[LangChain之链]Runnable——整个LangChain生态世界的起点
虽然真正的Runnable类型具有很多成员,但是本质上和我们在上面定义的模拟类型很类似。如下面的代码片段所示,这也是一个泛型的抽象类,同样具有一个唯一抽象方法invoke,只是它具有额外两个用于控制执行行为的参数:config提供作为执行配置的RunnableConfig对象,关键字参数kwargs以键值对的方式指定相应的控制选项。
Input = TypeVar('Input')
Output = TypeVar('Output')
class Runnable(ABC, Generic[Input, Output]):
name: str | None
def get_name(self, suffix: str | None = None, *, name: str | None = None) -> str
@abstractmethod
def invoke(
self,
input: Input,
config: RunnableConfig | None = None,
**kwargs: Any,
) -> Output
1. 命名
我们可以利用构造函数初始化name字段,为它指定一个名称。如果没有显式指定,也可以调用get_name方法通过解析自身类型得到一个名称。对于一般类型,该方法会直接返回类名。如果是一个继承自pydantic.BaseModel的泛型类型(比如Result[int]),会返回不含泛型参数的类名(Result)。我们还可利用参数suffix为返回的名称添加一个后缀。
class Runnable(ABC, Generic[Input, Output]):
name: str | None
def get_name(self, suffix: str | None = None, *, name: str | None = None) -> str
2. 输入/输出类型和Schema
除了利用属性InputType和OutputType返回输入和输出类型外,Runnable的get_input_schema和get_out_schema方法还会提供一个pydantic.BaseModel类型作为对应的Schema。如果输入或输出类型继承pydantic.BaseModel类型,这两个方法会直接返回它们,否则它们会根据具体类型创建一个。input_schema和output_schema属性返回的就是调用这两个方法的结果。至于另外一组get_input_jsonschema和get_output_jsonschema会根据输入和输出类型生成一个表示JSON Schema的字典。
class Runnable(ABC, Generic[Input, Output]):
@property
def InputType(self) -> type[Input]
@property
def OutputType(self) -> type[Output]
@property
def input_schema(self) -> type[BaseModel]
@property
def output_schema(self) -> type[BaseModel]
def get_input_schema(
self,
config: RunnableConfig | None = None,
) -> type[BaseModel]
def get_output_schema(
self,
config: RunnableConfig | None = None,
) -> type[BaseModel]
def get_input_jsonschema(
self, config: RunnableConfig | None = None
) -> dict[str, Any]
def get_output_jsonschema(
self, config: RunnableConfig | None = None
) -> dict[str, Any]
在如下的演示程序中,我们通过继承pydantic.BaseModel定义了两个数据类型Input和Output,函数handle将它们分别作为输入和输出。我们针对handle函数创建了一个RunnableLambda对象,并输出输入输出类型和相应的Schema。
from langchain_core.runnables import Runnable, RunnableLambda
from pydantic import BaseModel
import json
class Input(BaseModel):
foo: str
bar: int
class Output(BaseModel):
baz: str
qux: float
def handle(input: Input) -> Output:
pass
runnable = RunnableLambda(handle)
print(f"Input Type: {runnable.InputType}")
print(f"Output Type: {runnable.OutputType}")
print(f"Input Schema: {runnable.input_schema}")
print(f"Output Schema: {runnable.output_schema}")
print(f"Input JSON Schema: {json.dumps(runnable.get_input_jsonschema(), indent=2)}")
print(f"Output JSON Schema: {json.dumps(runnable.get_output_jsonschema(), indent=2)}")
这个RunnableLambda对象的输入和输出类型、输入和输出Schema以及JSON Schema体现在如下所示的输出结果中:
Input Type: <class '__main__.Input'>
Output Type: <class '__main__.Output'>
Input Schema: <class '__main__.Input'>
Output Schema: <class '__main__.Output'>
Input JSON Schema: {
"properties": {
"foo": {
"title": "Foo",
