OpenClaw 背后的秘密武器:极简智能体框架 Pi
当别人都在做加法的时候,Pi 选择了做减法。真正有力的系统,往往不是什么都有,而是底座足够稳、能力能自己长出来。正如 Armin 在文末写的——把软件接到聊天里、让 AI 直接写代码跑代码,这种形态正在飞速增长。而 Pi 这种极简但可演化的底座,很可能就是未来的方向之一。
Armin 自己就是这么干的。他用 Pi 写了一个基于 CDP 的浏览器自动化 skill,完全替代了他之前用的所有浏览器相关的 CLI 和 MCP 工具。不是因为那些替代品不好用,而是因为让 Agent 自己维护自己的功能,太自然了。
这几天 OpenClaw 在圈子里刷屏了。它曾用过 ClawdBot、MoltBot 等名字,核心能力很直接:接入你的聊天渠道,让 AI 直接写代码、跑代码。
但我更在意的不是 OpenClaw 本身,而是它背后的底座——Pi(以及它所在的 pi-mono 工具包)。
Pi 是由 Mario Zechner 开发的一个极简 coding agent 引擎。Armin Ronacher(Flask 的创造者)最近专门写了一篇长文来讲他为什么"上瘾"了——Pi 是他目前几乎唯一在用的 coding agent。
Pi 的默认工具只有四个:Read、Write、Edit、Bash。
听起来寒酸,但它把一件事做得极致:让模型在一个可控的闭环里读代码、写代码、改代码、跑起来验证;需要新能力时,不是先把工具列表堆到一百项,而是让 Agent 用代码"长出"新能力。
这篇文章我想把三件事讲清楚:
Pi 为什么刻意极简。pi-mono 那 7 个包各自负责什么。以及 OpenClaw 这种"把 Agent 接到聊天里"的形态,为什么更依赖底层工程约束,而不是华丽的 UI。
太长不看版
• Pi 的价值不在"功能多",而在"闭环完整"。 四个工具覆盖开发主路径:读→改→跑→再读
• 极简内核背后是扩展系统。 扩展能把状态写进会话,配合热重载,Agent 能自己写扩展、自己迭代
