[论文阅读] AI + 软件工程 | 34.43%性能提升!TraceCoder解锁LLM生成代码自动化调试新范式
大语言模型(LLMs)生成的代码常含隐性关键缺陷,现有自动化修复方法依赖二值反馈,故障定位模糊且无法从失败中学习,易陷入低效循环。为此提出迹驱动多智能体框架TraceCoder,模拟人类专家调试流程:通过插装智能体捕获细粒度运行时迹,分析智能体做因果故障分析,修复智能体执行靶向修复;结合历史经验学习机制(HLLM)避免重复错误,回滚机制(RM)保证修复稳定收敛。多基准实验表明,TraceCoder
34.43%性能提升!TraceCoder解锁LLM生成代码自动化调试新范式
论文信息
- 原标题:TraceCoder: A Trace-Driven Multi-Agent Framework for Automated Debugging of LLM-Generated Code
- 主要作者及研究机构:
- 黄江平(重庆邮电大学计算机科学与技术学院)
- 叶文广(重庆邮电大学计算机科学与技术学院)
- 孙伟松(新加坡南洋理工大学)
- 张建(北京航空航天大学)
- 张明玥(西南大学)
- 刘洋(新加坡南洋理工大学)
- 引文格式(GB/T 7714):HUANG J P,YE W G,SUN W S,et al.TraceCoder: A Trace-Driven Multi-Agent Framework for Automated Debugging of LLM-Generated Code[C]//2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE ’26).Rio de Janeiro:ACM,2026:1-13.
一段话总结
TraceCoder是由重庆邮电大学等机构研究人员提出的迹驱动多智能体自动化调试框架,专为修复大语言模型(LLMs)生成代码的缺陷设计,核心通过Instrumentation、Analysis、Repair三个专用智能体实现细粒度运行时轨迹捕获、因果故障分析和代码修复,创新融入历史经验学习机制(HLLM)和回滚机制(RM)解决现有方法依赖二值反馈、无法从失败学习、易陷入修复循环的问题;该框架在HumanEval+、ClassEval等多基准数据集上实现了最高34.43%的Pass@1准确率相对提升,消融实验证实迭代修复流程单模块贡献65.61%的相对精度增益,且在准确性和成本效率上显著优于主流迭代方法,其插装机制语义保留率超99%,当前主要失败模式为**错误答案(WA)**类逻辑缺陷,相关开源实现已发布,为LLM生成代码的可靠性优化提供了新方案。
研究背景
如今大语言模型(LLMs)已经成为程序员的“得力助手”,能轻松完成代码生成、摘要、转换等软件工程任务,但这个“助手”也有明显的短板——在复杂逻辑任务中,生成的代码总会藏着一些隐性但关键的bug,比如简单的判断条件写错、循环边界值出错等。
