LoRA 与参数高效微调:低秩适配实战指南
本文介绍了大模型微调的技术要点和参数优化方法。首先说明了项目环境配置,包括镜像设置和关键依赖安装(transformers、peft等)。重点分析了全量微调的计算成本,详细拆解了模型权重、梯度、优化器状态和中间激活值的内存需求。通过数学公式推导了梯度下降原理,解释了优化器(如AdamW)如何通过动量矩和方差矩解决训练中的方向不稳定和参数尺度差异问题。文章为高效微调大模型提供了理论基础和实践指导,特
阅读本文建议使用vscode中的
markdown preview enhanced插件打开
项目启动说明
编辑~/.bashrc引入hf-mirror镜像
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=$HOME/mydata/hf
export HF_DATASETS_CACHE=$HOME/mydata/hf/datasets
编写完成后执行source ~/.bashrc重载文件
注意:Transformers(以下简称 tsfs)必须通过 pip 方式安装。启动包含 tsfs 依赖的脚本时,tsfs 会触发依赖自检并自动下载匹配版本,但该过程会同时引发 uv 的路径依赖校验。由于遵循“就近依赖优先”原则,系统会优先匹配 tsfs 直接关联的 torch 版本,从而导致 pyproject.toml 中预设的 torch 依赖被覆盖失效。为避免此问题,请务必手动执行下述安装步骤。此外,除 tsfs 外的若干依赖项可能与 tsfs 版本存在耦合关系,因此一并纳入以下安装清单中进行统一管理。uv add 会触发uv的依赖路径检查uv pip install 直接安装则不会触发依赖重建
# 另外transformers5和4的api变化有些不同,你可以 transformers==4.57.3指定版本
uv pip install transformers peft datasets bitsandbytes accelerate
- transformers:提供对预训练 (pre-training)模型的访问以及 Trainer API,以简化训练循环。
- peft:包含各种PEFT方法的实现,包括LoRA以及QLoRA所需的配置。
- bitsandbytes:此库是QLoRA的根本,因为它负责处理低级别的量化 (quantization)操作(NF4、双重量化)以及前向和反向传播 (backpropagation)过程中的量化矩阵乘法。安装通常需要特定的CUDA版本。
- accelerate:促进硬件管理(GPU、TPU)和分布式训练设置,简化了在多个设备上运行训练的过程
一.参数效率的必要性
1.1 全量微调的计算成本
- 模型权重( W W W): 参数本身构成了基本的内存需求。对于一个有 N N N个参数的模型,以标准32位浮点精度(FP32)存储它们需要 4 N 4N 4N字节。即使使用FP16或BF16等16位格式的混合精度,仍然需要 2 N 2N 2N字节。对于像GPT-3这样拥有1750亿参数的模型,这意味着FP32下需要700GB,FP16/BF16下需要350GB,这远远超过了普通GPU的容量。
- 梯度( △ W \triangle W △W): 在反向传播过程中,会为每个参数计算梯度。这些梯度通常与模型权重具有相同的维度,并需要相同的内存量(如果对梯度使用混合精度,则FP32下需要额外 4 N 4N 4N字节,FP16/BF16下需要 2 N 2N 2N字节
- 优化器状态: Adam或AdamW等现代优化器会维护状态信息,以调整每个参数的学习率。例如,Adam为每个参数存储两个矩:第一矩(动量)和第二矩(方差)。如果这些矩以FP32存储,这将额外增加 8 N 8N 8N字节(每个矩 4 N 4N 4N字节)。即使使用8位优化器,仍然会增加可观的开销。在FP32中使用AdamW时,参数、梯度和优化器状态的总内存可迅速达到 4 N + 4 N + 8 N = 16 N 4N+4N+8N=16N 4N+4N+8N=16N字节。使用混合精度可能会将此减少到 2 N + 2 N + 8 N = 12 N 2N+2N+8N=12N 2N+2N+8N=12N 字节(如果矩保持在FP32中),如果矩也被量化,则会更少。
- 中间激活值: 前向传播为每个层生成激活值。在反向传播过程中需要这些激活值来计算梯度。激活值消耗的内存取决于批量大小、序列长度、模型隐藏维度以及层数。对于大型模型和长序列,激活值会消耗大量的内存,有时甚至超过权重和优化器状态所需的内存。激活检查点(或梯度检查点)等技术可以通过在反向传播时重新计算激活值而不是存储它们来减少内存消耗,但这会增加计算时间(通常增加约30%)。
高计算成本、极高内存需求和僵硬的部署逻辑相结合,使得完全微调对许多组织和研究团队来说不切实际。此外,更新所有参数存在灾难性遗忘的风险,即模型在适应新数据时,其在原始通用预训练任务,甚至之前学过的微调任务上的表现会大幅下降。
1.2 细谈梯度和优化器
①模型权重
特征的组合方式,即 存储神经网络中可学习的参数集合,用于把输入映射为输出的线性/非线性变换系数。
②梯度
为模型参数提供“如何调整”的方向与幅度。梯度给出 方向信息,重要性信息,联合优化能力。若没有梯度,只能随机改参数,不知道哪个参数更重要,不知道该增大还是减小
在神经网络中的具体用途
前向传播:
x → 网络 → y_pred → 计算loss
反向传播:
loss → 计算梯度 → 更新权重
在数学中的表示
机器学习只有一个数学目标,降低最小化损失函数:
min 0 L ( θ ) \min_0 L(\theta) 0minL(θ)
导数的定义就是“最敏感方向”
偏导定义:
∂ L ∂ θ i = lim △ → 0 L ( θ i + △ ) − L ( θ i ) △ \frac{\partial L}{\partial \theta_i} = \lim_{\triangle \to 0} \frac{L(\theta_i+\triangle)-L(\theta_i)}{\triangle} ∂θi∂L=△→0lim△L(θi+△)−L(θi)
含义:参数微小变化 → 损失变化率
正:增大参数会让loss变大
负:增大参数会让loss变小
绝对值:影响强度
这正是我们要的信号
为什么不是对“准确率/输出”求导?
