云原生安全: AI 在容器环境异常调用检测中的应用
IP 地址是动态的,容器的生命周期可能只有几分钟,传统的防火墙和基于签名的杀毒软件完全失效。如果一个平时只被“日志服务”访问的“数据库节点”,突然被一个“前端节点”连接了,且这个“前端节点”刚才发生了 Syscall 异常,那么 GNN 会通过消息传递机制(Message Passing),瞬间将这两个节点的风险值(Risk Score)拉满。在前面的章节中,我们要么是在对抗外部的流量攻击(WAF
云原生安全: AI 在容器环境异常调用检测中的应用
你好,我是陈涉川,欢迎来到我的专栏。在前面的章节中,我们要么是在对抗外部的流量攻击(WAF、IDS),要么是在对抗静态的代码漏洞(SAST/DAST),或者是构建蜜罐欺骗黑客。然而,随着企业数字化转型的深入,应用架构发生了翻天覆地的变化。
单体应用被打散成了数千个微服务,运行在 Docker 容器中,由 Kubernetes 编排。在这个**云原生(Cloud Native)**的世界里,传统的安全边界消失了。IP 地址是动态的,容器的生命周期可能只有几分钟,传统的防火墙和基于签名的杀毒软件完全失效。
本章将带你进入**内核态(Kernel Space)**的深处。我们将探讨如何利用 eBPF 技术捕获容器的每一次呼吸(系统调用),并利用 深度学习(Deep Learning) 识别出那些混杂在海量正常业务中的微小异常——那是黑客正在通过 Shell 逃逸的信号。
引言:消失的边界与“薛定谔”的容器
2018 年,某知名车企的 Kubernetes 集群被入侵,黑客利用未授权访问的 Dashboard 部署了挖矿容器。直到数月后,云账单暴涨才暴露了此次攻击。
这不是个例。云原生环境的复杂性为攻击者提供了完美的掩护。
在传统的虚拟机(VM)时代,服务器是“宠物(Pets)”,我们给它起名字,精心维护,装上安全代理(Agent),配置好 iptables。
在云原生时代,容器是“牲畜(Cattle)”。它们朝生暮死,不可变(Immutable),且数量庞大。一个典型的微服务集群可能每秒钟都有几十个容器在创建和销毁。
安全挑战的质变:
- 短命性(Ephemerality): 攻击者可能启动一个容器,运行恶意脚本,然后在 30 秒内销毁容器。当安全团队第二天来排查时,现场早已消失,日志可能也随之丢失。
- 东西向流量(East-West Traffic): 传统防火墙守卫的是南北向(互联网到内网)。但在 K8s 集群内部,服务之间的调用极其复杂,黑客一旦突破边界,就可以在内网无阻碍地横向移动。
- 共享内核风险: 容器不是 VM,它们共享宿主机的 Linux 内核。一旦发生容器逃逸(Container Escape),黑客就拥有了宿主机的控制权,进而控制整个节点。
面对这种环境,基于规则的防御(如 AppArmor, Seccomp)虽然有效,但维护成本极高。我们需要一种自适应的、基于行为的 AI 系统,它能理解:“什么是这个微服务的正常行为?” 并在出现偏差的毫秒级内发出告警。
第一章:云原生环境下的数据源革命——从日志到 eBPF
要训练 AI,首先需要数据。在容器环境中,传统的日志(Logs)已经不够用了。我们需要更底层、更精细的“听诊器”。
1.1 传统监控的局限
- 应用日志(Application Logs): 开发人员写的日志格式不统一,且黑客一旦拿到 Shell,第一件事就是清空 /var/log。
- 审计日志(Auditd): Linux 自带的审计系统。功能强大,但性能开销巨大。在高并发的容器环境中开启 Auditd,可能会导致服务器性能下降 20%-30%,这是业务方无法接受的。
- Sidecar 模式(边车): 在每个 Pod 里注入一个安全容器。虽然隔离性好,但资源消耗成倍增加,且增加了网络延迟。
1.2 eBPF:Linux 内核的可编程神经系统
eBPF (Extended Berkeley Packet Filter) 是近年来 Linux 内核最革命性的技术,被誉为“内核的可编程 JavaScript”。
- 原理: 它允许我们在不修改内核源码、不重新编译内核的情况下,插入一段沙箱代码(Bytecode),并由 JIT 编译器转换为原生机器码执行。
- 安全性: eBPF 代码在执行前必须通过**验证器(Verifier)**的检查,确保它不会导致死循环或内核崩溃。
- 零侵入(Zero Instrumentation): 我们不需要重启应用,不需要修改业务代码,就能监控任何一个系统调用(Syscall)、网络包或函数调用。
为什么 eBPF 是 AI 的最佳搭档?