为了解决这个问题,学界和工业界都在研究LLM生成代码的自动化修复技术,但现有方法却陷入了两个核心困境,就像医生看病只看“生病/没生病”的结果,却不看病因和病理报告:
- 黑盒盲改,故障定位精准度低:大多数修复方法只依赖测试用例的“通过/失败”二值反馈,完全看不到程序内部的执行过程。比如修复一个计算星期几的代码时,模型只知道结果错了,却不知道是索引计算、条件判断还是返回值出了问题,随便修改反而会破坏原本正确的功能,陷入“越改越错”的循环。
- 无记忆修复,重复踩坑效率低:现有方法没有从历史失败中学习的能力,同一个bug的修复思路错了一次,下次还会走同样的弯路,反复进行无效的修改,让修复过程变得冗长且低效。
举个直观的例子:LLM生成了一个计算“距离下一个周日还有几天”的代码,测试发现输入SUN时返回0而非7,现有方法会盲目修改计算逻辑,把7改成6,结果导致周一、周三的计算结果全部出错,后续又会盯着SUN的问题反复调整,始终找不到全局正确的解决方案。
正是这些问题,让LLM生成代码的可靠性大打折扣,也限制了LLM在实际开发中的落地应用,学界急需一种能精准定位故障、从失败中学习的自动化调试方法。
创新点
TraceCoder作为一款专为LLM生成代码设计的自动化调试框架,跳出了现有方法的固有思维,核心创新点体现在四个方面,也是其区别于其他调试方法的核心竞争力:
- 模拟人类调试的多智能体协作架构:首次将人类专家“观察-分析-修复”的调试流程拆解为三个专用智能体,实现模块化分工,让调试过程像工程师协作一样有序,而非单模型的盲目推理。
- 细粒度运行时迹驱动的白盒分析:通过插入非侵入式诊断探针,捕获程序内部的执行轨迹、变量状态和控制流,让调试从“黑盒盲改”变成“白盒精准定位”,解决了故障定位模糊的问题。
- 历史经验学习机制(HLLM):首次为LLM代码调试引入“记忆能力”,系统记录并复用过往修复失败的经验,避免重复执行无效策略,从根本上解决了无状态修复的低效问题。
- 回滚机制(RM):通过实时记录最优修复状态,防止修复过程中出现性能退化,确保每一次迭代都向正确方向推进,让修复过程稳定收敛,不会陷入越改越错的循环。
- 结构化的智能体通信模式:采用基于共享工件的顺序通信,而非直接消息传递,既保证了各智能体的信息互通,又提升了框架的可复现性和可控性。
研究方法和思路、实验方法
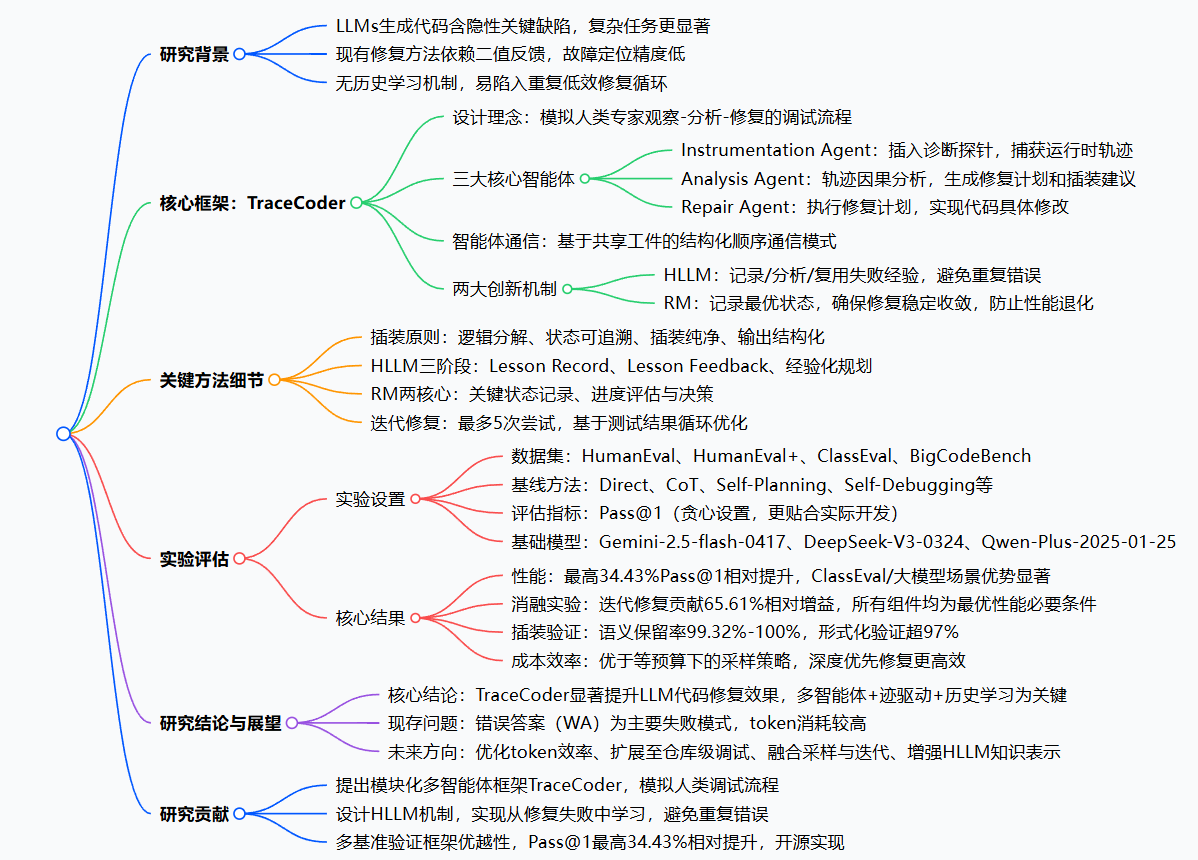
一、整体研究思路
TraceCoder的核心思路是模拟人类专家的调试流程,结合运行时迹的白盒分析、历史经验的记忆学习和回滚机制的稳定收敛,打造一套端到端的LLM生成代码自动化调试框架。框架以“迭代修复”为核心,当LLM生成的初始代码测试失败时,启动多智能体调试循环,直至代码通过所有测试或触发终止条件,整体流程实现了“精准定位-科学修复-经验沉淀-稳定收敛”的闭环。
二、核心模块与执行步骤
TraceCoder的核心由3个专用智能体+2个创新机制构成,各模块分工明确、协同工作,拆解后的执行步骤如下:
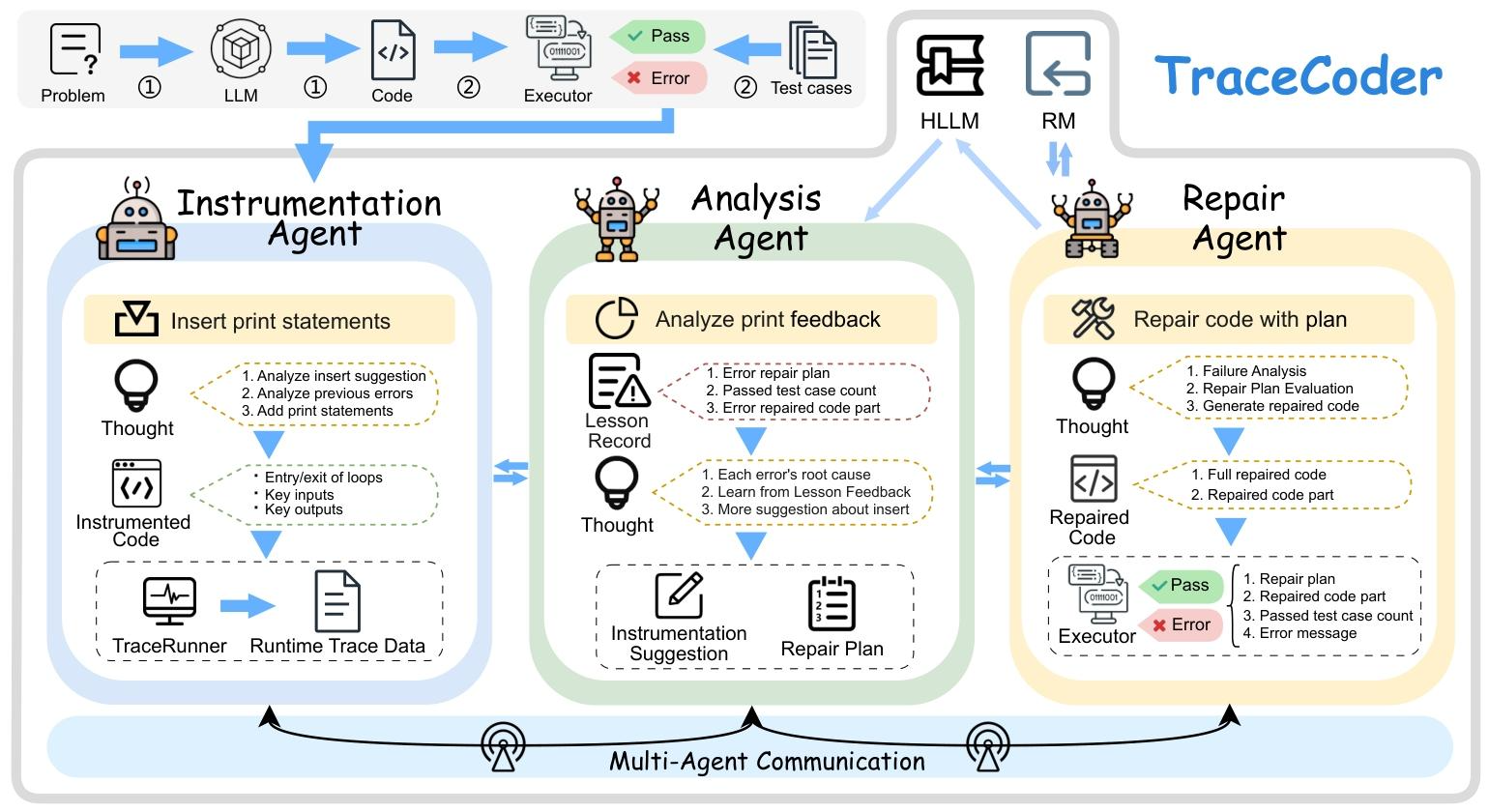
