
本地化部署哪个AI大模型运行结果最靠谱?
一.为什么要进行AI大模型的本地化部署?日常工作中,需要紧急处理的公司事务,需要 AI 帮忙分析提高处理速度和效率,但是由于文件涉密...不能把内容传到AI平台;出差乘机,正好想到好点子要优化方案,想找 AI 帮忙,但是许多航班并没有网络服务;学校老师给学生出题目,想到用AI来帮忙,但是发现AI出的题目,并不能get到你想要的点,AI出的题目的考查点与课堂内容相差颇大;也有可能你在用某个AI大模型

一.为什么要进行AI大模型的本地化部署?
日常工作中,需要紧急处理的公司事务,需要 AI 帮忙分析提高处理速度和效率,但是由于文件涉密...不能把内容传到AI平台;出差乘机,正好想到好点子要优化方案,想找 AI 帮忙,但是许多航班并没有网络服务;学校老师给学生出题目,想到用AI来帮忙,但是发现AI出的题目,并不能get到你想要的点,AI出的题目的考查点与课堂内容相差颇大;也有可能你在用某个AI大模型时,官网提供的访问路径再三提示“服务器繁忙,请稍后再试”;……

本地大模型的优势:
-
完全免费:不用每月支付AI模型的订阅费
-
速度飞快:本地运行,部署与电脑性能匹配的大模型后,和延迟说bye-bye
-
隐私安全:所有对话都在你自己电脑上完成,数据安全有保障
-
完全控制:可以自由选择模型和调整模型参数
-
永不掉线:不需要联网也能用,在飞机上、火车上没有网络也能随时可用
-
支持自建知识库:通过自建知识库,使得AI的输出更加精准、专业
简单来说,100% 本地运行,100% 隐私安全,100% 免费,100%专业。
二.怎么本地化部署AI大模型
以笔者的Mac为例,其配置如下;

与本机对应的AI大型选型如下:
|
名称 |
模型硬盘需求 |
模型运行内存需求 |
|
Deepseek r1:32b |
19G |
32G |
|
Qwen2.5:32b |
19G |
32G |
|
Gemma3:27b |
17G |
32G |
下面以部署deepseek r1:32b为例。
1.安装ollama。有两种方式:
(1)访问官网:
https://ollama.com
点击Download下载并安装即可。
(2)访问Ollama 的官方Github地址:https://github.com/ollama/ollama
对于macOS和Windows系统,点击Download进行ollama的下载并进行安装。
2.打开终端,在终端输入以下命令:
ollama pull deepseek-r1:32b 或者也可以直接输入以下命令:
ollama pull deepseek-r1:32b 
类似的办法,依次输入:
ollama run qwen2.5-coder:32b ollama run gemma3:27b完成Qwen2.5和Gemma3的安装。完成安装后,终端输入以下命令进行确认:
ollama list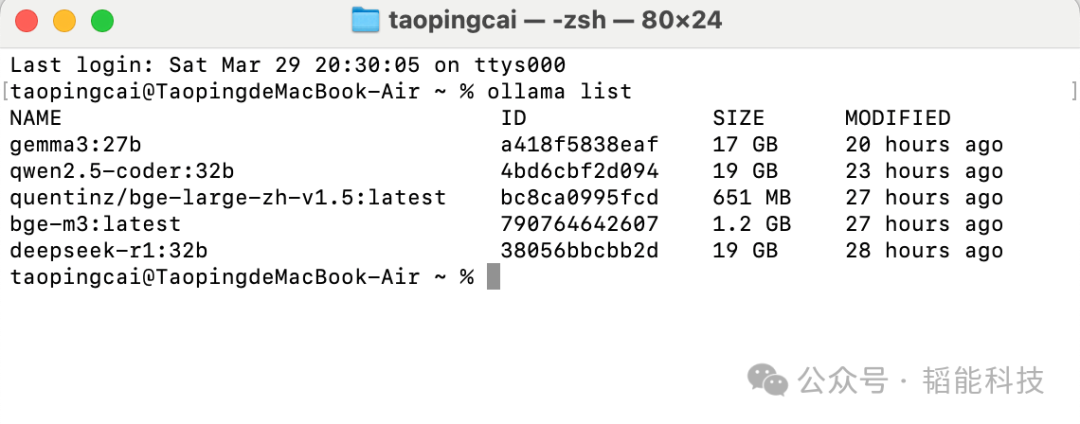
当刚刚安装的AI大模型出现在清单中,说明顺利完成了安装。
三.试运行测试AI大模型性能
本次测试的拟定任务是依次向deepseek-r1:32b模型、gemma3:27b模型和qwen2.5-coder:32b模型输入:
R134a制冷剂在工况条件:冷凝温度50℃,过冷度3 ℃;蒸发温度-10℃,吸气过热度度2℃,采用等熵绝热压缩,等焓节流,忽略管路和换热器流阻。请通过制冷循环过程分析,计算制冷系数。
测试三个模型在计算过程中,所用的时间和功耗(平均功耗和峰值功耗)、占用内存和推导结果的准确性,综合测试AI大模型的运行效率。测试结果需要用到命令;
sudo asitop 运行后,会显示mac当前的cpu、gpu、内存占用比例和功耗等运行数据,和mac自带的活动监视器差不多。但数据是显示一屏里,看起来比“活动监视器“方便多了。
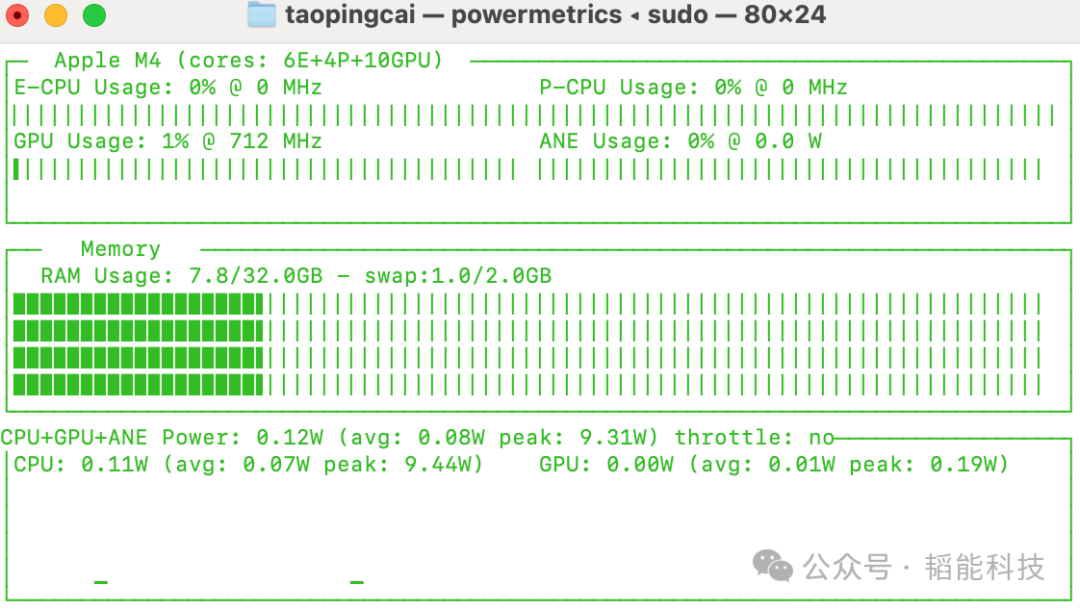
(1)deeseek r1:32b测试情况
-
资源消耗:该模型从收到测试任务到完成结果输出,一共用时15min。运行过程中,10颗GPU芯片全部占用。AI大模型在接受到任务后,功率消耗瞬间达到峰值,GPU峰值功率19.91W,CPU峰值功率4.46W,内存占用26.9G/32G;运行初期,GPU平均功率12.75W,CPU平均功率0.20W;运行后期,功率消耗进一步下降,GPU平均功率8.94W,CPU平均功率0.11W。
-
计算结果:该模型通过调用内部存储的制冷剂物性值(需要说明的是,状态点的温度、压力计算准确,但查出来的各个状态点物性参数数值并不准确),运用公式COP=Qcoo/Qcom计算出制冷系数COP=2.38
,时长00:44
(2)gemma3:27b测试情况
-
资源消耗:该模型从收到测试任务到完成结果输出,一共用时4min。运行过程中,10颗GPU芯片全部占用。AI大模型在接受到任务后,功率消耗瞬间达到峰值,GPU峰值功率19.61W,CPU峰值功率3.89W,内存占用26.6G/32G;运行初期,GPU平均功率14.2W,CPU平均功率0.24W;运行后期,功率消耗进一步下降,GPU平均功率10.5W,CPU平均功率0.13W。
-
计算结果:该模型通过调用内部存储的制冷剂物性值,运用公式COP=Qcoo/Qcom计算出制冷系数COP=8.28
需要说明的是,该模型对各个状态点的压力计算不准确,导致查出来的各个状态点物性参数数值很不准确,最后的输出结果更是大相径庭

