Dify私有化部署实战(四):进阶之通过 Workflow (工作流) 编排复杂业务逻辑
本文介绍了如何利用Dify的Chatflow功能构建智能问答系统。通过条件分支和代码节点实现知识库检索与联网搜索的双路召回架构:首先查询企业知识库,若置信度低于阈值则自动触发联网搜索,并对搜索结果进行清洗格式化后交由LLM回答。文章详细讲解了变量管理、知识检索置信度判断(Python代码实现)、条件分支逻辑和联网搜索数据清洗等关键节点的配置方法,最终实现了既能回答内部知识又能处理外部查询的全能助手
前言:
接上篇 Dify私有化部署实战(三):构建企业级 RAG 知识库,我们已经搞定了基于 BGE-M3 + Rerank 的高质量知识库。
但在实际生产环境中,单纯的 RAG 有个致命痛点:如果知识库里没有答案怎么办? 直接胡说八道(幻觉),还是回复“我不知道”?
本篇记录如何利用 Dify 的 Chatflow (高级编排) 功能,搭建一个**“知识库查不到自动联网搜索”**的全能助手。这将涉及到条件分支、代码执行、变量赋值等核心节点的实战应用。
1. 为什么需要 Workflow/Chatflow?
在 Dify 的基础模式中,我们通常只能配置 提示词 -> 上下文 -> 模型 这样线性的逻辑。但在企业级场景下,业务逻辑往往是分叉的:
-
场景 A:用户问公司政策 -> 查内部知识库。
-
场景 B:用户问今天的天气/新闻 -> 查互联网。
-
场景 C:用户查不到结果 -> 记录日志并转人工。
这就需要用到 Workflow(工作流)。在 Dify 中,如果是对话类应用,我们选择 Chatflow(对话工作流) 模式。
2. 实战目标:全能问答机器人(记忆版)
本次实战的目标是搭建一个智能客服,逻辑如下:
-
用户提问。
-
知识库检索:先去企业私有知识库捞数据。
-
阈值判断(Code节点):判断检索到的内容相似度是否达标(例如 Score > 0.5)。
-
条件分支(If-Else):
-
命中知识库:直接调用 LLM 基于上下文回答。
-
未命中:调用 Bocha Web Search 进行联网搜索,整理结果后调用 LLM 回答。
-
-
记忆处理:在对话过程中通过变量赋值维护用户偏好。
最终编排概览:(因为编排太长截图看不清楚,所以才拖拽成了这样)
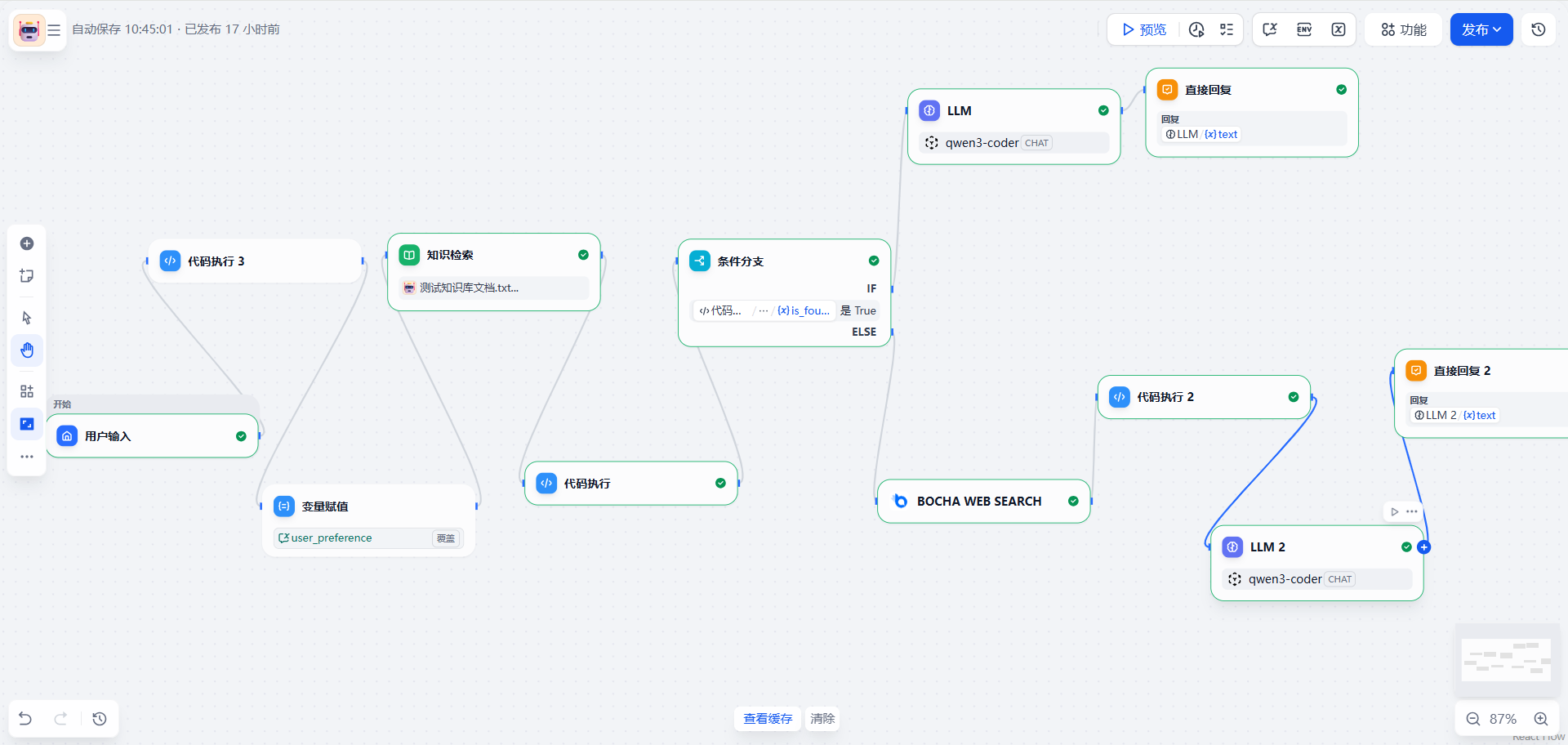
3. 核心节点配置详解
以下是我在搭建过程中几个关键步骤的配置笔记。
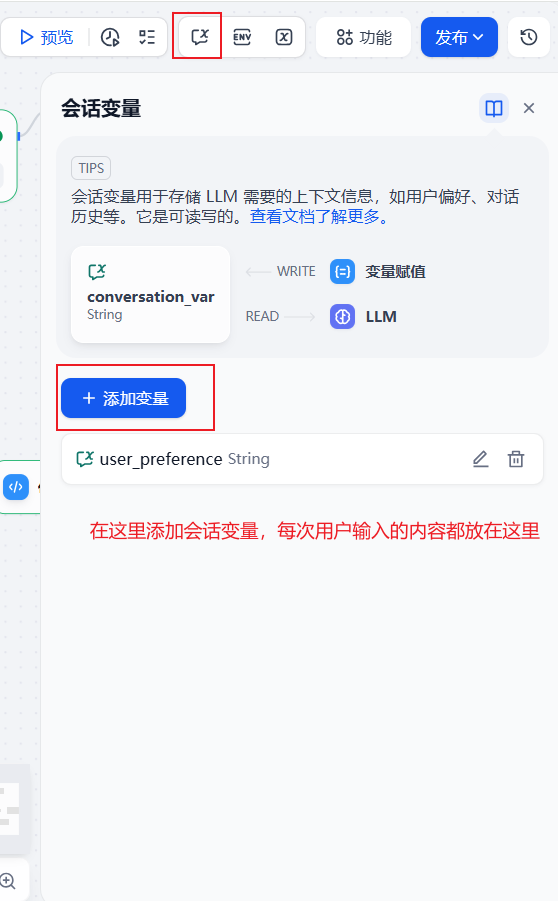
3.1 变量管理与记忆(Assigner 节点)