(一)三大核心智能体
- 插装智能体(Instrumentation Agent):调试的“眼睛”,负责收集程序执行的一手数据
- 触发场景:初始代码测试失败,或后续修复尝试未解决问题时;
- 核心输入:故障代码、测试失败反馈、分析智能体的插装建议(可选);
- 执行规则:遵循逻辑分解、状态可追溯、插装纯净、输出结构化四大原则,仅在代码中插入非侵入式的print诊断探针,不修改任何计算逻辑,保证程序语义完整;
- 核心输出:插装后的代码,经TraceRunner执行后生成细粒度运行时迹数据(包含变量状态、控制流、错误信息等)。
- 分析智能体(Analysis Agent):调试的“大脑”,负责定位故障根因并制定修复方案
- 核心输入:问题描述、插装代码、运行时迹数据、历史经验记录;
- 执行步骤:先分析运行时迹定位故障根因,再结合历史经验反思过往失败的原因,最后生成修复计划和下一轮插装建议;
- 核心输出:给修复智能体的结构化修复计划,给插装智能体的靶向插装建议。
- 修复智能体(Repair Agent):调试的“双手”,负责将修复计划落地为具体代码修改
- 核心输入:问题描述、故障代码、测试失败反馈、分析智能体的修复计划;
- 执行步骤:先分析测试失败的具体原因,再验证修复计划的合理性,最后严格按照计划修改代码(允许局部微调不违背核心策略的细节);
- 核心输出:修复后的代码,重新送入测试环节进行验证。
(二)两大创新机制
- 历史经验学习机制(HLLM):为框架赋予“记忆能力”,避免重复踩坑
基于试错学习理论设计,分为三个阶段:- 记录阶段:修复失败后,自动捕获本次的修复计划、故障代码、错误反馈、通过测试数等关键信息,形成经验记录;
- 反馈阶段:生成新修复计划前,分析所有历史经验记录,提取无效的修复策略;
- 规划阶段:结合经验反馈,制定新的修复计划,避开过往的错误思路。
- 回滚机制(RM):为框架保驾护航,确保修复稳定收敛
分为两个核心步骤:- 状态记录:实时跟踪最优代码(通过测试数最多)、最高通过测试数、上一次通过测试数、停滞计数器四个关键状态;
- 进度决策:修复后对比新代码与最优代码的测试通过数,分三种情况处理:改进则将新代码设为最优、停滞则继续尝试、退化则回滚到最优代码,停滞多次则终止修复,避免无效计算。
(三)智能体通信模式
各智能体采用结构化、顺序化的工件介导通信,无直接消息传递:插装智能体生成的运行时迹作为分析智能体的输入,分析智能体生成的修复计划作为修复智能体的输入,修复失败后的经验记录则送入HLLM,为下一轮分析智能体的决策提供依据,形成闭环的调试循环。
三、实验方法
为了全面验证TraceCoder的有效性,研究团队设计了多维度的实验,围绕4个核心研究问题展开,实验设置做到了公平、可复现:
- 实验数据集:选用4个主流基准数据集,覆盖函数级和类级代码生成任务,兼顾简单和复杂场景:HumanEval、HumanEval+(HumanEval增强测试覆盖)、BigCodeBench(复杂指令、多样函数调用)、ClassEval(类级程序,含结构依赖);