准确率不可导:
准确率
a c c = 预测正确个数 N acc = \frac{预测正确个数}{N} acc=N预测正确个数
是离散的分段常数,无法提供方向信息。
从最简单的模型推导
线性回归:
y = ω x + b y=\omega x +b y=ωx+b
L = ( y − y t r u e ) 2 L=(y-y_{true})^2 L=(y−ytrue)2
对 ω \omega ω求偏导:
∂ L ∂ ω = 2 ( y − y t r u e ) x \frac{\partial L}{\partial \omega}=2(y-y_{true})x ∂ω∂L=2(y−ytrue)x
完美解释误差大 → \rightarrow → 调整大,方向由符号决定, x x x决定重要性
链式法则的必然性
神经网络是复合函数:
L ( y ( f ( x ; θ ) ) ) L(y(f(x;\theta))) L(y(f(x;θ)))
必须: ∂ L ∂ θ = ∂ L ∂ y ⋅ ∂ y ∂ θ \frac{\partial L}{\partial \theta} =\frac{\partial L}{\partial y}·\frac{\partial y}{\partial \theta} ∂θ∂L=∂y∂L⋅∂θ∂y
从优化理论看
泰勒展开:
L ( θ + △ ) ≈ L ( θ ) + ▽ L T △ L(\theta + \triangle) ≈ L(\theta)+\triangledown L^T \triangle L(θ+△)≈L(θ)+▽LT△
| 符号 | 含义 |
|---|---|
| L ( θ ) L(\theta) L(θ) | 当前模型损失函数, θ \theta θ 是全部可训练参数 |
| θ + △ \theta + \triangle θ+△ | 对参数做微小调整后的新参数 |
| △ \triangle △ | 参数变化向量 δ θ \delta θ δθ,表示你准备更新的方向和幅度 |
| ∇ L \nabla L ∇L | 梯度向量,即 (L) 对每个参数的偏导数组成的向量 |
| ∇ L T △ \nabla L^T \triangle ∇LT△ | 梯度向量与更新向量的内积,表示在这个方向上损失的线性变化 |
要让loss下降最快:
△ = − η ▽ L \triangle = - \eta \triangledown L △=−η▽L
只有损失梯度能给出最速下降方向
③优化器
现代优化器adamW有两大特征:动量矩 → 解决“方向不稳定”,方差矩 → 解决“不同参数尺度差异”。
动量矩:
核心作用:抑制梯度方向震荡,加速连续同向的更新
数学形式:滑动平均
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t=\beta_1 m_{t-1}+(1-\beta_1)g_t mt=β1mt−1+(1−β1)gt
m t m_t mt: 动量矩,滑动平均梯度向量(与梯度维度相同)
β 1 ∈ [ 0 , 1 ) \beta_1 \in [0,1) β1∈[0,1):一阶矩衰减率(常用0.9)
m t − 1 m_{t-1} mt−1: 上一时刻动量矩
g t g_t gt:当前梯度
方差矩:
核心作用:自适应缩放不同参数的步长,解决梯度尺度差异问题
数学形式:平方梯度滑动平均
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t=\beta_2 v_{t-1}+(1-\beta_2)g_t^2 vt=β2vt−1+(1−β2)gt2
v t v_t vt: 方差矩,滑动平均梯度平方
β 2 ∈ [ 0 , 1 ) \beta_2 \in [0,1) β2∈[0,1):二阶矩衰减率(常用0.999)
v t − 1 v_{t-1} vt−1: 上一时刻方差矩
g t 2 g_t^2 gt2:逐元素平方,表示每个参数梯度的幅度大小
单纯梯度下降存在问题:
| 问题 | 原因 |
|---|---|
| 局部震荡 | 梯度方向在不同 mini-batch 或非凸表面来回变化 |
| 梯度噪声大 | 小批量训练导致随机波动 |
| 陡峭方向步子太大 | 梯度幅度大,沿高曲率方向容易跳过最优点 |
| 平坦方向步子太小 | 梯度幅度小,沿低曲率方向收敛缓慢 |
| 不同参数尺度差异 | 各层或各参数梯度大小差异巨大,统一学习率无法平衡 |
结论:梯度本身只提供局部方向信息,无法“记忆历史梯度”或“自适应步长”,因此无法解决上述干扰。需要优化器参与解决
参数更新公式(结合动量矩和方差矩):
AdamW更新:
θ t + 1 = θ t − η × m ^ t v ^ t + ϵ − η λ θ t \theta_{t+1}=\theta_t - \eta × \frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} - \eta\lambda\theta_t θt+1=θt−η×v^t+ϵm^t−ηλθt
| 符号 | 含义 | 备注 |
|---|---|---|
| θ t \theta_t θt | 参数向量在第 t t t 步的值 | 可为标量、向量或张量 |
