Vibe Coding - Claude Skills 最佳实践指南:把“提示词”升级成可复用的工作流
摘要:本文介绍如何构建专业AI Agent的Skill(技能),将工作流程打包成可复用的指令集。Skill包含YAML元数据、SKILL.md核心文件和辅助资源,采用渐进式披露优化性能。与MCP(模型连接协议)配合使用,可解决工具连接后工作流不稳定的问题。Skill分为文档生成、工作流自动化和MCP增强三类,需通过具体用例定义触发条件和步骤。文章详细讲解命名规则、YAML编写、指令设计原则及测试方
文章目录
- Pre
- 1. 引言:为什么突然都在聊 Skills?
- 2. Skills 是什么:不只是提示词,而是“流程+标准+检查”
- 3. Skills 长什么样:一个文件夹 + 一个 SKILL.md
- 4. Skills 和 MCP:厨房和菜谱,缺一不可
- 5. 三种常见 Skill:从“写文档”到“多工具编排”
- 6. 从 0 到 1:写一个能触发、能跑通、能复用的 Skill
- 7. 测试与迭代:别只看“能不能跑”,要看“比之前强多少”
- 8. 快速上手:用 skill-creator 先生成一个可用骨架
- 9. 常见坑:为什么不触发、为什么乱触发、为什么不听话?
- 10. 分发与使用:个人、团队、企业、API 各有一套玩法
- 11. 五种设计模式:把“能用”做成“好用、可维护”
- 12. 一个可直接套用的 Skill 示例(简化版)
- 13. 结语:Skills 真正改变的是“协作方式”
Pre
LLM - 从 0 打造专业 Agent Skill:一套能落地的完整实践指南
1. 引言:为什么突然都在聊 Skills?
过去一年,大家折腾 MCP(Model Context Protocol)更多:把模型连上你的工具、数据源、业务系统,能查、能写、能改,听起来很强。