"type": "string"
},
"bar": {
"title": "Bar",
"type": "integer"
}
},
"required": [
"foo",
"bar"
],
"title": "Input",
"type": "object"
}
Output JSON Schema: {
"properties": {
"baz": {
"title": "Baz",
"type": "string"
},
"qux": {
"title": "Qux",
"type": "number"
}
},
"required": [
"baz",
"qux"
],
"title": "Output",
"type": "object"
}
3. 四种调用形式
Runnable支持invoke、stream、transform和batch四种调用方式,它们又同时具有同步的异步版本。由于它只定义了一个唯一的invoke抽象方法,意味着它针对其他调用方式默认实现,最终都会调用此方法来完成。这自然仅仅是一种“兜底”的形式,派生类需要根据需求重写相应的方法。
invoke/ainvoke
如下所示的ainvoke方法会利用run_in_executor方法在一个时间循环中以异步方式调用invoke方法。
class Runnable(ABC, Generic[Input, Output]):
async def ainvoke(
self,
input: Input,
config: RunnableConfig | None = None,
**kwargs: Any,
) -> Output:
return await run_in_executor(config, self.invoke, input, config, **kwargs)
stream/astream
以流的方式实时输出执行结果的stream方法返回一个Iterator[Output]对象,它会直接调用invoke方法。另一个返回AsyncIterator[Output]的astream方法则会调用ainvoke方法。
class Runnable(ABC, Generic[Input, Output]):
def stream(
self,
input: Input,
config: RunnableConfig | None = None,
**kwargs: Any | None,
) -> Iterator[Output]:
yield self.invoke(input, config, **kwargs)
async def astream(
self,
input: Input,
config: RunnableConfig | None = None,
**kwargs: Any | None,
) -> AsyncIterator[Output]:
yield await self.ainvoke(input, config, **kwargs)
transform/atransform
流式处理还体现在transform/atransform方法上。stream 方法接收一个完整输入,然后流式地返回输出块,transform/atransform方法第一个参数是一个Iterator[Input]/AsyncIterator[Input]类型的迭代器,也就是说它接收一个输入流并实时产生输出流。这意味着当链条中的上一个组件还在吐出数据时,transform/atransform方法就可以开始处理并向下游传递,而不需要等待上游完全结束。
Runnable实现这两个方法的方式非常的“简单粗暴”,它会假设Input具有可加性,并利用+操作符对提供的输入进行汇总,如果不支持就只处理最后一个输入。该方法最终调用的还是stream和astream方法。
class Runnable(ABC, Generic[Input, Output]):
def transform(
self,
input: Iterator[Input],
config: RunnableConfig | None = None,
**kwargs: Any | None,
) -> Iterator[Output]:
final: Input
got_first_val = False
for ichunk in input:
if not got_first_val:
final = ichunk
got_first_val = True
else:
try:
final = final + ichunk # type: ignore[operator]
except TypeError:
final = ichunk
if got_first_val:
yield from self.stream(final, config, **kwargs)
async def atransform(
self,
input: AsyncIterator[Input],
config: RunnableConfig | None = None,
**kwargs: Any | None,
) -> AsyncIterator[Output]:
final: Input
got_first_val = False
async for ichunk in input:
if not got_first_val:
final = ichunk
got_first_val = True
else:
try:
final = final + ichunk # type: ignore[operator]
except TypeError:
final = ichunk
if got_first_val:
async for output in self.astream(final, config, **kwargs):
yield output
知道了transform/atransform方法在Runnable中的默认实现,我们对该方法在如下程序中的返回值就不会感到奇怪了。由于该方法总是会输入进行迭代,并利用“+”操作符对它们进行汇总,所以第一次调用被用于转换的其实是字符串“foobarbaz”。由于我们定义的Point类型不支持此操作符,所以方法只对最后一个元素进行处理。
from langchain_core.runnables import Runnable,RunnableConfig
from typing import Any, Callable