• 会话是树形结构。 你可以分支去修一个坏掉的工具或尝试另一种方案,修好再带回主线
• 不内置 MCP,不是偷懒,是哲学。 Pi 的理念是:需要新能力?让 Agent 自己写一个
• OpenClaw 之所以能"接到聊天里还可用",靠的是工程化约束。 默认串行、命令白名单、可回放的会话日志
• 记忆系统越朴素越好维护。 Markdown 记事实,JSONL 记对话,再叠检索层就够了
先把 Pi 放回正确的分类里
很多人看到"Pi 是一个 coding agent",会下意识把它当成 IDE 里的某条功能线——补全、重构、生成单测。
Pi 不是这样。
Pi 更像"引擎"而不是"应用"。 它把 Agent 的最小可行形态拆到几乎不能再拆:给模型一个工作目录、四个工具、一套会话记录方式、以及一套扩展机制。
Armin 在文中特别提到 Pi 本身的工程质量:不闪烁、不吃内存、不会随机崩溃——它是由一个对软件品质极度在意的人写的。这个评价本身,就是一种很硬的背书。
你可以用 Pi 的核心组件搭建自己的 agent 产品。OpenClaw 就是这么做的;Armin 自己做了一个 Telegram bot;Mario 则做了一个叫 pi-mom 的 Slack bot。换句话说,如果 OpenClaw 是汽车,Pi 就是让它发动的引擎。
pi-mono 的 7 个包:每个解决一个清晰问题
如果只看名字,pi-mono 很像"又一个 agent 项目合集"。但拆开看,每个包的边界很干净。
下面这张图展示了它们之间的依赖关系——注意看层级:入口层、运行时、模型抽象、资源配置各自独立,组合方式留给你的产品形态。
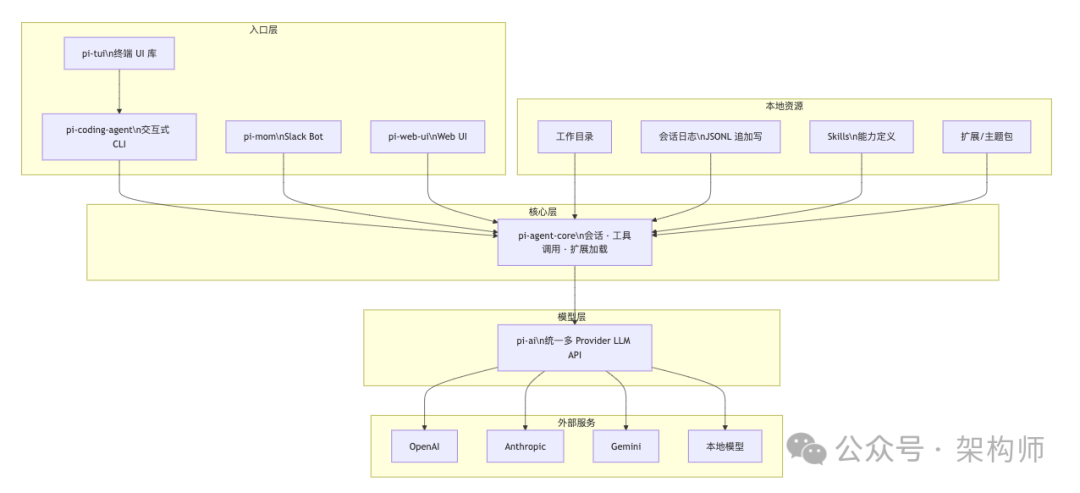
各包职责一句话说清:
|
包名 |
一句话 |
|
|
把 OpenAI / Anthropic / Gemini / 本地模型统一成同一种调用方式——LLM 的驱动层 |
