多模态大模型学习笔记(四)——从零掌握TF-IDF:原理、实战与可视化
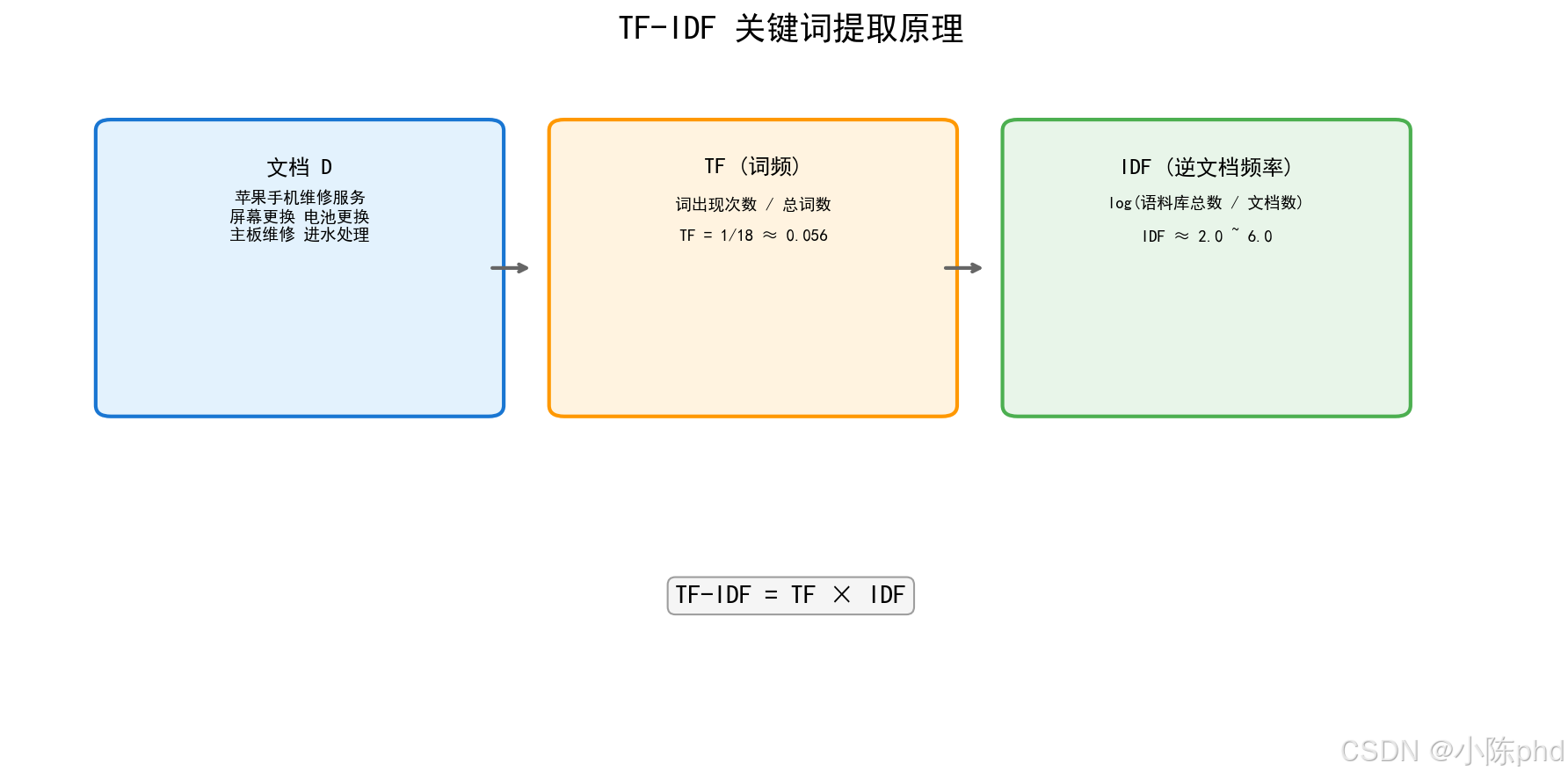
TF-IDF = 词频 × 逆文档频率TF衡量词语在当前文档的重要性IDF衡量词语的独特性/区分度TF-IDF综合两者,提取真正有区分度的关键词。
TF-IDF关键词提取原理与代码实践
1. 什么是TF-IDF
TF-IDF(Term Frequency - Inverse Document Frequency)是一种用于文本关键词提取和信息检索的统计方法。它评估一个词语对于一个文档集或语料库中某个文档的重要程度。
1.1 核心思想
- 词频(TF):一个词语在当前文档中出现的频率越高,越重要
- 逆文档频率(IDF):一个词语在越少文档中出现,越独特,越重要
最终得分 = TF × IDF
2. TF(词频)原理
2.1 计算公式
TF(t,d)=词语t在文档d中出现次数文档d的总词数TF(t,d) = \frac{词语t在文档d中出现次数}{文档d的总词数}TF(t,d)=文档d的总词数词语t在文档d中出现次数
2.2 示例说明
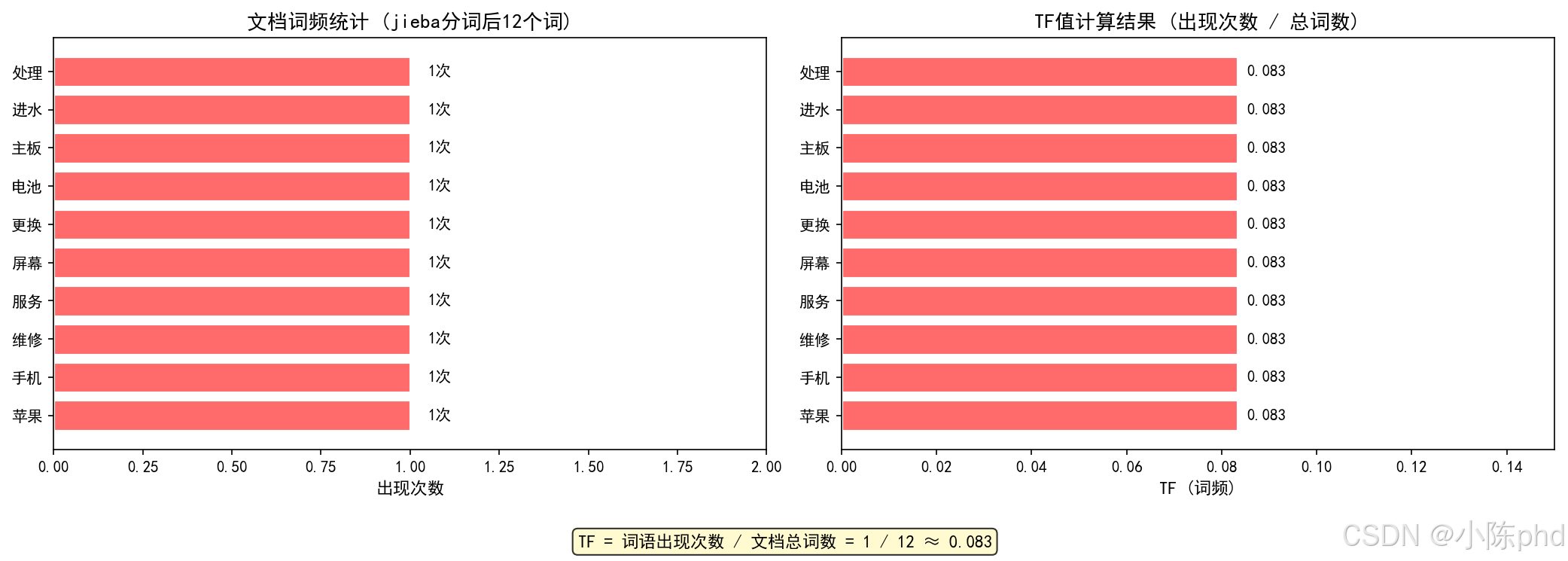
假设文档D:「苹果手机维修服务,提供屏幕更换、电池更换、主板维修与进水处理」
