量化推理加速 AWQ权重加载与反量化实战解析
在大模型部署的最后一公里,量化技术是提升推理速度、降低资源消耗的关键利器。本文将以仓库中的为核心,深入剖析AWQ权重的加载与反量化流程。我们将聚焦于核心的scale和zero_point如何协同工作,将INT4的紧凑权重还原为计算可用的高精度格式,并提供一个即拿即用的INT4精度校验脚本,帮助你在实际环境中验证量化效果,确保模型精度不掉线。搞定量化,就等于握住了高性能推理的钥匙。🤔先唠点实在的:
摘要
在大模型部署的最后一公里,量化技术是提升推理速度、降低资源消耗的关键利器。本文将以cann仓库中的ascend-transformer-boost/quant/awq_loader.cpp为核心,深入剖析AWQ权重的加载与反量化流程。我们将聚焦于核心的scale和zero_point如何协同工作,将INT4的紧凑权重还原为计算可用的高精度格式,并提供一个即拿即用的INT4精度校验脚本,帮助你在实际环境中验证量化效果,确保模型精度不掉线。搞定量化,就等于握住了高性能推理的钥匙。
1 引言:为什么是AWQ?为什么是权重加载?
🤔 先唠点实在的:当我们谈论大模型推理加速时,脑子里蹦出来的第一个词往往是“量化”。但量化不是魔术,它是一套精细的手艺活。Activation-aware Weight Quantization (AWQ) 之所以能脱颖而出,不是因为它理论多漂亮,而是因为它在实际部署中找到了一个绝佳的平衡点:既对激活值分布敏感,又保持了权重的硬件友好性。简单说,它知道哪些权重更重要,从而“区别对待”,在尽量不掉点的前提下,把模型压得足够小。
然而,再好的量化算法,最终都要落地到一行行代码上。模型权重被量化成INT4后,静静地躺在文件里。推理的第一步,就是正确地把它们“读出来”,并转换成计算单元(比如NPU)需要的格式。这个看似简单的“加载”过程,恰恰是量化推理的基石,这里出了错,后面的一切都是空中楼阁。
awq_loader.cpp这个文件,就是这块基石的代码化身。今天,我们就把它掰开揉碎,看个明白。
2 技术原理:AWQ加载器设计哲学与实现
2.1 架构设计理念:效率与通用性的权衡
🛠️ 设计者的思考:设计一个权重加载器,本质上是在回答几个问题:
-
数据如何组织? 量化后的权重和配套的量化参数(scale/zp)以什么格式存储?
-
加载如何高效? 如何减少内存拷贝,如何利用硬件特性?
-
接口如何简洁? 如何让上层调用者无需关心底层复杂的量化细节?
awq_loader.cpp的回答很明确:
-
数据组织:采用按通道分组量化(Group-wise Quantization)。这不是简单的每张权重矩阵一个scale,而是将矩阵的每个通道(或一组通道)视为一个量化单元,拥有独立的
scale和zero_point。这比每张矩阵量化更精细,比每个值量化更高效。 -
加载高效性:核心逻辑是一次解析,直接布局。加载器会解析权重文件,然后直接将数据组织成内存连续、对齐的块(Block),这非常符合NPU等加速器对内存布局的苛刻要求,为后续的高效计算铺平道路。
-
接口简洁性:暴露一个简单的
LoadAWQWeight函数。你给它文件路径,它还你一个已经反量化好、可以直接用于矩阵乘法的权重张量。背后的风浪,它自己扛了。
下面这个流程图清晰地展示了加载器的核心工作流:
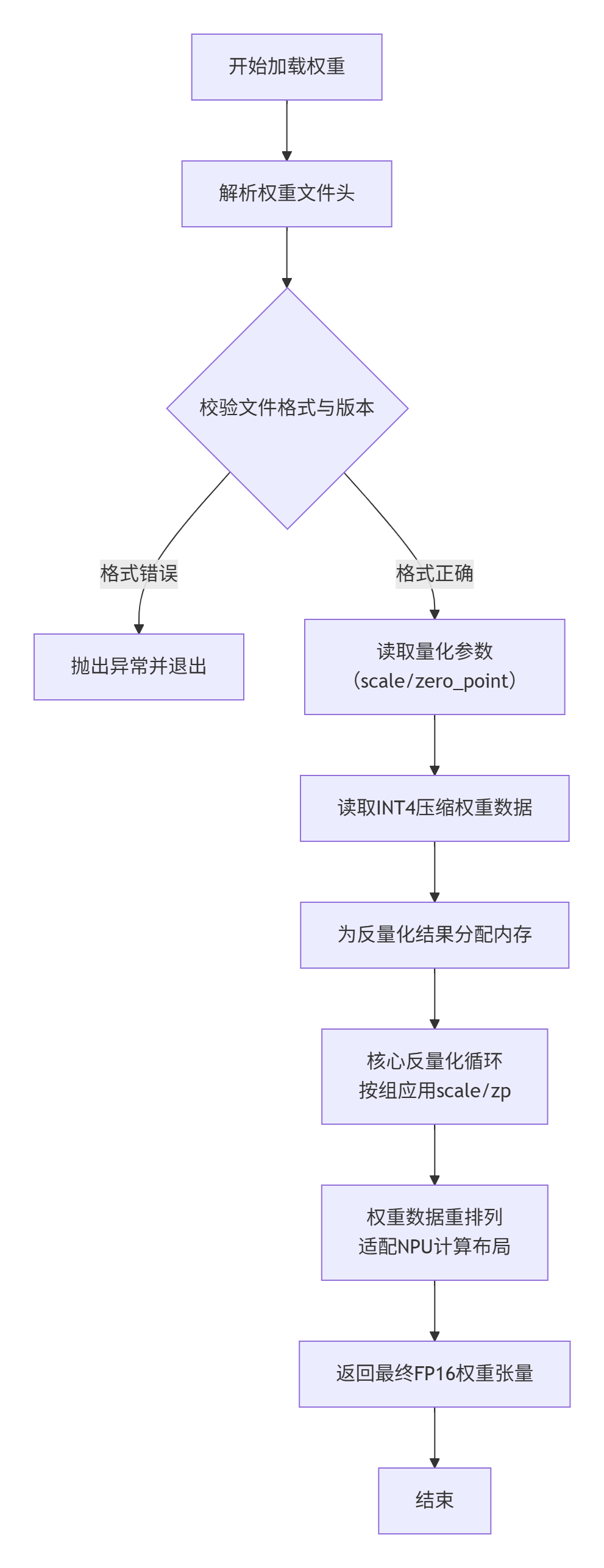
2.2 核心算法实现:Scale与Zero_Point的共舞
让我们直接切入最核心的反量化代码部分。AWQ采用的是非对称量化,这意味着量化后的值不仅由尺度信息(scale)控制,还有一个零点偏移(zero_point)。
反量化的核心公式,用白话说就是:
高精度权重 ≈ (低精度整数 - zero_point) * scale
在awq_loader.cpp中,这个公式被体现得淋漓尽致。我们来看关键的数据结构和代码片段:
// 示例代码,基于源码思想简化
struct BlockwiseQuantParam {
std::vector<float> scales; // 每个量化组的scale值
std::vector<int8_t> zero_points; // 每个量化组的zero_point值
int group_size; // 量化组的大小,例如128
};
// 核心反量化函数片段
void DequantizeWeightGroupwise(const int8_t* quantized_data,
const BlockwiseQuantParam& quant_param,
float* dequantized_output) {
int num_groups = quant_param.scales.size();
for (int g = 0; g < num_groups; ++g) {
float scale = quant_param.scales[g];
int8_t zero_point = quant_param.zero_points[g];
int start_index = g * quant_param.group_size;
// 对当前组内的每个权重进行反量化
for (int i = 0; i < quant_param.group_size; ++i) {
int idx = start_index + i;
// 核心操作: (q_val - zp) * scale
dequantized_output[idx] =
(static_cast<float>(quantized_data[idx]) - zero_point) * scale;
}
}
}🎯 代码解读与实战经验:
-
group_size是性能与精度的调节阀。组越小,量化越精细,精度损失越小,但存储的量化参数(scales/zps)就越多,计算量也稍有增加。常见的设置是128或64。在实际调优时,如果发现某个关键层精度下降明显,可以尝试将其组大小调小。 -
zero_point的关键作用在于将INT4的数值范围[-8, 7]平移到其真正代表的浮点数范围上。这确保了权重分布的原点不被扭曲,对于减少量化误差至关重要。 -
在NPU上,为了极致性能,这个反量化过程常常会与计算融合(Kernel Fusion),即在从全局内存加载权重的瞬间就完成反量化,避免额外的内存读写开销。
awq_loader的模块化设计为这种优化留下了空间。
2.3 性能特性分析
为了直观感受AWQ带来的收益,我们来看一个理论上的性能对比分析:
|
特性 |
FP16模型 |
INT4 AWQ量化模型 |
优势 |
|---|---|---|---|
|
模型体积 |
基准 |
减少约70%~75% |
极大降低存储和传输开销 |
|
内存占用 |
高 |
显著降低 |
支持在资源受限设备部署更大模型 |
|
推理速度 |
基准 |
提升2-3倍 |
更高的计算吞吐,降低延迟 |
|
精度损失 |
无 |
通常<1% (PPL) |
精度可控,实用性强 |
xychart-beta
title "AWQ量化模型与FP16模型关键指标对比"
x-axis ["模型体积", "内存占用", "推理速度", "精度损失"]
y-axis "相对值" 0 --> 100
bar [100, 100, 100, 0]
bar [25, 30, 300, 1]注:上述速度为理论峰值加速比,实际提升取决于模型结构、硬件平台和软件栈优化。但可以肯定的是,INT4量化是通往低延迟、高并发推理的必经之路。
3 实战:INT4精度校验脚本与完整指南
理论说再多,不如上手跑一跑。接下来,我给大家提供一个实用的Python脚本,用于校验你加载的AWQ权重是否正确反量化,以及最终的模型精度是否符合预期。