|
|
核心运行时:会话管理、工具调用循环、扩展加载——引擎本体 |
|
|
把上两层封装成交互式 CLI——你最可能碰到的入口 |
|
|
Slack bot,把消息委托给 coding agent 处理 |
|
|
终端 UI 组件库,灵活到能在里面跑 Doom(真的) |
|
|
Web 端的交互组件 |
|
|
vLLM / GPU pods 的部署与管理 CLI |
是的,pi-tui 灵活到 Mario 证明了可以在里面跑 Doom[1]。虽然不实用,但如果你能跑 Doom,你当然能做一个好用的调试仪表盘。
四个工具,为什么反而更强
写软件这件事,本质上是一个循环:
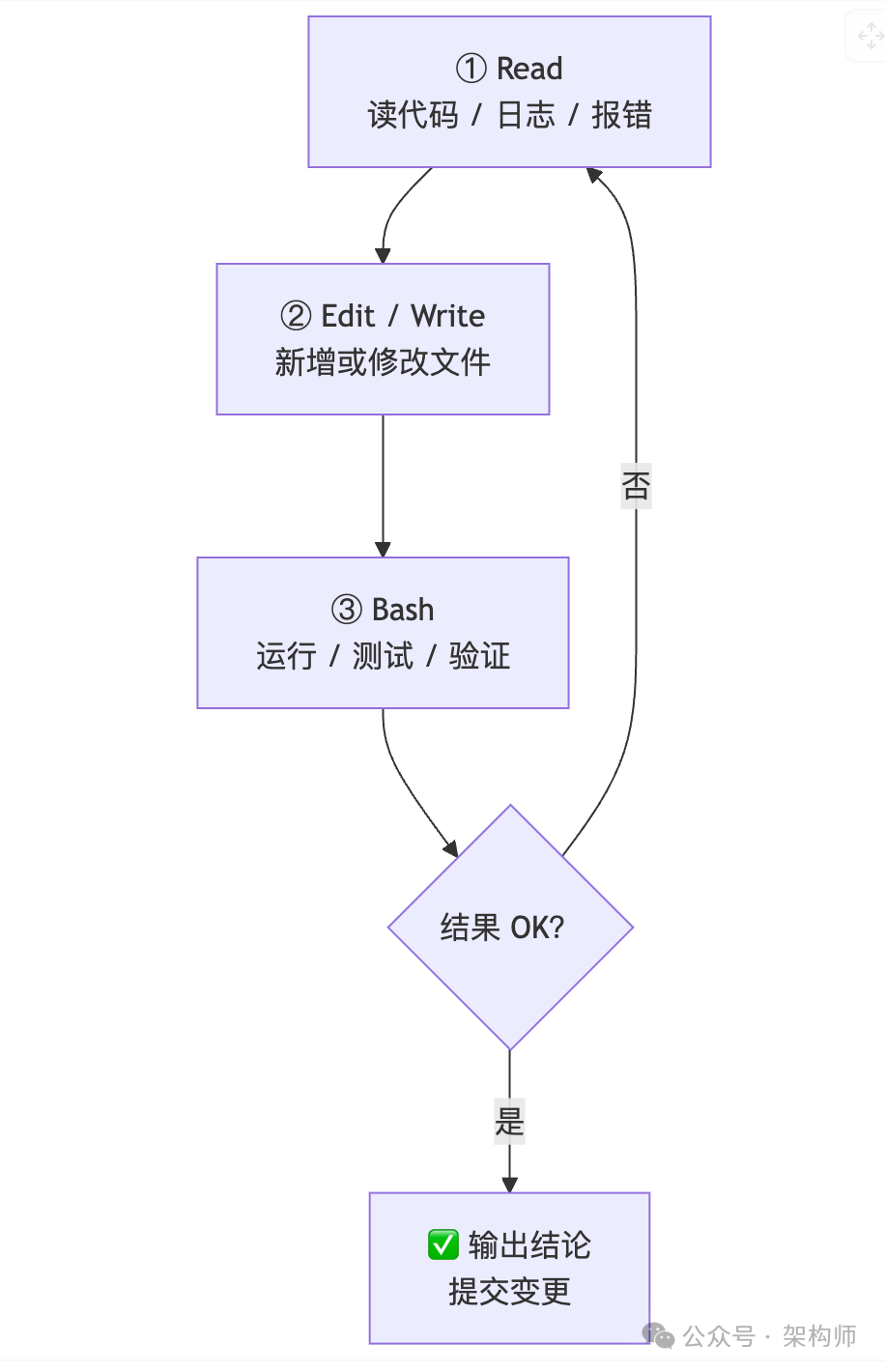
如果工具系统能稳定覆盖这个循环,剩下的"看起来很高级"的能力,其实很多只是工作流包装。
极简的好处有三个:
上下文更干净。 工具越多,系统提示词越长,模型越容易"误用工具"或把工具当成能力本身。Armin 提到 Pi 拥有他所知最短的系统提示词——这不是巧合。
可审计性更强。 四个工具带来的副作用更可控。当出问题时,你能更清楚地知道 Agent 做了什么。
逼着你把工程约束前置。 命令白名单、目录隔离、会话持久化、失败回滚——这些才是"能不能长期用"的分水岭。
一个朴素的偏好:先把"跑得通"变成"跑得稳",再去追求"能跑更多花活"。
真正的关键:扩展不是"加工具",而是"长能力"
Pi 不是"只有四个工具就结束了"。它把可塑性押注在扩展系统上,做对了三点:
(1)扩展能把状态写进会话
你可以把"这次任务的配置""外部系统的映射关系""上次审查的结论"等,作为扩展状态跟着会话走。不需要每次都重新提示一遍。
(2)扩展支持热重载
这意味着一个关键工作方式成立了:
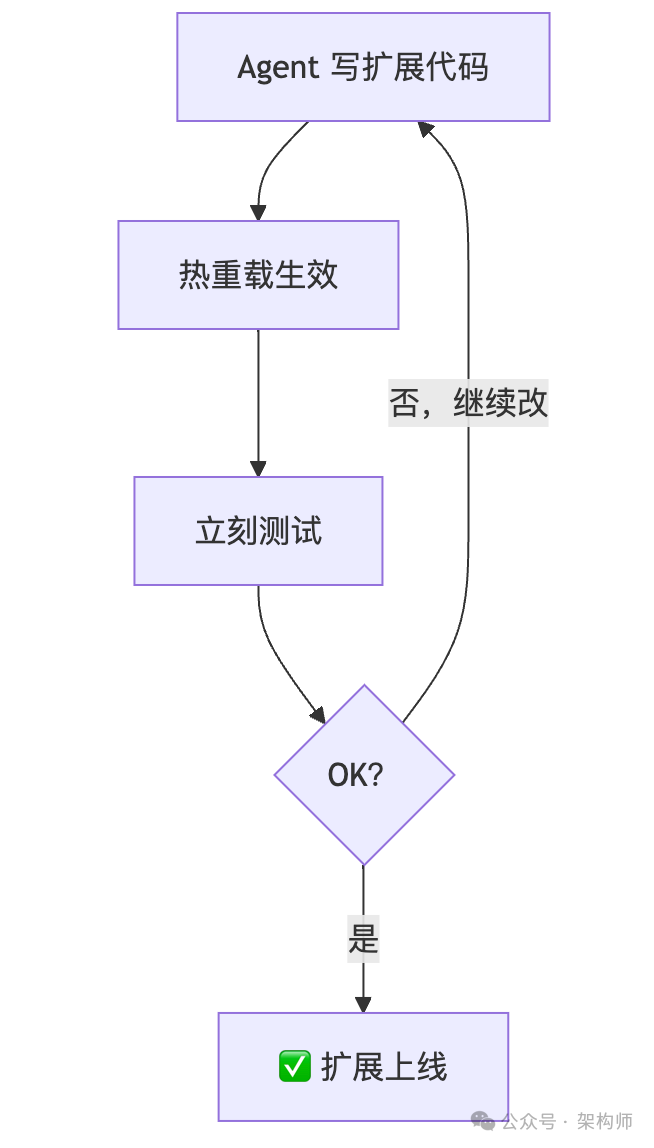
"让 Agent 维护自己的能力"不再是口号,而是一条可重复的工程路径。
