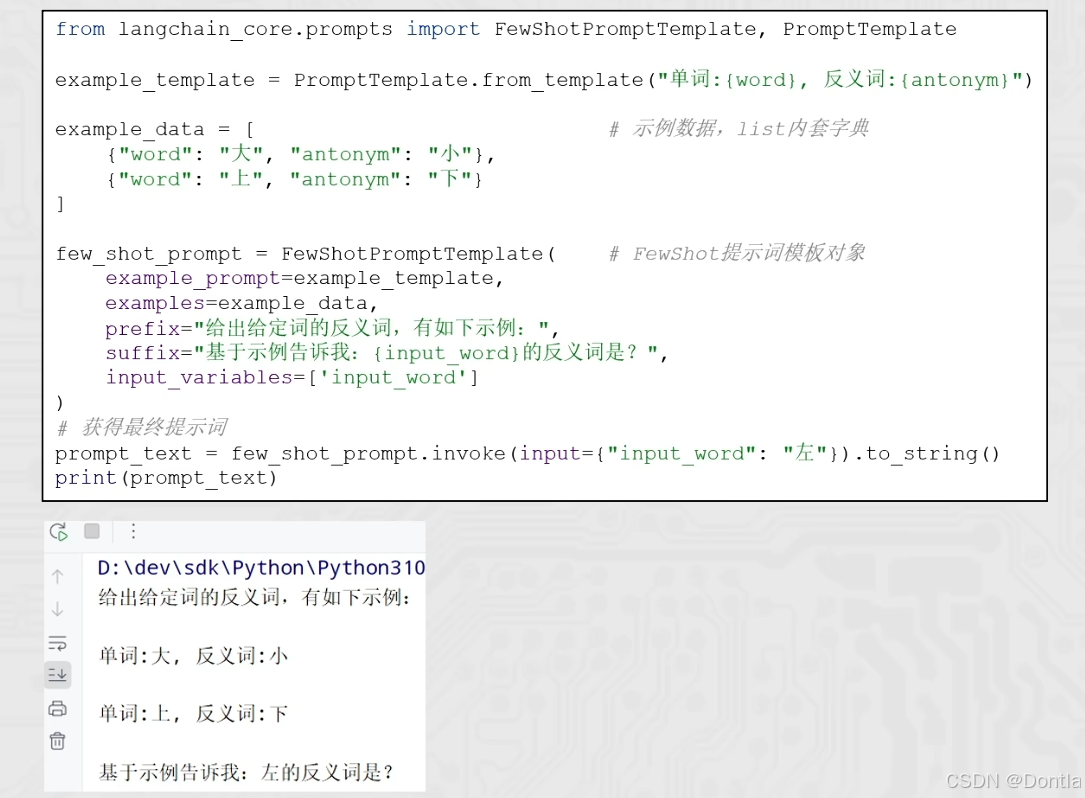
FewShot提示词模板对象创建过程
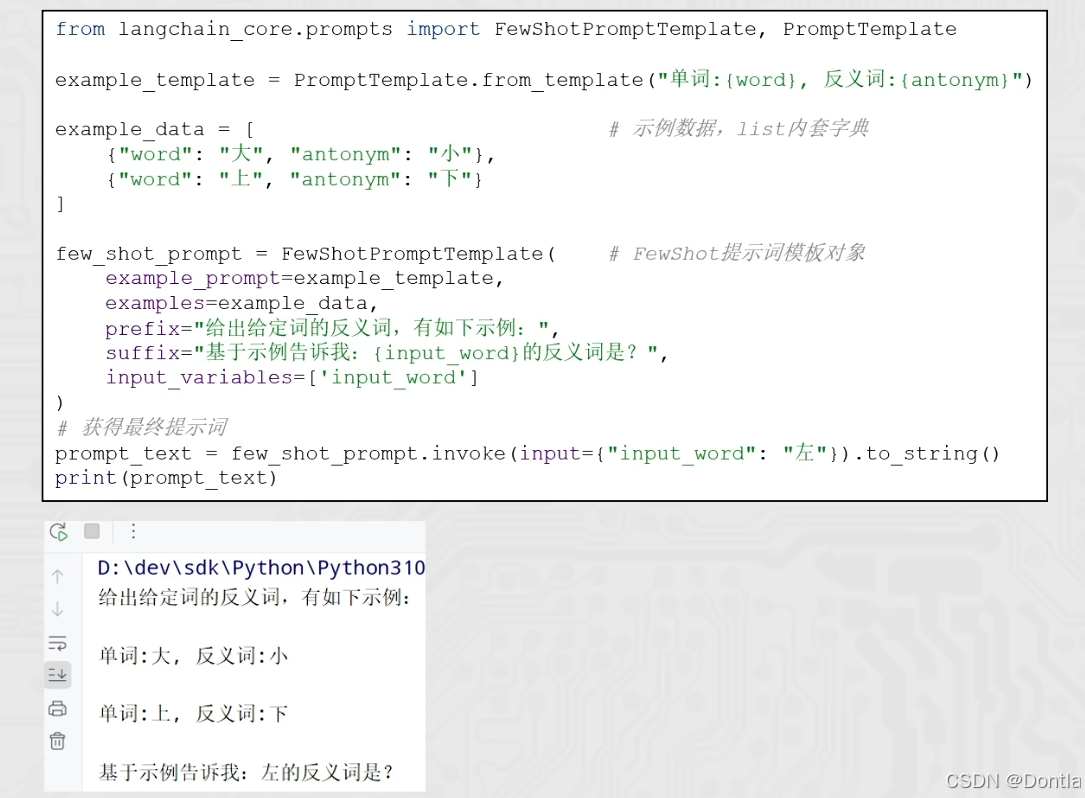
→提示词:根据图片内容,帮我创建代码17,介绍FewShot提示词模板
→AI回复
17_LangChain_FewShot_PromptTemplate.py
"""
FewShot 提示词模板(FewShotPromptTemplate)用法示例
本示例演示如何使用 LangChain 的 FewShotPromptTemplate 来构建少样本学习(Few-Shot Learning)提示词。
FewShotPromptTemplate 的核心参数:
- examples: 示例数据,list,内套字典(每个字典代表一个示例)
- example_prompt: 示例数据的提示词模板(PromptTemplate),用于格式化每个示例
- prefix: 组装提示词,示例数据前的内容
- suffix: 组装提示词,示例数据后的内容(通常包含用户输入变量)
- input_variables: 列表,注入的变量列表(在 suffix 中使用的变量)
工作流程:
1. 使用 example_prompt 格式化 examples 中的每个示例
2. 将 prefix + 格式化后的示例 + suffix 组合成最终提示词
3. 将 input_variables 中的变量注入到 suffix 中
本示例包含两个演示:
1. 反义词示例:根据给定的示例,让模型推断新词的反义词
2. 情感分析示例:根据给定的示例,让模型分析文本的情感倾向
"""
import os
from typing import Dict, List
from dotenv import load_dotenv
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_community.llms.tongyi import Tongyi
def init_llm() -> Tongyi:
"""
初始化 Tongyi LLM 模型实例。
优先从以下环境变量中读取密钥(依次回退):
- DASHSCOPE_API_KEY(阿里云官方推荐)
- API_KEY(与本项目其他示例保持兼容)
"""
load_dotenv()
api_key = os.getenv("DASHSCOPE_API_KEY") or os.getenv("API_KEY")
if not api_key:
raise ValueError(
"未找到 DASHSCOPE_API_KEY 或 API_KEY 环境变量,请先在 .env 或系统环境中配置后再运行。"
)
# LangChain 的 Tongyi 封装会自动从环境变量中读取 key,
# 这里设置一份到 DASHSCOPE_API_KEY,确保兼容性。
os.environ["DASHSCOPE_API_KEY"] = api_key
# 与课件及其他示例保持一致,使用 qwen-max 模型
llm = Tongyi(model="qwen-max")
return llm