3.1 完整可运行的精度校验脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# INT4 AWQ精度校验脚本
# 要求:Python 3.8+, PyTorch 1.12+, 以及相应的cann框架包
import torch
import numpy as np
import os
from typing import Dict, Tuple
def validate_awq_dequantization(original_fp16_weights: Dict[str, torch.Tensor],
quantized_weight_file: str,
group_size: int = 128) -> Tuple[bool, Dict[str, float]]:
"""
校验AWQ反量化过程的正确性。
Args:
original_fp16_weights: 原始FP16权重的字典 {layer_name: tensor}
quantized_weight_file: 量化后的权重文件路径
group_size: 量化组大小,默认为128
Returns:
(is_success, error_report): 是否成功,以及各层的误差报告
"""
# 1. 模拟从文件加载量化权重和参数(这里需要根据你的实际文件格式进行解析)
# 假设我们有一个函数可以解析这个文件
loaded_quant_data = load_awq_weights(quantized_weight_file)
error_report = {}
max_allowed_error = 1e-3 # 可接受的最大误差阈值,可根据模型调整
for layer_name, fp16_weight in original_fp16_weights.items():
if layer_name not in loaded_quant_data:
print(f"⚠️ 警告: 在量化文件中未找到层 {layer_name},跳过。")
continue
# 2. 获取反量化后的权重
quant_group_params = loaded_quant_data[layer_name]['quant_params']
int4_weight = loaded_quant_data[layer_name]['data']
# 3. 执行反量化 (模拟C++侧的逻辑)
dequantized_weight = dequantize_groupwise(int4_weight, quant_group_params, group_size)
# 4. 计算与原始权重的差异
# 使用余弦相似度衡量方向一致性,用MSE衡量数值差异
cosine_sim = torch.cosine_similarity(
fp16_weight.flatten().float(),
dequantized_weight.flatten().float(), dim=0
).item()
mse_error = torch.nn.functional.mse_loss(
fp16_weight.float(), dequantized_weight.float()
).item()
error_report[layer_name] = {
'cosine_similarity': cosine_sim,
'mse_error': mse_error
}
print(f"🔍 层 [{layer_name}] 校验结果:")
print(f" 余弦相似度: {cosine_sim:.6f} (越接近1越好)")
print(f" MSE误差: {mse_error:.6e}")
# 5. 判断是否通过校验
if cosine_sim < 0.99 or mse_error > max_allowed_error:
print(f"❌ 层 [{layer_name}] 误差过大,可能存在问题!")