(3)Pi 自带文档和示例,供 Agent 参考
Pi 仓库里附带了扩展的文档和示例代码。这意味着当你让 Agent 写一个新扩展时,它不是从零猜测——它能参考现有的实现来"照着做"。
为什么不内置 MCP?这不是偷懒
这是关于 Pi 最容易被误解的一点。Armin 在文中说得很明确:这不是一个懒惰的遗漏,这来自于 Pi 的工作哲学。
Pi 的核心理念是:如果你想让 Agent 做它还不能做的事,不要去下载一个扩展或技能——你让 Agent 自己写一个。
这并不意味着你不能下载别人的扩展(这完全支持)。但更推荐的做法是:你指着一个已有的扩展,跟 Agent 说——"照着那个做,但加上这些我想要的改动"。
Armin 自己就是这么干的。他用 Pi 写了一个基于 CDP 的浏览器自动化 skill,完全替代了他之前用的所有浏览器相关的 CLI 和 MCP 工具。不是因为那些替代品不好用,而是因为让 Agent 自己维护自己的功能,太自然了。
如果确实需要 MCP,OpenClaw 的做法是使用 mcporter[2]——一个把 MCP 调用暴露为 CLI 接口的工具。够用就行,不需要内置到核心。
树形会话:把试错做成可控的分支
做复杂任务时最怕两件事:
• 想试一个大胆方案,但担心把当前进度弄乱
• 某个工具坏了,不得不在主对话里一边修一边解释,上下文被污染
Pi 的会话结构是树形的,协作方式更像 Git:
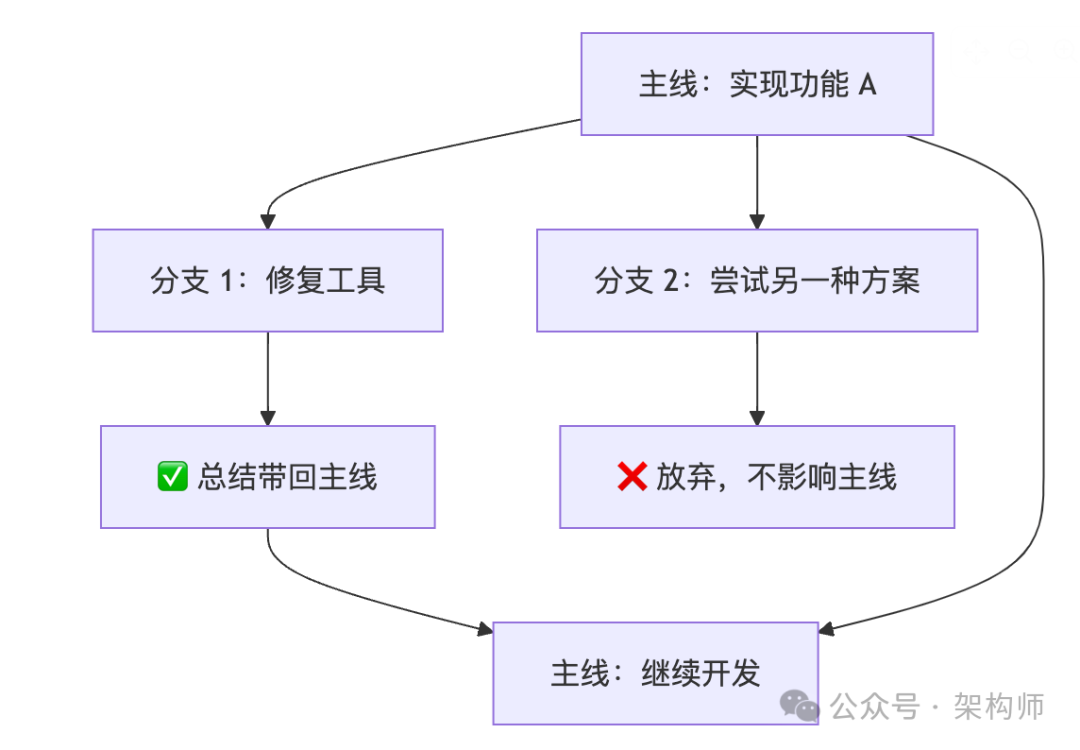
分支里发生的事情可以被总结,再带回主线。Armin 提到一个典型场景:在分支里做代码审查(用 /review 扩展),拿到审查结论后,在主线上做修复。
这对 coding agent 特别关键——开发不是直线任务,更多时候是并行试探和回滚。
实用扩展案例:它们解决的是"工作流"
Armin 分享了他日常使用的几个扩展。值得注意的是:这些扩展全部不是他自己手写的,而是他让 Pi 按照自己的要求写出来的。

|