但很多团队很快会撞到同一个墙:“连上了,然后呢?” —— 工具是通了,流程却没固化,产出时好时坏,用户也不知道下一步该怎么用。
Skills 要解决的就是这件事:把一段“靠谱的做事方法”打包成可复用的工作流,让 Claude 每次都按同一套步骤做事,减少重复解释、减少误用工具、提升结果一致性。
你可以把 Skills 理解成:给 AI 写一份交接文档。你教它一次,以后团队反复用。
2. Skills 是什么:不只是提示词,而是“流程+标准+检查”
Skills 就是一套打包好的指令,用来教会 Claude 如何处理你的特定工作流程。
它的核心价值体现在三点:
- 不用每次对话都从头解释背景、步骤和规范,只要说目标就能启动流程。
- 工具调用能按既定步骤执行,不需要人一步步带着点。
- 输出更稳定,团队协作成本更低(一次配置,多人共享)。
3. Skills 长什么样:一个文件夹 + 一个 SKILL.md
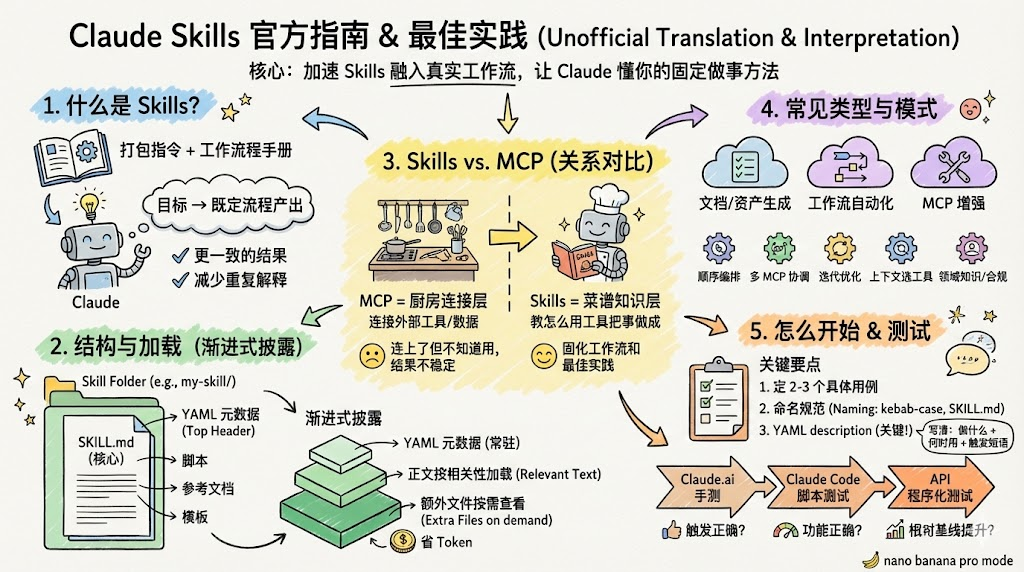
从技术形态看,Skills 就是一个文件夹,核心文件必须叫 SKILL.md(Markdown),顶部是 YAML 元数据;你还可以放脚本、参考文档、模板素材等。
典型结构
your-skill-name/
├── SKILL.md # 必需 - 主要的 Skill 文件
├── scripts/ # 可选 - 可执行代码
├── references/ # 可选 - 参考文档
└── assets/ # 可选 - 模板、字体、图标
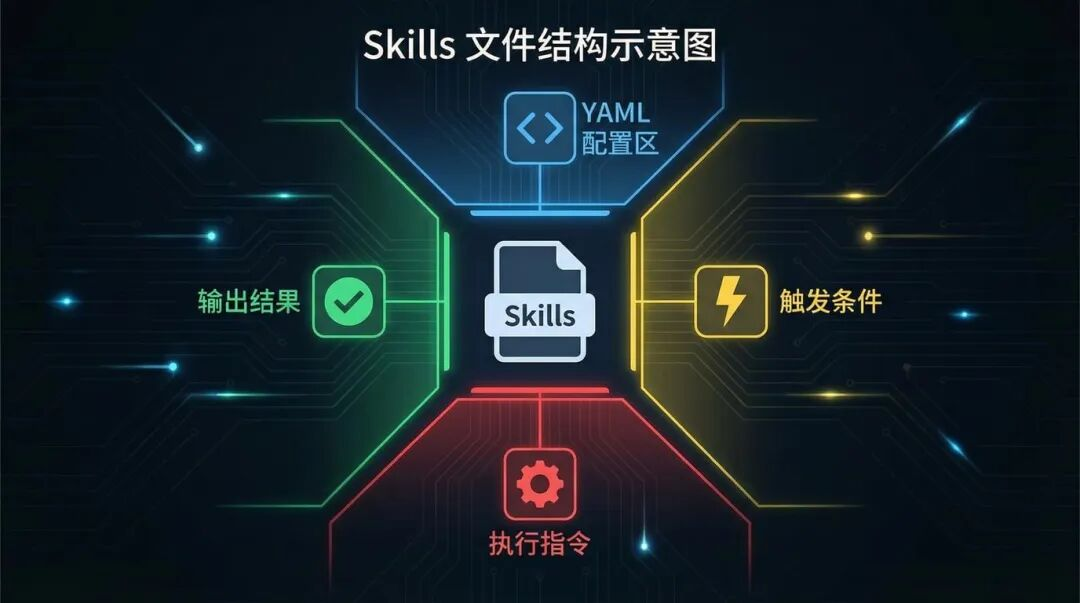
3.1 渐进式披露:省 token、也更“像个产品”
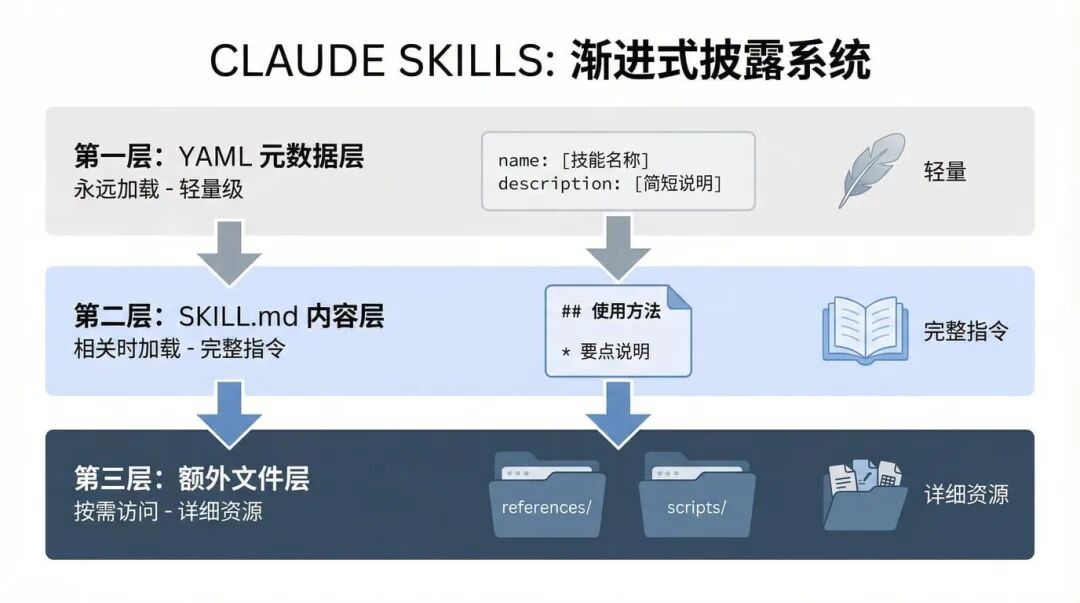