| θ t + 1 \theta_{t+1} θt+1 | 参数向量在第 t + 1 t+1 t+1 步的更新后值 | — |
| η \eta η | 学习率(learning rate) | 控制步长,通常为正标量 |
| m ^ t \hat{m}_t m^t | 一阶矩的偏差校正估计(bias-corrected first moment) | m ^ t = m t 1 − β 1 t \hat{m}_t=\dfrac{m_t}{1-\beta_1^t} m^t=1−β1tmt,对应动量项 |
| v ^ t \hat{v}_t v^t | 二阶矩的偏差校正估计(bias-corrected second moment) | v ^ t = v t 1 − β 2 t \hat{v}_t=\dfrac{v_t}{1-\beta_2^t} v^t=1−β2tvt,对应平方梯度的滑动平均 |
| ϵ \epsilon ϵ | 防止除零的小常数(数值稳定项) | 常用如 1 e − 8 1e^{-8} 1e−8 |
| λ \lambda λ | 权重衰减系数(weight decay) | 与正则化相关,有时写作 w w w 或 weight_decay |
| m t m_t mt | 一阶矩(动量)未校正估计 | m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t=\beta_1 m_{t-1} + (1-\beta_1) g_t mt=β1mt−1+(1−β1)gt |
| v t v_t vt | 二阶矩(平方梯度)未校正估计 | v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t=\beta_2 v_{t-1} + (1-\beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2 |
| g t g_t gt | 当前梯度( ∇ θ L \nabla_\theta L ∇θL 在步 t t t 的值) | — |
| β 1 , β 2 \beta_1,\beta_2 β1,β2 | 一阶、二阶矩的衰减率超参数 | 常用值 β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9,\ \beta_2=0.999 β1=0.9, β2=0.999 |
1.3为什么效率并非可有可无
完全微调的局限性使得开发能够有效调整LLM,同时只修改总参数中一小部分的办法变得十分必要。这一需求推动了参数高效微调(PEFT)技术的发展和采用。主要目标包括:
- 大幅减少计算和内存: 使微调在要求较低的硬件上(例如,单个GPU或较小的集群)变得可行,并缩短训练时间。
- 实现高效多任务调整: 允许单个预训练模型实例通过只加载少量特定任务的参数来服务多个任务,而不是加载整个模型副本。这极大地简化了部署并显著降低了存储开销。
- 减轻灾难性遗忘: 通过冻结原始模型绝大部分参数,只调整一小部分,PEFT方法通常比完全微调更能保留模型的通用能力。
- 促进更快实验: 较低的资源需求允许在开发和测试新任务调整时进行更快的迭代周期。
PEFT方法通过策略性地添加或修改少量参数(通常少于总参数的1%),同时保持预训练模型的大部分冻结状态来实现这一点。其基本假设,尤其与后面将讨论的LoRA等方法相关,是特定任务所需的调整通常存在于一个低维子空间中。这意味着模型权重中所需的变化,即更新矩阵 △ W \triangle W △W,通常可以通过一个低秩矩阵有效近似,这比完整的 △ W \triangle W △W需要少得多的参数来表示。
二.LoRA低本征秩详解
2.1 LoRA假说说明
低秩适应(LoRA)引入了一种特定的数学结构,其设计理念是基于适应过程中权重更新具有低内在秩的假设,旨在提升参数效率。在标准微调中,通过添加一个增量矩阵 △ W ∈ R d × k \triangle W \in R^{d×k} △W∈Rd×k,来更新预训练权重矩阵 W 0 ∈ R d × k W_0 \in R^{d×k} W0∈Rd×k,从而得到适应后的权重 W = W 0 + △ W W = W_0 +\triangle W W=W0+△W。这种传统训练方法需要学习 △ W \triangle W △W中的所有 d × k d×k d×k个参数。
LoRA提出了一种不同的方法。我们不直接学习可能很大的 △ W \triangle W △W,而是使用低秩分解对其进行近似。具体来说, △ W \triangle W △W由两个较小矩阵 B ∈ R d × k B \in R^{d×k} B∈Rd×k和 A ∈ R d × k A \in R^{d×k} A∈Rd×k的乘积表示: △ W ≈ B A \triangle W ≈ BA △W≈BA