因为 AI 需要结构化、高保真、低底噪的数据。
eBPF 可以直接从内核结构体(task_struct, sk_buff)中提取数据,它看到的不仅仅是“发生了一个写操作”,而是:
“PID 为 3456 的进程(属于容器 nginx-frontend),调用了 sys_openat,试图以 O_WRONLY 模式打开 /etc/passwd,其父进程是 bash。”
这种带有**上下文(Context-aware)**的数据,是训练异常检测模型的完美燃料。
1.3 数据采集架构设计
我们将构建一个基于 eBPF 的遥测系统:
- 内核探针(Kprobes/Tracepoints):
- 挂载点:sys_enter(系统调用入口)、sys_exit(系统调用出口)、tcp_connect、process_execution。
- eBPF Map: 内核态的高效哈希表,用于暂存采集到的数据,供用户态程序读取。
- 元数据富化(Metadata Enrichment):
- eBPF 只能拿到 PID(进程ID)。
- 用户态 Agent 需要查询 Kubernetes API Server 或 Docker Daemon,将 PID 映射到 Pod Name, Namespace, Container Image ID, Service Label。
- 这一点至关重要:AI 模型不关心 PID 12345 做了什么,它关心的是“支付服务(Payment Service)”做了什么。
- 开源实践参考: 业界成熟的开源项目如 Cilium Tetragon 正是采用了这种 eBPF 感知 Kubernetes 元数据的架构。它不仅能捕获系统调用,还能自动关联 Pod 名称、Namespace 甚至 Service Identity,极大地降低了数据清洗的门槛。
第二章:系统调用(Syscall)——进程的行为指纹
在 Linux 世界里,一切皆文件,而操作这些文件的唯一合法途径就是系统调用。
无论你是用 Java, Python, Go 还是 C++ 写的程序,最终都要转化为内核能理解的 Syscall。
2.1 Syscall 的语言学特征
如果我们把一个进程看作是在“说话”,那么 Syscall 就是它的“单词”。
- open = 打开
- read = 读取
- write = 写作
- socket = 建立连接
- execve = 执行程序
一个正常的 Web 服务器(如 Nginx)的“语言”是单调且重复的:
epoll_wait -> accept -> read -> open -> sendfile -> write -> close
(等待连接 -> 接收请求 -> 读取请求 -> 打开静态文件 -> 发送文件 -> 写入日志 -> 关闭连接)
而一个被植入 Webshell 的 Nginx,它的“语言”会突然出现异类:
... -> read -> execve("/bin/sh") -> pipe -> dup2 -> connect -> ...
(... -> 读取攻击载荷 -> 执行 Shell -> 建立管道 -> 重定向输入输出 -> 反弹连接)
2.2 序列数据的 AI 建模
这听起来像什么?这正是 自然语言处理(NLP) 解决的问题!
我们可以将 Syscall 序列视为文本句子,利用 NLP 模型来学习进程的“语法”。
数据预处理:
- 词表构建(Vocabulary): Linux x86-64 架构下约有 300+ 个系统调用。我们将每个 Syscall ID 映射为一个 Token。
- 序列切分(Windowing): 将连续的 Syscall 流切分为固定长度的滑动窗口(例如 Length=20)。
- Sequence A: [read, write, open, close, ...]
- 参数嵌入(Argument Embedding):
- 仅仅知道调用了 open 是不够的。打开 /var/www/html/index.html 是正常的,打开 /etc/shadow 是异常的。
- 我们需要对关键参数(如文件路径、网络端口)进行 Hash 或 Embedding 处理,作为辅助特征输入模型。
第三章:无监督学习——在没有黑样本的世界里
在实际生产环境中,我们面临一个棘手的问题:样本极其不平衡。
- 99.999% 的流量是正常的业务流量。
- 真正的攻击样本极少,且攻击手法千变万化(0-Day)。
因此,传统的监督学习(Supervised Learning,训练分类器区分黑白)在这里行不通。我们需要无监督学习(Unsupervised Learning)或自监督学习(Self-Supervised Learning)。
我们的核心假设是:攻击行为在统计上属于小概率的异常事件。
3.1 自动编码器(Autoencoder, AE)
这是异常检测领域的“瑞士军刀”。
原理:
Autoencoder 是一个神经网络,它试图学习一个恒等函数 f(x) ≈ x。
它由两部分组成:
- 编码器(Encoder): 将高维输入 x(Syscall 序列)压缩为低维的隐变量 z(Latent Vector)。
z = σ(Wx + b)
- 解码器(Decoder): 试图从 z 重构出原始输入 x'。
x' = σ'(W'z + b')
如何检测异常?
