gpt-Image-1最新一代原生多模态图像生成模型,适用于多个领域,让图像生成更精准
GPT-Image-1 是 OpenAI 推出的最新一代原生多模态图像生成模型,基于 GPT-4o 的强大架构构建,专为开发者和企业级应用设计,支持高精度、可定制化的图像生成与编辑功能。
GPT-Image-1 是 OpenAI 推出的最新一代原生多模态图像生成模型,基于 GPT-4o 的强大架构构建,专为开发者和企业级应用设计,支持高精度、可定制化的图像生成与编辑功能。该模型通过 API 形式在 Azure AI Foundry 平台开放,具备更强的指令理解能力、文本渲染表现和跨模态整合能力,适用于创意设计、教育、电商、游戏开发等多个领域。
一、核心功能与能力
1. 文本到图像生成(Text-to-Image)
-
用户输入详细的文字描述(prompt),模型即可生成符合语义的高质量图像。
-
支持复杂提示词解析,能准确理解多对象、多属性、空间关系等长文本指令。
-
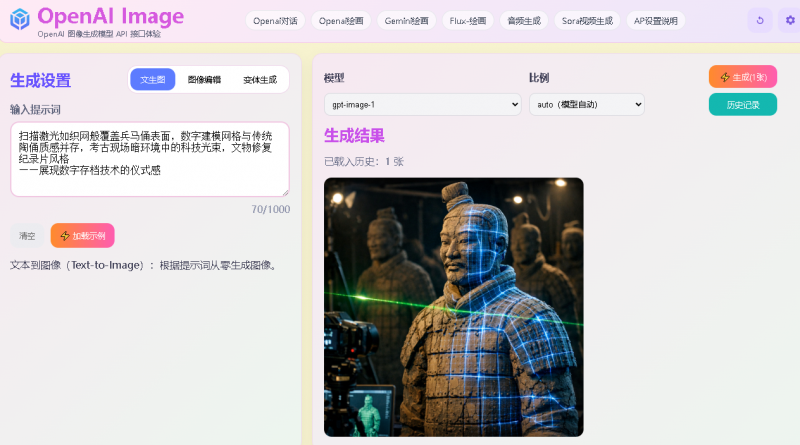
示例:输入“一位穿着汉服的少女站在樱花树下,手持油纸伞,背景是江南水乡的清晨”,可生成细节丰富、风格统一的图像。
2. 图像到图像生成(Image-to-Image)
-
支持上传现有图像并结合文本提示生成新图像,实现风格迁移、场景重构等功能。
-
与 DALL-E 不同,此功能已集成于 GPT-Image-1 API 中,无需依赖 ChatGPT 界面即可调用。
-
应用场景:产品原型迭代、艺术风格转换、广告视觉优化。
3. 图像编辑(Image Editing / Inpainting)
-
局部重绘(Inpainting):用户可通过绘制蒙版(bounding box)指定图像中需修改的区域,并提供文本提示,模型将仅对该区域进行重绘,其余部分保持不变。
-
全局编辑:通过文本指令直接修改图像整体风格、光照、色彩等,如“将这张照片转为赛博朋克风格”。
-
支持文件路径或 Base64 编码输入,便于自动化流程集成。
4. 文本内容渲染优化
-
显著提升图像中文字的可读性与排版准确性,解决了以往 AI 模型常出现的字母错乱、字体扭曲等问题。
-
适用于海报设计、UI 原型、教育插图等需要嵌入清晰文字的场景。
5. 多图融合与组合生成
-
可同时接收多张参考图像与文本提示,综合理解后生成融合元素的新图像。
-
例如:上传 4 张不同商品图,提示“将它们放入一个复古木箱中,摆放在阳光下的庭院里”,模型可生成协调一致的合成场景图。
二、技术规格与参数配置

三、高级特性与创新优势
1. 零样本能力(Zero-shot Capabilities)
-
无需训练即可理解并执行新颖、复杂的生成任务,如“画一个莫比乌斯环形状的图书馆,内部有漂浮的书籍”。
-
基于 GPT 系列强大的世界知识库,能准确呈现历史、文化、艺术等背景元素。
2. 风格控制与个性化定制
-
支持多种艺术风格生成,包括写实、水彩、油画、动漫、吉卜力风等。
-
可通过提示词精确控制光影、色调、构图风格,如“皮克斯动画风格”、“80年代复古海报质感”。
3. API 优先设计,易于集成
-
提供标准 RESTful API 接口,支持 Python、Node.js 等主流语言调用。
-
已接入 Figma、Kittl 等设计工具,实现“在编辑器内直接生成图像”的无缝工作流。
4. 安全与合规机制
-
内置内容过滤系统(Content Filtering),自动拦截违法、有害或侵犯隐私的内容请求。
-
支持企业客户申请关闭部分内容限制(如生成未成年人形象),需通过审核流程。
-
所有输出图像附带 C2PA 元数据,确保来源可追溯,符合数字版权管理要求。
四、典型应用场景
-
教育领域:自动生成教学插图、互动绘本、科学示意图,提升课程可视化水平。
-
游戏开发:快速生成角色设定图、场景原画、道具设计,保持美术风格一致性。
-
电商平台:一键生成商品宣传图、场景化陈列图,支持透明背景输出,降低拍摄成本。
-
UI/UX 设计:生成高保真界面原型、图标、背景图,加速产品迭代。
-
广告创意:批量生成多风格广告素材,用于 A/B 测试与投放优化。
我们就以数字先锋API(api.cxsee.com)接口体验为例,生成几张关键词+图效果,总结使用下来对中文理解支持度非常好,简单高效。

查看数字先锋API平台日志费用非常低,后面播播资源小编还为大家介绍一些价格低效果好的模型供使用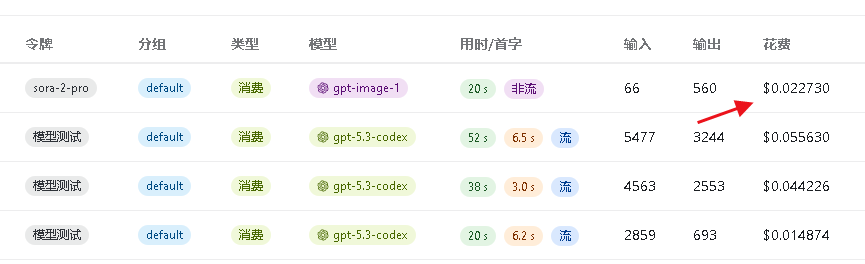

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)