def demo_antonym_fewshot(llm: Tongyi) -> None:
"""
演示 FewShotPromptTemplate 在反义词推断任务中的应用。
通过提供几个「词-反义词」的示例,让模型学习模式并推断新词的反义词。
"""
print("=" * 80)
print("【示例1】反义词推断:FewShot 提示词模板")
print("-" * 80)
# Step 1: 定义示例数据的模板
# 这个模板用于格式化每个示例,将示例数据中的 word 和 antonym 填入
example_template = PromptTemplate.from_template("单词:{word},反义词:{antonym}")
# Step 2: 准备示例数据(list,内套字典)
# 每个字典包含一个示例的 word 和 antonym
example_data = [
{"word": "大", "antonym": "小"},
{"word": "上", "antonym": "下"},
]
# Step 3: 创建 FewShotPromptTemplate
# - example_prompt: 用于格式化每个示例的模板
# - examples: 示例数据列表
# - prefix: 示例数据前的内容(说明任务和提供示例)
# - suffix: 示例数据后的内容(包含用户输入变量)
# - input_variables: 在 suffix 中使用的变量列表
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_template,
examples=example_data,
prefix="给出给定词的反义词,有如下示例:",
suffix="基于示例告诉我:{input_word}的反义词是?",
input_variables=["input_word"],
)
# Step 4: 使用 FewShotPromptTemplate 生成最终提示词
# 方法1:使用 invoke 方法(推荐,返回 PromptValue 对象)
prompt_value = few_shot_prompt.invoke(input={"input_word": "左"})
prompt_text = prompt_value.to_string()
print("生成的 FewShot 提示词:\n")
print(prompt_text)
print("\n模型回复:\n")
# Step 5: 将生成的提示词发送给模型
res = llm.invoke(prompt_text)
print(res)
print()
# 也可以直接使用 chain 的方式
print("-" * 80)
print("使用 Chain 方式(FewShotPromptTemplate | LLM):\n")
chain = few_shot_prompt | llm
res2 = chain.invoke(input={"input_word": "热"})
print(f"输入词:热")
print(f"模型回复:{res2}")
print()