- 训练阶段: 我们只使用正常的业务流量训练 AE。模型会被迫学习正常行为的“压缩表示”和“解压规律”。
- 推理阶段:
- 当正常的 Syscall 序列输入时,模型能很好地还原,重构误差(Reconstruction Error) 很小。
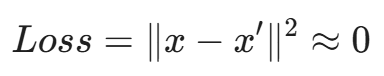
-
- 当异常的攻击序列(如 Webshell 行为)输入时,因为模型从未见过这种模式,且经过了低维压缩,解码器无法正确还原,重构误差 会非常大。
- 我们设定一个阈值 \theta,当 Loss > \theta 时,判定为异常。
3.2 LSTM-Autoencoder:捕捉时间依赖性
普通的 AE 只能处理定长向量,忽略了 Syscall 的先后顺序(时序性)。
open -> write 和 write -> open 的含义完全不同。
我们需要将 LSTM(长短期记忆网络)引入 AE 结构中。
- Encoder: 是一个 LSTM 网络,读取整个序列,将最后时刻的隐藏状态 h_T 作为序列的压缩表示。
- Decoder: 也是一个 LSTM 网络,利用 h_T 逐步预测重构序列。
模型公式:
给定序列 X = {x_1, x_2, ..., x_T}
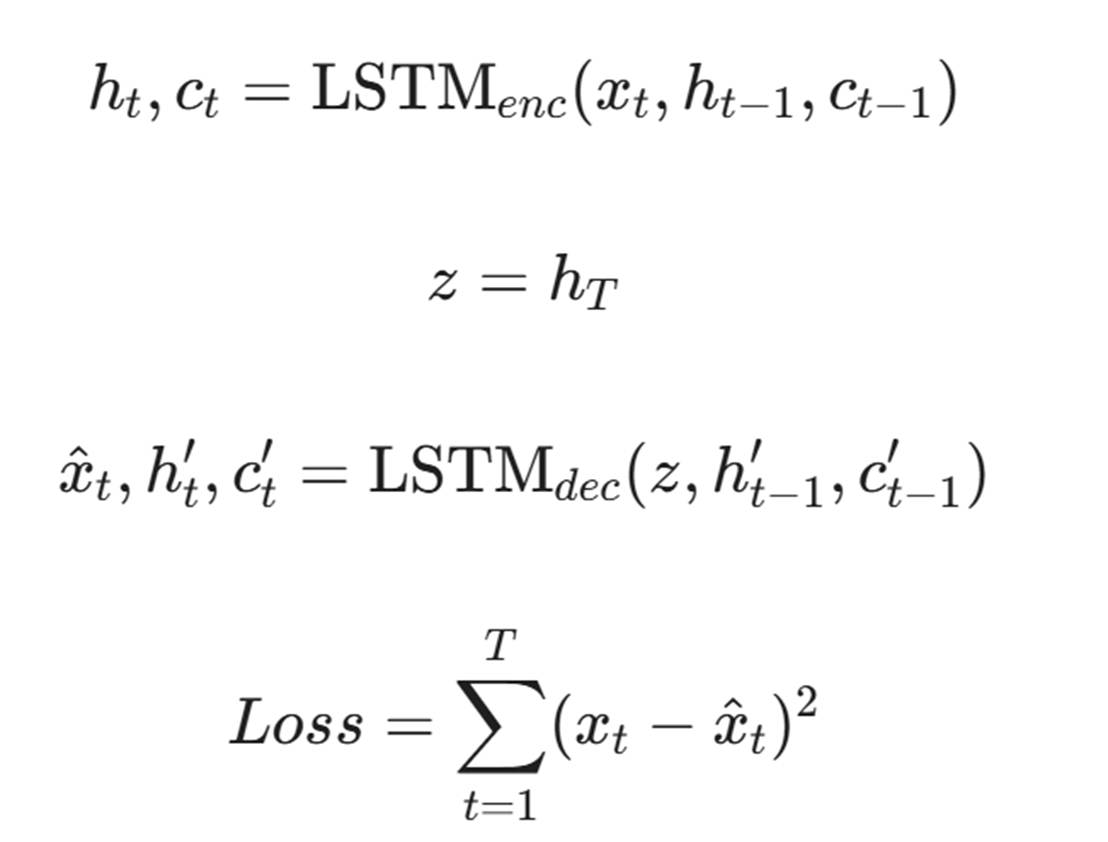
这种模型能极其敏感地捕捉到执行流的异常跳转。
第四章:VAE 与生成式模型的进阶应用
虽然 Autoencoder 效果不错,但它的隐空间(Latent Space)是不连续的。为了更鲁棒的检测,我们引入 变分自编码器(Variational Autoencoder, VAE)。
4.1 概率分布建模
VAE 不直接学习隐变量 z,而是学习 z 的概率分布(通常假设为高斯分布 N(\mu, σ^2))。
优势:
- 它不仅能给出“是否异常”,还能给出“异常的概率置信度”。
- 它允许我们对正常行为的多样性进行建模。例如,一个微服务在启动阶段和运行阶段的行为差异很大,VAE 可以学习到一个混合高斯分布来覆盖这两种模式。
ELBO 损失函数:
VAE 的训练目标是最大化证据下界(ELBO):
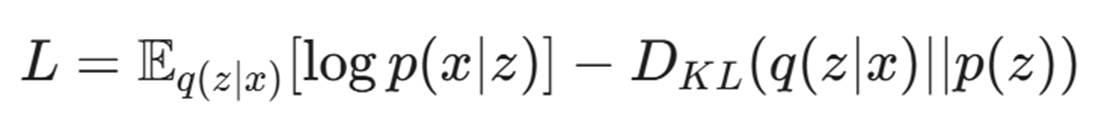
- 第一项:重构误差(类似于 AE)。
- 第二项:KL 散度(Kullback-Leibler Divergence),强制学习到的分布 q(z|x) 接近标准正态分布 p(z)。
如果某个 Syscall 序列导致的 KL 散度极高,说明该样本在概率空间中距离“正常簇”非常远,这往往意味着严重的未知威胁。
第五章:技术实战——构建基于 Syscall 的异常检测引擎
让我们离开公式,进入代码世界。我们将使用 Python (PyTorch) 和 BPF (BCC) 来实现一个原型。
5.1 Step 1: eBPF 数据采集 (C + Python/BCC)
首先,我们需要一段运行在内核里的 C 代码来捕获 sys_enter 事件。
// syscall_monitor.c
#include <uapi/linux/ptrace.h>
#include <linux/sched.h>
struct data_t {
u32 pid;
u32 uid;
u32 syscall_id;
char comm[TASK_COMM_LEN];
};
// 定义一个 Perf Ring Buffer 用于传输数据到用户态
BPF_PERF_OUTPUT(events);
// 挂载到 tracepoint:raw_syscalls:sys_enter
int trace_syscall(struct tracepoint__raw_syscalls__sys_enter *args) {
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid();
data.syscall_id = args->id;
bpf_get_current_comm(&data.comm, sizeof(data.comm));
// 过滤掉系统本身的噪音进程 (简单的过滤示例)
if (data.pid != 0) {
events.perf_submit(args, &data, sizeof(data));
}
return 0;
}Python 加载端:
from bcc import BPF
# 加载 eBPF 程序
b = BPF(src_file="syscall_monitor.c")
# 挂载 Tracepoint
b.attach_tracepoint(tp="raw_syscalls:sys_enter", fn_name="trace_syscall")
print("Monitoring syscalls... Ctrl+C to stop.")