- 对比基线:选取5类代表性方法,涵盖非迭代/迭代两大范式,确保对比的全面性:Direct(直接生成)、CoT(思维链提示)、Self-Planning(自规划分解)、Self-Debugging(迭代二值反馈修复)、INTERVENOR(师生双智能体修复);
- 评估指标:采用Pass@1(每个问题仅评估1个解决方案),更贴合实际开发中程序员依赖LLMTop-1生成结果的场景;
- 基础模型:选用3款主流大模型,验证框架的跨模型通用性:Gemini-2.5-flash-0417、DeepSeek-V3-0324、Qwen-Plus-2025-01-25;
- 实验控制:所有方法使用相同的模型和API参数,迭代修复均限制最多5次尝试,所有代码在Python 3.10环境中执行,保证对比的公平性。
主要成果和贡献
TraceCoder通过多维度实验验证了其在LLM生成代码自动化调试领域的优越性,不仅实现了性能的大幅提升,还为该领域提供了全新的研究思路,核心成果和贡献可分为实验成果和领域贡献两部分,其中开源代码地址为:https://github.com/CSMA-Research-Group/TraceCoder。
一、核心实验成果
围绕4个研究问题的实验结果均展现了TraceCoder的显著优势,核心结果归纳如下表:
| 研究问题 | 实验核心内容 | 关键结论 |
|---|---|---|
| RQ1:TraceCoder与现有方法的性能对比 | 跨4个数据集、3个基础模型,对比TraceCoder与5类基线方法的Pass@1准确率 | 全场景实现Pass@1准确率第一,复杂基准(ClassEval/BigCodeBench)优势显著,Gemini-2.5-flash+ClassEval实现**34.43%**相对提升,平均相对提升最高达11.93% |
| RQ2:超参数对性能的影响 | 分析max_attempts(最大修复次数)、patience(早停阈值)对Pass@1的影响 | 对两个超参数高度敏感,增大任一超参数均能提升准确率,更高的容错性可帮助框架跳出局部最优,代价是增加计算开销 |
| RQ3:各核心组件的贡献 | 对BigCodeBench-Complete数据集做消融实验,逐一移除核心组件验证性能变化 | 所有组件均为最优性能必要条件,迭代修复流程贡献最大(相对增益65.61%),RM(5.31%)、HLLM(2.64%)为性能提供关键优化 |
| RQ4:实际应用性分析 | 验证插装有效性、分析成本效率、对比采样策略、诊断失败模式、案例验证修复能力 | 插装语义保留率99.32%-100%;等预算下优于盲采样;主要失败模式为错误答案(WA,最高8.86%);能精准修复隐性逻辑缺陷 |
此外,实验还验证了TraceCoder的成本效率优势:虽然属于高token消耗范式,但在等token/等尝试预算下,其反馈引导的深度优先修复策略远优于Direct/CoT的盲采样策略,比如Gemini+ClassEval场景,TraceCoder的Pass@1(82.00%)远超CoT的Pass@15(58.00%),用更少的有效尝试实现了更高的修复成功率。
