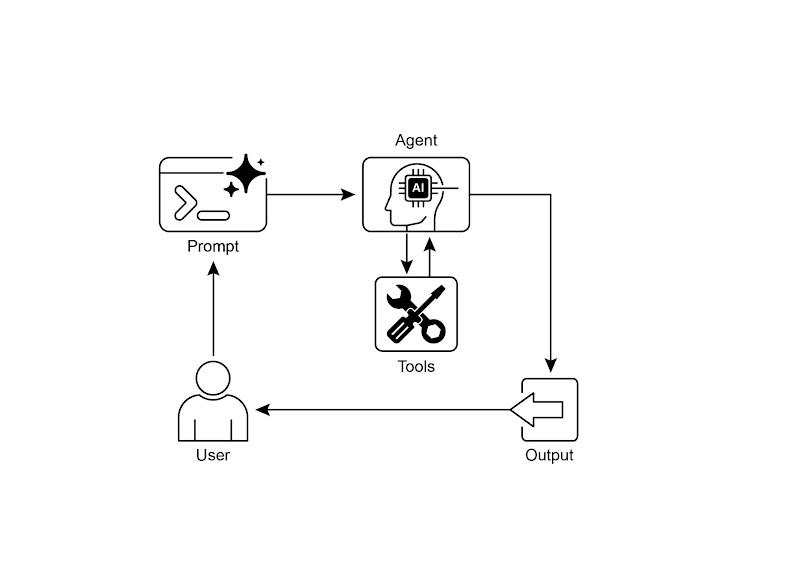
智能体设计模式 第五章:工具使用
我们讨论的智能体模式侧重于在大语言模型之间协调交互和管理智能体内部的信息流(如提示链、路由、并行化和反思模式)。但如果要让智能体真正有用、能与现实世界或外部系统交互,就必须赋予它们使用工具的能力。工具使用模式通常通过函数调用(Function Calling)机制实现,使智能体能够与外部 API、数据库、服务交互,甚至直接执行代码。它允许作为智能体核心的大语言模型根据用户请求或当前任务状态,来决定
智能体设计模式 第五章:工具使用
工具使用模式概述
到目前为止,我们讨论的智能体模式侧重于在大语言模型之间协调交互和管理智能体内部的信息流(如提示链、路由、并行化和反思模式)。但如果要让智能体真正有用、能与现实世界或外部系统交互,就必须赋予它们使用工具的能力。
工具使用模式通常通过函数调用(Function Calling)机制实现,使智能体能够与外部 API、数据库、服务交互,甚至直接执行代码。它允许作为智能体核心的大语言模型根据用户请求或当前任务状态,来决定何时以及如何使用特定的外部函数。

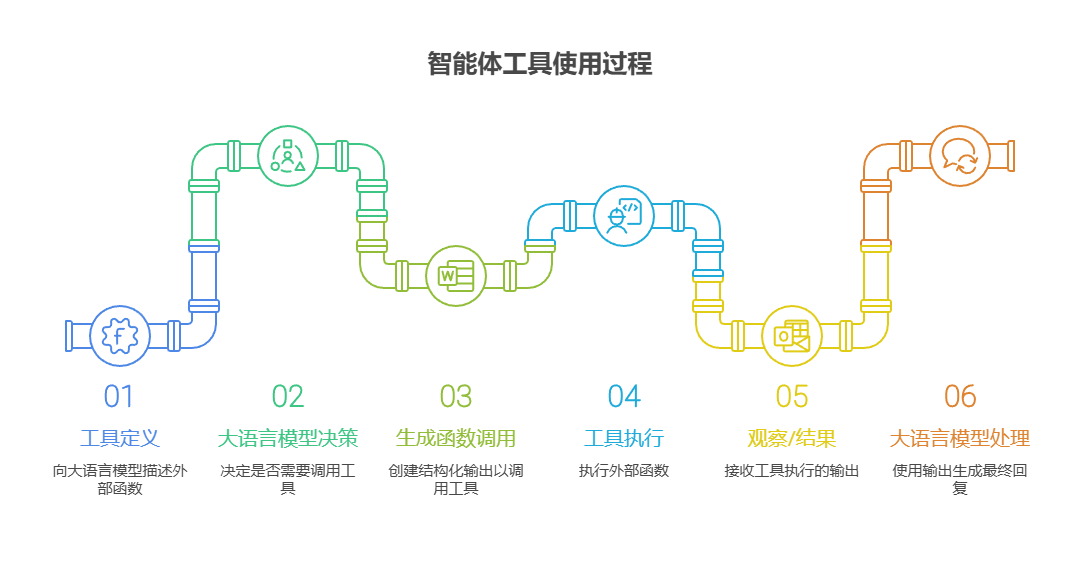
这个过程通常包括以下几个步骤:
- 工具定义:向大语言模型描述外部函数或功能,包括函数的用途、名称,以及所接受参数的类型和说明。
- 大语言模型决策:大语言模型接收用户的请求和可用的工具定义,并根据对两者的理解判断是否需要调用一个或多个工具来完成请求。
- 生成函数调用:如果大语言模型决定使用工具,它会生成结构化输出(通常是 JSON 对象),指明要调用的工具名称以及从用户请求中提取的参数。
- 工具执行:智能体框架或编排层捕获这个结构化输出,识别要调用的工具,并根据给定参数执行相应的外部函数。
- 观察/结果:工具执行的输出或结果返回给智能体。
- 大语言模型处理(可选,但很常见):大语言模型接收工具的输出作为上下文,并用它来生成对用户的最终回复,或决定工作流的下一步(可能涉及调用另一个工具、进行反思或提供最终答案)。