def print_event(cpu, data, size):
event = b["events"].event(data)
print(f"PID: {event.pid}, Comm: {event.comm}, SyscallID: {event.syscall_id}")
# 这里应该将数据写入 Kafka 或文件,供 AI 模型训练
save_to_dataset(event.syscall_id)
# 循环读取
b["events"].open_perf_buffer(print_event)
while True:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
5.2 Step 2: 模型构建 (PyTorch LSTM-AE)
import torch
import torch.nn as nn
class SyscallLSTMAutoencoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(SyscallLSTMAutoencoder, self).__init__()
# Embedding 层:将 Syscall ID (0-300) 转换为向量
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# Encoder
self.encoder = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_dim,
batch_first=True
)
# Decoder
# 注意:Decoder 的输入来自于 Encoder 的隐藏状态 (hidden_dim),而非原始 Embedding
self.decoder = nn.LSTM(
input_size=hidden_dim,
hidden_size=hidden_dim,
batch_first=True
)
# Output mapping: 将解码器的输出映射回 Syscall ID 空间
self.linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
# x shape: [batch_size, seq_len]
embedded = self.embedding(x)
# Encoding
# output shape: [batch, seq, hidden]
# hidden shape: [num_layers, batch, hidden] -> 这里的 num_layers=1
_, (hidden, cell) = self.encoder(embedded)
# Decoding
# 我们使用 Encoder 最后的隐藏状态作为 Decoder 每一步的输入
# hidden[-1] shape: [batch, hidden]
# 扩展维度以匹配序列长度: [batch, 1, hidden] -> [batch, seq_len, hidden]
decoder_input = hidden[-1].unsqueeze(1).repeat(1, x.size(1), 1)
decoded, _ = self.decoder(decoder_input)
output = self.linear(decoded)
return output # Logits
# 训练参数配置
vocab_size = 350 # Linux Syscall 总数
embedding_dim = 64
hidden_dim = 128
model = SyscallLSTMAutoencoder(vocab_size, embedding_dim, hidden_dim)
criterion = nn.CrossEntropyLoss()
# 确保使用 parameters() 方法
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环示例 (伪代码)
# for batch in normal_traffic_loader:
# # output shape: [batch, seq, vocab_size]
# output = model(batch)
# # Flatten data for CrossEntropy: [batch*seq, vocab_size] vs [batch*seq]
# loss = criterion(output.view(-1, vocab_size), batch.view(-1))
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()5.3 Step 3: 阈值设定与漂移适应
模型训练好后,最大的挑战是概念漂移(Concept Drift)。
当应用发布新版本(Rolling Update)时,它的行为模式自然会改变。如果 AI 不更新,就会产生大量误报。
自适应策略:
- 金丝雀发布监控: 当 K8s 进行金丝雀发布(Canary Deployment)时,自动启动一个新的“影子模型(Shadow Model)”在金丝雀 Pod 上进行在线学习(Online Learning)。
- 基线动态调整: 不使用固定的 Loss 阈值,而是使用基于统计学的动态阈值(例如:过去 1 小时 Loss 均值 + 3倍标准差)。
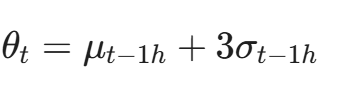
第六章:深入对抗——AI 如何应对“模拟正常行为”的攻击?