jieba分词后得到词语:苹果、手机、维修、服务、屏幕、更换、电池、主板、进水、处理(共12个词)
| 词语 | 出现次数 | 文档总词数 | TF值 |
|---|---|---|---|
| 苹果 | 1 | 12 | 0.083 |
| 手机 | 1 | 12 | 0.083 |
| 维修 | 1 | 12 | 0.083 |
| 服务 | 1 | 12 | 0.083 |
| 屏幕 | 1 | 12 | 0.083 |
| 更换 | 1 | 12 | 0.083 |
2.3 TF的问题
如果只使用TF,会导致常见词(如:「的」「了」「是」)排名最高,无法有效提取关键词。
3. IDF(逆文档频率)原理
3.1 计算公式
IDF(t,D)=log语料库文档总数包含词语t的文档数IDF(t,D) = \log\frac{语料库文档总数}{包含词语t的文档数}IDF(t,D)=log包含词语t的文档数语料库文档总数
3.2 示例说明
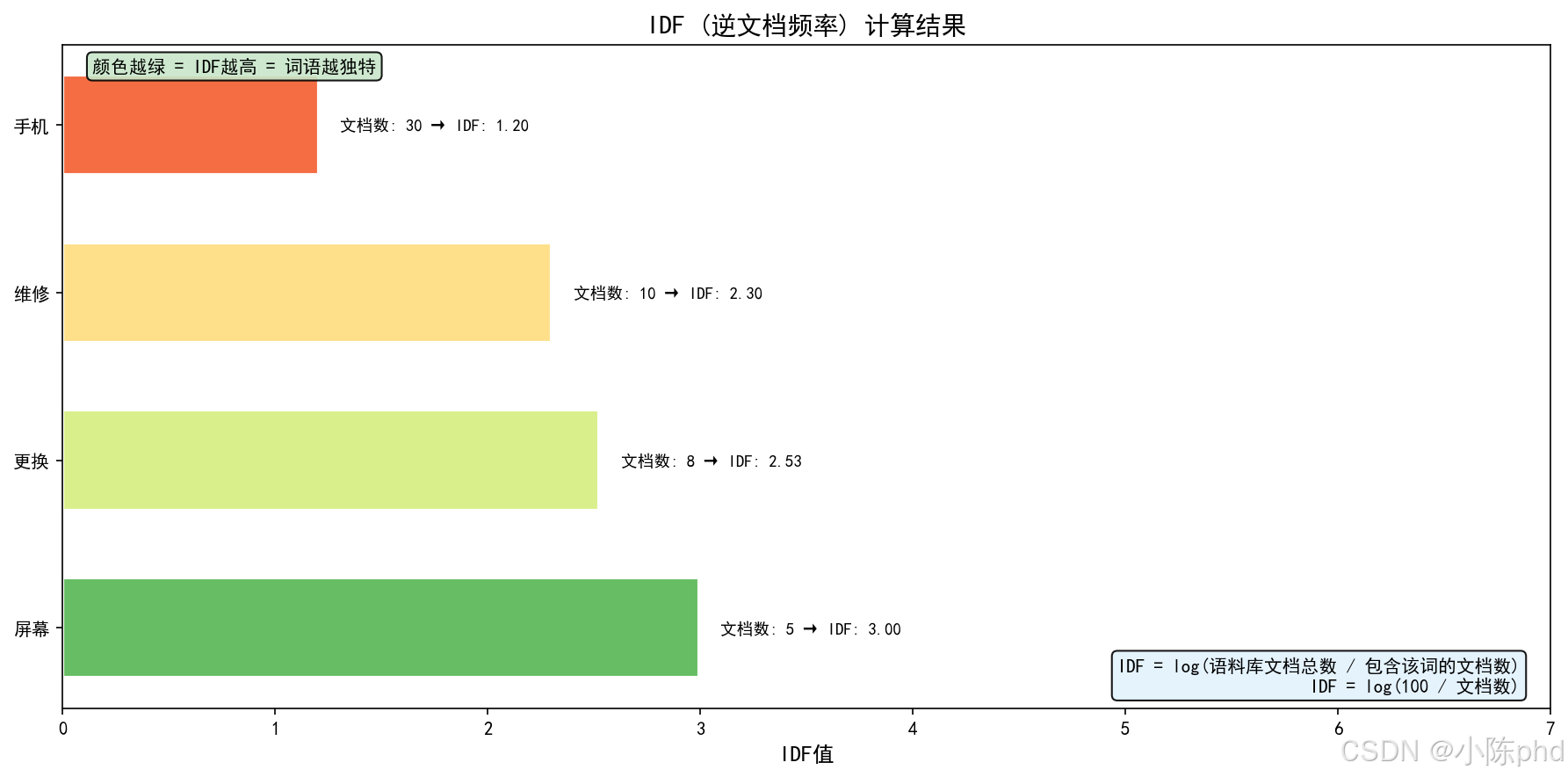
假设语料库有100个文档:
| 词语 | 包含该词的文档数 | IDF值 |
|---|---|---|
| 屏幕 | 5 | log(100/5)≈2.996\log(100/5) ≈ 2.996log(100/5)≈2.996 |