这里,LoRA 提出不学习整个 △ W \triangle W △W的 d × k d×k d×k个参数,而是仅学习 B B B和 A A A 中的参数。 B B B和 A A A中参数的总数为 d × r + r × k = r ( d + k ) d×r+r×k=r(d+k) d×r+r×k=r(d+k)。其中 r r r是分解的秩,LoRA的主要思想是 r < < m i n ( d , k ) r << min(d,k) r<<min(d,k)。由于 r r r的选择远小于 d d d和 k k k这个约束, r ( d + k ) r(d+k) r(d+k)会远小于 d × k d×k d×k。大大减少了我们需要学习的参数数量。原始权重 W 0 W_0 W0保持冻结(训练期间不更新),而矩阵 A A A和 B B B包含表示任务特定适应的可训练参数。
例如,考虑一个线性层,其中 d = 4096 , k = 4096 d=4096,k=4096 d=4096,k=4096。全量更新的 △ W \triangle W △W有超过1600万个参数。若假定适配可以通过秩 r = 8 r=8 r=8来表示,LoRA矩阵 B B B和 A A A将共有 8 × ( 4096 + 4096 ) = 65536 8×(4096+4096)=65536 8×(4096+4096)=65536个参数。这表示针对该特定层的适配,需要训练和存储的参数数量减少了99%以上。
LoRA核心假说: 适配的低本征秩,这种低秩假说是 LoRA 高效性的根本。通过假定任务特定的适配存在于一个低秩子空间中,LoRA 用其低秩因子 B B B和 A A A的优化来替代 △ W \triangle W △W的直接优化,同时保持原始模型权重 W W W不变。
2.2 LoRA数学表述
由2.1 LoRA的原式 W = W 0 + △ W W = W_0 +\triangle W W=W0+△W可得,考虑通过LoRA修改的层的正向传播。对于输入 x x x,原始输出是 y = x W 0 y=xW_0 y=xW0,加入LoRA更新后的线性(全连接)层的标准向前传播修改输出变为:
y = x W 0 T + b y=xW_0^T+b y=xW0T+b
其中 x x x是输入张量, W 0 ∈ R d o u t × d i n W_0 \in R^{d_{out} × d_{in}} W0∈Rdout×din 是权重(weight)矩阵, b b b是可选的偏置(bias)向量(vector), y y y是输出张量。转置符号 T T T把“参数矩阵的存储形状”与“线性层的数学乘法方向”对齐(不改变模型能力,只是决定向量是按“行向量×权重”还是“列向量×权重”来写公式)。这些维度假设输入批次 x ∈ R N × d i n x \in R^{N × d_{in}} x∈RN×din 产生输出 y ∈ R N × d i n y \in R^{N × d_{in}} y∈RN×din。
使用LoRA时,我们保持 W 0 W_0 W0和 b b b不变。适应项 △ W = B A \triangle W = BA △W=BA(其中 B ∈ R d o u t × r , A ∈ R r × d i n B \in R^{d_{out} × r},A \in R^{r × d_{in}} B∈Rdout×r,A∈Rr×din,r是自定义秩),添加到计算中得
y = x W 0 T + x ( △ W ) T + b ( 1 ) y=xW_0^T+x(\triangle W)^T+b (1) y=xW0T+x(△W)T+b(1)
y = x W 0 T + x ( A B ) T + b ( 2 ) y=xW_0^T+x(AB)^T+b (2) y=xW0T+x(AB)T+b(2)
y = x W 0 T + x A T B T + b ( 3 ) y=xW_0^T+xA^TB^T+b (3) y=xW0T+xATBT+b(3)
LoRA论文引入缩放因子 α r \frac{\alpha}{r} rα,应用于低秩更新。这种缩放有助于控制适应项对于原始权重的量级,尤其在改变秩 r r r时。最终LoRA向前传播为:
y = x W 0 T + ( x A T B T ) α r + b ( 4 ) y=xW_0^T+(xA^TB^T)\frac{\alpha}{r}+ b (4) y=xW0T+(xATBT)rα+b(4)
2.3 r r r和 α \alpha α的选择策略
通过上式,可以发现 r r r决定了训练参数的量级,同时更高的 r r r允许 B A BA BA近似更复杂的 △ W \triangle W △W。如果所需适配的真实“固有秩”较高,较小的 r r r可能不够用,导致欠拟合 (underfitting)。反之,如果 r r r设置得过高,它可能会通过捕捉噪声或虚假相关性导致训练数据过拟合 (overfitting),此外还会不必要地增加计算成本。
这与奇异值分解 (SVD) 等矩阵分解的思路相关,其中低秩近似能够捕捉矩阵中最主要的变动。LoRA 将此原则应用于微调过程中权重的变化。
r r r通常为研究和实践中常试用的典型值通常包括 2 的幂次方,例如 r = 4 , 8 , 16 , 32 , 64 , 128 r=4,8,16,32,64,128 r=4,8,16,32,64,128。最优值很大程度上取决于具体的模型、数据集和任务。
实验表明 α \alpha α与 r r r 有很大不同时,例如 α = 2 r \alpha=2r α=2r 或 α = r / 2 \alpha=r/2 α=r/2,模型表现最佳。
三.将LoRA融入transformers架构
