【AI大模型前沿】T5Gemma 2:谷歌开源的下一代紧凑型多模态长上下文编解码模型
T5Gemma 2 是基于 Gemma 3 架构的下一代编码器 - 解码器模型,首次引入了多模态与长上下文支持。相比前代,它采用共享词嵌入及合并解码器自注意力与交叉注意力机制,有效减少参数量,提供 270M - 270M(约 3.7 亿)、1B - 1B(约 17 亿)和 4B - 4B(约 70 亿)三种规模的紧凑预训练模型,适用于快速实验与终端设备部署。
系列篇章💥
前言
随着人工智能技术的不断发展,大型语言模型在自然语言处理领域取得了显著进展。然而,这些模型往往面临着参数庞大、计算资源消耗大等问题,限制了其在实际应用中的广泛部署。谷歌近期开源的 T5Gemma 2 模型,旨在通过技术创新解决这一难题,它在保持紧凑尺寸的同时,实现了功能上的巨大扩展,为紧凑型编解码模型的性能树立了新的标杆。
一、项目概述
T5Gemma 2 是基于 Gemma 3 架构的下一代编码器 - 解码器模型,首次引入了多模态与长上下文支持。相比前代,它采用共享词嵌入及合并解码器自注意力与交叉注意力机制,有效减少参数量,提供 270M - 270M(约 3.7 亿)、1B - 1B(约 17 亿)和 4B - 4B(约 70 亿)三种规模的紧凑预训练模型,适用于快速实验与终端设备部署。
二、核心功能
(一)多模态理解与生成
T5Gemma 2 能够同时处理文本和图像信息,可执行视觉问答、多模态推理等任务,比如根据图像内容回答相关问题,将图像信息与文本描述相结合进行生成。
(二)长上下文处理
具备强大的长上下文能力,能处理长达 128K 个标记的上下文窗口,适合需要长文本理解和生成的场景,如长篇文档的总结、长故事的续写等。
(三)编码 - 解码功能
作为编码器 - 解码器模型,将输入的文本或图像编码成向量,通过解码器生成目标文本,用于翻译、文本改写、摘要生成等多种自然语言处理任务。
(四)多语言支持
支持超过 140 种语言,满足不同语言环境下的应用需求,实现跨语言的文本处理和生成。
(五)端侧高效部署
模型参数紧凑,适合在手机、浏览器等端侧设备上快速部署和运行,为端侧应用提供强大的 AI 能力支持。
三、技术揭秘
(一)编码器 - 解码器架构
T5Gemma 2 采用经典的编码器 - 解码器架构,编码器负责处理输入(如文本或图像),生成语义向量;解码器基于向量生成目标输出(如文本描述)。
(二)多模态能力
T5Gemma 2 集成一个高效的视觉编码器(如 SigLIP),将图像转换为 256 个嵌入向量,向量被输入到编码器中进行视觉理解。通过将视觉特征和文本特征融合,模型能同时处理文本和图像信息,支持多模态任务,如视觉问答(VQA)和图像描述生成。
(三)长上下文处理
T5Gemma 2 采用交替局部和全局注意力机制,能处理长达 128K 的上下文窗口,显著提升长上下文任务的性能。通过调整位置编码的频率,模型在处理长序列时能更好地捕捉局部和全局信息。
(四)模型适配技术
T5Gemma 2 的参数初始化来自预训练的纯解码器模型(如 Gemma 3),通过 UL2 预训练目标进行适配,继承预训练模型的语言理解能力。这种适配策略不仅适用于文本任务,还扩展到了多模态和长上下文任务,证明了其通用性和高效性。
(五)效率优化
T5Gemma 2 将编码器和解码器的词嵌入层绑定在一起,共享参数,显著减少模型的总参数量,提高模型的效率。将解码器中的自注意力和交叉注意力合并为一个统一的模块,减少模型参数和架构复杂性,同时提高推理效率。