二、领域贡献
TraceCoder不仅实现了性能的突破,还为LLM生成代码的自动化调试领域带来了三大实实在在的价值,推动了该领域的研究发展:
- 提出了全新的调试框架范式:首次将迹驱动的白盒分析和多智能体协作结合起来,打破了现有方法“黑盒盲改”的固有模式,为后续LLM代码调试研究提供了新的框架参考;
- 解决了两大核心行业痛点:通过HLLM和RM机制,分别解决了现有方法“无记忆重复踩坑”和“修复易退化”的痛点,让自动化调试从“无序迭代”变成“有序收敛”,大幅提升了调试效率;
- 提供了可复现的开源方案:发布了TraceCoder的开源实现,为后续研究提供了可复现、可扩展的基础,降低了该领域的研究门槛,同时其插装、分析的设计思路也可迁移到其他编程语言和LLM中。
详细总结
本文发表于ICSE ’26,由中、新多所高校研究人员联合提出TraceCoder——一款迹驱动的多智能体框架,针对大语言模型生成代码的自动化调试问题展开研究,解决了现有方法故障定位不准、无历史学习、修复易退化的核心痛点,通过多维度实验验证了框架的优越性,并明确了未来研究方向。以下为详细内容:
一、研究背景与现存问题
- LLMs已成为代码生成、摘要、转换等软件工程任务的重要工具,但在复杂/逻辑密集型场景中,生成代码常含隐性且关键的缺陷,亟需自动化修复方案。
- 现有LLM代码自修复方法存在两大核心局限:
- 依赖测试套件的二值通过/失败反馈,缺乏程序内部执行洞察,故障定位精度低,易导致性能退化(修复破坏原有正确功能)。
- 采用无状态修复范式,无法从历史调试失败中学习,易陷入局部错误修复的循环与停滞,效率低下。
二、TraceCoder框架核心设计
TraceCoder模拟人类专家信息收集-假设形成-修复的调试认知模型,采用模块化多智能体协作架构,融合运行时迹捕获、历史经验学习、回滚收敛三大核心思想,整体为迭代修复流程,直至代码通过所有测试或触发终止条件。
- 三大专用智能体
智能体 核心功能 输入 输出 关键原则/流程 Instrumentation Agent 插入诊断探针,捕获细粒度运行时轨迹 故障代码、测试失败反馈、插装建议(可选) 插装后的代码 遵循4大原则:逻辑分解、状态和控制可追溯、插装纯净(仅加print,不修改逻辑)、输出结构化;语义保留率99.32%-100% Analysis Agent 轨迹因果分析,定位故障根因 问题描述、插装代码、运行时迹、经验记录 修复计划、后续插装建议 两阶段流程:诊断与反思(结合历史经验)、策略制定(生成可执行修复方案) Repair Agent 执行修复计划,修改代码 问题描述、故障代码、测试失败反馈、修复计划 修复后的代码 三步流程:故障分析、修复计划评估、代码修复执行;允许局部微调,不违背核心修复策略 - 智能体通信:采用基于共享工件的结构化顺序通信,无直接消息传递,避免全量多智能体框架的冗余复杂度,提升可复现性;每次修复失败后,结果会记入HLLM,为下一次分析提供经验。