渐进式披露(分三层加载):
- 第一层:YAML 元数据,始终在系统提示中(占用少,但决定“何时触发”)。
- 第二层:
SKILL.md正文,在 Claude 判断相关时加载(提供完整步骤与规范)。 - 第三层:额外文件(references/assets 等),按需查看(放详细文档、长清单、规范)。
直观好处是:不把所有东西一次性塞进上下文,响应更快、成本更低,同时在需要的时候又能拉起足够的专业细节。
3.2 可组合性:多个 Skill 可以一起工作
Skills 具有可组合性:Claude 可以同时加载多个 Skills,让它们协同工作;并且同一套 Skills 能在 Claude.ai、Claude Code 和 API 上使用,做到“一次创建,多处运行”。
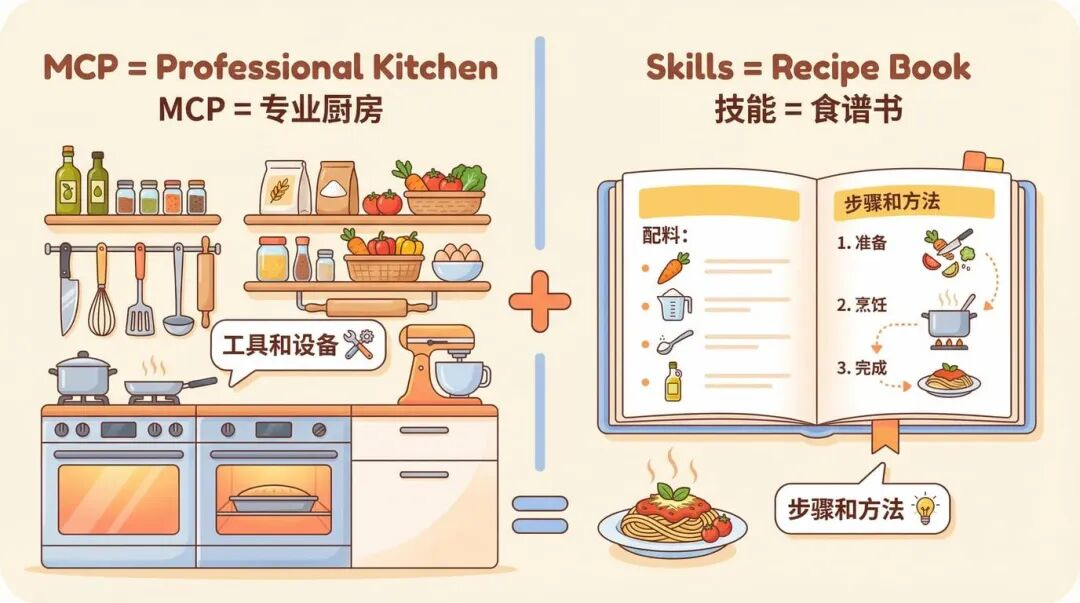
4. Skills 和 MCP:厨房和菜谱,缺一不可
- MCP 是“专业厨房”,负责把 Claude 接到你的服务和实时数据上(工具、食材、设备)。
- Skills 是“菜谱”,负责告诉 Claude 具体怎么用这些工具,把事一步步做成。
“只做 MCP 连接、没有 Skills”常见的失败症状:
- 用户连上服务,但不知道下一步做什么。
- 每次对话从零开始,结果不一致。
- 用户以为“连接器不好用”,其实缺的是工作流指导。
- 支持工单反复问“怎么用你们的集成做 X”。
加上 Skills 之后,工作流能自动激活,工具使用更一致,最佳实践变成每次交互的一部分。
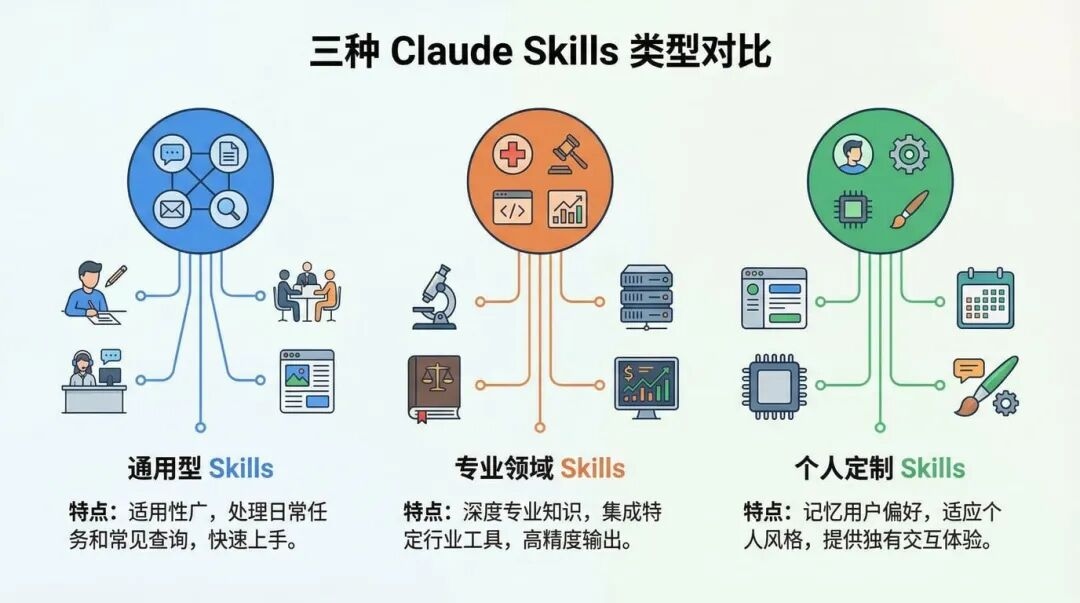
5. 三种常见 Skill:从“写文档”到“多工具编排”
Skills 的使用场景归成三类,典型示例:
-
文档和资产创建
