【OpenAI】Google Gemini 3 Pro多模态内容生成实战教程:文本+图片联合输入快速上手获取OpenAI API KEY的两种方式,开发者必看全方面教程!
通过以上步骤,你已经掌握了如何获取和使用 OpenAI API Key 的基本流程。无论你是开发者还是技术爱好者,掌握这些技能都将为你的项目增添无限可能!🌟。
【爆款详解】Google Gemini 3 Pro Preview深度解析:AI新时代的多模态革命,入门教程+实战技巧全攻略!
你是否好奇Google最新发布的Gemini 3 Pro到底有多强?它如何引领AI多模态技术新潮流?本文将带你全面揭秘Gemini 3 Pro的核心优势、应用场景及实操教程,助你快速掌握这款划时代的智能引擎,开启AI创新之路!🚀
一、引言:为什么Google Gemini 3 Pro值得你关注?
在AI技术飞速发展的今天,Google Gemini 3 Pro作为Google最新推出的多模态大模型,融合了文本、图像、视频等多种信息,极大提升了机器理解和生成的能力。它不仅是技术的突破,更是产业升级的关键驱动力。
想象一下,你只需一句话加上一张图片,Gemini 3 Pro就能帮你生成高质量的内容、智能分析复杂场景,甚至辅助决策。这样的能力,正在改变各行各业的工作方式。
故事分享:
小李是一家内容创业公司的技术负责人,过去他们的编辑团队每天需要花费大量时间整理素材、撰写图文内容。自从引入Gemini 3 Pro后,只需输入简单的文字描述和相关图片,系统就能自动生成高质量的新闻稿件,团队效率提升了3倍,内容质量也获得了用户的高度认可。小李感叹:“这真是内容创作的革命!”
二、Google Gemini 3 Pro核心优势详解
| 优势点 | 详细说明 |
|---|---|
| 多模态融合能力 | 支持文本、图像、视频等多种数据类型联合理解与生成 |
| 超强推理性能 | 采用最新架构优化,响应速度快,适合实时交互和大规模应用 |
| 广泛适用场景 | 适合内容创作、智能客服、医疗诊断、自动驾驶等多个领域 |
| 灵活部署方案 | 支持云端、本地及混合部署,满足不同企业安全和性能需求 |
2.1 多模态融合的技术突破
Gemini 3 Pro通过深度神经网络架构,能够同时处理文字、图片、视频等多种信息源,实现跨模态的语义理解和生成。这意味着它不仅能“看懂”图片,还能结合文字内容,生成更符合上下文的答案或内容。
2.2 超强推理性能保障实时体验
得益于Google强大的算力支持和模型优化,Gemini 3 Pro在保持高准确率的同时,实现了秒级响应,满足在线客服、智能助手等实时交互场景需求。
三、Gemini 3 Pro实战教程:快速上手多模态AI应用
3.1 环境准备与安装