class RunnableCallable(Runnable[str,str]):
def __init__(self, func: Callable[[str], str]):
super().__init__()
self.func = func
def invoke(
self,
input: str,
config: RunnableConfig | None = None,
**kwargs: Any,
) -> str:
return self.func(input)
runnable = RunnableCallable(lambda x: x.upper())
result = runnable.transform(("foo","bar","baz"))
assert list(result) == ["FOOBARBAZ"]
class Point:
def __init__(self, x: float, y: float):
self.x = x
self.y = y
def __str__(self):
return f"({self.x}, {self.y})"
runnable = RunnableCallable(lambda point: str(point))
result = runnable.transform([Point(1.0, 1.0),Point(2.0, 2.0),Point(3.0, 3.0)])
assert list(result) == [ "(3.0, 3.0)"]
batch/abatch
前面两种调用方式只能一次指定单一的任务,batch方法则可以通过一个调用完成多项任务,这是处理高吞吐量和实现大规模并行计算的核心方法。这种方式将多个任务打包执行还可以减少调用LLM消耗的Token数量,进而降低成本。Runnable默认实现的batch方法会判断输入的数量,如果没有输入,直接返回一个空的输出列表。如果只有一个输入,只需要以此为参数调用invoke方法,并将执行结果封装成返回的输出列表。对于多个输入,会拆分成多个针对invoke方法的调用,这些调用会在一个所谓的执行器中并行执行。只有等到所有调用全部结束,方法才会将汇总的输出封装成返回的列表。
class Runnable(ABC, Generic[Input, Output]):
def batch(
self,
inputs: list[Input],
config: RunnableConfig | list[RunnableConfig] | None = None,
*,
return_exceptions: bool = False,
**kwargs: Any | None,
) -> list[Output]
abatch方法会将每个输入转换成针对ainvoke方法调用的Coroutine并调度执行。如果在配置中设置了最大并发度,该方法会创建一个asyncio.Semaphore对象实施并发控制。调用此方法也同样需要等到所有并发调用全部结束后,才会得到汇总的结果。
class Runnable(ABC, Generic[Input, Output]):
async def abatch(
self,
inputs: list[Input],
config: RunnableConfig | list[RunnableConfig] | None = None,
*,
return_exceptions: bool = False,
**kwargs: Any | None,
) -> list[Output]
batch/abatch方法这种等到所有的输入全部处理完毕才能获取汇总结果的调用方式可能会带来很大的时延,所以最好的方式是每处理一个就返回一个,这正是batch_as_completed方法存在的原因。从如下的实现可以看出,它将针对每个输入的invoke方法的调用封装成一个Future,每个Future结束之后其结果都会立即返回。该方法返回一个迭代器,每次迭代都会得到一个二元组,前半部分表示当前处理的输入在指定输入列表中的序号,后半部分是执行结果。abatch_as_completed方法以并发调用执行coroutine的方式实现了类似的功能。
class Runnable(ABC, Generic[Input, Output]):
@overload
def batch_as_completed(
self,
inputs: Sequence[Input],
config: RunnableConfig | Sequence[RunnableConfig] | None = None,
*,
return_exceptions: Literal[False] = False,
**kwargs: Any,
) -> Iterator[tuple[int, Output]]: ...
@overload
def batch_as_completed(
self,
inputs: Sequence[Input],
config: RunnableConfig | Sequence[RunnableConfig] | None = None,
*,
return_exceptions: Literal[True],
**kwargs: Any,
) -> Iterator[tuple[int, Output | Exception]]: ...
def batch_as_completed(
self,
inputs: Sequence[Input],
config: RunnableConfig | Sequence[RunnableConfig] | None = None,
*,
return_exceptions: bool = False,
**kwargs: Any | None,
) -> Iterator[tuple[int, Output | Exception]]
@overload
def abatch_as_completed(
self,
inputs: Sequence[Input],
config: RunnableConfig | Sequence[RunnableConfig] | None = None,
*,
return_exceptions: Literal[False] = False,
**kwargs: Any | None,
) -> AsyncIterator[tuple[int, Output]]: ...