黑客也懂 AI。如果攻击者知道你在用 Syscall 序列检测,他会尝试 Mimicry Attack(拟态攻击)。
比如,他想执行 execve,但他不直接调用,而是通过插入大量的无意义 read/write(垃圾操作)来稀释攻击序列,试图让 Loss 降低。
6.1 频率分析与 TF-IDF
简单的 LSTM 可能被长序列的垃圾操作糊弄。我们可以引入 NLP 中的 TF-IDF(词频-逆文档频率) 思想。
- read, write, clock_gettime 这种 Syscall 到处都是,权重(IDF)应该很低。
- ptrace, mprotect, execve 这种 Syscall 很少见,权重应该极高。
在计算 Loss 时,引入加权机制:
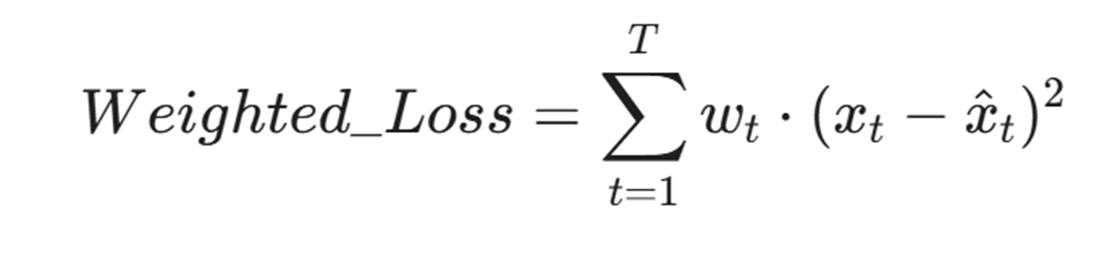
其中 w_t 是该 Syscall 的风险权重。这样,哪怕黑客只插入了一个危险调用,整个序列的 Loss 也会瞬间飙升。
6.2 Skip-Gram 与 N-Gram 的结合
为了防止黑客通过改变时序来绕过 LSTM,我们可以同时运行一个轻量级的 N-Gram 概率模型。
N-Gram 关注的是局部共现概率:
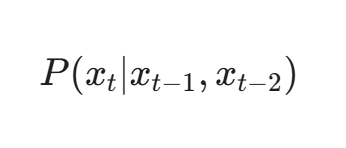
如果黑客强行插入垃圾 Syscall,势必会打破原本紧密的局部调用关系(例如 socket 后面通常紧跟 connect,如果中间插了 10 个 getpid,N-Gram 模型会立刻报警)。
第七章:服务网格(Service Mesh)与 API 流量的语义理解
如果说 eBPF 监控的是“肌肉动作”(系统调用),那么 Service Mesh(如 Istio, Linkerd)监控的就是“语言交流”(HTTP/gRPC 请求)。在 OSI 模型中,我们从 L4 升级到了 L7。
7.1 微服务间的“巴别塔”
在 K8s 集群中,服务 A 调用服务 B 的 API 是常态。传统的 WAF 很难部署在东西向流量(East-West Traffic)中,因为流量太大了。
黑客利用这一点,通过 BOLA (Broken Object Level Authorization) 漏洞进行攻击:
- 正常请求:GET /api/v1/orders/12345 (用户 A 查看自己的订单)
- 攻击请求:GET /api/v1/orders/12346 (用户 A 尝试查看别人的订单)
从 HTTP 协议看,这两个请求都是合法的(200 OK),格式也完全一样。基于规则的 WAF 无法区分。但 AI 可以理解上下文。
7.2 基于 BERT 的 API 异常检测
我们可以借鉴 NLP 中的 BERT (Bidirectional Encoder Representations from Transformers) 模型来理解 API 流量。
- URL Tokenization:
将 URL 切分为 Token 序列。
/api/v1/orders/12345 -> ['api', 'v1', 'orders', '<UUID>']
- 流量模式学习:
模型学习到 orders 后面通常跟着一个 UUID。如果在某个时刻,orders 后面跟着一段 SQL 注入代码 ' OR 1=1 --,或者跟着一个极其长的不规则字符串,BERT 的 Attention 机制会立即捕捉到这种“语义违和感”。
- 用户行为画像(UEBA for Services):
AI 还会学习调用链的逻辑。
-
- 正常路径: Auth-Service -> Token -> Order-Service
- 异常路径: 直接访问 Order-Service 而没有携带 Auth-Service 颁发的 Token(即使 Token 格式是对的,但来源 IP 不对)。
7.3 无代理(Sidecar-less)检测趋势
传统的 Service Mesh 依赖 Sidecar 代理,资源消耗大。
结合 eBPF,我们可以在内核层直接解析 HTTP/2 协议头,将 API 请求元数据发送给 AI 引擎,而无需在每个 Pod 里插一个 Sidecar。这是 Cilium Service Mesh 等 eBPF 原生网格的核心优势,或者是 Istio Ambient Mesh 试图通过共享代理来解决的问题。
第八章:图神经网络(GNN)——捕捉横向移动的幽灵
当黑客攻陷了一个前端容器(Frontend),他下一步会做什么?他会扫描内网,寻找数据库(Database)或认证中心(Auth)。
在 K8s 的网络拓扑图中,这表现为一条未曾出现过的边(Unexpected Edge)。
8.1 为什么 CNN/RNN 处理不了拓扑结构?