在工作流中,我尝试记录用户的偏好(User Preference)。这里用到了 变量赋值 (Assigner) 节点。
-
逻辑:将当前的 sys.query (用户输入) 追加到 conversation 变量中。
-
代码预处理:为了拼接字符串,先跑了一段简单的 JS 代码。
先创建会话变量
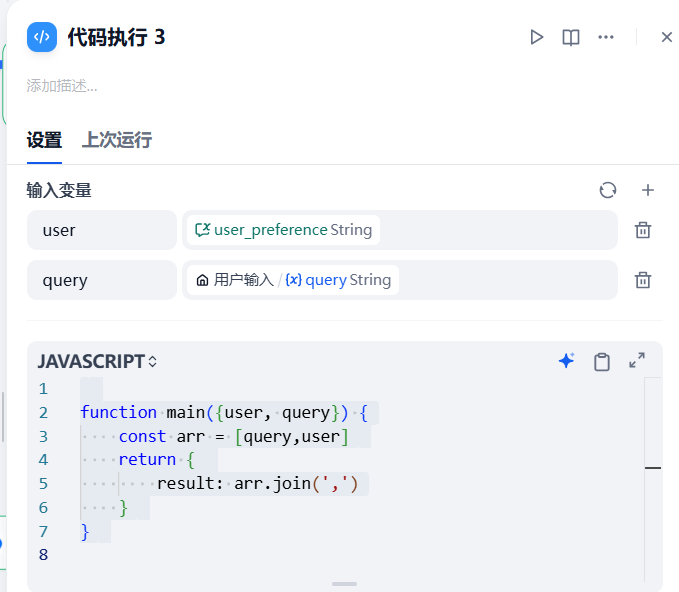
function main({user, query}) { const arr = [query,user] return { result: arr.join(',') } }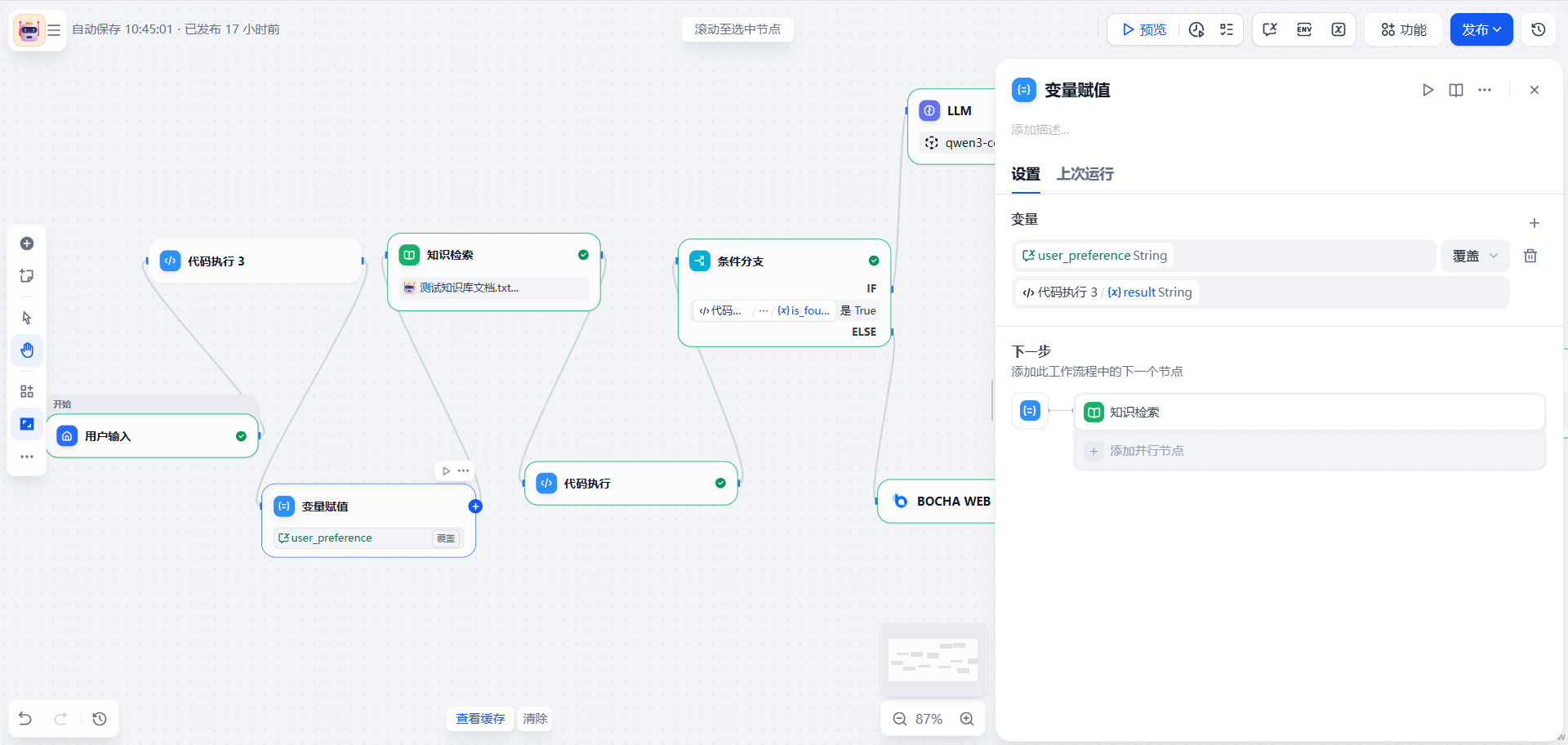
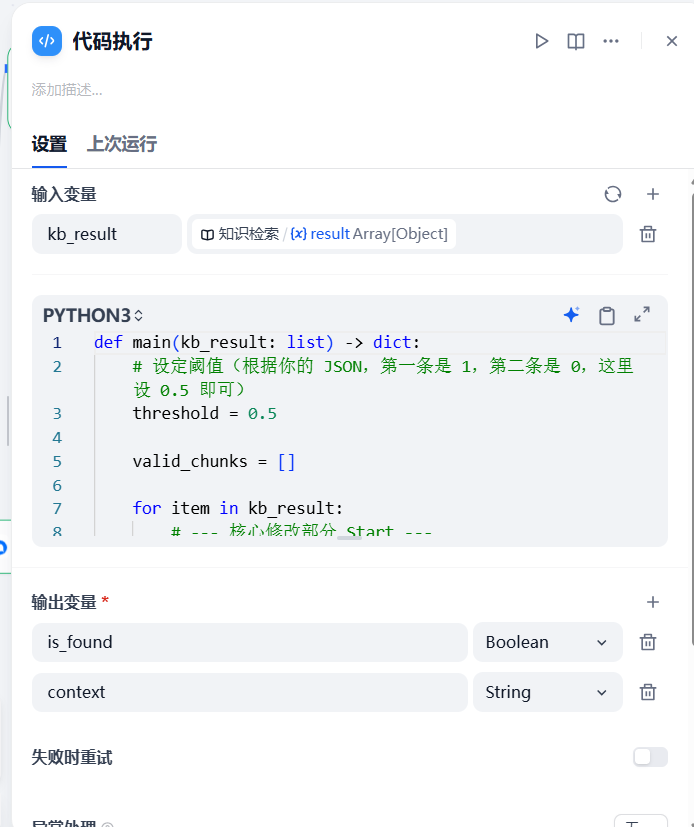
3.2 知识检索与置信度判断(关键!)