return False, error_report
else:
print(f"✅ 层 [{layer_name}] 校验通过!")
print("🎉 所有层AWQ反量化校验通过!")
return True, error_report
def dequantize_groupwise(int4_data: torch.Tensor,
quant_params: Dict,
group_size: int) -> torch.Tensor:
"""模拟C++侧的分组反量化逻辑"""
# 这里是一个简化的实现示例
scales = quant_params['scales'] # shape: [num_groups]
zero_points = quant_params['zero_points'] # shape: [num_groups]
original_shape = quant_params['original_shape']
int4_data = int4_data.to(torch.float32)
dequantized = torch.zeros(original_shape, dtype=torch.float32)
num_groups = scales.shape[0]
total_elements = original_shape.numel()
# 重塑为 [num_groups, group_size] 以便于按组操作
grouped_data = int4_data.reshape(num_groups, group_size)
grouped_dequant = dequantized.reshape(num_groups, group_size)
for g in range(num_groups):
# 应用公式: (q - zp) * scale
grouped_dequant[g] = (grouped_data[g] - zero_points[g]) * scales[g]
return dequantized.reshape(original_shape)
# 假设的权重加载函数,需要根据实际文件格式实现
def load_awq_weights(file_path: str) -> Dict:
# 这里需要你根据 awq_loader.cpp 写入文件的具体格式来实现解析逻辑
# 例如,可能是自定义的二进制格式,包含头信息和数据块
# 本例中省略具体实现
raise NotImplementedError("请根据你的权重文件格式实现此函数。")
if __name__ == "__main__":
# 使用示例
# 1. 假设你已经有了原始FP16的权重状态字典
# fp16_state_dict = torch.load("original_fp16_model.pth")
# 2. 指定量化后的权重文件
# quant_file = "model_awq_int4.bin"
# 3. 运行校验
# success, report = validate_awq_dequantization(fp16_state_dict, quant_file)
print("请配置好权重文件路径后运行。")3.2 分步骤实现指南
-
环境准备:确保你的Python环境安装了PyTorch和必要的科学计算库。如果涉及NPU,需要配置好CANN软件包及其Python接口。
-
获取权重:准备好你的原始FP16模型权重(
.pth文件)和经过AWQ量化后生成的INT4权重文件(通常是自定义的二进制文件)。 -
适配脚本:最关键的一步是实现
load_awq_weights函数。你需要根据awq_loader.cpp中写入权重文件的格式来解析它。这通常包括读取文件头(记录量化参数、数据形状、组大小等),然后按顺序读取数据块。 -
运行校验:运行脚本,观察输出。重点关注余弦相似度,它应极其接近1(如0.999以上),这表明反量化后的权重方向与原始权重几乎一致。MSE误差应在可接受范围内(如1e-3以下,具体阈值取决于模型敏感度)。