扩展 |
解决什么问题 |
|
|
Agent 回复里的问题散落各处?提取出来,变成清爽的输入框 |
|
|
在 |
|
|
展示 diff、未提交改动、新增依赖——让"能跑"变成"敢让它跑" |
|
|
列出会话里引用过的文件,支持在 Finder/VSCode 中打开或对比 |
|
|
让一个 Agent 给另一个 Agent 发提示,做轻量的分工实验 |
社区也开始出现第三方扩展:subagent 扩展[3]、interactive-shell[4](让 Pi 在可观察的 TUI 覆盖层中自主运行交互式 CLI)。
这些扩展的共性是:它们不是在"发明新工具",而是在让协作更顺滑、让复盘更省力、让错误更早暴露。
OpenClaw 这类产品,靠什么从"能跑"变成"能用"
把 Agent 接入聊天渠道,最大的挑战常常不在模型会不会写代码,而在系统会不会失控。
(1)默认串行,显式并行
多智能体/多任务系统里,异步并发最先伤到的是可读性和可调试性:日志交错、状态竞态、问题难复现。
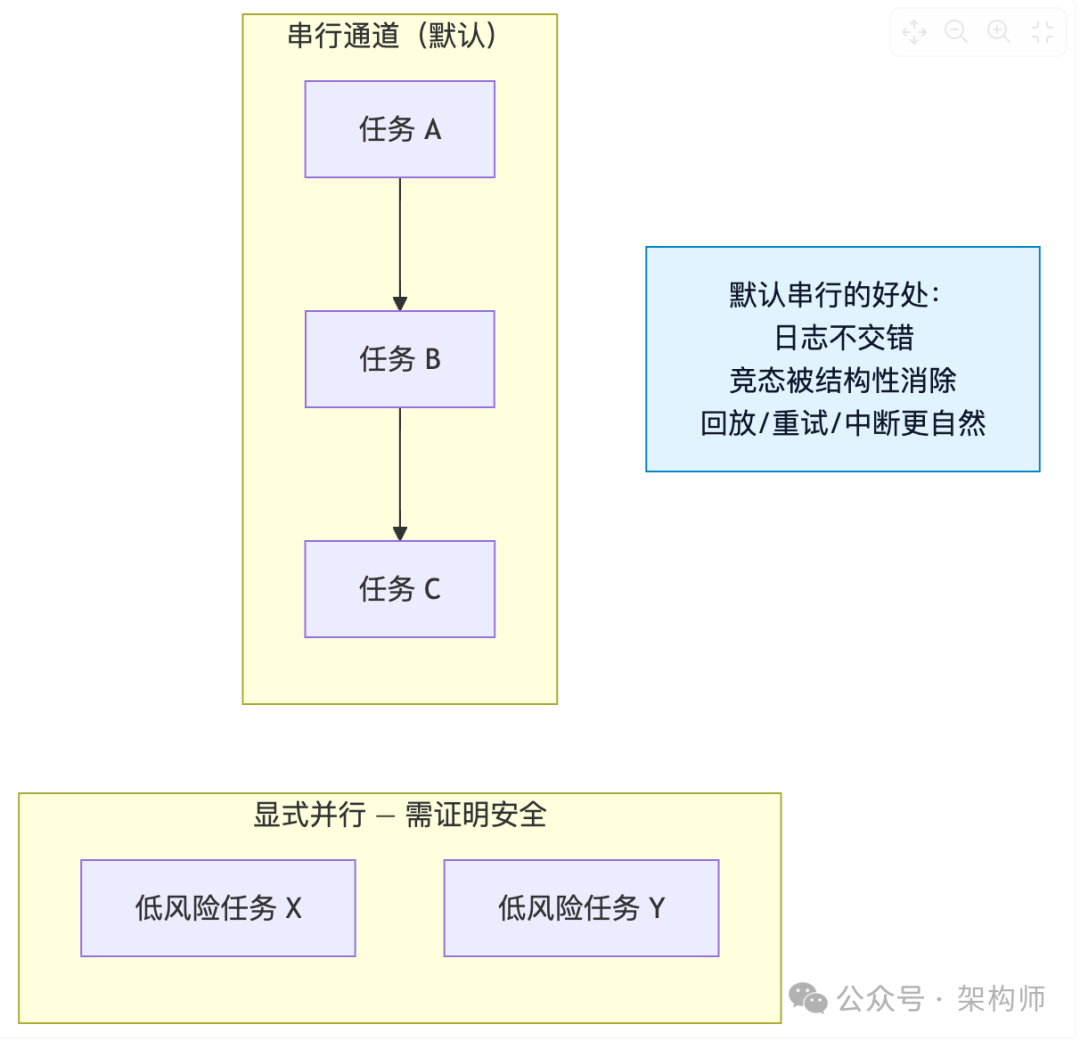
一个更工程化的心智模型:并行是一种需要证明安全的特权,不是默认权利。
有些实现会把每个会话绑定到一个 Lane(通道),让命令天然串行排队。日志不交错、竞态被结构性消除、回放/重试都更自然。
(2)记忆用文件系统,检索再叠一层
比起复杂的"专用记忆 API",更耐用的路径:
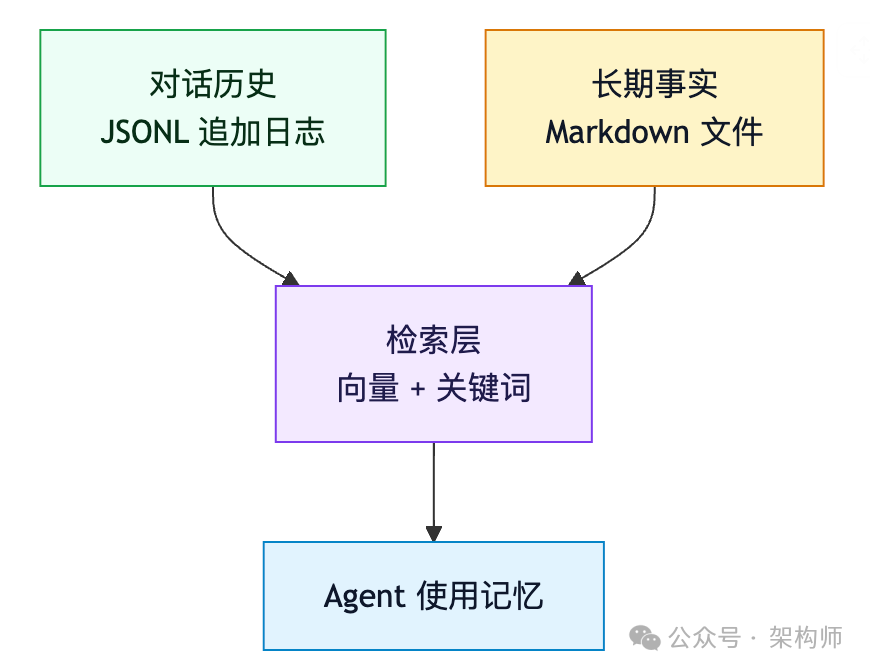
好处是可迁移、可审计、可手工修。如果你被"记忆系统"这四个字吓过,先接受这种土办法:让事实先落地成文件,再谈智能。
(3)浏览器自动化:语义快照优于截图
截图对视觉模型自然,但对纯文本模型是负担:体积大、坐标定位难、成本高。
用可访问性树(ARIA)导出的语义快照,页面变成这样:
- button "Sign In" [ref=1]
- textbox "Email" [ref=2]