用于生成一致的高质量输出(文档、演示、设计交付物、代码骨架等),通常内嵌风格指南、模板结构、质量检查清单;强调不一定需要 MCP,更多依赖模型能力本身。 -
工作流自动化
适合多步骤、重复性高、方法论固定的流程(发布流程、客户入职、代码审查、项目规划等),可以包含验证关卡、迭代优化循环,也可以跨多个 MCP 服务器协调。 -
MCP 增强
专门为某个 MCP 工具提供“怎么用”的指导:按顺序协调多个 MCP 调用,嵌入领域知识,把用户原本要手动补充的上下文提前固化进去。
6. 从 0 到 1:写一个能触发、能跑通、能复用的 Skill
这一部分是全篇最“可落地”的内容:怎么选场景、怎么命名、YAML 怎么写、正文怎么写、怎么测、怎么迭代。
6.1 先别急着写:先定 2–3 个具体用例
写任何代码前,先明确 2 到 3 个具体使用场景,并写清三件事:触发条件、步骤、预期结果。
它给了一个“项目冲刺规划”的用例示例,包括:用户触发语、通过 MCP 获取 Linear 状态、分析容量、建议优先级、创建任务等步骤,以及最后要产出的结果。
这一步做不好,后面 YAML 和正文就会变成“万能提示词”,看似能用,实际不稳定。
6.2 命名规则:看起来“强迫症”,但很要命
- 文件夹名用小写加短横线(kebab-case),例如
notion-project-setup。 - 主文件必须叫
SKILL.md(大小写敏感)。 - 不要在 Skill 文件夹里放
README.md。
这是系统识别 Skill 的关键,写错 Claude 可能就找不到它。
6.3 YAML 元数据:最关键的是 description
YAML 元数据决定 Claude 是否会加载你的 Skill;最简格式只需要 name 和 description。
其中 description 是黄金字段,它要同时回答两个问题:
- 这个 Skill 做什么?