这种模式很关键,因为它突破了大语言模型训练数据的局限,使其能够获取最新信息、执行内部无法处理的计算、访问用户特定的数据,或触发现实世界的动作。函数调用是连接大语言模型推理能力与外部功能的技术桥梁。
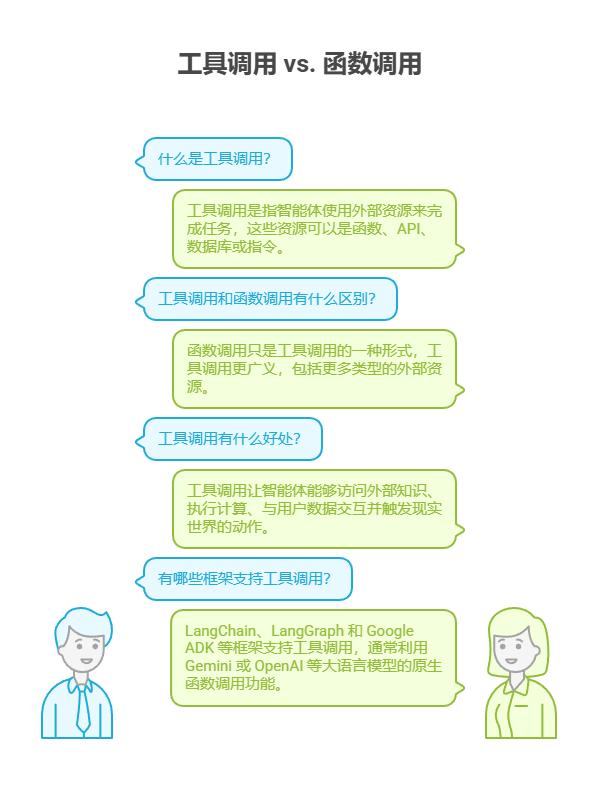
虽然「函数调用」这个说法确实能准确描述调用预定义代码函数的过程,但从更广阔的视角理解「工具调用」这一概念更为有益。通过这个更广义的术语,我们看到智能体的能力可以远远超出简单的函数执行。工具可以是传统函数、复杂的 API 接口、数据库请求,甚至是发给另一个智能体的指令。这种视角让我们能够构想更复杂的系统,例如,主智能体可以将复杂的数据分析任务委托给专门的「分析智能体」,或通过 API 查询外部知识库。「工具调用」的思维方式能更好地捕捉智能体作为编排者的全部潜力,使其能够在多样化的数字资源和其他智能生态系统中发挥作用。
LangChain、LangGraph 和 Google ADK 等框架可以很方便地定义工具并将它们集成到智能体工作流中,通常会利用 Gemini 或 OpenAI 等现代大语言模型的原生函数调用功能。在这些框架中,你可以定义工具,并通过设置让智能体识别和使用这些工具。
工具使用是构建强大、可交互且能感知和利用外部资源的智能体的关键模式。
实际应用场景
当智能体需要的不只是文本生成,而是执行操作或检索动态信息的时候,工具使用模式几乎都能派上用场。
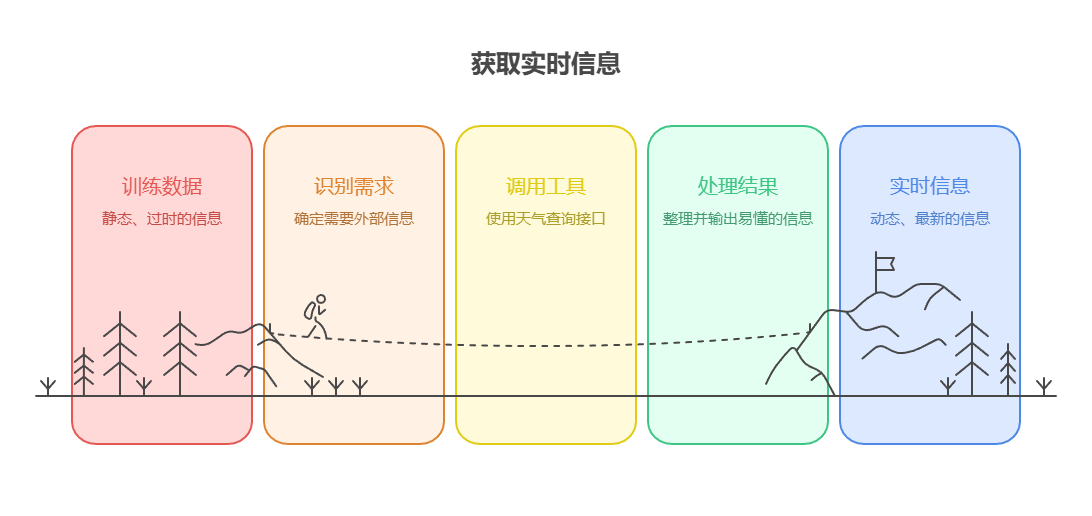
- 从外部来源获取信息:
获取大语言模型训练数据中未包含的实时数据或信息。
-
用例:天气信息智能体。
-
工具:天气查询接口,可输入地点并返回该地的实时天气。
-
智能体流程:用户提问「伦敦天气怎么样?」,大语言模型识别出需要使用天气工具,并使用「伦敦」作为参数调用该工具,工具返回数据后,大语言模型将这些信息整理并以易懂的方式输出给用户。
- 与数据库和接口交互:
对结构化数据执行查询、更新或其他操作。
-
用例:电商平台智能体。
-
工具:通过接口来检查产品库存、查询订单状态或处理支付。
-
智能体流程:用户提问「产品 X 有货吗?」,大语言模型先调用库存接口,工具返回库存数量后,大语言模型向用户反馈该产品库存情况。