四、基准评测
(一)多模态任务
T5Gemma 2-270m-270m 在多模态任务中表现出色,能够处理图像和文本输入并生成文本输出。例如,在视觉问答(VQA)任务中,模型可以准确理解图像内容并回答相关问题。在图像描述生成任务中,模型能够根据输入图像生成详细的描述文本,帮助用户快速理解图像内容。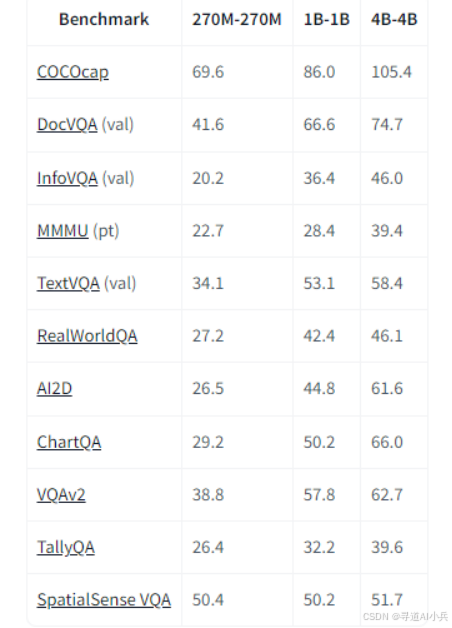
(二)长上下文处理
该模型支持长达 128K 的上下文窗口,适用于长文本生成和理解任务。在长文本生成任务中,模型能够生成高质量的长篇文档总结或续写内容。在长上下文推理任务中,模型能够处理复杂的长文本输入并生成准确的输出。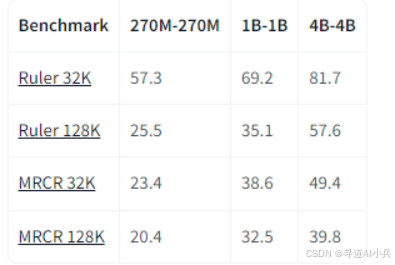
(三)多语言支持
T5Gemma 2-270m-270m 支持超过 140 种语言,能够处理多语言输入并生成多语言输出。在跨语言翻译任务中,模型能够将一种语言的文本准确翻译成另一种语言,广泛应用于国际商务和在线翻译服务。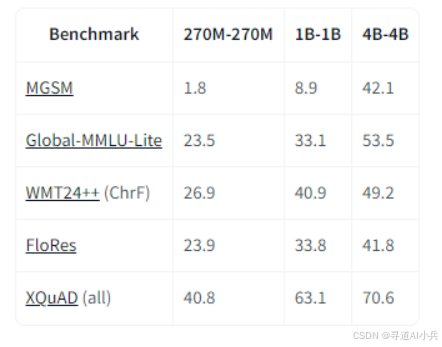
(四)推理任务
在推理任务中,模型能够结合图像和文本信息进行复杂推理,判断场景是否符合描述或进行逻辑推理。例如,在智能安防领域,模型可以分析监控图像并生成警报信息。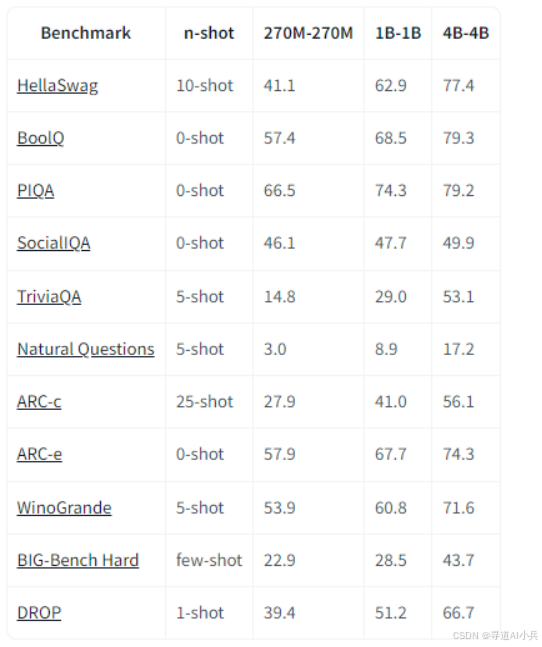
五、应用场景
(一)视觉问答
T5Gemma 2 在视觉问答(VQA)任务中表现出色。它能够同时理解图像和文本信息,根据图像内容回答相关问题。例如,用户上传一张照片并提问“图片中的人在做什么?”模型可以准确识别图像内容并生成清晰的回答。这种能力使其在教育、智能客服等领域具有广泛的应用前景,能够帮助用户快速获取图像中的关键信息。
(二)图像描述生成
T5Gemma 2 可以自动生成图像描述文本。用户只需上传一张图片,模型就能生成详细的描述文本,帮助用户快速理解图像内容。这一功能对于社交媒体平台和视障人士辅助工具尤为重要,能够为用户提供更丰富的视觉信息,提升用户体验。
(三)多模态推理
T5Gemma 2 支持多模态推理任务,能够结合图像和文本进行复杂推理。例如,它可以判断场景是否符合描述,或者根据图像和文本信息进行逻辑推理。这一功能在智能安防和自动驾驶等领域具有重要应用价值,能够帮助系统更准确地理解环境信息并做出决策。
(四)跨语言翻译
T5Gemma 2 支持超过 140 种语言的跨语言翻译。用户可以输入一种语言的文本,模型将其翻译成另一种语言。这一功能广泛应用于在线翻译服务和国际商务沟通,帮助用户跨越语言障碍,实现更高效的跨语言交流。
(五)手机语音助手
T5Gemma 2 适合在手机等端侧设备上快速部署和运行。它可以作为语音助手的核心模型,支持语音搜索和指令执行。用户可以通过语音指令获取信息或完成操作,提升交互体验。这种高效部署能力使其成为手机语音助手的理想选择。
(六)长文本生成
T5Gemma 2 具备强大的长上下文处理能力,能够处理长达 128K 个标记的上下文窗口。这使得它在长文本生成任务中表现出色,例如长篇文档的总结、长故事的续写等。用户可以输入一段长文本,模型生成高质量的总结或续写内容,帮助用户高效处理长文本任务。
(七)文档理解与处理
T5Gemma 2 可以应用于文档理解与处理任务,例如从长篇文档中提取关键信息、生成摘要或回答相关问题。它能够处理复杂的文档结构,理解上下文信息,并生成准确的输出。这一功能在办公自动化、学术研究等领域具有重要应用价值。