- 用户什么时候会需要它(也就是触发语和场景)?
description 的规则:
- 要写“做什么 + 什么时候用”。
- 少于 1024 字符。
- 包含用户可能说的具体任务短语。
- 涉及文件类型要提到(比如上传 .fig 文件)。
- 不能包含 XML 标签(
< >)。
我的建议:可以把 description 当成一条检索 Query 来写,越像用户的真实说法越好,比如“写周报/生成周报/本周总结”。站在用户角度写触发词,越具体越准确。
6.4 SKILL.md 正文:把“口头提示”写成可执行手册
- Skill 名称
- 指令部分(分步骤)
- 示例(常见场景、预期结果)
- 故障排除(常见错误、解决方案)
好指令要写到“可执行”的程度,例如给出确切命令和参数,而不是一句“验证数据”。
同样,错误处理也要具体到“看到某报错时按 1、2、3 做什么”。
三条写指令的原则:
- 具体可执行:给出确切命令与参数。
- 包含错误处理:提前覆盖常见问题。
- 用渐进式披露:核心放 SKILL.md,细节放 references/。
还有一句很“像写给同事交接”的提醒:别假设对方应该知道,要手把手写清楚,才能让 Claude 更独立工作,不反复打断你问问题。
7. 测试与迭代:别只看“能不能跑”,要看“比之前强多少”
- Claude.ai 手动测试:快,但不可重复、难规模化。
- Claude Code 脚本测试:可重复、偏团队协作,但要写脚本。
- API 程序化测试:最系统、可量化,适合生产,但成本和设置更高。
7.1 官方推荐的迭代节奏:先攻克最难的一个任务
先在单个挑战性任务上迭代到成功,再把成功的方法提取成 Skill;这比一开始就做大而全的覆盖更快拿到反馈。
7.2 三个关键测试维度
三维测试框架:
- 触发测试:该触发时自动加载,不该触发时别乱跳出来。
- 功能测试:输出是否正确、API 调用是否成功、错误处理是否有效、边缘情况是否覆盖。
- 性能比较:要证明 Skill 相比“没有 Skill 的基线”确实更好,比如来回消息数、API 失败次数、token 消耗、用户干预次数。
8. 快速上手:用 skill-creator 先生成一个可用骨架
skill-creator:如果你已经有 MCP 服务器,并且明确了前 2–3 个工作流,通常可以在 15–30 分钟内构建并测试一个功能性 Skill。
它给的用法很直接:对 Claude 说“使用 skill-creator 帮我构建一个 [你的用例] 的 Skill”,它会一步步追问触发方式、步骤、结果,然后生成基础版本供你微调。
对于新手,这个路径很合理:先有一个“能跑通的骨架”,再按你团队的真实流程补细节。
9. 常见坑:为什么不触发、为什么乱触发、为什么不听话?
- 不触发:description 太泛;解决思路是补具体触发短语与场景。
- 触发太频繁:范围没定义清;网页建议加负面触发条件、缩小适用范围。
- MCP 调用失败:连接/认证/权限/工具名问题;网页给了检查项,比如服务器状态、API 密钥、独立测试 MCP 调用等。
- 指令不被遵循:指令太冗长或模糊;解决思路是结构化、突出关键步骤、把细节迁移到 references/,并提供明确命令参数。
对关键验证尽量用脚本做程序化检查,不要只靠语言指令,因为代码是确定性的,要么通过要么报错。
10. 分发与使用:个人、团队、企业、API 各有一套玩法
- 个人:下载文件夹 → 压 zip → 上传到 Claude.ai。
- 团队:放到 Claude Code 的技能目录,用 Git 同步更新。
- 企业:管理员在工作区范围部署,集中管理和更新。