- 两大创新机制
- 历史经验学习机制(HLLM):基于试错学习理论,解决无状态修复问题,分三阶段运行:Lesson Record(捕获失败修复的计划、代码、错误反馈等信息)、Lesson Feedback(分析经验记录,提取无效策略)、经验化规划(基于经验制定新修复计划,避免重复错误)。
- 回滚机制(RM):确保修复稳定收敛,防止性能退化,核心为关键状态记录(最优代码、最高通过测试数、上一次通过数、停滞计数器)和进度评估决策(根据新修复代码的测试通过数,判定改进/停滞/退化,执行接受/继续/回滚操作,停滞多次则终止)。
三、实验设置
- 数据集:4个主流基准,覆盖函数级和类级代码生成任务——HumanEval、HumanEval+(HumanEval增强测试覆盖)、BigCodeBench(含Complete/Instruct子集,复杂指令)、ClassEval(面向类级程序,含结构依赖)。
- 基线方法:5类代表性方法,涵盖非迭代/迭代范式——Direct(直接生成)、CoT(思维链提示)、Self-Planning(自规划分解)、Self-Debugging(迭代二值反馈修复)、INTERVENOR(师生双智能体修复)。
- 评估指标:采用Pass@1(贪心设置,每个问题仅评估1个解决方案),更贴合实际开发场景。
- 基础模型:3款主流大模型——Gemini-2.5-flash-0417、DeepSeek-V3-0324、Qwen-Plus-2025-01-25;所有方法使用相同模型和API参数,迭代修复均限制最多5次尝试。
- 运行环境:统一Python 3.10,保证实验公平性。
四、实验结果与分析
针对4个研究问题(RQ1-RQ4)展开多维度实验,核心结果如下:
- RQ1:框架整体性能:TraceCoder在所有数据集和基础模型上均实现最高Pass@1准确率,复杂基准(ClassEval/BigCodeBench)优势尤为显著,Gemini-2.5-flash-0417+ClassEval场景实现34.43%的相对提升,所有场景平均相对提升11.93%(Gemini)、7.78%(DeepSeek)、5.28%(Qwen)。
- RQ2:超参数影响:框架性能对**max_attempts(最大修复次数)和patience(早停阈值)**高度敏感,增大任一超参数均能提升准确率,因更多尝试/更高容错性可帮助框架跳出局部最优,但会增加计算开销(token消耗)。
- RQ3:组件消融实验(基于BigCodeBench-Complete):所有组件均为最优性能的必要条件,核心数据如下:
- 全框架Pass@1:89.04%。
- 移除迭代修复流程:准确率骤降至53.77%,相对增益65.61%,为框架最核心的贡献模块。
- 移除Instrumentation Agent:准确率降至78.51%,验证运行时迹对故障定位的重要性。