这是实现“智能分流”最关键的一步。Dify 的原生知识检索节点会直接输出结果,但我们需要根据 Score(分数) 来决定是否采用。
步骤一:知识库检索
配置 Top K = 4,开启 Rerank(重排),确保拿到的分数是精准的。
步骤二:编写 Python 代码过滤低分块
我加了一个 Code 节点,专门处理检索结果。如果最高分低于 0.5,就视为“未找到”。
# 节点:代码执行 (判断是否命中)
def main(kb_result: list) -> dict:
# 设定阈值
threshold = 0.5
valid_chunks = []
for item in kb_result:
# 兼容处理:尝试获取 rerank 后的 score
metadata = item.get('metadata', {})
score = metadata.get('score')
# 如果 metadata 没拿到,尝试外层 (兼容不同版本 Dify)
if score is None:
score = item.get('score', 0)
# 筛选逻辑
if isinstance(score, (int, float)) and score >= threshold:
content = item.get('content', '')
valid_chunks.append(content)
# 判断是否找到有效内容
is_found = len(valid_chunks) > 0
context_str = "\n\n".join(valid_chunks)
return {
"is_found": is_found,
"context": context_str
}
3.3 条件分支(If-Else)
有了上面的 is_found 变量,条件分支就很好写了。
-
条件:is_found (上一步代码节点的输出) IS True。
-
True 分支:走“内部知识库回答”链路。
-
False 分支:走“联网搜索”链路。
-
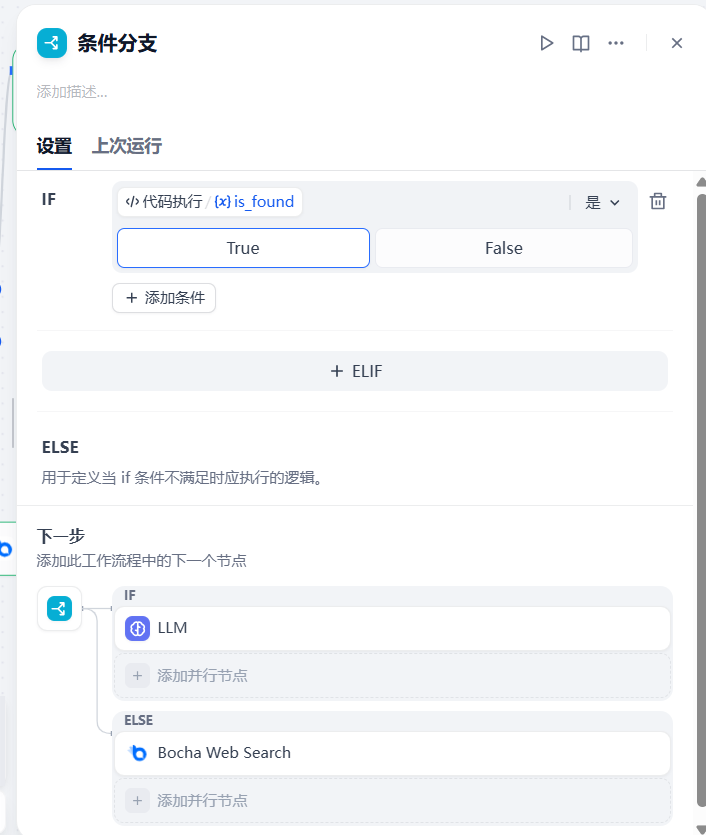
3.4 联网搜索兜底(Bocha Search + 结果清洗)
当知识库没答案时,我们需要联网。这里我使用了 Bocha Web Search 插件(需要在 Dify 插件市场安装)。
-
Tool 节点:调用 BochaWebSearch,传入 query。
-
Code 节点(清洗数据):搜索回来的数据通常是一大坨 JSON,直接扔给 LLM 会消耗大量 Token 且容易由于格式问题导致幻觉。我写了一个解析脚本:
# 节点:代码执行 2 (格式化搜索结果) import json def main(search_result) -> dict: formatted_text = "" data = search_result # 容错处理... (省略部分基础校验代码) if not isinstance(data, list) or len(data) == 0: return {"text": "未找到搜索结果。"} # 提取 webpage 数组 first_item = data[0] pages = first_item.get('webpage', []) # 拼接格式化文本供 LLM 阅读 for idx, page in enumerate(pages, 1): title = page.get('name', '无标题') url = page.get('url', '#') content = page.get('summary') or page.get('snippet', '') formatted_text += f"【引用 {idx}】{title}\n链接: {url}\n内容: {content}\n\n" return { "text": formatted_text }LLM 节点(联网版):
提示词设置为:内部知识库中未找到答案,已为你搜索互联网。 