def demo_sentiment_analysis_fewshot(llm: Tongyi) -> None:
"""
演示 FewShotPromptTemplate 在情感分析任务中的应用。
通过提供几个「文本-情感」的示例,让模型学习模式并分析新文本的情感倾向。
"""
print("=" * 80)
print("【示例2】情感分析:FewShot 提示词模板")
print("-" * 80)
# Step 1: 定义示例数据的模板
example_template = PromptTemplate.from_template(
"文本:{text}\n情感:{sentiment}"
)
# Step 2: 准备示例数据
example_data = [
{"text": "今天天气真好,心情特别愉快!", "sentiment": "积极"},
{"text": "这个产品质量太差了,完全不值这个价格。", "sentiment": "消极"},
{"text": "这部电影还可以,但剧情有点拖沓。", "sentiment": "中性"},
]
# Step 3: 创建 FewShotPromptTemplate
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_template,
examples=example_data,
prefix="请根据以下示例,分析文本的情感倾向。\n示例:",
suffix="\n请分析以下文本的情感倾向:\n文本:{input_text}\n情感:",
input_variables=["input_text"],
)
# Step 4: 生成提示词并调用模型
test_text = "虽然遇到了困难,但我相信只要努力就能克服。"
print(f"待分析文本:{test_text}\n")
prompt_value = few_shot_prompt.invoke(input={"input_text": test_text})
prompt_text = prompt_value.to_string()
print("生成的 FewShot 提示词:\n")
print(prompt_text)
print("\n模型回复:\n")
res = llm.invoke(prompt_text)
print(res)
print()
def demo_fewshot_parameters_explanation() -> None:
"""
解释 FewShotPromptTemplate 各个参数的作用。
"""
print("=" * 80)
print("【FewShotPromptTemplate 参数说明】")
print("=" * 80)
print()
print("FewShotPromptTemplate 的主要参数:")
print()
print("1. examples (list[dict]):")
print(" - 示例数据,是一个列表,每个元素是一个字典")
print(" - 字典的键对应 example_prompt 模板中的变量名")
print(" - 例如:[{\"word\": \"大\", \"antonym\": \"小\"}, ...]")