@overload
def abatch_as_completed(
self,
inputs: Sequence[Input],
config: RunnableConfig | Sequence[RunnableConfig] | None = None,
*,
return_exceptions: Literal[True],
**kwargs: Any | None,
) -> AsyncIterator[tuple[int, Output | Exception]]: ...
async def abatch_as_completed(
self,
inputs: Sequence[Input],
config: RunnableConfig | Sequence[RunnableConfig] | None = None,
*,
return_exceptions: bool = False,
**kwargs: Any | None,
) -> AsyncIterator[tuple[int, Output | Exception]]
4. 可视化呈现
Runnable的get_graph方法返回一个Graph对象可以展现其图结构。这意味着Runnable不仅仅提供了基于代码的描述语言,还直接提供了一种可视化的呈现方式,对于一个承载复杂任务的Runnable,以可视化的方式将其整个全貌展现出来具有很大的价值。
class Runnable(ABC, Generic[Input, Output]):
def get_graph(self, config: RunnableConfig | None = None) -> Graph
一个Graph对象定义的图由节点(Node)和边(Edge)构成。它的每个Node都有一个唯一标识,我们可以调用next_id方法为下一个待添加的Node生成此标识。在构建图的时候,我们不仅可以调用add_node、remove_node和add_edge这样的方法以添加/移除Node和Edge,还可以调用extend方法将另一个Graph的所有Node和Edge添加进来。
@dataclass
class Graph:
nodes: dict[str, Node] = field(default_factory=dict)
edges: list[Edge] = field(default_factory=list)
def next_id(self) -> str
def add_node(
self,
data: type[BaseModel] | RunnableType | None,
id: str | None = None,
*,
metadata: dict[str, Any] | None = None,
) -> Node
def remove_node(self, node: Node) -> None
def add_edge(
self,
source: Node,
target: Node,
data: Stringifiable | None = None,
conditional: bool = False, # noqa: FBT001,FBT002
) -> Edge
def extend(
self, graph: Graph, *, prefix: str = ""
) -> tuple[Node | None, Node | None]:
def reid(self) -> Graph:
def first_node(self) -> Node | None
def last_node(self) -> Node | None
def trim_first_node(self) -> None
def trim_last_node(self) -> None
def to_json(self, *, with_schemas: bool = False) -> dict[str, list[dict[str, Any]]]
def draw_ascii(self) -> str:
def print_ascii(self) -> None:
@overload
def draw_png(
self,
output_file_path: str,
fontname: str | None = None,
labels: LabelsDict | None = None,
) -> None: ...
@overload
def draw_png(
self,
output_file_path: None,
fontname: str | None = None,
labels: LabelsDict | None = None,
) -> bytes: ...