搜索结果:{{#1770716460867.text#}} // 这个是上一步python代码执行后的输出 请根据搜索结果回答:{{#sys.query#}}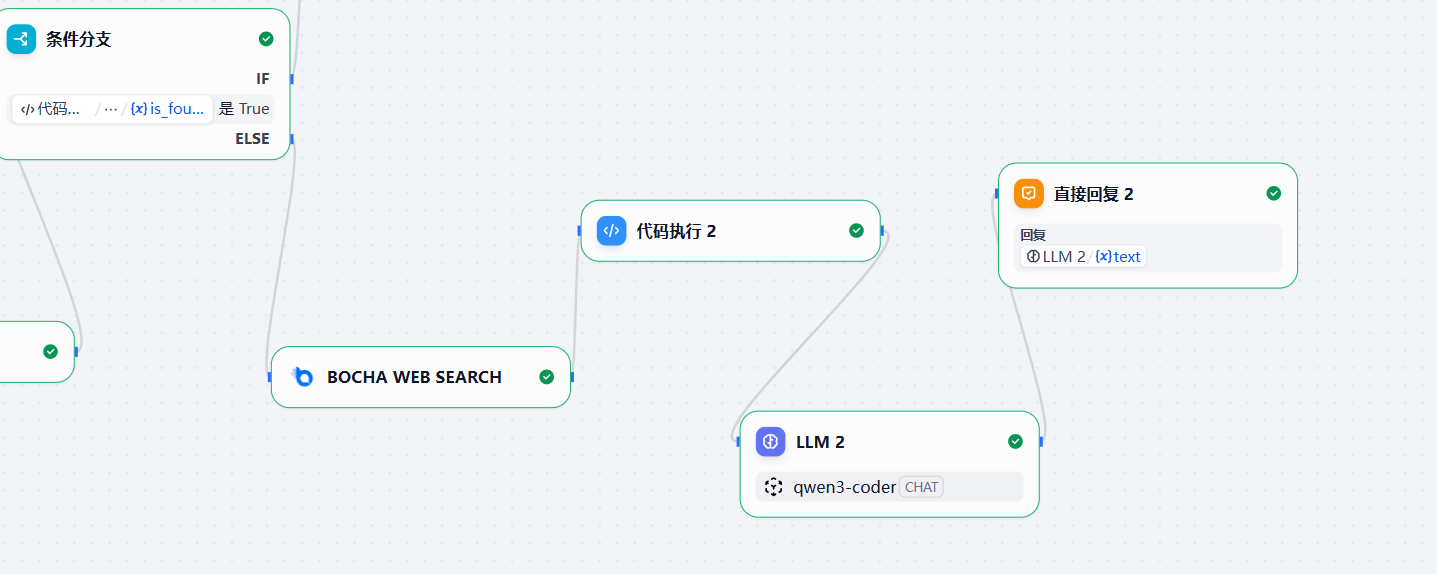
4. 调试与效果验证
点击右上角的 “预览/运行” 进行测试。
测试案例 1:命中知识库
输入我知识库里有的内容(例如:Dify 部署架构)。
-
预期:If-Else 走 True 分支,直接利用 RAG 回答,速度快。
测试案例 2:未命中,触发联网
输入最近的新闻(例如:2024年 OpenAI 发布的 Sora 模型)。
-
预期:知识库 Score 低于 0.5 -> If-Else 走 False -> 调用 Bocha -> LLM 总结搜索结果。
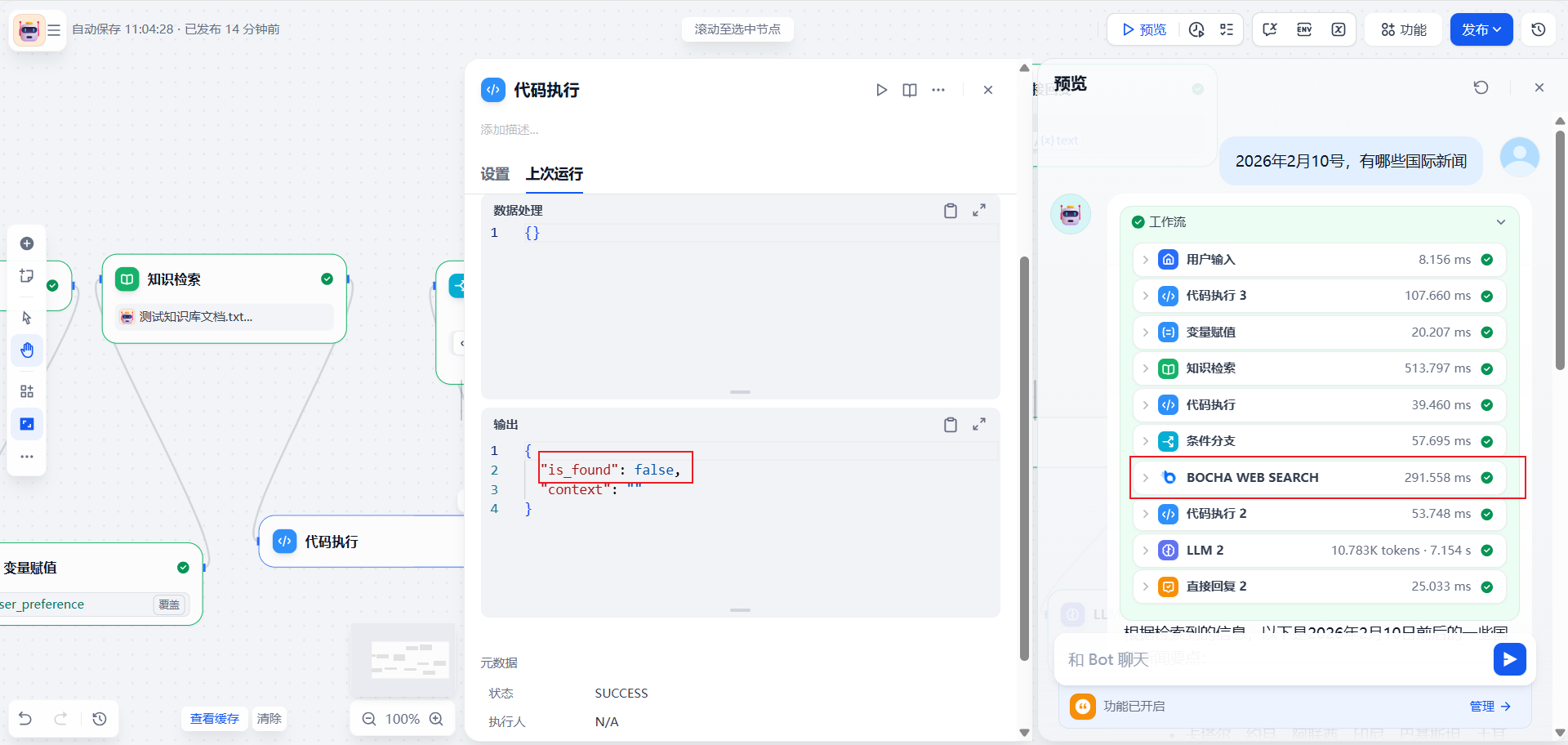
5. 总结
通过这次实战,我们将 Dify 从一个简单的“文档问答器”升级为了具备逻辑判断能力的业务系统。
核心沉淀:
-
Code 节点是胶水:Dify 的原生节点输出有时不满足逻辑判断需求(比如缺少布尔值状态),通过 Python 简单处理一下(如本例中的 Score 阈值判断)能极大增强灵活性。
-
双路召回架构:优先内网 RAG,兜底外网 Search,这几乎是企业级 AI 客服的标配架构。
-
结构化思维:Chatflow 强迫我们像画流程图一样思考业务逻辑,比写长篇大论的 Prompt 更可控、更稳定。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)