| 维修 | 10 | log(100/10)≈2.303\log(100/10) ≈ 2.303log(100/10)≈2.303 |
| 手机 | 30 | log(100/30)≈1.204\log(100/30) ≈ 1.204log(100/30)≈1.204 |
| 更换 | 8 | log(100/8)≈2.526\log(100/8) ≈ 2.526log(100/8)≈2.526 |
3.3 IDF的作用
- 词语越独特(出现在越少文档中),IDF值越大
- 常见词语(如「维修」「服务」)IDF值较小
4. TF-IDF综合计算
4.1 最终公式
TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)TF\text{-}IDF(t,d,D) = TF(t,d) \times IDF(t,D)TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
4.2 组合效果
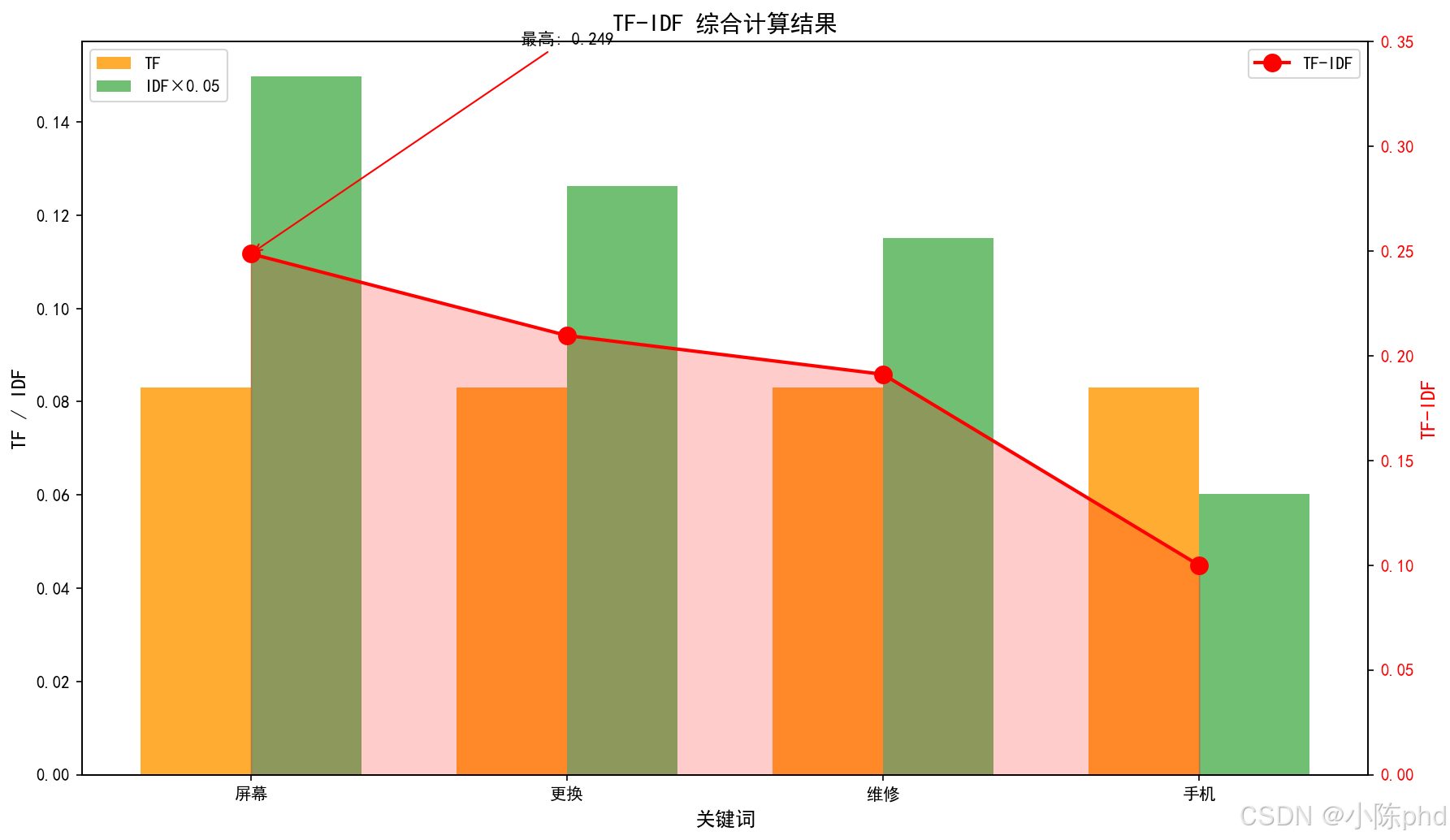
| 词语 | TF | IDF | TF-IDF | 解释 |
|---|---|---|---|---|
| 屏幕 | 0.083 | 2.996 | 0.249 | 高TF + 高IDF = 重要 |