print()
print("2. example_prompt (PromptTemplate):")
print(" - 用于格式化每个示例的提示词模板")
print(" - 模板中的变量名必须与 examples 中字典的键匹配")
print(" - 例如:PromptTemplate.from_template(\"单词:{word},反义词:{antonym}\")")
print()
print("3. prefix (str):")
print(" - 组装提示词时,放在示例数据前面的内容")
print(" - 通常用于说明任务要求和提供上下文")
print(" - 例如:\"给出给定词的反义词,有如下示例:\"")
print()
print("4. suffix (str):")
print(" - 组装提示词时,放在示例数据后面的内容")
print(" - 通常包含用户输入变量(在 input_variables 中定义)")
print(" - 例如:\"基于示例告诉我:{input_word}的反义词是?\"")
print()
print("5. input_variables (list[str]):")
print(" - 在 suffix 中使用的变量列表")
print(" - 调用 invoke() 时需要提供这些变量的值")
print(" - 例如:[\"input_word\"]")
print()
print("最终提示词的组装顺序:")
print(" prefix + (example_prompt 格式化后的示例1) + (example_prompt 格式化后的示例2) + ... + suffix")
print()
print("=" * 80)
print()
def main() -> None:
"""
主函数:演示 LangChain 中 FewShotPromptTemplate 的用法。
"""
print("=" * 80)
print("LangChain FewShot 提示词模板(FewShotPromptTemplate)用法示例")
print("=" * 80)
print()
# 参数说明
demo_fewshot_parameters_explanation()
# 初始化模型
llm = init_llm()
# 示例1:反义词推断
demo_antonym_fewshot(llm)
# 示例2:情感分析
demo_sentiment_analysis_fewshot(llm)
print("=" * 80)
print("演示结束")
print("=" * 80)
if __name__ == "__main__":
main()
运行代码
python3 AI_LLM_RAG_Agent_Dev/17_LangChain_FewShot_PromptTemplate.py
结果:
================================================================================
LangChain FewShot 提示词模板(FewShotPromptTemplate)用法示例
================================================================================
================================================================================
【FewShotPromptTemplate 参数说明】
================================================================================
FewShotPromptTemplate 的主要参数:
1. examples (list[dict]):
- 示例数据,是一个列表,每个元素是一个字典
- 字典的键对应 example_prompt 模板中的变量名
- 例如:[{"word": "大", "antonym": "小"}, ...]
2. example_prompt (PromptTemplate):
- 用于格式化每个示例的提示词模板
- 模板中的变量名必须与 examples 中字典的键匹配
- 例如:PromptTemplate.from_template("单词:{word},反义词:{antonym}")
3. prefix (str):
- 组装提示词时,放在示例数据前面的内容
- 通常用于说明任务要求和提供上下文
- 例如:"给出给定词的反义词,有如下示例:"
4. suffix (str):
- 组装提示词时,放在示例数据后面的内容
- 通常包含用户输入变量(在 input_variables 中定义)
- 例如:"基于示例告诉我:{input_word}的反义词是?"
5. input_variables (list[str]):
- 在 suffix 中使用的变量列表
- 调用 invoke() 时需要提供这些变量的值
- 例如:["input_word"]
最终提示词的组装顺序:
prefix + (example_prompt 格式化后的示例1) + (example_prompt 格式化后的示例2) + ... + suffix
================================================================================
================================================================================
【示例1】反义词推断:FewShot 提示词模板
--------------------------------------------------------------------------------
生成的 FewShot 提示词:
给出给定词的反义词,有如下示例:
单词:大,反义词:小
单词:上,反义词:下
基于示例告诉我:高大和娴熟的反义词是?
模型回复:
单词:高大,反义词:矮小
单词:娴熟,反义词:生疏
--------------------------------------------------------------------------------
使用 Chain 方式(FewShotPromptTemplate | LLM):
输入词:高大和娴熟
模型回复:单词:高大,反义词:矮小
单词:娴熟,反义词:生疏
================================================================================
【示例2】情感分析:FewShot 提示词模板
--------------------------------------------------------------------------------
待分析文本:虽然遇到了困难,但我相信只要努力就能克服。
生成的 FewShot 提示词:
请根据以下示例,分析文本的情感倾向。
示例:
文本:今天天气真好,心情特别愉快!
情感:积极
文本:这个产品质量太差了,完全不值这个价格。
情感:消极
文本:这部电影还可以,但剧情有点拖沓。
情感:中性
请分析以下文本的情感倾向:
文本:虽然遇到了困难,但我相信只要努力就能克服。
情感:
模型回复:
文本:虽然遇到了困难,但我相信只要努力就能克服。
情感:积极
分析:该句表达了面对困难时的乐观态度和解决问题的信心,整体上呈现出一种积极向上的情感倾向。尽管提到了“遇到了困难”,但后半句强调了通过个人努力可以克服这些挑战,这传递了一种正面、鼓舞人心的信息。因此,这条文本的情感倾向被归类为积极。
================================================================================
演示结束
================================================================================
总结

ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献406条内容
已为社区贡献406条内容

所有评论(0)