六、快速使用
(一)安装依赖
pip install -U transformers
(二)使用 pipeline API 运行
from transformers import pipeline
generator = pipeline(
"image-text-to-text",
model="google/t5gemma-2-270m-270m",
)
generator(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
text="<start_of_image> in this image, there is",
generate_kwargs={"do_sample": False, "max_new_tokens": 50},
)
(三)在单个/多个GPU运行
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForSeq2SeqLM
processor = AutoProcessor.from_pretrained("google/t5gemma-2-270m-270m")
model = AutoModelForSeq2SeqLM.from_pretrained("google/t5gemma-2-270m-270m")
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "<start_of_image> in this image, there is"
model_inputs = processor(text=prompt, images=image, return_tensors="pt")
generation = model.generate(**model_inputs, max_new_tokens=20, do_sample=False)
print(processor.decode(generation[0]))
Input: 输入:
1)文本字符串,例如一个问题、一个提示或一个要总结的文档
2)图像,标准化为 896 x 896 分辨率,每张图像编码为 256 个 token
3)总输入上下文为 128K 个 token
Output: 输出:
1)根据输入生成的文本,例如问题的答案、图像内容的分析或文档的摘要
2)总输出上下文高达 32K 个 token
七、结语
T5Gemma 2 作为谷歌开源的下一代紧凑型多模态长上下文编解码模型,凭借其强大的多模态处理能力、长上下文支持以及高效的端侧部署性能,为自然语言处理领域带来了新的突破。它不仅在性能上超越了前代模型,还在多语言支持和应用场景的广泛性上展现出巨大潜力。T5Gemma 2 的开源为研究人员和开发者提供了强大的工具,推动了 AI 技术在更多领域的应用和发展。
项目地址
- 项目官网:https://blog.google/technology/developers/t5gemma-2/
- HuggingFace 模型库:https://huggingface.co/collections/google/t5gemma-2
- arXiv 技术论文:https://arxiv.org/pdf/2512.14856

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)