def draw_png(
self,
output_file_path: str | None = None,
fontname: str | None = None,
labels: LabelsDict | None = None,
) -> bytes | None
def draw_mermaid(
self,
*,
with_styles: bool = True,
curve_style: CurveStyle = CurveStyle.LINEAR,
node_colors: NodeStyles | None = None,
wrap_label_n_words: int = 9,
frontmatter_config: dict[str, Any] | None = None,
) -> str
def draw_mermaid_png(
self,
*,
curve_style: CurveStyle = CurveStyle.LINEAR,
node_colors: NodeStyles | None = None,
wrap_label_n_words: int = 9,
output_file_path: str | None = None,
draw_method: MermaidDrawMethod = MermaidDrawMethod.API,
background_color: str = "white",
padding: int = 10,
max_retries: int = 1,
retry_delay: float = 1.0,
frontmatter_config: dict[str, Any] | None = None,
base_url: str | None = None,
proxies: dict[str, str] | None = None,
) -> bytes
调用reid方法可以返回一个新的Graph对象,它尽量保留图中可读性的元素,但是Node的ID会重新生成。Graph的first_node和last_node方法返回第一个和最后一个Node。如果我们希望删除第一个只有单一输出Edge或者最后一个只有单一输入Edge的Node,可以调用trim_first_node或者trim_last_node方法。
Graph提供了五个“绘图”方法,其中draw_ascii和print_ascii方法采用ascii码字符的呈现方式,前者返回具体的ascii码字符串,后者则直接在终端将图绘制出来,这种方法不依赖其他的绘图相关的包。draw_mermaid和draw_mermaid_png方法采用Mermaid图表的呈现方式,Mermaid是一种基于文本的流程图定义语言,广泛支持于 GitHub、Notion 和各种编辑器中。draw_mermaid返回图标文本,而draw_mermaid_png则直接将图表进一步渲染成PNG图片。Graph对象也可以通过调用draw_png方法渲染成PNG图片,该方法最终会Graphviz(一个开源的图可视化软件)来布局和渲染图片。
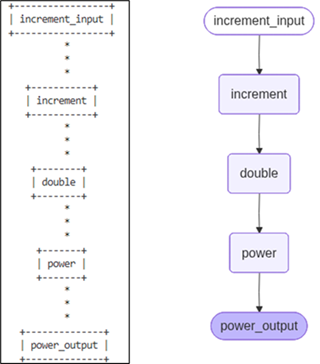
在如下的演示程序中,我们利用管道的形式构建了由三个RunnableLambda组成的Runnable对象,在得到它的Graph对象后,我们调用graph.print_ascii方法在当前终端输出以ASCII码字符呈现的结构。然后我们调用draw_mermaid_png方法得到渲染成PNG图片的字节,并利用PIL将此图片显示出来。
from PIL import Image
import io
from langchain_core.runnables import RunnableLambda
chain = RunnableLambda(lambda x: x + 1, name="increment")
chain = chain | RunnableLambda(lambda x: x * 2, name="double")
chain = chain | RunnableLambda(lambda x: x * x, name="power")
graph = chain.get_graph()
print(graph.draw_ascii())
png_bytes = graph.draw_mermaid_png()
Image.open(io.BytesIO(png_bytes)).show()
下面这张图片左边就是Graph对象以ASCII码字符绘制出来的效果,右边则是渲染出来的更具表现力的PNG图片。
5. 获取提示词模板
Runnable的get_prompts方法可以提取提示词模板,具体返回的是一个BasePromptTemplate对象列表,BasePromptTemplate是提示词模板的基类。
class Runnable(ABC, Generic[Input, Output]):
def get_prompts(
self, config: RunnableConfig | None = None
) -> list[BasePromptTemplate]
在如下这个演示实例中,我们创建了两个Runnable对象,一个是ChatPromptTemplate对象,并一个基于“gpt-5.2-chat”的ChatOpenAI对象。我们利用管道将两者串联在一起,并将用于替换模板占位符的内容作为参数调用其invoke方法,完整了以此针对Chat模型的调用。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("Give me some briefing information about {topic}.")
model = ChatOpenAI(
model= "gpt-5.2-chat",
base_url="…",
api_key= "…")
chain = prompt | model
response = chain.invoke({"topic": "LangGraph.Pregel"})
result:str = response.content
print(result[:200],"...\n")
for p in chain.get_prompts():
print("Prompt used:")
print(p.pretty_repr())
我们输出模型返回的内容。为了确认此内容是否与当前使用的提示词向匹配,我们调用了get_prompts方法,并传入一样的对得到提示词模板进行格式化,模型的输出和提示词模板格式化的结果包含在如下的输出中。
**LangGraph.Pregel** is an execution model in the **LangGraph** framework that’s inspired by Google’s **Pregel** system for large-scale graph processing. It’s designed to run **stateful, iterative, an ...
Prompt used:
Human: Give me some briefing information about LangGraph.Pregel.
其实Runnable还有很多其他的方法,但是它们的返回值大都但会一个具体的Runnable对象,我们后续对这些预定义Runnable实现进行详细介绍时再来补充

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)