本章节详见lora_transformer.py和load_lora_weight.py
Transformer 由堆叠的模块构成,通常包含多头自注意力 (self-attention) (MHA) 机制和位置前馈网络 (FFN)。MHA 和 FFN 都非常依赖线性变换,这些变换由大型权重矩阵表示。它们是 LoRA 适应的主要目标。
3.1 特定层选择
LoRA 允许采用选择性的方法,而不是修改模型中的每个权重 (weight)矩阵。最常见的方法是调整涉及以下内容的权重矩阵:
-
自注意力 (self-attention)机制 (attention mechanism): 用于计算查询( W q W_q Wq)、键( W k W_k Wk)和值( W v W_v Wv)矩阵的线性投影是主要的选择。通常,在组合注意力头之后的输出投影矩阵( W o W_o Wo)也会进行适应。
-
前馈网络 (FFN): FFN 通常由两个线性层组成,中间有一个激活函数 (activation function)。这两个线性层都可以作为 LoRA 适应的目标。
3.2 将 LoRA 整合到线性层中
在LoRA中,适应是通过在前向传播期间添加低秩更新来实现的。
y = x W 0 T + ( x A T B T ) α r + b ( 4 ) y=xW_0^T+(xA^TB^T)\frac{\alpha}{r}+ b (4) y=xW0T+(xATBT)rα+b(4)
3.3 Transformer 模块中 LoRA 整合的可视化
此图显示了 LoRA 适配器 ( B A BA BA) 通常在标准 Transformer 编码器模块中的插入位置。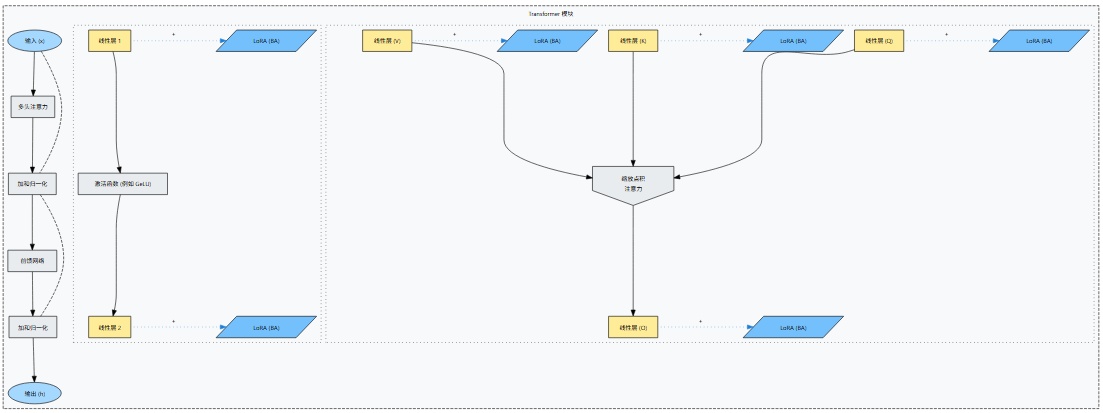
(图3-1)
LoRA 层内部的计算流可以按如下方式可视化: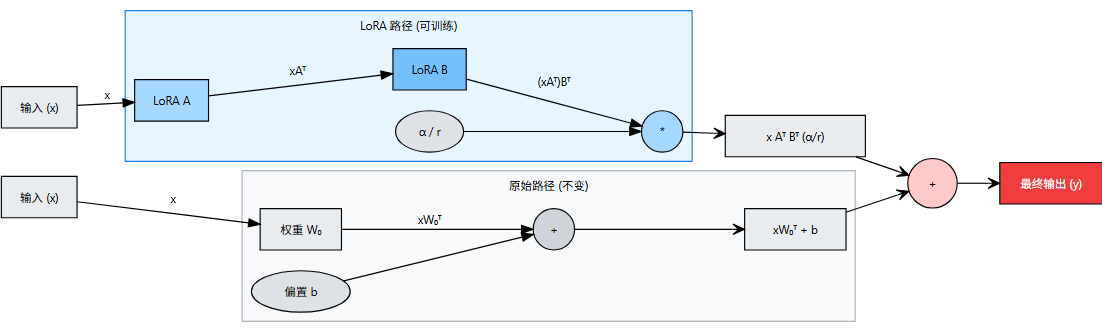
(图3-2)
四.PEFT 方法概览
peft是tsfs高效的训练微调库,核心目标是:在不全量更新大模型参数的前提下,只训练极少量参数就完成模型适配。
在确立了低秩适配 (LoRA) 的原理与实现后,我们将视野转向其他主要的参数 (parameter)高效微调 (fine-tuning) (PEFT) 技术。本章将比较介绍为应对大型语言模型 (LLM) 微调计算需求而发展的不同方法。
主要有:
- 适配器微调 (Adapter Tuning): 了解如何在预训练 (pre-training)模型层中插入小型、可训练的适配器模块。介绍它们的架构和实现细节。
- 前缀微调 (Prefix Tuning): 考察如何通过向输入或隐藏状态添加可调的连续向量 (vector)前缀,从而调整模型行为,同时不修改核心权重 (weight)。
- 提示微调 (Prompt Tuning): 研究侧重于学习软提示嵌入 (embedding)的技术,这提供了一种高效指导模型输出的方式。
4.1 适配器微调
4.1.1 适配器微调介绍
核心思想:注入可训练模块
适配器微调 (fine-tuning)的基本原理简洁而巧妙:冻结预训练 (pre-training)模型绝大多数参数 (parameter)(通常有数十亿个),并在模型的每一层或选定层中插入紧凑的、任务专用的“适配器”模块。微调时,只有这些新添加的适配器模块的参数会被训练。大语言模型(LLM)的原始权重 (weight)保持不变。如图3-2 所示。
其结构通常包含:
1.下投影: 一个线性层,将输入隐藏状态 h h h(维度为 d d d) 投影到一个小得多的中间维度 m m m。这个瓶颈维度 m m m是一个重要的超参数 (parameter) (hyperparameter),通常远小于 d d d。
2.非线性处理: 一个激活函数 (activation function) σ \sigma σ(如ReLU、GeLU或SiLU),应用于下投影的输出。这使得适配器能够学习复杂的非线性变换。
3.上投影: 一个线性层,将激活后的瓶颈表示重新投影回原始隐藏维度 d d d。
4.残差连接: 上投影的输出加回到原始输入隐藏状态 h h h。
数学上,如果 h ∈ R d h \in R^d h∈Rd 是适配器模块的输入,该操作可表示为:
h a d a p t e r = W u p ( σ ( W d o w n ( h ) ) ) h_{adapter}=W_{up}(\sigma(W_{down}(h))) hadapter=Wup(σ(Wdown(h)))
这里 W d o w n ∈ R m × d W_{down} \in R^{m×d} Wdown∈Rm×d 是下投影的权重(weight)矩阵, W u p ∈ R d × m W_{up} \in R^{d×m} Wup∈Rd×m是上投影的权重矩阵, σ \sigma σ是非线性激活函数。线性层中可以选择性地包含偏置 (bias)项。
适配器模块处理后的最终输出 h ′ h^\prime h′,包括残差连接,为:
h ′ = h + h a d a p t e r = h + W u p ( σ ( W d o w n ( h ) ) ) h^\prime=h+h_{adapter}=h+W_{up}(\sigma(W_{down}(h))) h′=h+hadapter=h+Wup(σ(Wdown(h)))