- 移除RM/HLLM:准确率分别降至84.55%(相对降5.31%)、86.75%(相对降2.64%),验证两大机制的协同优化作用。
- RQ4:实际应用性分析
- 插装有效性:形式化验证表明,插装代码与原代码行为等价性超97%,实证验证语义保留率99.32%-100%。
- 成本效率:TraceCoder属于高token消耗、高性能范式,但在等token/等尝试预算下,其深度优先的反馈引导修复策略,显著优于Direct/CoT的盲采样策略(如Gemini+ClassEval,TraceCoder Pass@1=82.00%,CoT Pass@15仅58.00%)。
- 失败模式:在BigCodeBench中,**错误答案(WA)**为主要失败模式(Complete=6.34%,Instruct=8.86%),即框架能解决显式运行时错误,但对隐性逻辑缺陷的修复仍为难点。
- 案例验证:针对“提取严格正数”的逻辑缺陷(误将0纳入),TraceCoder通过迹捕获精准定位根因,实现靶向修复,而依赖二值反馈的方法易陷入盲修复。
五、威胁与有效性
- 外部有效性:TraceCodertoken消耗较高,可能限制其在资源受限环境的应用,未来需优化轻量化智能体。
- 构造有效性:修复效果依赖测试套件的覆盖度,测试不足可能导致过拟合,隐藏未被检测的缺陷。
- 内部有效性:采用BigCodeBench(发布于模型知识截止日后)降低数据污染风险,所有方法实验条件一致,保证对比公平性。
六、研究贡献与未来方向
- 三大核心贡献
- 提出TraceCoder——模块化的多智能体框架,模拟人类调试流程,实现LLM生成代码的迹驱动自动化修复。
- 设计历史经验学习机制(HLLM),首次实现从修复失败中学习,避免重复错误,提升调试效率。
- 多基准/多模型验证框架优越性,Pass@1准确率最高相对提升34.43%,发布开源实现,为后续研究提供支撑。
- 未来研究方向
- 优化token效率,设计轻量化智能体,降低计算开销。
- 将框架扩展至仓库级调试,解决大上下文、跨文件依赖、插装爆炸等问题。
- 融合采样与迭代修复的混合策略,并行运行TraceCoder实例,扩大解空间探索。
- 增强HLLM的结构化知识表示,实现修复策略跨任务/跨领域的泛化。
七、实验关键数字汇总
- Pass@1相对提升:最高34.43%(Gemini+ClassEval),平均最高11.93%(Gemini)。
- 消融实验:迭代修复流程贡献**65.61%**相对精度增益;RM/HLLM分别贡献5.31%/2.64%的性能提升。
- 插装语义保留率:99.32%-100%,形式化行为等价性超97%。
- 主要失败模式占比:错误答案(WA)最高8.86%(BigCodeBench-Instruct)。
- 迭代修复上限:5次,超参数patience/max_attempts增大可提升性能。
关键问题
问题1(框架设计类):TraceCoder解决现有LLM代码修复方法痛点的核心设计思路是什么?