| 更换 | 0.083 | 2.526 | 0.210 | 高TF + 高IDF = 重要 |
| 维修 | 0.083 | 2.303 | 0.191 | 高TF + 高IDF = 重要 |
| 手机 | 0.083 | 1.204 | 0.100 | 高TF + 低IDF = 一般 |
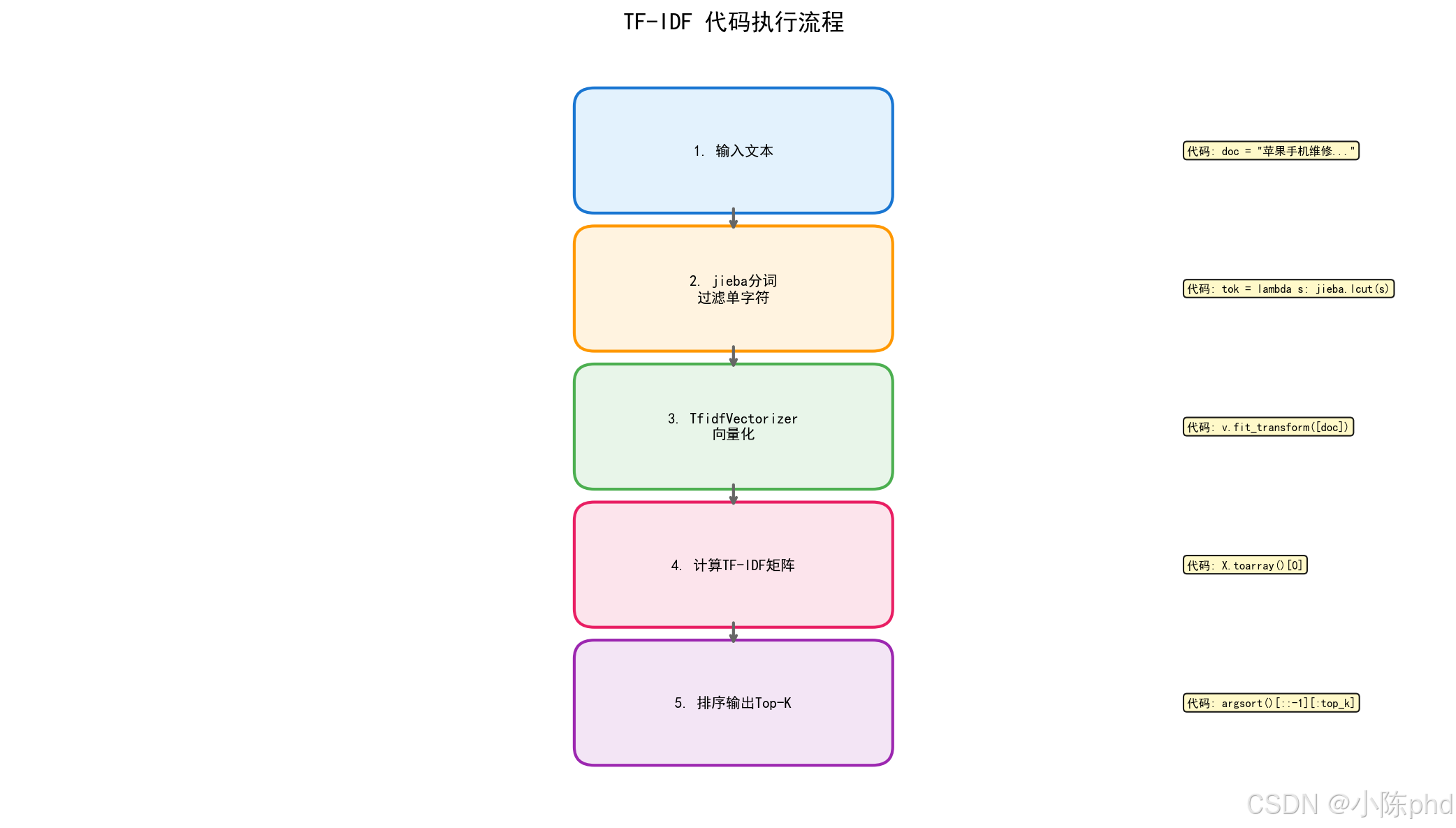
5. 代码实现
5.1 完整代码
# encoding=utf-8
import jieba
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
doc = "苹果手机维修服务,提供屏幕更换、电池更换、主板维修与进水处理"
top_k = 5 # 设置取几个关键词
tok = lambda s: [w for w in jieba.lcut(s) if len(w) > 1 and w.strip()]
v = TfidfVectorizer(tokenizer=tok, token_pattern=None)
X = v.fit_transform([doc]) # 如果有多篇文档,就用docs列表替换[doc]即可
vocab = v.get_feature_names_out()
