一文讲清:如何才能实现一个多模态RAG系统呢?
摘要:多模态RAG系统通过融合文本、图像等异构数据,突破传统RAG的文本局限,实现更全面的信息处理。其实现流程包括文档解析、多模态嵌入融合和上下文构建三个核心环节,需解决跨模态对齐、语义关联等挑战。尽管面临工程落地难题,多模态RAG在工程设计图等场景已展现应用价值。随着AI大模型快速发展,掌握多模态技术将成为应对行业人才缺口的重要方向。(149字)
多模态RAG是一个高度复杂的系统,必须分模块推进,涵盖文档解析、多模态嵌入融合、上下文构建等多个环节。
尽管RAG技术仍存在诸多局限,但它已具备落地真实业务的能力,能够应对部分现实需求;而随着应用场景日益多元,多模态RAG逐渐成为必然方向——因为在许多场景中,仅靠文本信息根本无法完整表达或解决问题。
例如,在工程设计图、产品原型图、系统架构图等场景下,纯文字描述往往力不从心;正因如此,多模态RAG应运而生。
当然,这一概念并非近年首创,早已被学术界和工业界所探讨。若仅从理论层面看,多模态RAG似乎只是在传统RAG基础上叠加了图像、图表等非文本数据,但在实际工程落地中,却处处遭遇瓶颈与挑战。
因此,本文将简要梳理多模态系统的实现路径,并剖析当前面临的核心难题。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2026最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
多模态RAG实现流程
多模态RAG在基础RAG框架中融入多模态数据,其整体流程仍严格沿袭“文档解析–>入库–>检索召回–>生成”的完整链条。
然而,因多模态数据的本质特性,其处理方式与传统纯文本系统存在显著分野:在文档解析阶段,必须从原始材料中分离出文本、图像等多种模态成分,对各模态进行独立表征与存储,并建立跨模态间的语义关联结构。
{
"file_id": "文件id",
"page_no": "页码",
"text": "文本描述",
"img": ["图片地址", "图片地址"]
}
文档解析可采用多样化的技术路径:一方面,可通过调用专业的文档处理库,或通过人工方式逐层提取文本、图像、页码等元素;另一方面,也可依托视觉语言模型(VLM)实现语义理解,或借助OCR技术识别文本与表格内容,甚至直接接入成熟的第三方解析服务。
总而言之,文档解析的首要任务在于提取文档内多模态数据,并完整保留其原始结构与元数据信息。
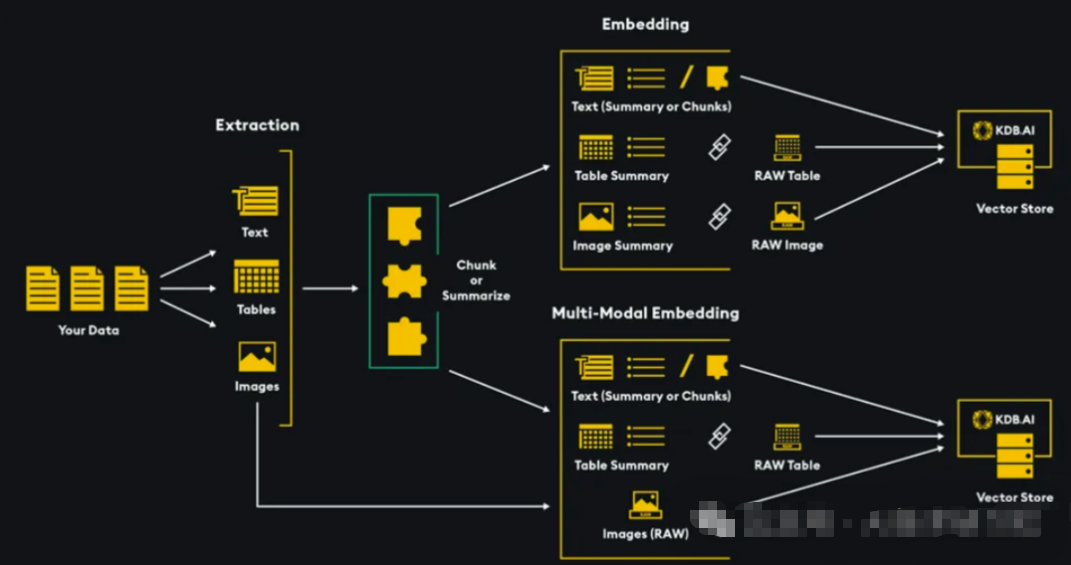
入库与检索
多模态文档入库的目标与传统RAG一致,均服务于向量相似度计算;然而,其实现路径可分为两类:
内容提取:将多模态内容解析为文本描述,继而依托文本语义相似度完成检索
多模态嵌入模型:通过模态融合机制,直接将文字、图像、视频、音频等异构数据映射至统一向量空间进行检索,代表性模型如CLIP
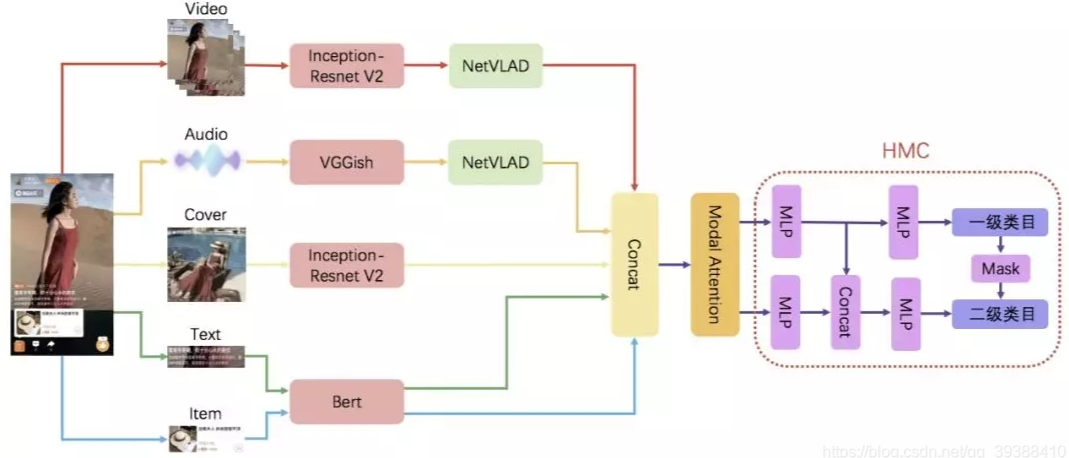
当然,未来或许还会涌现出其他应对多模态检索的策略,例如将不同模态的数据独立分块处理——文本用于检索文本信息,图像用于检索视觉内容,最终再将各模态的检索结果进行整合;抑或出现全新的算法范式。
总而言之,存储采用何种方式,提取时就必须匹配对应的方法;多模态数据的处理涉及一系列核心技术,涵盖但不限于跨模态对齐、多模态表示、多模态融合等,其终极目标始终如一:更高效地协同处理异构模态的信息。
生成
在RAG框架中,检索的本质是为生成提供支撑,而生成才是最终目标——若缺乏有效的生成,再精准的检索也形同虚设。
生成质量的核心在于上下文的构建,唯有结构清晰、语义连贯的上下文,才能有效引导模型输出高质量内容。
对于文本型RAG,上下文的组装极为直接:只需依据提示词模板,将用户查询、对话历史与检索到的文档内容线性拼接即可完成;
然而,在多模态场景下,上下文构建的复杂性显著提升。由于当前主流多模态模型的输入接口将文本与图像作为独立通道处理,二者之间的语义对齐与关联建模成为关键瓶颈——如何建立图文间的有效对应关系,成为亟待解决的结构性难题。
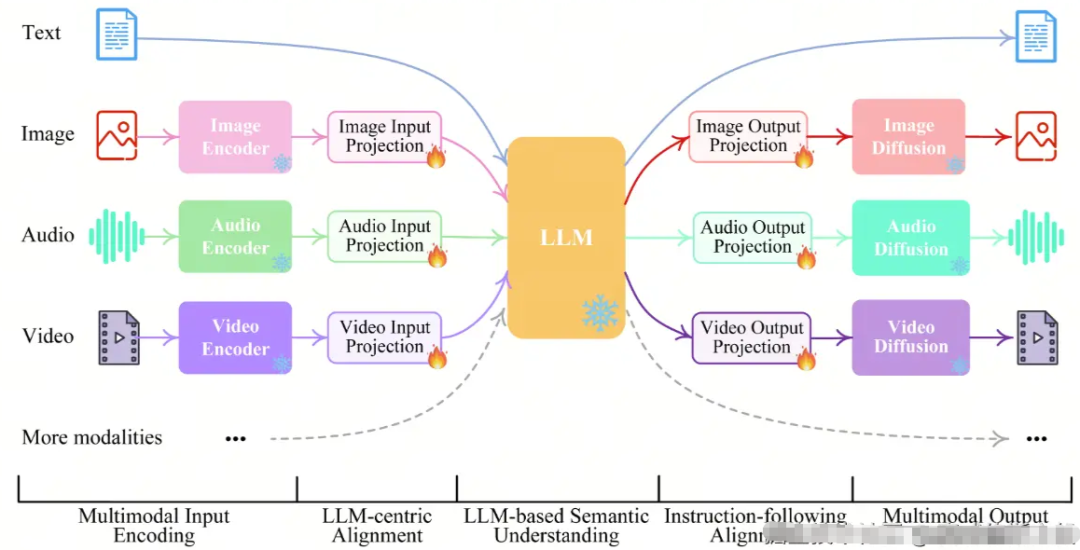
在多模态RAG的实践中,完成检索与上下文构建之后,模型自身的理解与生成能力成为决定效果的关键——这完全依赖模型的内在机制;例如,互联网、房地产、铁路、交通等领域的设计图,其结构逻辑与关注维度各不相同;针对这些垂直行业,若不对模型进行针对性训练与调优,便难以实现预期的精准响应。
总结
多模态RAG的落地远比理论模型更为复杂,无法一蹴而就,唯有遵循RAG的整体架构,逐层拆解、逐步迭代,方能持续推进。在作者看来,其最核心的三大环节为:文档解析、嵌入、生成,分别对应智能文档处理、多模态融合嵌入、上下文构建。
对模型而言,其输入需是一个由文本、图像、视频、音频等多模态元素构成的结构化上下文;嵌入环节聚焦于多模态数据的存储与高效检索,涵盖内容摘要、跨模态对齐与融合等技术,本质是解决“上下文数据从何而来、如何构建”的问题;而文档解析的核心目标,则是对原始文档进行结构化拆分,为后续的存储、索引与检索奠定基础。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2026最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)