初始化: 一种常见做法是随机初始化 W d o w n W_{down} Wdown (例如使用标准的Kaiming或Xavier初始化),但将 W u p W_{up} Wup初始化为接近零。这确保了在训练开始时 t = 0 t=0 t=0,适配器模块的输出 h a d a p t e r h_{adapter} hadapter接近零,使 h ′ ≈ h h^\prime≈h h′≈h。这种策略有助于保留预训练 (pre-training)模型的初始能力并有助于稳定训练,因为适配器会逐步学习必要的任务专用变换。
Transformer中的插入位置
适配器模块需要策略性地放置在Transformer架构内。常见位置包含:
- 在多头自注意力 (self-attention)(MHSA)子层之后: 修改注意力机制 (attention mechanism)生成的表示。
- 在前馈网络(FFN)子层之后: 修改逐位置变换后的表示。
- 在每个Transformer块的最终层归一化 (normalization)之后。
通常,适配器在每个Transformer块内的注意力子层和FFN子层之后插入。下图展示了这些典型插入位置。
4.1.2适配器微调的实现细节
使用适配器最常见的方法是采用基于PyTorch或TensorFlow等流行框架构建的专业库。例如Hugging Face的adapter-transformers等库大大简化了过程。这些库无需手动修改底层模型架构,而是提供了高级API来执行以下操作:
1.加载预训练 (pre-training)模型: 从标准Transformer模型(例如BERT、RoBERTa、GPT-2)开始。
2.添加适配器模块: 指定适配器应插入的位置(通常在注意力层和前馈层内部或之后),并配置它们的属性(如瓶颈维度)。
3.管理适配器激活: 控制哪些适配器在训练或推理 (inference)期间处于活动状态。
训练策略:冻结基础模型
适配器训练的一个重要方面是冻结原始预训练 (pre-training)模型的权重 (weight)。只有新添加的适配器参数 (parameter)是可训练的。这大幅减少了需要计算和更新梯度的参数数量,与完全微调 (fine-tuning)相比,能显著节省内存和计算资源。
参数数量: 尽管基础模型可能拥有数亿或数十亿参数,但适配器通常只增加一小部分(通常小于1-5%)可训练参数
优化器: 通常使用AdamW等标准优化器。由于需要更新的参数较少,优化器状态(如动量和方差)的内存占用要小得多。
学习率: 训练适配器的最佳学习率可能与用于完全微调的学习率不同。它通常需要调整,但可能略高于用于微调整个大型模型的极小学习率,因为适配器是随机初始化并从头开始训练的。常见的学习率范围为 1 e − 4 1e−4 1e−4到 1 e − 3 1e−3 1e−3。
超参数 (parameter) (hyperparameter)和配置
有几个超参数控制着适配器的行为和能力:
1.瓶颈维度(适配器大小 / reduction_factor): 这可以说是最重要的超参数。它定义了适配器内部中间层的大小(下投影 W d o w n ∈ R d × d ′ W_{down} \in R^{d×d^\prime} Wdown∈Rd×d′ 和上投影 W u p ∈ R d ′ × d W_{up} \in R^{d^\prime×d} Wup∈Rd′×d中的 d ′ d^\prime d′, 其中 d d d是transformer层的隐藏维度。
- 较小的瓶颈维度意味着更少的参数、更快的训练和更低的内存使用,但可能会限制适配器学习任务的能力。
- 较大的维度会增加能力,但也会增加计算成本以及过拟合 (overfitting)的风险,尤其是在较小的数据集上。
- 典型值范围为8到64,通常需要根据任务和数据集大小进行经验性调整。
2.非线性: 在适配器模块中,下投影之后会应用一个激活函数 (activation function)。常见选项包括GeLU、ReLU或SiLU。选择的函数会影响性能,并且是另一个可能需要调整的超参数。
3.初始化: 适配器权重 (weight)( W d o w n W_{down} Wdown、 W u p W_{up} Wup和偏置(bias))通常随机初始化(例如,使用标准正态或Kaiming初始化),而基础模型权重保持冻结。一些研究表明,特定的初始化方案可以稍微改善收敛,但标准初始化通常效果良好。
4.适配器放置位置: 尽管原始的Adapter论文建议在每个Transformer块内的多头注意力 (multi-head attention)子层和前馈子层之后都插入适配器,但存在不同的变体。有些实现可能只在FFN之后放置适配器,从而进一步减少参数数量。最佳放置位置可能取决于具体任务。
4.2 前缀微调
不同于在模型现有层中嵌入 (embedding)可训练模块的方法,前缀微调 (fine-tuning)提供了一种不同的参数 (parameter)高效调整方式。它不修改内部权重 (weight)或添加适配器模块,而是通过在输入或隐藏状态前附加一系列连续的、特定于任务的向量 (vector)(即前缀),来调节冻结的预训练 (pre-training)模型的行为。