卷积神经网络(CNN)擅长处理网格数据(图像),RNN 擅长处理序列数据(文本)。但微服务调用关系是一个**非欧几里得结构(Non-Euclidean Structure)**的图(Graph)。
节点(Node)是 Pod,边(Edge)是 TCP 连接。
我们需要 图神经网络(GNN) 来直接在图结构上进行学习。
8.2 动态图嵌入(Dynamic Graph Embedding)
我们构建一个动态图 G_t = (V_t, E_t)。
- V(节点特征):包含 Pod 的静态属性(镜像 ID、开放端口)和动态属性(过去 1 分钟的 CPU/内存负载、Syscall 异常分)。
- E(边特征):包含连接的协议(TCP/UDP)、流量大小、延迟。
为什么要强调“动态”? 容器环境的拓扑是瞬息万变的,静态图无法捕捉这种变化(例如:攻击者可能在 5 秒内完成探测并断开连接)。传统的 GCN 会丢失时间信息,因此我们需要引入 TGN (Temporal Graph Networks) 或在 GNN 中引入时间注意力机制(Time Attention),让模型理解“连接发生的顺序”与“连接的结构”同样重要。
我们使用 GCN (Graph Convolutional Network) 或 GAT (Graph Attention Network) 来聚合邻居节点的信息。
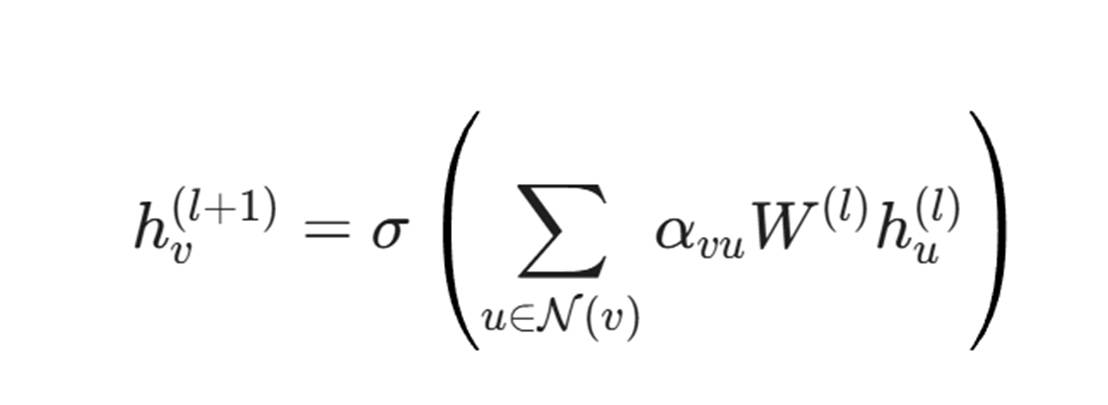
其中 h_v 是节点 v 的特征向量。这意味着,一个节点的状态不仅取决于它自己,还取决于谁在连接它。
如果一个平时只被“日志服务”访问的“数据库节点”,突然被一个“前端节点”连接了,且这个“前端节点”刚才发生了 Syscall 异常,那么 GNN 会通过消息传递机制(Message Passing),瞬间将这两个节点的风险值(Risk Score)拉满。
8.3 链接预测(Link Prediction)作为异常检测
我们可以将横向移动检测转化为一个链接预测问题。
模型的目标是预测两个节点之间存在边的概率 P(u, v)。
- 如果实际网络中出现了一条连接 (u, v)。
- 但 GNN 模型预测 P(u, v) ≈ 0(即这两个服务在逻辑上不应该有交互)。
- 结论: 这是一个非法连接,可能是横向移动或数据泄露。
这种方法比传统的 K8s Network Policy(白名单)更智能,因为它能容忍正常的临时调用(只要符合业务逻辑),但能精准阻断异常的探测行为。
第九章:联邦学习(Federated Learning)——数据孤岛中的协同防御
云原生环境往往涉及混合云(Hybrid Cloud)。银行的核心交易系统在私有云,而前端在公有云。出于合规要求(如 GDPR),私有云的数据(包含客户隐私)绝对不能上传到公有云进行 AI 训练。
但这导致了一个问题:威胁情报无法共享。
9.1 联邦平均算法(FedAvg)
联邦学习允许我们在不交换数据的情况下协同训练一个强大的异常检测模型。
- 初始化: 中央服务器(Global Server)初始化一个全局模型 W_G。
- 分发: 将 W_G 发送给各个边缘集群(Client A, Client B...)。
- 本地训练:
- Client A 使用自己的私有数据训练模型,得到更新梯度 \Delta W_A。
- Client B 使用自己的数据训练,得到 \Delta W_B。
- 加密聚合: 各个 Client 将梯度(而非原始数据)加密上传给中央服务器。
- 全局更新: 中央服务器进行加权平均:
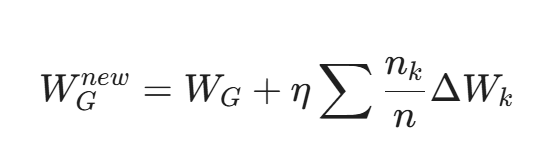
- 迭代: 重复上述步骤。
9.2 免疫系统的“群体智慧”
这就像生物的群体免疫。
如果 Client A(某银行的分支机构)遭受了一种新型的 Container-Escape-v2 攻击,它的本地模型会迅速学习到这种攻击的 Syscall 特征。
在下一轮联邦聚合中,这个特征会被合并到全局模型。
随后,Client B(该银行的另一个分支,甚至完全不同的公司)更新了全局模型。
结果: Client B 虽然从未见过这种攻击,但它已经获得了免疫力。
9.3 对抗“投毒攻击”(Poisoning Attack)
联邦学习面临的最大风险是:如果有恶意的参与者(Client X 被黑客控制),它故意上传错误的梯度,试图破坏全局模型。
我们需要引入 拜占庭容错(Byzantine Robustness) 机制。例如,使用 Krum 聚合算法,而不是简单的平均值,剔除那些与大多数梯度方向偏离过大的“异常梯度”。
第十章:可解释性(XAI)与误报控制——让 SecOps 信任 AI
在安全运营中心(SOC),最怕的不是漏报,而是海量的误报(False Positives)。如果 AI 每天发出 1000 个告警,安全人员会直接把它关掉。
10.1 从“黑盒”到“白盒”:SHAP 值
当 AI 判定某个容器异常时,不能只输出 Score: 0.99。它必须解释 Why。
我们利用 SHAP (SHapley Additive exPlanations) 值来量化每个特征对结果的贡献。
告警详情示例:
Alert: Container payment-service-x8f2 Anomaly Detected.