- 程序化:通过 API 管理和调用,配合版本控制与自动化管道。
Anthropic 的一个承诺:Skills 作为开放标准发布(类似 MCP),强调跨平台可移植性——同样的 Skill 不应只绑定在某个平台上。
在 API 侧,关键能力点:/v1/skills 端点用于列出和管理 Skills;通过 container.skills 参数把 Skills 加到 Messages API 请求;通过 Console 做版本控制,并可与 Claude Agent SDK 结合构建自定义代理。
11. 五种设计模式:把“能用”做成“好用、可维护”
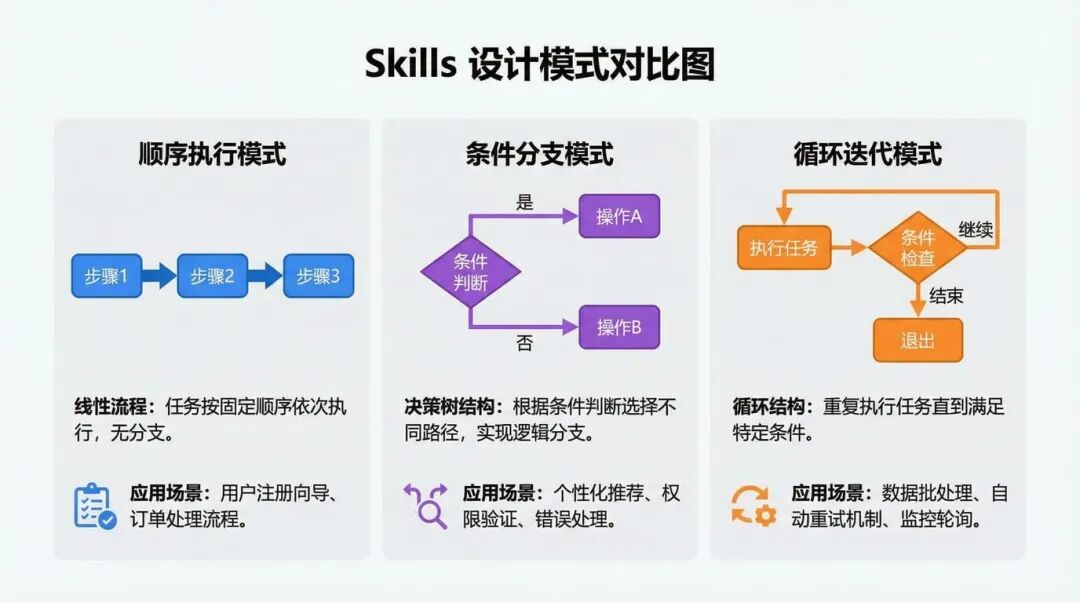
5 种常见且有效的 Skill 设计模式
- 顺序工作流编排:多步骤强依赖,强调验证与回滚。
- 多 MCP 协调:跨多个服务,阶段分离、数据传递、集中错误处理。
- 迭代优化:初稿→检查→改进→再检查,强调质量标准、验证脚本和停止条件。
- 上下文感知工具选择:同一目标不同工具,强调决策标准、fallback、对用户解释原因。
- 领域特定智能:把领域知识与合规检查“写进流程”,强调审计与治理。
其中我最想提醒的是第 3 点“停止条件”:要知道何时停止迭代,避免无限循环。
这在报告生成、代码重构、文档润色这类任务里特别重要,否则模型会一直“还能更好”。
12. 一个可直接套用的 Skill 示例(简化版)
把一个“代码评审 + 质量门禁”的 Skill 骨架写出来(你可以按自己环境替换工具名/命令)。这个示例重点是结构和写法,不依赖具体厂商。
文件夹:
pr-review-gate/
主文件:SKILL.md(必须全大写)
***
name: pr-review-gate
description: 对 GitHub Pull Request 做代码评审与质量门禁。当用户说“帮我审这个 PR”“代码评审”“检查这次提交风险”“给出修改建议”时使用。
***
# PR Review Gate
# 目标
在尽量少的来回沟通下,给出可执行的评审结论:问题清单、风险分级、修改建议、必要时给出可直接复制的补丁片段。
# 工作流程(按顺序执行)
1. 获取 PR 基本信息:标题、描述、变更文件列表、主要 diff。
2. 做静态检查:代码风格、可读性、重复逻辑、潜在异常。
3. 做风险检查:权限/鉴权、敏感信息、输入校验、日志泄露。
4. 生成结论:必须改 / 建议改 / 可不改;给出修改位置与理由。
5. 若用户同意修复:输出一个“最小改动”的修复方案,并说明验证方法。
# 质量门禁(必须满足)
- 结论必须包含:风险分级、影响范围、修复优先级。
- 建议必须“能落地”:指出具体文件/函数/逻辑块,而不是泛泛而谈。
- 如果缺上下文:先问 1-3 个关键问题再继续,不要猜。
# 常见问题
- 如果无法获取 diff:提示用户提供 PR 链接或贴出关键 diff。
- 如果评审范围过大:优先评审高风险模块(鉴权、支付、数据写入、外部调用)。
你会发现,这个写法基本就是“写给同事的操作手册”:步骤具体、质量标准明确、遇到缺信息先问关键问题,而不是硬猜。
13. 结语:Skills 真正改变的是“协作方式”
Skills 表面是个新功能,本质是在改变我们和 AI 的协作方式——从“我说一句你做一下”,变成“我教你一次你反复复用”。
如果你已经在做 MCP/Agent/企业集成,我建议把 Skills 当成产品的一部分来设计:连接层(MCP)+ 方法论层(Skills) 一起交付,用户体验会完全不一样。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)