- textbox "Password" [ref=3]模型直接引用 ref 做操作。成本低,也更像"读结构化数据"而不是"看图找点"。Armin 自己就用 Pi 写了一个基于 CDP 的浏览器 skill 来替代所有截图方案。
(4)安全策略:白名单优先,黑名单兜底
当 Agent 能跑 bash,安全不是可选项。更现实的做法是允许用户配置可执行命令白名单:
{
"agents": {
"main": {
"allowlist": [
{ "pattern": "/usr/bin/jq" },
{ "pattern": "/usr/bin/rg" },
{ "pattern": "/usr/bin/sed" }
]
}
}
}把"允许执行什么命令"当成配置写出来,不同项目、不同环境可以不同,而不是用提示词去赌模型记得住。
一张表看懂两条路线
|
维度 |
"堆工具/堆技能"路线 |
"极简闭环 + 扩展"路线(Pi) |
|
上手体验 |
一开始更爽,功能列表很长 |
更克制,要先建立工作方式 |
|
长期维护 |
工具治理成本高,越用越复杂 |
先约束边界,再按需生长 |
|
可审计性 |
工具多 → 行为面更大 |
工具面小 → 更容易看清 |
|
定制能力 |
依赖生态质量与兼容性 |
直接用代码定制,贴合任务 |
|
风险控制 |
常靠提示词约束,容易漂 |
配置与工程约束为主 |
|
能力增长 |
下载安装,被动等生态 |
Agent 自己写,主动长出来 |
这不是对错题。它更像你在做工程决策时的一个选择:你更愿意为"短期惊艳"付出多少"长期治理成本"。
我怎么判断一个 coding agent "能不能长期用"
看模型指标有用,但我更在意三件"土"事,它们决定了你能不能把它放进真实工作流:
1. 出问题时能不能复盘。 有没有完整日志?能不能回放一次会话里做过的改动?能不能快速定位是哪条工具调用把事情带偏了?