答案:TraceCoder核心通过三大设计思路解决现有方法的痛点,一是模拟人类调试的多智能体协作架构,将调试拆分为插装、分析、修复三个模块化环节,实现细粒度的运行时迹捕获与因果故障定位,解决二值反馈导致的故障定位不准问题;二是创新历史经验学习机制(HLLM),系统记录、分析并复用过往修复失败的经验,避免重复执行无效策略,解决无状态修复的低效问题;三是引入回滚机制(RM),实时记录修复过程中的最优状态,根据测试通过数判定修复进度,执行回滚操作防止性能退化,确保修复过程稳定收敛,解决修复易陷入循环与停滞的问题。
问题2(实验性能类):TraceCoder在性能上的核心优势体现在哪些方面?有哪些关键实验数据支撑?
答案:TraceCoder的性能优势体现在场景普适性、复杂任务适配性、成本效率优越性三个方面,关键数据如下:1)普适性:在HumanEval、ClassEval等4个基准数据集,以及Gemini、DeepSeek、Qwen三款基础模型上,均实现Pass@1准确率第一,是目前性能最优的LLM代码修复方法;2)复杂任务适配性:在类级/复杂指令基准(ClassEval/BigCodeBench)上优势显著,Gemini-2.5-flash-0417+ClassEval场景实现**34.43%**的Pass@1相对提升,远高于其他基准;3)成本效率:在等token/等尝试预算下,其深度优先的反馈引导修复策略显著优于盲采样,如Gemini+ClassEval场景,TraceCoder的Pass@1(82.00%)远超CoT的Pass@15(58.00%),验证了其以更高的智能性降低了无效的解空间探索。
问题3(实际应用与未来研究类):TraceCoder当前的主要局限性是什么?针对这些局限性,研究人员提出了哪些未来研究方向?
答案:TraceCoder当前的主要局限性有两点:1)技术层面,目前的主要失败模式为错误答案(WA),占比最高达8.86%,说明框架对LLM生成代码的隐性逻辑缺陷修复能力仍有待提升,对显式运行时错误的修复效果更优;2)工程层面,框架属于高token消耗范式,虽然成本效率优于等预算采样策略,但绝对token消耗较高,可能限制其在资源受限环境的实际应用。针对上述局限性,研究人员提出四大未来研究方向:1)优化智能体的token效率,设计轻量化插装、分析、修复模块,降低计算开销;2)将框架扩展至仓库级调试场景,解决大上下文管理、跨文件依赖、插装爆炸等新问题;3)探索采样与迭代修复融合的混合策略,结合初始采样与并行TraceCoder实例,高效扩大解空间探索;4)增强HLLM的结构化知识表示,让修复策略能够跨任务、跨领域泛化,提升框架的通用能力。
总结
TraceCoder是一款专为LLM生成代码设计的迹驱动多智能体自动化调试框架,由重庆邮电大学、新加坡南洋理工大学等机构联合提出,核心是模拟人类专家“观察-分析-修复”的调试流程,通过插装、分析、修复三大智能体实现模块化分工,结合历史经验学习机制(HLLM)和回滚机制(RM),解决了现有方法故障定位不准、无记忆重复踩坑、修复易退化的核心问题。
该框架在HumanEval+、ClassEval、BigCodeBench等主流数据集上实现了全面的性能突破,Pass@1准确率相对提升最高达34.43%,消融实验验证了各核心组件的必要性,其中迭代修复流程贡献了65.61%的相对增益。同时,TraceCoder在插装有效性、成本效率、实际修复能力上均表现优异,仅在隐性逻辑缺陷的修复上仍有提升空间。
TraceCoder不仅为LLM生成代码的自动化调试提供了全新的框架范式,还推动了该领域从“黑盒盲改”向“白盒精准修复”的转变,大幅提升了LLM生成代码的可靠性,为LLM在实际软件工程中的落地应用提供了重要支撑,后续其优化方向将聚焦于token效率提升、仓库级调试扩展、修复策略泛化等方面。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)