核心思路是学习一小组参数,这些参数能够有效地引导大型固定模型的激活,使其朝向所需的下游任务行为。可以设想,在模型处理实际输入之前,我们给它一个特殊的、学习到的“指令序列”。这个指令序列并非由离散的词元 (token)组成,而是由通过梯度下降 (gradient descent)直接优化的连续向量构成。
4.2.1 前缀微调 (fine-tuning)的工作方式
前缀微调在Transformer架构中通常涉及将可学习的前缀向量 (vector)添加到自注意力 (self-attention)机制 (attention mechanism)中每一层使用的键( K K K)和值( V V V)。原始模型参数 (parameter)保持不变。
让我们来看一下标准的自注意力计算:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
这里, Q , K , V Q,K,V Q,K,V 通常是输入隐藏状态 h h h的线性投影: Q = h W Q , K = h W K , V = h W V Q=hW_Q,K=hW_K,V=hW_V Q=hWQ,K=hWK,V=hWV。前缀微调通过将前缀向量 P K P_K PK和 P V P_V PV 连接到投影的键和值上来修改此过程:
K ′ = [ P K ; K ] = [ P K ; h W K ] K^\prime=[P_K;K]=[P_K;hW_K] K′=[PK;K]=[PK;hWK]
V ′ = [ P V ; V ] = [ P V ; h W V ] V^\prime=[P_V;V]=[P_V;hW_V] V′=[PV;V]=[PV;hWV]
查询 Q Q Q保持不变 Q = h W Q Q=hW_Q Q=hWQ。注意力计算变为:
A t t e n t i o n ( Q , K ′ , V ′ ) = s o f t m a x ( Q ( K ′ ) T d k ) V Attention(Q,K^\prime,V^\prime)=softmax(\frac{Q(K^\prime)^T}{\sqrt{d_k}})V Attention(Q,K′,V′)=softmax(dkQ(K′)T)V
前缀向量 P K P_K PK和 P V P_V PV各自包含 L p L_p Lp个向量,而 L p L_p Lp则是选择的前缀长度(一个超参数 (hyperparameter))。每个向量的维度与原始键/值向量相同(通常是 d k d_k dk或 d m o d e l d_{model} dmodel。这些前缀参数共同形成一个矩阵 P P P,是微调过程中唯一更新的参数。
参数 (parameter)数量与初始化
前缀微调 (fine-tuning)中的可训练参数数量取决于前缀长度 L p L_p Lp、模型的隐藏维度 d m o d e l d_{model} dmodel,以及层数 N N N:
可训练参数 ≈ L p × d m o d e l × N × 2 可训练参数 ≈ L_p × d_{model} × N × 2 可训练参数≈Lp×dmodel×N×2
(因子2是因为键和值有独立的前缀)。通常,会使用一个小型多层感知器(MLP)来将一个更小的初始前缀矩阵投影到 P K P_K PK和 P V P_V PV所需的完整维度,从而进一步减少参数。
训练与重参数 (parameter)化
在训练过程中,梯度仅相对于前缀参数 P P P计算,而大型预训练 (pre-training)模型保持冻结。使用AdamW等标准优化器。
经常采用的一个技术细节是重参数化。不是直接优化每层的前缀参数 P ∈ R L p × d m o d e l P \in R^{L_p × d_{model}} P∈RLp×dmodel,而是学习一个更小的矩阵 P ′ ∈ R L p × d e m b P^\prime \in R^{L_p × d_{emb}} P′∈RLp×demb,同时学习两个投影矩阵
W p r o j , K , W p r o j , V ∈ R d e m b × d m o d e l W_{proj,K},W_{proj,V} \in R^{d_{emb} × d_{model}} Wproj,K,Wproj,V∈Rdemb×dmodel。这样, P K = P p r o j , K ′ W P_K=P^{\prime W}_{proj,K} PK=Pproj,K′W和 P V = P p r o j , V ′ W P_V=P^{\prime W}_{proj,V} PV=Pproj,V′W。如果 d e m b < d m o d e l d_{emb} < d_{model} demb<dmodel,这会减少可训练参数的数量。
前缀微调 (fine-tuning)对比提示微调
前缀微调与提示微调密切相关。主要区别在于调节发生的位置。提示微调通常只在输入层序列前附加可学习的嵌入 (embedding),使其参数 (parameter)效率更高。前缀微调则通过将学习到的向量 (vector)注入每一层的注意力机制 (attention mechanism),可能提供更大的表达能力来影响模型在整个生成过程中的内部表示,尽管代价是参数量略多于提示微调。
