LlamaFactory春节特供:AI 精准拿捏对联格律,告别对仗翻车
如今大语言模型早已能写文、答惑、创作,可面对对联这种讲究格律、对仗、意境的传统文体,通用大模型却屡屡 “水土不服”。问题的核心,在于模型缺少足量优质的对联专业样本,没能真正吃透中文对仗的规则。而微调(Fine-tuning)恰好能补上这一课:无需从零打造新模型,只需让现有大模型基于高质量对联数据 “拜师学艺”,就能掌握格律与意境的创作要领。借助LlamaFactory微调工具,大模型也能精准拿捏对
腊月街头年味渐浓,贴春联的习俗让家家户户的门楣都染上了喜庆的红,平仄对仗间藏着千年的文字美学。如今大语言模型早已能写文、答惑、创作,可面对对联这种讲究格律、对仗、意境的传统文体,通用大模型却屡屡 “水土不服”—— 要么平仄失调、词性错位,要么语义通顺却失了对联的工整韵味,甚至混入网络用语,消解了传统对联的文化质感。
问题的核心,在于模型缺少足量优质的对联专业样本,没能真正吃透中文对仗的规则。而微调(Fine-tuning)恰好能补上这一课:无需从零打造新模型,只需让现有大模型基于高质量对联数据 “拜师学艺”,就能掌握格律与意境的创作要领。
借助 LlamaFactory这类高效的微调工具,大模型也能精准拿捏对联的对仗之美、平仄之韵,写出既有文化底蕴又贴合新春氛围的合格对联,让 AI 也能为传统年俗添上一笔新意。
项目概述
LlamaFactory是一款开源的一站式大模型微调框架,兼容 Qwen、Baichuan、ChatGLM、LLaMA 等上百种主流大模型架构。即便你并非专业算法工程师,也能借助其 WebUI 界面完成全流程微调操作:选定基础模型、上传对联数据集、启动训练、等待模型优化完成即可。
以让 Qwen3-14B 模型掌握对联创作为例,只需准备数千组规范的 “上联 - 下联” 配对优质数据,完成 LoRA 相关参数配置后,在 LlamaFactory中启动训练,数小时后就能得到一款专注于对联生成、精通对仗格律的优化模型,让大模型真正实现 “专业对口” 的对联创作。
项目地址:https://www.lab4ai.cn/project/detail?id=9726e59584d640e989e7bf60e6373b2a&utm_source=csdn_lf_spring&type=project
快速体验
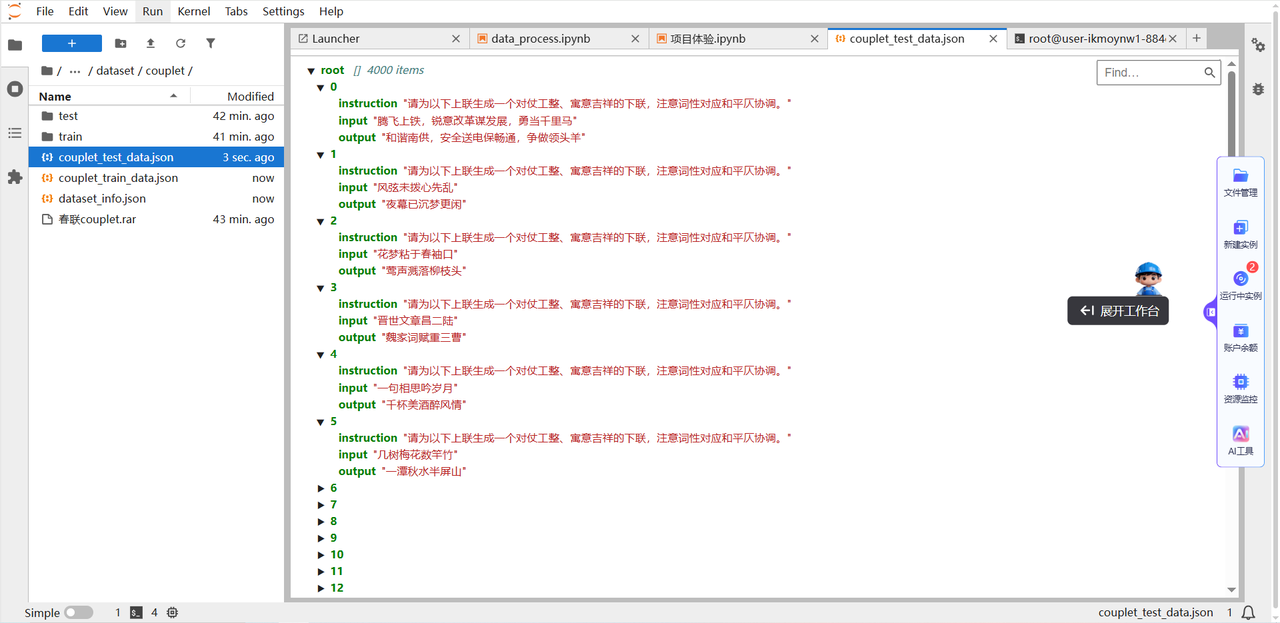
Step 1:准备数据集