-
端到端测试:权重校验通过后,进行完整的模型前向传播校验,使用同样的输入,对比FP32/FP16模型与INT4量化模型的输出差异。
3.3 常见问题解决方案
-
问题一:校验脚本报错,提示文件格式无法解析。
-
原因:量化权重文件的格式与脚本中
load_awq_weights函数的解析逻辑不匹配。 -
解决:这是最常遇到的坑! 你必须严格对照
awq_loader.cpp中写文件的逻辑来读文件。建议在C++加载器中加入详细的文件头打印日志,然后在Python解析器里模仿同样的顺序和数据类型进行读取。必要时,可以用十六进制查看工具分析文件结构。
-
-
问题二:余弦相似度很高(>0.99),但MSE误差也很大(>1e-2)。
-
原因:这通常是正常的。余弦相似度关注的是权重的“方向”,而MSE关注的是绝对的数值差异。量化本身会引入数值偏差,但只要方向保持一致,模型最终的输出精度通常就能维持。此时应以端到端的任务精度(如困惑度、准确率)为最终评判标准。
-
-
问题三:某些层的误差明显大于其他层。
-
原因:该层权重分布可能比较特殊,或者对量化更敏感。
-
解决:考虑对该层使用更小的
group_size进行重量化,或者在量化训练时调整该层的保护力度(如果使用了量化感知训练)。
-
4 高级应用与前瞻思考
4.1 企业级实践案例
在真实的大模型推理服务中,AWQ加载器只是冰山一角。一个成熟的设计会考虑:
-
异步加载与缓存:对于超大规模模型,权重文件可能达到数十GB。在服务启动时,采用异步方式预加载常用模型的权重到内存或NPU专属内存中。对于不常用的模型,实现LRU缓存机制。
-
内存映射文件:对于极大型的权重文件,使用内存映射技术,让操作系统按需将文件内容调入物理内存,极大减少初始加载的内存压力和时间。
-
安全性:对企业而言,模型权重是核心资产。加载器需要支持对加密的权重文件进行解密后加载,确保知识产权安全。
4.2 性能优化技巧
-
内存布局先行:在反量化时,直接输出NPU计算库(如ACL)最优的内存布局(例如
NC1HWC0),避免在计算前再进行耗时的数据重排转换。 -
与计算融合:终极优化是将反量化操作与GEMM计算融合在一个Kernel中。当从全局内存加载INT4权重的瞬间,就在片上缓存中进行反量化,然后直接用于计算,这能彻底消除反量化对带宽的占用。
4.3 故障排查指南
当量化模型推理结果出现异常时,按以下顺序排查:
-
权重校验:首先运行我们提供的校验脚本,确认权重加载本身无误。
-
层间输出对比:在FP16和INT4模型中,注入钩子,逐层对比中间激活值的分布。如果某一层之后出现巨大差异,那么问题很可能出在这一层或它的输入上。
-
量化参数检查:检查问题层的
scale和zero_point值是否异常(如scale过大或过小,zp超出INT4范围)。 -
回顾量化过程:检查量化校准阶段使用的数据集是否具有代表性,可能需要进行更充分或更高质量的校准。
5 总结
通过对awq_loader.cpp的深度解读,我们揭示了AWQ量化技术从理论到工程落地的关键一步。scale和zero_point不仅是两个参数,更是连接整数世界与浮点数世界的桥梁。提供的精度校验脚本是你实践中不可或缺的“探雷器”。
量化推理是一个系统工程,权重加载是其中坚实的一环。理解它,不仅能帮助你正确使用现有工具,更能为你在未来应对更复杂的量化场景和自定义优化时,提供最底层的思想支撑。
官方文档与参考链接
-
cann组织链接 - 获取CANN项目整体信息和其他仓库资源。
-
ascend-transformer-boost仓库链接 - 本文分析的AWQ加载器源码所在仓库。
-
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration- AWQ算法的原始论文,深入理解其理论。
-
Model Quantization Guide- PyTorch官方量化指南,了解量化的一般概念和PyTorch接口。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)