Confidence: 98%
Reasoning (Top SHAP values):
- Syscall Sequence (+0.6): socket followed by connect to External IP. (该服务平时只连内网)
- Parent Process (+0.2): Process spawned by /bin/dash. (通常是 Java 直接启动)
- Time of Day (+0.1): Activity at 03:00 AM. (平时此时间段无流量)
这种可解释性让分析师能瞬间判断这是误报(比如运维在半夜做手动调试)还是真实攻击。
10.2 人机回环(Human-in-the-Loop)与主动学习
为了降低误报,我们需要建立反馈闭环。
- AI 发出告警。
- 分析师点击“标记为误报(False Positive)”。
- 系统自动将该样本加入“困难样本集(Hard Examples)”。
- 触发 增量学习(Incremental Learning),微调模型权重,确保下次不再对类似的 legitimate pattern 报警。
这种机制让 AI 像一个新入职的初级分析师,随着时间的推移,越来越懂企业的业务习惯。
第十一章:代码实战——构建基于 PyTorch Geometric (PyG) 的横向移动检测
在这一节,我们将演示如何构建一个简单的 GCN 模型,来识别 K8s 集群中的异常连接。
11.1 数据准备:图结构构建
假设我们从 K8s 网络流日志(VPC Flow Logs 或 Cilium Hub)中提取了邻接矩阵。
import torch
from torch_geometric.data import Data
# 1. 定义节点特征 (Node Features)
# 假设有 4 个 Pod,每个 Pod 有 3 个特征: [CPU利用率, 内存利用率, Syscall异常分]
# Pod 0, 1 是正常服务,Pod 2 是被攻陷的跳板机,Pod 3 是数据库
x = torch.tensor([
[0.1, 0.2, 0.0], # Pod 0 (Normal)
[0.2, 0.3, 0.0], # Pod 1 (Normal)
[0.5, 0.6, 0.9], # Pod 2 (Compromised - High Syscall Score)
[0.8, 0.8, 0.0], # Pod 3 (Database)
], dtype=torch.float)
# 2. 定义边 (Edge Index)
# 格式: [Source_Nodes, Target_Nodes]
# 正常连接: 0->1
# 异常连接: 2->3 (跳板机连接数据库)
edge_index = torch.tensor([
[0, 1, 2], # Source
[1, 0, 3] # Target
], dtype=torch.long)
# 3. 定义边的标签 (Edge Labels) 用于训练
# 1 = 正常, 0 = 异常
edge_label = torch.tensor([1, 1, 0], dtype=torch.float)
data = Data(x=x, edge_index=edge_index, y=edge_label)11.2 模型定义:GCN Link Predictor
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class Net(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
# 第一层图卷积
self.conv1 = GCNConv(in_channels, hidden_channels)
# 第二层图卷积
self.conv2 = GCNConv(hidden_channels, out_channels)
def encode(self, x, edge_index):
# 编码器:将节点特征聚合,生成 Embedding
x = self.conv1(x, edge_index)
x = x.relu()
return self.conv2(x, edge_index)
def decode(self, z, edge_label_index):
# 解码器:计算两个节点 Embedding 的点积,作为连接概率
return (z[edge_label_index[0]] * z[edge_label_index[1]]).sum(dim=-1)
def forward(self, x, edge_index, edge_label_index):
z = self.encode(x, edge_index)
return self.decode(z, edge_label_index)
# 初始化模型
model = Net(in_channels=3, hidden_channels=16, out_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)11.3 推理逻辑
# 假设我们在推理阶段,模型已经训练好
model.eval()
with torch.no_grad():
# 获取所有节点的 Embedding
z = model.encode(data.x, data.edge_index)
# 预测 Pod 2 -> Pod 3 的连接概率
# edge_to_check = [2, 3]
prob = (z[2] * z[3]).sum().sigmoid()
print(f"Link Probability (Pod 2 -> Pod 3): {prob.item():.4f}")
if prob < 0.2:
print("ALERT: Anomalous Lateral Movement Detected!")
