字节这款新模型,终于让AI视频不那么“假“了
从测评结果看,Seedance 2.0确实是目前国内文生视频模型的第一梯队水平。它不是那种"一步到位"的完美产品,但在视音频协同、镜头表达、细节还原这些关键点上,找到了实用的平衡点。AI视频生成这个领域,进步速度比预期快。半年前觉得还差点意思的功能,现在已经能用了。再过半年会变成什么样,确实值得期待。想体验的话,可以关注字节官方的开放情况。💡 现在做AI相关的东西基本都在搞,Claude、GPT
字节这款新模型,终于让AI视频不那么"假"了
2月7日,字节跳动发布了新一代视频生成模型Seedance 2.0。
作为一直关注AI视频领域的人,我第一时间去了解了这款模型的测评数据。SuperCLUE团队基于他们的T2V基准做了一轮专项测评,结果显示Seedance 2.0在多个维度超越了谷歌的Veo 3.1,登上榜首。
这篇文章不吹不黑,聊聊它到底强在哪,还有哪些问题。
先看成绩
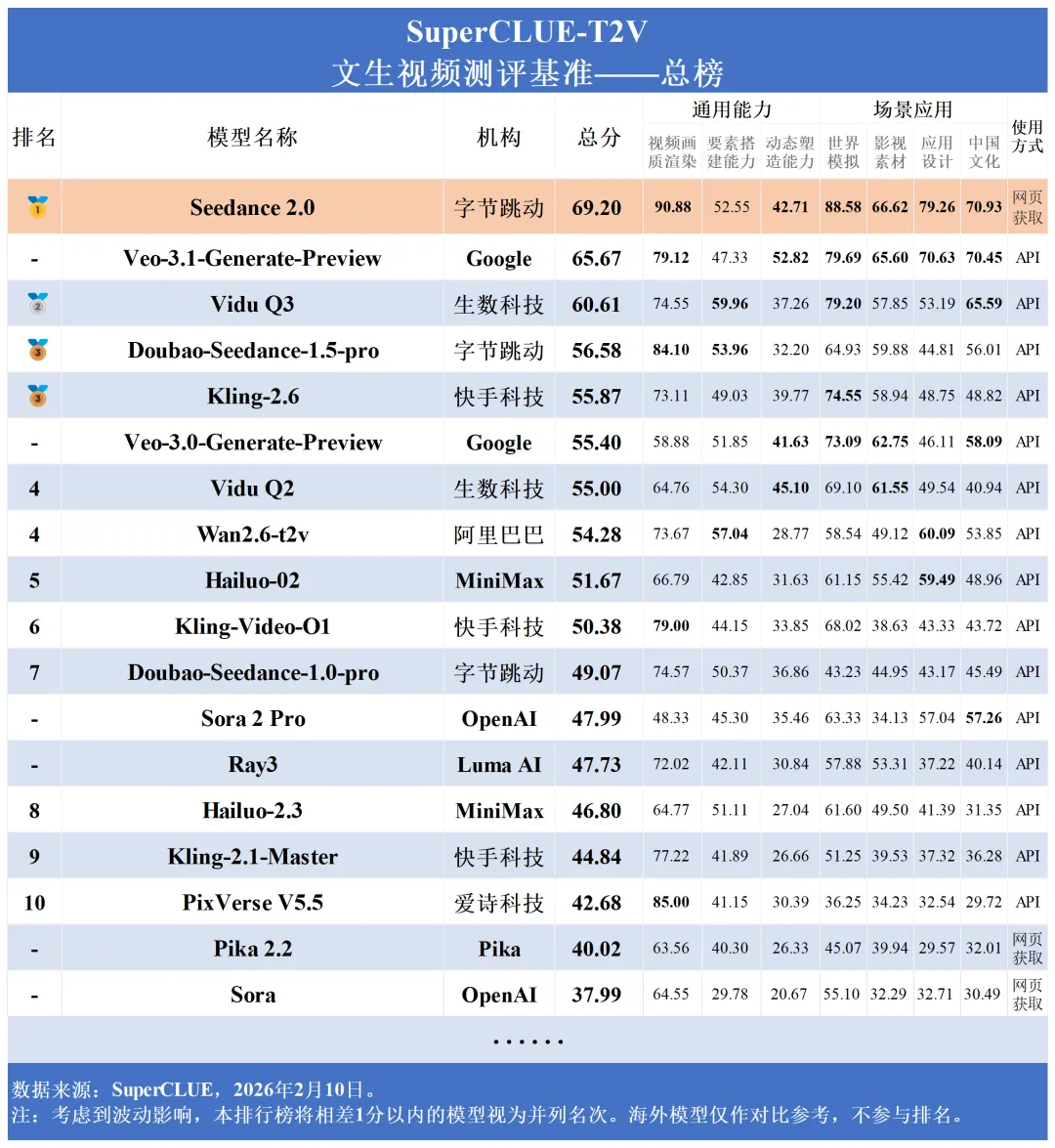
根据SuperCLUE-T2V榜单,Seedance 2.0在以下核心维度得分较高:
- 视频画质渲染:90.88分
- 世界模拟:88.58分
- 应用设计:79.26分
- 影视素材:66.62分