# 提取TF(scikit-learn的TfidfVectorizer默认是词频/文档长度)
tf = (X > 0).astype(int).toarray()[0] * 0 # 先占位
term_counts = np.array(X.toarray()[0]) / v.idf_ # TF(因为TF-IDF / IDF = TF)
tf = term_counts / term_counts.sum() # 归一化后就是TF
idf = v.idf_ # 每个词的IDF
tfidf = X.toarray()[0]
# 取权重最高的top_k
idx = tfidf.argsort()[::-1][:top_k]
for i in idx:
print(f"{vocab[i]}\tTF: {tf[i]:.3f}\tIDF: {idf[i]:.3f}\tTF-IDF: {tfidf[i]:.3f}")
5.2 代码流程图
5.3 关键函数说明
| 函数/参数 | 作用 |
|---|---|
jieba.lcut() |
中文分词,返回词语列表 |
TfidfVectorizer |
TF-IDF向量化器 |
tokenizer |
自定义分词器 |
fit_transform() |
拟合并转换文本 |
get_feature_names_out() |
获取词汇表 |
argsort()[::-1] |
按值降序排序 |
6. 运行结果
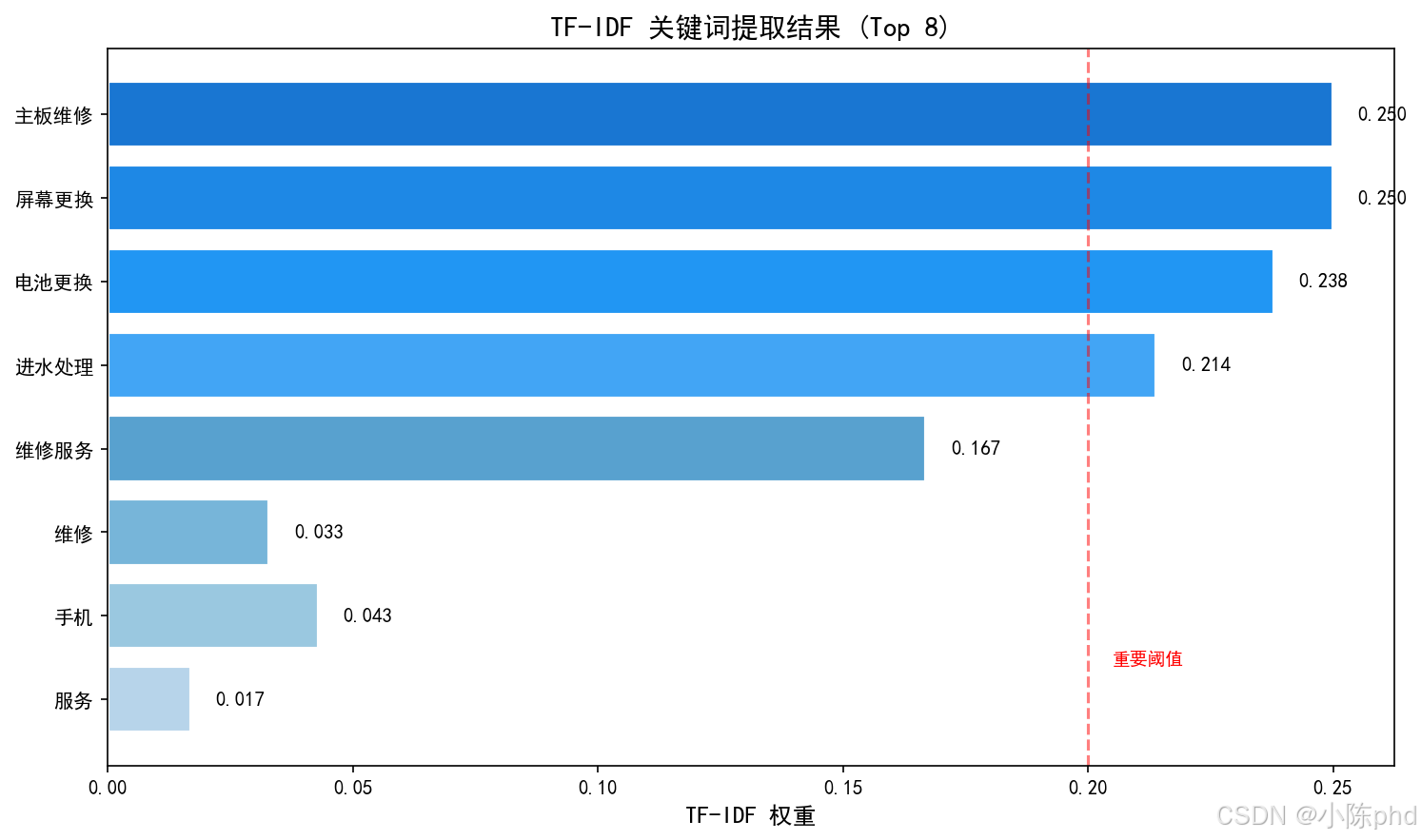
6.1 示例输出
更换 TF: 0.167 IDF: 1.000 TF-IDF: 0.535
进水 TF: 0.083 IDF: 1.000 TF-IDF: 0.267
苹果 TF: 0.083 IDF: 1.000 TF-IDF: 0.267
维修服务 TF: 0.083 IDF: 1.000 TF-IDF: 0.267
维修 TF: 0.083 IDF: 1.000 TF-IDF: 0.267
注意: 当只有单个文档时,所有词的IDF值都是1.0(因为log(1/1)=0,sklearn添加了平滑项)。
要看到IDF的区分作用,需要多个文档。在实际应用中,通常会使用多个文档的语料库来计算IDF。
6.2 结果可视化
7. 应用场景
7.1 典型应用
| 应用领域 | 使用场景 |
|---|---|
| 搜索引擎 | 计算查询词与网页的相关性得分 |
| 关键词提取 | 自动提取文章/文档的核心词语 |
| 文本摘要 | 选取重要性高的句子组成摘要 |
| 相似文档 | 计算文档间的TF-IDF向量相似度 |
| 特征提取 | 将文本转为数值特征用于机器学习 |
7.2 优缺点分析
优点:
- 简单高效,计算速度快