在开始之前,请确保你已经拥有Google Gemini 3 Pro的API访问权限,并安装了官方SDK。
pip install google-gemini3pro-sdk
## 第一种方式(国外):获取 OpenAI API Key
要开始使用 OpenAI 的服务,你首先需要获取一个 API Key。以下是获取 API Key 的详细步骤:
### 1. 访问 OpenAI
在浏览器中点击 [OpenAI ](https://www.openai.com)。
### 2. 创建账户
- 点击网站右上角的“**Sign Up**”或者选择“**Login**”登录已有用户。
### 3. 进入 API 管理界面
- 登录后,导航到“**API Keys**”部分。
### 4. 生成新的 API Key
- 在 API Keys 页面,点击“**Create new key**”按钮,按照提示完成 API Key 的创建。
> **注意**:创建 API Key 后,务必将其保存在安全的地方,避免泄露。🔒

## 使用 OpenAI API
现在你已经拥有了 API Key 并完成了充值,接下来是如何在你的项目中使用 GPT-4.0 API。以下是一个简单的 Python 示例,展示如何调用 API 生成文本:
```python
import openai
import os
# 设置 API Key
openai.api_key = os.getenv("OPENAI_API_KEY")
# 调用 GPT-4.0 API
response = openai.Completion.create(
model="gpt-4.0-turbo",
prompt="鲁迅与周树人的关系。",
max_tokens=100
)
# 打印响应内容
print(response.choices[0].text.strip())
代码解析
- 导入库:首先导入必要的库。
- 设置 API Key:通过环境变量设置 API Key。
- 调用 API:发送一个包含问题的请求到 GPT-4.0 模型。
- 打印响应:打印出模型生成的答案。

第二种方式(国内):获取 能用AI API Key
要开始使用 能用AI 的服务,以下是获取 API Key 的详细步骤:
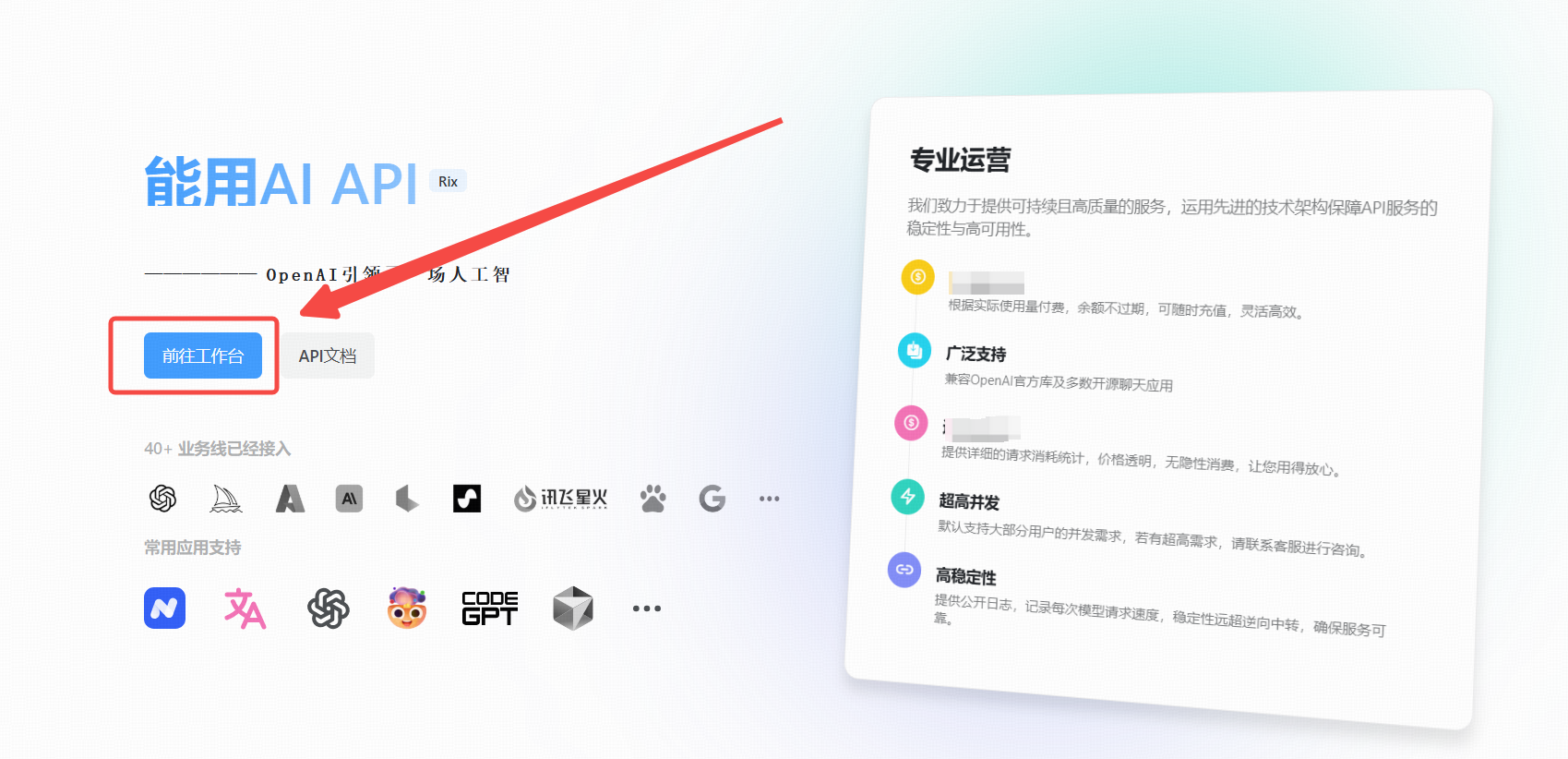
1. 点击 [能用AI 工具]
在浏览器中打开 能用AI 工具。
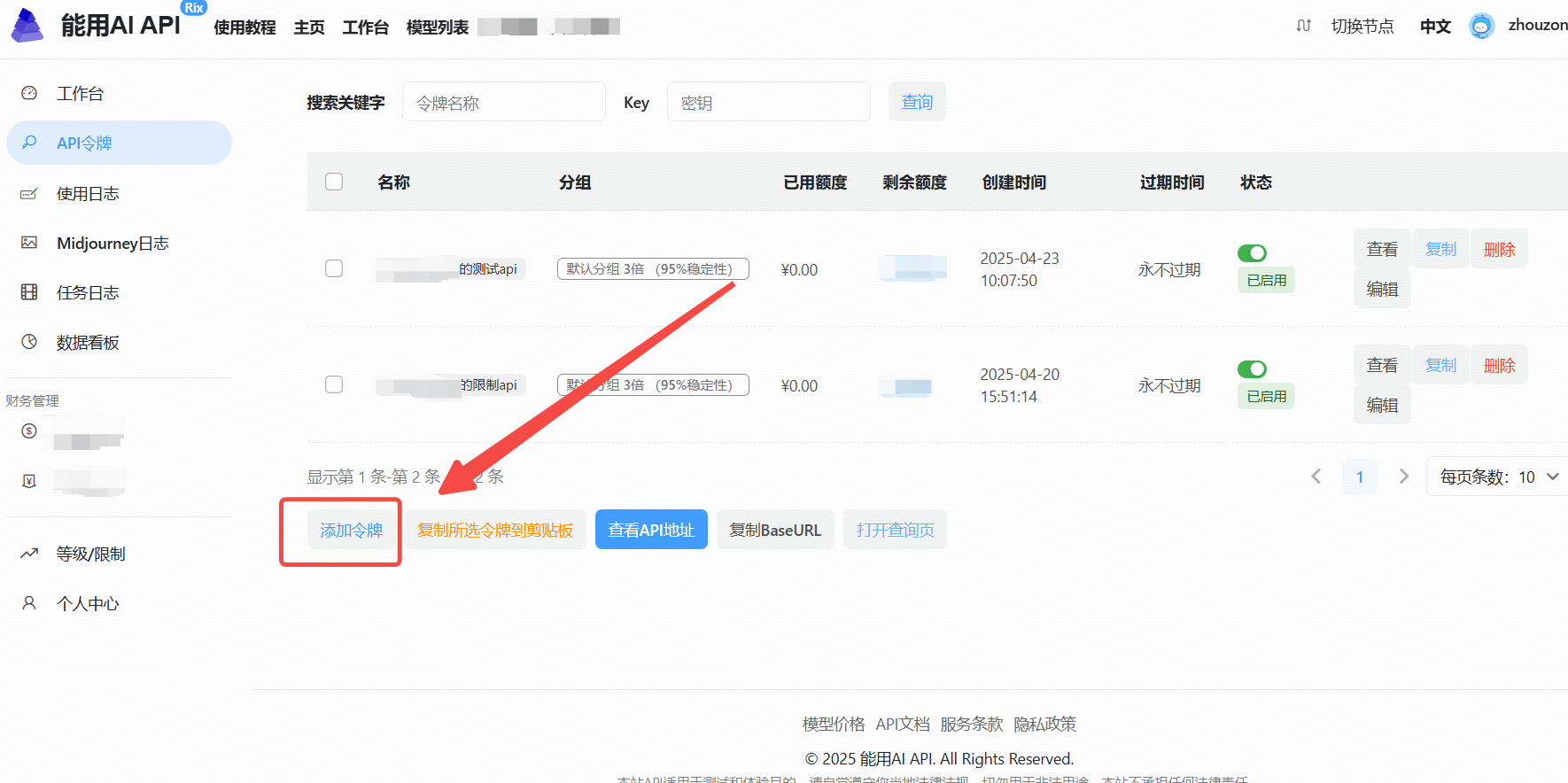
2. . 进入 API 管理界面
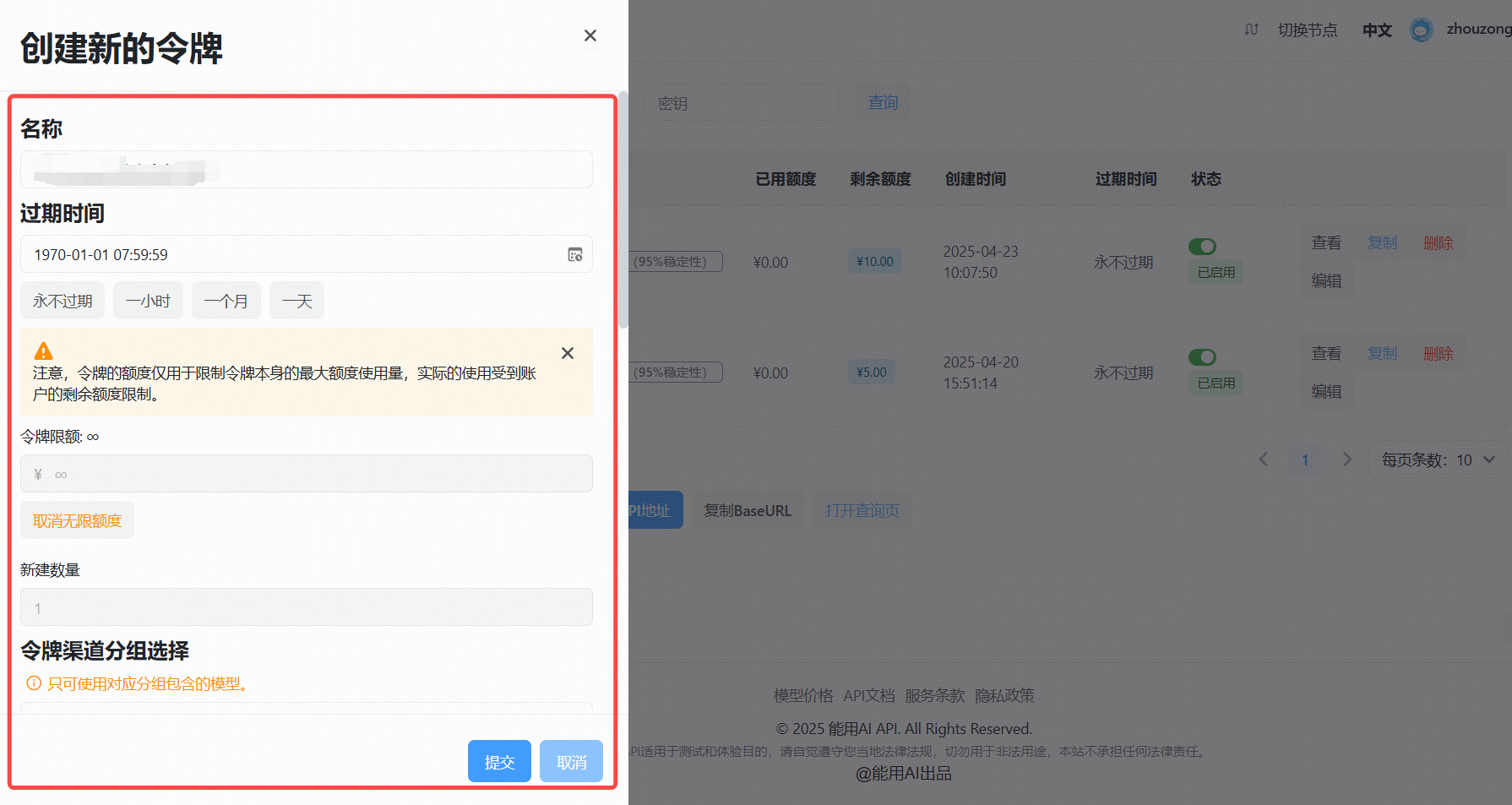
3. 生成新的 API Key