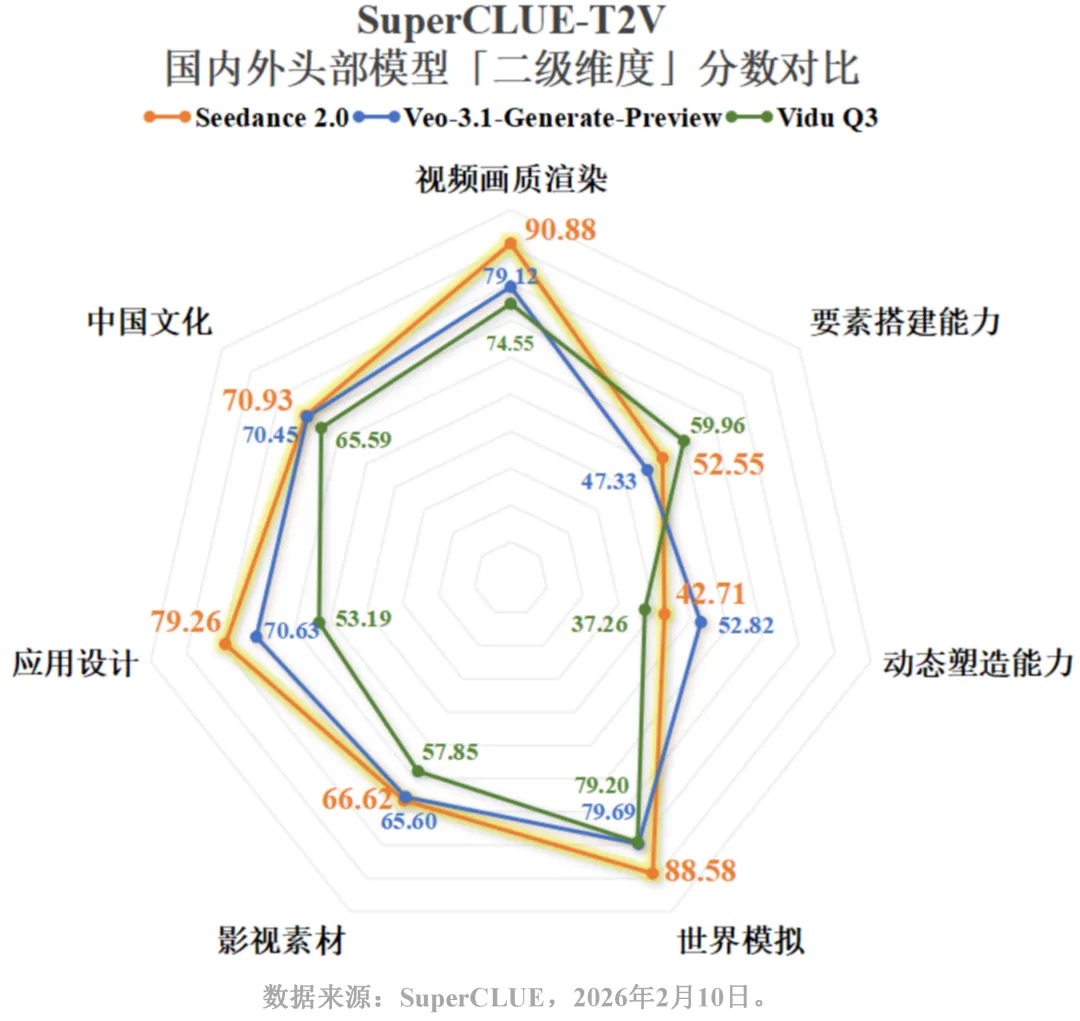
它做对了什么
视音频协同能力
这是我觉得最实用的一个升级。以往AI生成的视频,画面和声音往往是割裂的。Seedance 2.0在动态场景的还原上下了功夫,能根据画面中动作的速度、空间关系来匹配音效。
比如滑雪场景中,铲雪、起跳、落地这些动作的音效能和画面同步,而且能根据镜头远近智能调控音量。这点对于做短视频内容的人来说,应该挺实用的。
镜头语言表达
Seedance 2.0支持多类型镜头的自主生成和衔接,能够根据文本描述灵活搭配镜头形式。比如虚实焦转换、慢镜头、镜头切换这些操作,它能自己完成,不需要额外调整。
细节刻画
在落叶飘落的场景测试中,Seedance 2.0能区分枫叶、银杏叶、梧桐叶的形态差异,并且飘落、触地、层叠的动态表现符合物理规律。这种细节上的准确性,是区分"能用"和"好用"的关键。
和上一代对比
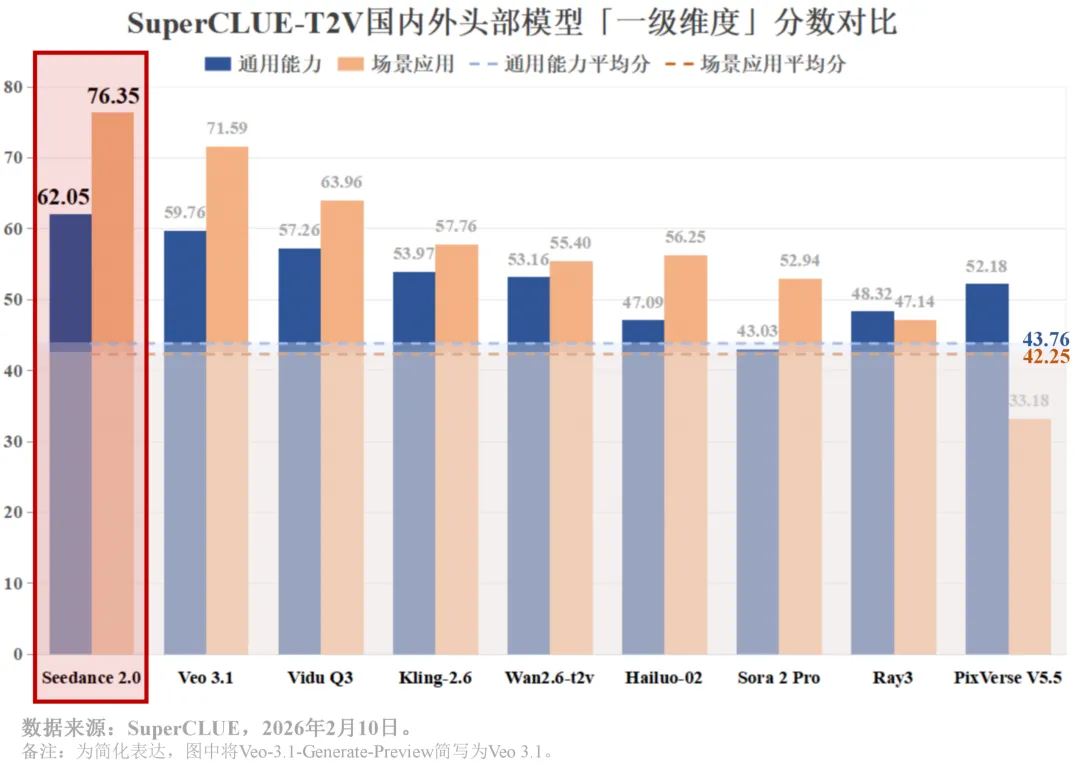
对比Seedance 1.5版本,2.0的迭代不只是画质提升,而是在世界模拟、中国文化理解、应用设计这些场景化能力上实现了跨越。
比如苏州绣娘的场景,1.5版本得分6.50,2.0版本得分9.50。这个提升幅度说明字节在这半年里,确实针对实际应用场景做了优化。
还有哪些问题
中文乱码