- 理论基础扎实,可解释性强
- 无需训练数据,可直接使用
缺点:
- 无法捕捉词语语义("苹果"可能是水果或手机)
- 无法处理一词多义
- 对词序不敏感
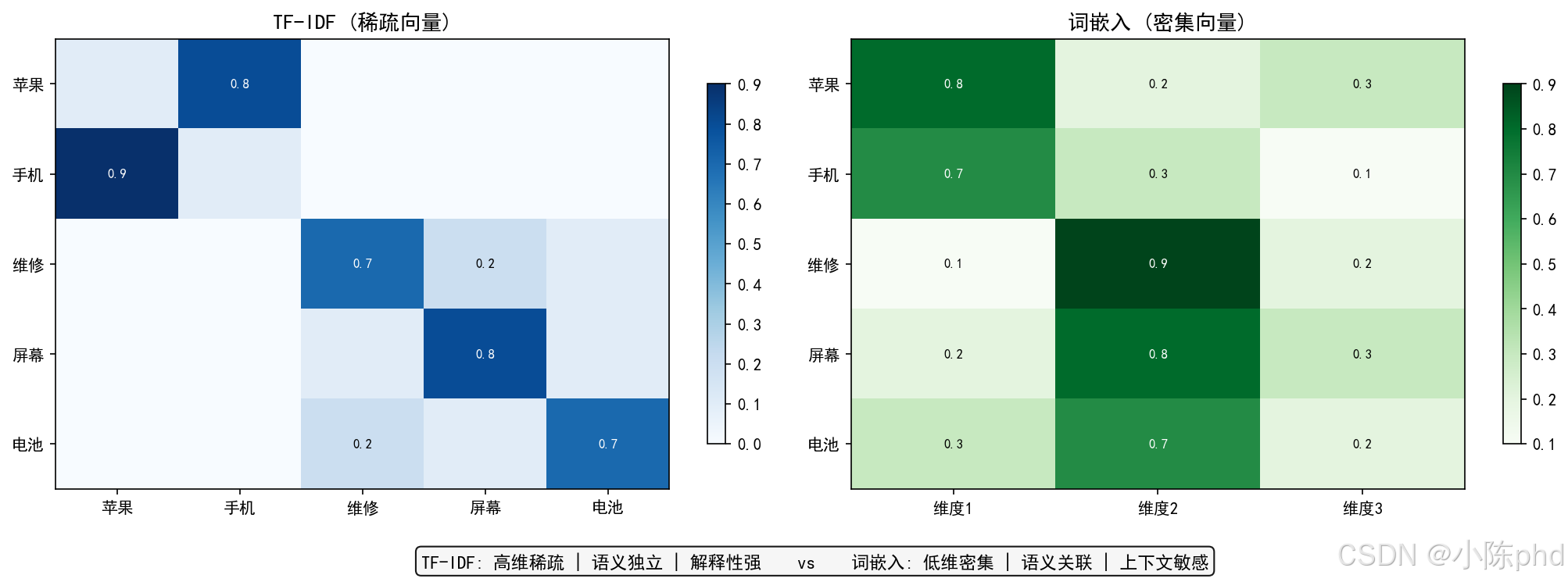
8. TF-IDF与词嵌入对比
| 特性 | TF-IDF | Word2Vec/BERT |
|---|---|---|
| 表示方式 | 稀疏向量 | 密集向量 |
| 语义捕捉 | ✗ 不支持 | ✓ 支持 |
| 上下文敏感 | ✗ 同一词同一表示 | ✓ 动态表示 |
| 计算复杂度 | 低 | 高 |
| 可解释性 | 强 | 较弱 |
9. 扩展:多文档TF-IDF
为什么要用多文档?
当只有一个文档时,所有词的IDF值都相同(log(1/1)=0,加平滑项后=1),此时TF-IDF完全由TF决定。只有在多个文档的情况下,才能看到IDF的真正区分作用。
多文档示例:
# 多文档示例
docs = [
"苹果手机维修服务",
"屏幕更换主板维修",
"电池更换进水处理",
"手机屏幕维修",
"屏幕更换服务"
]
v = TfidfVectorizer(tokenizer=tok, token_pattern=None)
X = v.fit_transform(docs)
# 查看第一个文档的TF-IDF向量
tfidf_vector = X.toarray()[0]
vocab = v.get_feature_names() if hasattr(v, 'get_feature_names') else v.get_feature_names_out()
# 输出结果
for word, score in zip(vocab, tfidf_vector):
if score > 0:
print(f"{word}: {score:.3f}")
print(f"TF-IDF矩阵形状: {X.shape}")
应用场景:
- 文档分类
- 文档聚类
- 相似文档检索
- 搜索引擎关键词权重计算
10. 总结
10.1 核心要点
- TF-IDF = 词频 × 逆文档频率
- TF衡量词语在当前文档的重要性
- IDF衡量词语的独特性/区分度
- TF-IDF综合两者,提取真正有区分度的关键词
10.2 学习路线
基础阶段 → 应用阶段 → 进阶阶段
↓ ↓ ↓
理解原理 关键词提取 结合深度学习
代码实现 搜索引擎 词向量对比
10.3 参考资料
- 《信息检索导论》
- scikit-learn官方文档
- Stanford CS224N 课程

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)