2. 变更能不能被审查。 有没有差异视图?有没有"新增依赖提醒"?有没有一个机制让你在合并之前把风险看清楚?
3. 能力能不能被沉淀。 你这次踩过的坑,下一次能不能靠扩展/脚本/测试直接避开?还是又写一遍提示词?
Pi 的极简给我的感觉是:它把这些"工程信号"放在了比"功能列表"更前面的位置。
如果你也想做"自己的 OpenClaw"
代价与边界:极简不是银弹
Pi 这条路线也有明显取舍:
• 它要求你接受"能力由代码长出来"。 对工程师友好,对纯业务使用者可能不够即插即用
• 扩展生态不是一开始就有的。 你会更依赖自己(或团队)维护扩展与工作流
• 文件化记忆会变大、会变乱。 需要配套的整理策略,否则"可审计"会变成"可怕的堆积"
• 它对工程素养有要求。 Armin 说得很直接——他的扩展和 skill 都是让 Agent 写的,但你得知道要让 Agent 写什么
所以它更适合两类人:想把 Agent 当作长期生产工具的人,或者想自己做 Agent 产品的人。
一句话总结
当别人都在做加法的时候,Pi 选择了做减法。而 OpenClaw 的爆火证明了:真正有力的系统,往往不是什么都有,而是底座足够稳、能力能自己长出来。
正如 Armin 在文末写的——把软件接到聊天里、让 AI 直接写代码跑代码,这种形态正在飞速增长。而 Pi 这种极简但可演化的底座,很可能就是未来的方向之一。
参考
• Armin Ronacher:Pi: The Minimal Agent Within OpenClaw[5](2026-01-31)
• Pi 源码仓库:github.com/badlogic/pi-mono[6]
• Armin 的扩展与 skills:github.com/mitsuhiko/agent-stuff[7]
• OpenClaw 官网:openclaw.ai[8]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献242条内容
已为社区贡献242条内容

所有评论(0)