else:
print("Traffic looks normal.")代码解读
这段代码的核心在于 encode 阶段。当 GCN 计算 Pod 3(数据库)的 Embedding 时,它会聚合邻居的信息。如果它的邻居 Pod 2 具有极高的“Syscall 异常分”(在 Node Feature 中体现),那么 Pod 3 的 Embedding 也会发生偏移,导致它们之间的连接评分变得极低(如果不符合正常拓扑结构)。
这实现了多模态检测:结合了节点内部行为(Syscall)和节点间关系(Topology)。
第十二章:工程化挑战——从 Demo 到生产环境
在 Jupyter Notebook 里跑通模型只是第一步,在每秒数百万请求的生产集群中部署才是挑战。
12.1 推理加速与 Sidecar 优化
- 模型量化(Quantization): 将 FP32 模型权重压缩为 INT8 进行推理,精度损失微乎其微,但推理速度提升 4 倍,内存占用减少 75%。
- ONNX Runtime: 将 PyTorch 模型导出为 ONNX 格式,使用 C++ 运行时在 Sidecar 中加载,避免 Python GIL 的性能瓶颈。
12.2 数据漂移(Concept Drift)的自动化处理
微服务更新频繁。每次新版本上线(Image Tag 变更),Syscall 序列都会变。
策略:CI/CD 集成。
我们在 CI/CD 流水线中加入一个 Profiling Stage。
- 新代码 Commit。
- Jenkins 构建镜像。
- 在测试环境自动运行集成测试。
- 安全 Agent 自动采集此时的 Syscall/流量数据,作为“白基线(White Baseline)”。
- 自动微调模型,随新镜像一起发布。
这样,AI 模型永远与业务代码保持同步,不会因为业务升级而误报。
12.3 资源配额与“断路器”设计 (Resource Quotas & Circuit Breakers) 安全不能以牺牲业务稳定性为代价。在生产环境中部署 AI 模型(尤其是基于 eBPF 的采集端),必须设计严格的熔断机制。
- CPU/Mem 限制(Cgroups): 严格限制 Sidecar 或 Agent 的 CPU 使用率(例如不超过 1 Core 的 10%)。
- 自适应采样(Adaptive Sampling): 当节点负载(Load Average)飙升时,Agent 应自动降级,从“全量采集”切换到“采样模式”或仅监控高危 Syscall,确保业务流量优先通过。
- 用户态推理卸载: 尽量不要在内核态做复杂计算。eBPF 只负责传输数据,复杂的 LSTM 推理应异步发送到专用的 Inference Server 集群处理,而不是在业务节点本地跑大模型。
第十三章:未来展望——自适应免疫系统
我们正在迈向一个自适应免疫系统(Adaptive Immune System)的时代。 未来的云原生安全将不再是“外挂”的防火墙,而是内生于基础设施的生物学特性。
- T细胞容器(Counter-Measure Containers / Quarantine Pods): 当 AI 确认某个 Pod 被感染,它不是简单地杀掉(Kill),而是启动一个特权容器,注入到受害 Pod 的 Namespace 中,冻结其内存,提取现场证据,然后将其隔离到“高危 VLAN”,就像白细胞包裹细菌一样。
- 混沌工程安全(Security Chaos Engineering): 类似于 Netflix 的 Chaos Monkey。我们会有 Security Monkey,随机在集群中模拟攻击(生成异常 Syscall、尝试横向移动),以此来持续训练和验证 AI 防御系统的敏锐度。
结语:从“筑墙”到“免疫”——安全范式的终极重构
云原生浪潮的席卷,标志着基于边界防御(Perimeter Defense)时代的终结。在数万个容器瞬息生灭的数字混沌中,没有任何一堵墙能挡住所有威胁。
但这并非绝境,而是进化的契机。
通过本章的探索,我们见证了一套全新防御体系的诞生:
- eBPF 赋予了我们深入内核的“上帝视角”,让观测不再有盲区;
- LSTM 与 Transformer 让我们听懂了系统调用的微观语言,识别出隐藏在二进制流中的恶意意图;
- GNN 则在宏观层面织起了一张关系大网,让横向移动的攻击者无所遁形;
- 联邦学习 打破了数据孤岛,让防御智慧得以在合规的前提下指数级增长。
这不再是简单的工具堆叠,而是安全理念的质变——我们正在从构建静态的“马奇诺防线”,转向培育一个有生命的**“数字免疫系统”**。就像生物免疫系统一样,它并不追求绝对的无菌环境,而是追求对异常的极致感知、快速响应与自我记忆。
未来的 SecOps 不再是盯着屏幕的人肉运维,而是与智能 Agent 协作的指挥官。当 AI 接管了海量数据的筛选与研判,人类安全专家将回归其真正的价值高地:战略对抗与复杂溯源。
在这场算力与认知的博弈中,如果你掌握了 AI,你就掌握了定义安全新规则的权利。
下期预告:第 26 篇《威胁狩猎: 基于自然语言的交互式威胁查询系统(ChatWithSecurity)》
传统的威胁狩猎(Threat Hunting)需要专家编写复杂的 SPL (Splunk Processing Language) 或 KQL (Kusto Query Language)。
“查找过去 24 小时内所有从非标准端口发起的外联请求,且目标 IP 地理位置为高风险地区的记录。” —— 这句话写成 SQL 可能有 20 行。
AI 正在改变这一切。
在下一篇中,我们将探讨:
- Text-to-SQL/Text-to-SPL: 利用 LLM 将自然语言直接翻译成可执行的查询代码。
- 交互式推理: AI 不仅仅是查数据,它还能帮你分析数据。“这个 IP 看起来很像 APT29 的基础设施,建议你检查一下相关的 DNS 记录。”
- 知识图谱增强: 如何将外部威胁情报(CTI)无缝集成到对话中。
陈涉川
2026年02月10日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)