在部分复杂中文文本生成场景中,仍然存在字符编码异常的问题。如果你的视频需要显示中文文字,目前可能还需要后期处理。
长镜头逻辑
对于复杂、多约束的提示词,模型的理解能力还有提升空间。部分生成内容与现实物理规律存在偏差,比如镜头切换不够自然、场景过渡生硬。
官方给出的问题案例是健康监测手环的演示场景——手环屏幕文字出现乱码,镜头切换显得僵硬,场景过渡缺乏逻辑衔接。这些问题在长视频制作中会比较明显。
适合谁用
如果你的需求是长剧情视频、复杂的中文文字动画,或者对物理真实性要求极高的场景,可能还需要再等等,或者结合其他工具使用。
最后说几句
AI视频生成这个领域,进步速度比预期快。半年前觉得还差点意思的功能,现在已经能用了。再过半年会变成什么样,确实值得期待。
💡 顺便分享个自用的小工具:ChatTools (https://chattools.top),它把 Claude 4.5、GPT 5.2 和 Midjourney v7 这些模型都整合在一起了,最省心的是不用折腾网络环境,打开就能直接用。
📰 AI 圈迭代实在太快,我平时习惯刷刷 AI Inking (https://aiinking.com) 来看最新的动态,信息更新挺及时的,省去了到处找资讯的时间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)