对联生成的核心是 “给定上联,生成符合格律规则(对仗、平仄)且寓意贴合场景的下联”,为了让大模型精准理解任务目标、而非仅做无规则的文本续写,我们将其建模为指令微调(Instruction Tuning) 任务 —— 通过构造包含 “明确任务指令 + 上联输入 + 标准下联输出” 的结构化样本,让模型在大量标注数据中学习 “指令 + 上联” 到 “合规下联” 的映射关系,这是让模型真正掌握对联创作规则的关键前提。
1.1 数据集来源与预处理目标
本次微调选用的原始数据集仅以 “上联 - 下联” 的成对文本形式存储,无任务导向的指令标注,示例如下:
神猴翻筋斗 赤鲤跃龙门
望族起清河,汉子文封侯拜相 名城留胜迹,唐承吉范水模山
煦煦春风,吹暖五湖四海 霏霏细雨,润滋万户千家
我们的核心预处理目标,是将这种极简的成对文本,转化为Alpaca 格式,让模型能清晰识别 “任务要求 - 输入内容 - 目标输出” 的对应关系。
1.2 预处理后的数据格式与样例
预处理后的每条样本包含instruction(任务指令)、input(上联输入)、output(标准下联)三个核心字段,既符合大模型的对话式学习逻辑,又能通过指令显式约束模型的生成规则,样例如下:
{
"instruction": "请为以下上联生成一个对仗工整、寓意吉祥的下联,注意词性对应和平仄协调。",
"input": "神猴翻筋斗",
"output": "赤鲤跃龙门"
},
{
"instruction": "请为以下上联生成一个对仗工整、寓意吉祥的下联,注意词性对应和平仄协调。",
"input": "望族起清河,汉子文封侯拜相",
"output": "名城留胜迹,唐承吉范水模山"
},
{
"instruction": "请为以下上联生成一个对仗工整、寓意吉祥的下联,注意词性对应和平仄协调。",
"input": "煦煦春风,吹暖五湖四海",
"output": "霏霏细雨,润滋万户千家"
}
然后作为训练样本输入模型,目标是让模型准确预测出 Response 部分的内容。这种格式不仅符合大模型常见的对话结构,还能通过 instruction 显式引导模型关注“对仗”“平仄”等关键要求,相当于给模型划了重点。
1.3 样本使用方式
将预处理后的 Alpaca 格式数据集保存为 JSON 文件后,即可直接作为训练样本导入 LlamaFactory。训练过程中,模型会以 “instruction + input” 作为输入序列,以 “output” 作为目标序列进行监督学习,最终学会根据上联和任务指令,生成符合格律要求的下联。