前缀微调提供了一种优雅的方式来调整LLMs,通过将计算工作集中在学习一个小的、特定于任务的“控制序列”上,而不是改变模型的核心知识。它在PEFT工具包中是一种有价值的替代方案,特别是在严格的参数效率和非侵入式模型调整是主要目标时。
4.3 提示词微调
提示词 (prompt)微调 (fine-tuning)提供了一种独特的模型行为引导策略。与那些通过修改或增加Transformer层中的组件来进行模型微调的方法不同,提示词微调通过操作模型的输入来实现这一点,而完全不改变基础模型的内部权重 (weight)。此方法简单但对许多任务来说非常有效,是现有参数 (parameter)效率最高的策略之一。
主要原理:可学习的软提示词 (prompt)
传统提示词涉及在实际输入前添加离散的文本指令(例如:“将英语翻译成法语:”)。提示词微调 (fine-tuning)用可学习的连续向量 (vector)取代了这些手动编写的文本提示词,这些向量通常被称为“软提示词”或“提示词嵌入 (embedding)”。想象一下,你想对LLM进行摘要任务的微调。你不是仅仅输入要摘要的文本,而是在其前面添加一个包含 K K K个特殊提示词嵌入的序列:
[ P 1 , P 2 , . . . , P k , E ( x 1 ) , E ( x 2 ) , . . . , E ( X n ) ] [P_1,P_2,...,P_k,E(x_1),E(x_2),...,E(X_n)] [P1,P2,...,Pk,E(x1),E(x2),...,E(Xn)]
此处:
- E ( x i ) E(x_i) E(xi)表示第 i i i个输入词元 (token) x i x_i xi的标准嵌入。
- P j P_j Pj 是第 j j j个可训练的提示词嵌入向量。每个 P j P_j Pj与词嵌入具有相同的维度(例如, d m o d e l d_{model} dmodel)。
- k k k 是一个指示软提示词长度的超参数 (parameter) (hyperparameter)。
在微调过程中,唯一被更新的参数是这 k k k个提示词向量 P 1 , . . . , P k P_1,...,P_k P1,...,Pk所有原始LLM参数(注意力层、前馈网络中的权重 (weight),嵌入查找表 E E E等)都保持冻结。优化过程通过反向传播 (backpropagation)调整提示词嵌入 P j P_j Pj,以便将它们添加到输入序列前,从而引导冻结的LLM生成所需的输出(例如,一个正确的摘要)。这种方法极大地减少了可训练参数的数量,即使对于数十亿参数的模型,通常也只减少到几千或几万个(远低于总参数的0.1%)。这使得训练的内存效率非常高。
初始化的影响
提示词 (prompt)嵌入 (embedding) P j P_j Pj的初始化方式可以明显影响训练稳定性和最终性能。常用策略有:
1.随机初始化: 使用小的随机值初始化向量 (vector),类似于其他网络权重 (weight)的初始化方式。这种方法简单,但可能需要仔细调整学习率,并可能导致更长的收敛时间。
2.词汇初始化: 使用模型词汇表 (vocabulary)中与目标任务相关的特定词汇的平均嵌入来初始化提示词嵌入。例如,对于摘要任务,你可以使用“Summarize”、“TLDR”、“Abstract”、“Condense”等词汇的嵌入进行初始化。这可以为优化过程提供一个更好的起点。
P-Tuning:提升提示词 (prompt)的稳定性和能力
尽管基础提示词微调 (fine-tuning)效率很高,但其性能有时会落后于完全微调或LoRA等方法,特别是在GLUE或SuperGLUE等基准测试中发现的复杂自然语言理解(NLU)任务上。开发P-Tuning等变体就是为了解决这些局限性。
P-Tuning (v1):引入提示词编码器
P-Tuning (v1) 观察到手动选择最优提示词的离散性很难实现,并且独立的提示词嵌入 (embedding)(如基础提示词微调中所示)可能缺乏表现力。它提出了两个主要方面:
1.提示词编码器: P-Tuning没有直接学习静态提示词嵌入,而是使用一个小型神经网络 (neural network)(通常是BiLSTM后接MLP),称为“提示词编码器”。该编码器将虚拟提示词标记 (token)序列作为输入,并动态生成实际的连续提示词嵌入。这使得提示词嵌入之间可以存在依赖关系,从而可能增加它们的表现力。
2.锚定标记: 有时会在输入中散布任务特定的锚定标记,以进一步引导模型。
P-Tuning v2(深度提示词微调):层级特定提示词
P-Tuning v2(常被称为深度提示词微调)通过将可训练的提示词嵌入应用于Transformer的每个层,而不仅仅是输入层,从而大幅增强了该方法。然而,P-Tuning v2通常只添加前缀向量 (vector),而Prefix Tuning通常涉及专门为注意力机制 (attention mechanism)学习前缀键值对。
参考资料
https://gitee.com/WangJiaHui202144/lora-env
https://apxml.com/zh/courses/lora-peft-efficient-llm-training

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)