创建成功后点击“查看KEY”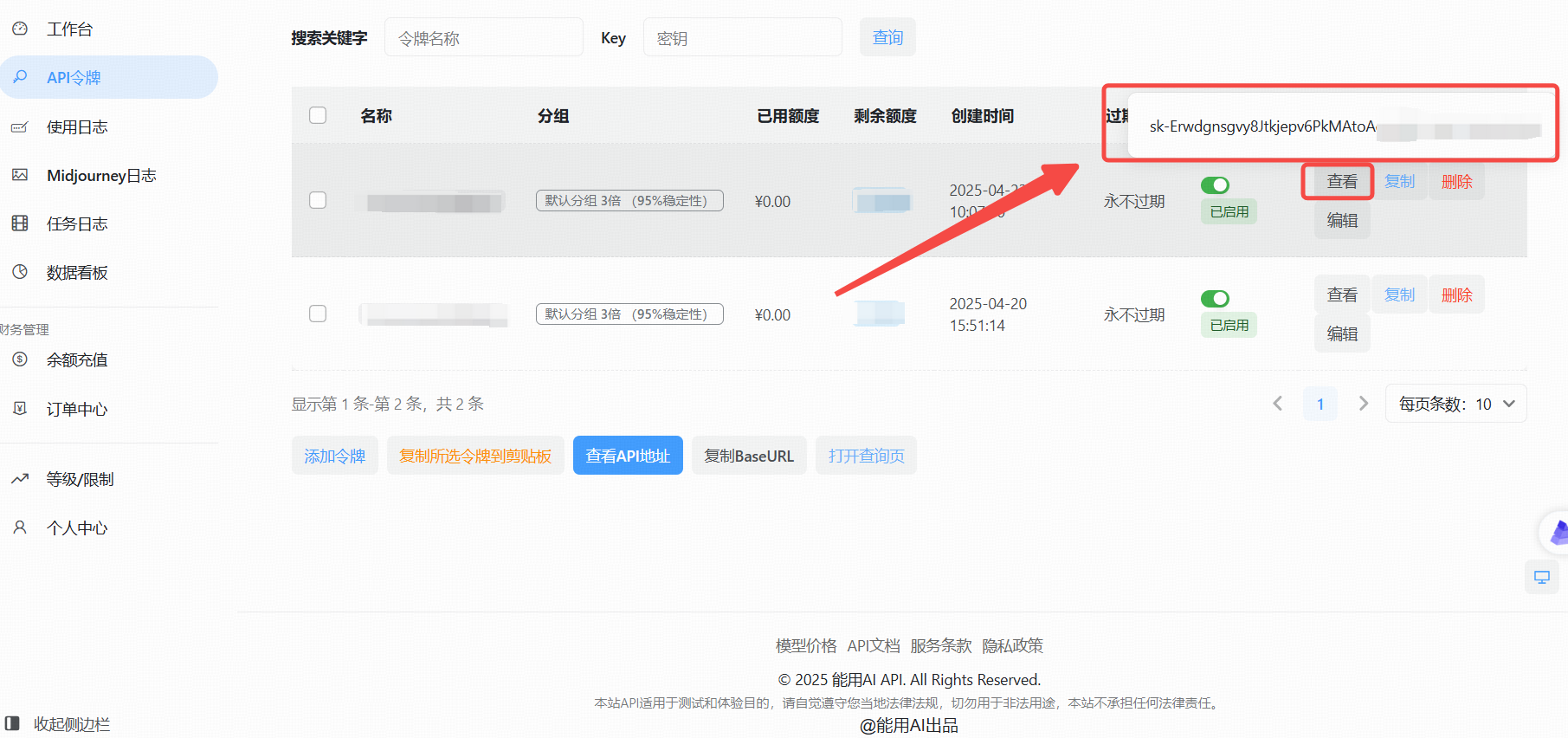
4. 调用代码使用 能用AI API
# [调用API:具体模型大全](https://flowus.cn/codemoss/share/42cfc0d9-b571-465d-8fe2-18eb4b6bc852)
from openai import OpenAI
client = OpenAI(
api_key="这里是能用AI的api_key",
base_url="https://ai.nengyongai.cn/v1"
)
response = client.chat.completions.create(
messages=[
{'role': 'user', 'content': "鲁迅为什么打周树人?"},
],
model='gpt-4',
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end="", flush=True)
总结
通过以上步骤,你已经掌握了如何获取和使用 OpenAI API Key 的基本流程。无论你是开发者还是技术爱好者,掌握这些技能都将为你的项目增添无限可能!🌟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)