。
,时长00:23
(3)qwen2.5-coder:32b
-
资源消耗:该模型从收到测试任务到完成结果输出,一共用时3min多一点。运行过程中,10颗GPU芯片全部占用。AI大模型在接受到任务后,功率消耗瞬间达到峰值,GPU峰值功率20.46W,CPU峰值功率1.24W,内存占用26.7G/32G;运行初期,GPU平均功率14.5W,CPU平均功率0.08W;运行后期,功率消耗进一步下降,GPU平均功率10.85W,CPU平均功率0.08W。
-
计算结果:该模型通过调用内部存储的制冷剂物性值,运用公式COP=Qcoo/Qcom计算出制冷系数COP=0.389

需要说明的是,该模型对各个状态点的温度、压力计算都不准确,导致查出来的各个状态点物性参数数值很不准确,最后的输出结果更是大相径庭

。
,时长00:16
四.测试总结
|
名称 |
求解时间 (min) |
内存占用 (G) |
GPU功率(W) |
CPU功率 (W) |
计算结果 准确度 |
||
|
峰值 |
均值 |
峰值 |
均值 |
||||
|
Deepseek r1 32b |
15 |
26.9 |
19.91 |
12.75 |
4.46 |
0.11 |
状态点物性参数取值不准确 |
|
Gemma3:27b |
4 |
26.6 |
19.61 |
14.2 |
3.89 |
0.13 |
状态点的压力 取值不准确 |
|
Qwen2.5:32b |
3 |
26.7 |
20.46 |
14.5 |
1.24 |
0.08 |
状态点的温度、压力取值不准确 |
综上测试结果表明,Deepseek r1:32b模型花最多的时间,占用了最大的内存,GPU+CPU消耗了最多的能量,同时输出了准确的状态点压力和温度值,计算出了最接近准确值的制冷系数值,相对来说最靠谱;Gemma:27b,占用内存和Deepseek r1:32b相当,GPU+CPU能耗略低,尽管将时间缩短至4min,但是却带来了计算的不准确,特别是状态点压力值计算出现错误,导致结果大幅偏离;Qwen2.5:32b,占用内存和Deepseek r1:32b相当,GPU+CPU能耗略低,尽管将时间进一步缩短至3min左右,但是却带来了计算更加的不准确,特别是状态点的温度和压力值计算都出现错误,导致结果跑了火车,可以说是相当的不准确,最不靠谱。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取