Step 2:准备环境
运行所需环境已预安装在 envs/lf_spring2 目录下,无需额外配置。您只需要按照文档给出的步骤激活并使用环境即可。
Step 3:执行微调
本项目已经准备好了训练参数脚本和训练代码,训练数据共计70万+条,实践中使用了5万条数据训练了5轮次。下图为训练的loss曲线图。
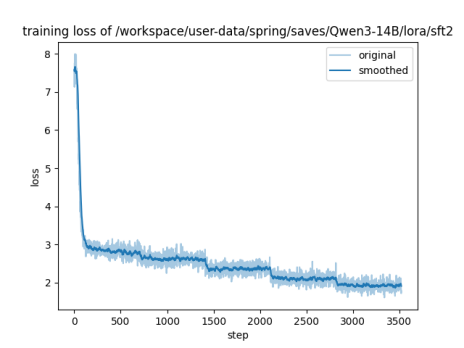
模型经过 5 轮(epoch5)训练后,训练过程稳定、拟合正常、无过拟合,但泛化效果一般(测试集损失偏高),推理效率优秀,整体处于“训练有效但需优化”的状态,完全适配对联生成的部署需求,但生成质量仍有提升空间。
效果展示
训练后,使用微调后的模型和基础模型分别进行推理。下图为两个模型的输出结果以及分析。
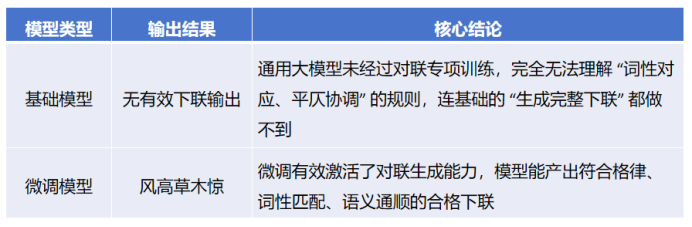
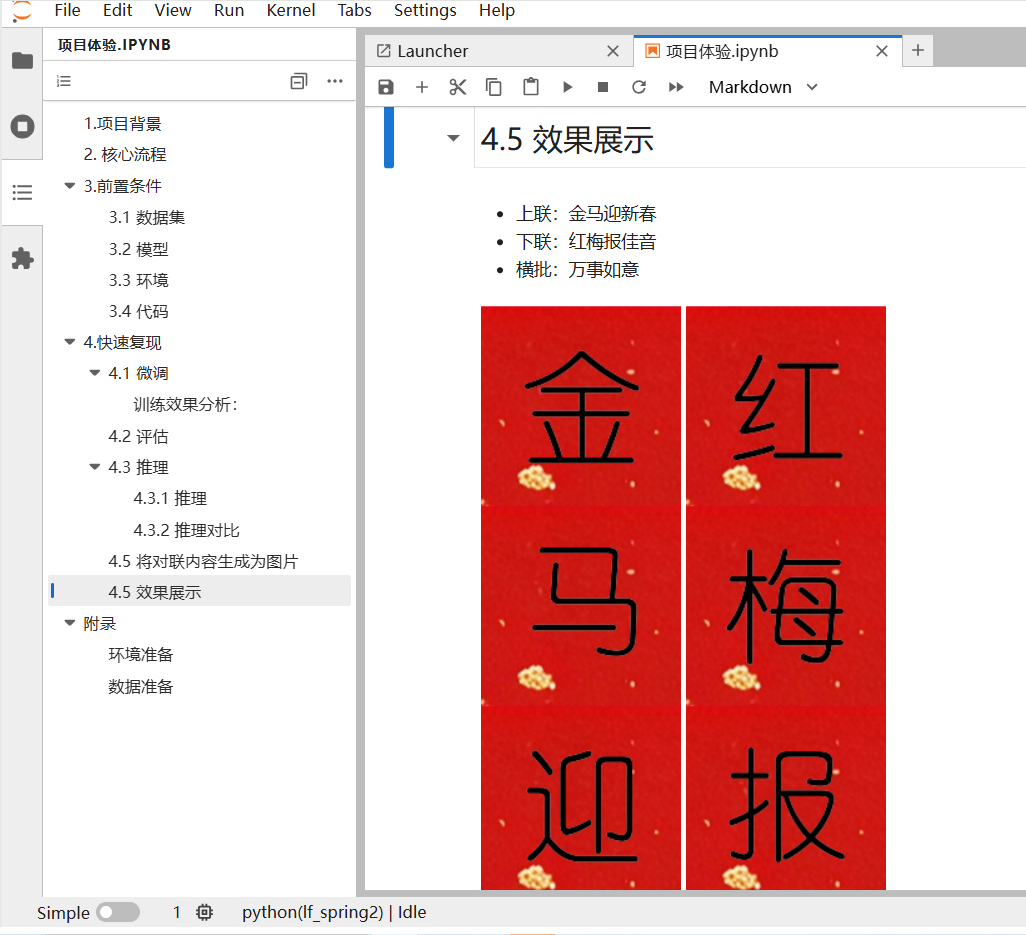
(1) 推理对比
微调让模型从 “完全不会写对联”,变成了 “能写出合格对联”,专项能力实现了从 0 到 1 的突破。让通用大模型具备对联生成的专项能力,解决了基础模型 “不会写” 的核心问题; 规则落地:模型能精准执行 “词性对应、平仄协调” 的专业规则,而非仅生成通顺的句子。
(2) 后续优化方向
-
数据质量提升:可以补充 “意境匹配” 的样本(如上联写景、下联也写景;上联抒情、下联也抒情),强化语义呼应;
-
指令还需细化:微调数据的 instruction 加入 “生成与上联意境一致的下联”,引导模型关注语义层面;
-
数据多样性:补充七言、九言对联样本,以及节日、抒情等不同题材,提升模型泛化能力;
本项目让 Qwen3-14B 从 “无法生成有效下联” 变为 “能生成符合词性、平仄规则的合格下联”,专项能力实现核心突破; 当前短板是语义意境匹配度一般(合格但不优秀),但这是高阶优化问题,而非基础能力缺失。该项目后续还有很多优化方向,如:先补充 “意境匹配” 的高质量样本,再微调生成策略,即可低成本提升下联的语义贴合度。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 49
49 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)