- 执行计算和数据分析:
使用计算器、数据分析库或统计工具。
-
用例:金融领域智能体。
-
工具:计算器函数、股票行情接口、电子表格工具。
-
智能体流程:用户提问「苹果公司当前股价是多少?如果我以 150 美元买入 100 股,可能会赚多少钱?」,大语言模型会先调用股票行情接口获取最新价格,然后调用计算器工具计算收益,最后把结果整理并返回给用户。
- 消息发送:
发送电子邮件、消息或调用外部通信服务的接口。
-
用例:个人助理智能体。
-
工具:邮件发送接口。
-
智能体流程:用户说「给约翰发一封关于明天会议的邮件」,大语言模型会从请求中提取收件人、主题和正文,并调用邮件接口发送邮件。

- 执行代码:
在受控且安全的环境中运行代码片段以完成特定任务。
-
用例:编程助理智能体。
-
工具:代码解释器。
-
智能体流程:用户提供一段 Python 代码并问「这段代码是做什么的?」,大语言模型会先使用代码解释器运行代码,并据此进行分析和解释。
- 控制其他系统或设备:
与智能家居设备、物联网平台或其他联网系统交互。
-
用例:智能家居智能体。
-
工具:控制智能灯的接口。
-
智能体流程:用户说「关掉客厅的灯」,大语言模型将带有命令和目标设备信息的请求发送给智能家居工具以执行操作。
工具使用模式将语言模型从文本生成器变成能够在数字或现实世界中感知、推理和行动的智能体。
实战代码:使用 LangChain
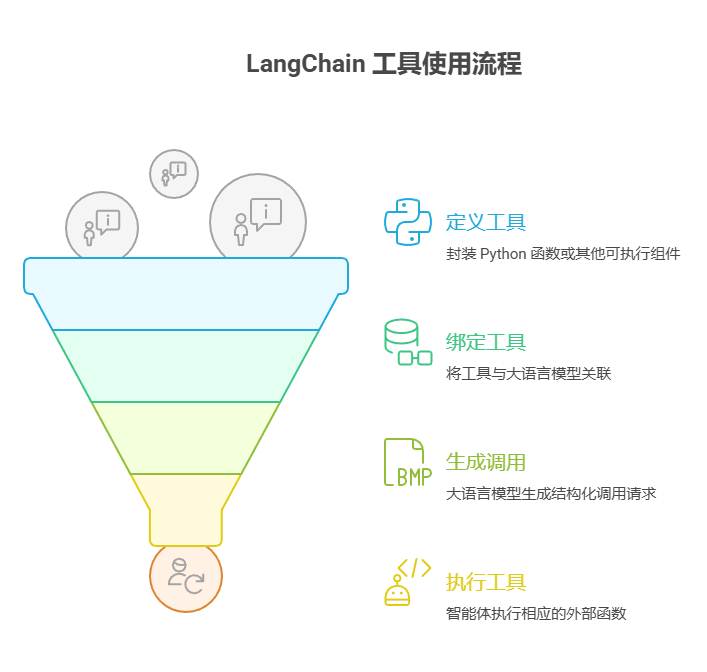
在 LangChain 框架中,使用工具分两个步骤。首先,定义一个或多个工具,通常通过封装现有的 Python 函数或其他可执行组件来完成。随后,将这些工具和大语言模型绑定,这样当大语言模型判断需要调用外部函数来完成用户请求时,就能生成结构化的调用请求并执行相应操作。
以下代码将演示这一原理。首先定义一个简单函数来模拟信息检索工具,然后构建并配置智能体,使其能够利用该工具响应用户输入。运行此示例需要先安装 LangChain 的核心库和相应的模型接入包,并在本地环境中配置好 API 密钥。
Gemini API 测试
import os
import google.generativeai as genai
# 替换自己的 API_KEY
API_KEY = "AIzaSy******"
# 如果你是开了 Clash / 代理,这两行可以确保 REST 请求也走代理
# 没有代理就不用写
# os.environ["HTTP_PROXY"] = "http://127.0.0.1:7890"
# os.environ["HTTPS_PROXY"] = "http://127.0.0.1:7890"
# 关键:强制使用 REST,而不是默认的 gRPC
genai.configure(
api_key=API_KEY,
transport="rest",
)
model = genai.GenerativeModel("models/gemini-2.5-flash")
response = model.generate_content(
"测试一下你是否正常工作?用中文回答。",
request_options={"timeout": 20}, # 超时 20 秒,不够可以调大一点
)
print("模型输出:")
print(response.text)
运行示例:

信息检索工具模拟
这是一个用“文本协议”模拟 Tool Calling 的极简 Agent Demo:模型负责决定是否需要工具,Python 负责真正调用工具,然后模型负责把工具结果写成最终回答;最后用 asyncio 并发跑多个问题。
import os
import asyncio
import nest_asyncio
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# =========================================================
# 1. 环境初始化(可切换 DeepSeek / Qwen)
# =========================================================
load_dotenv()
# 可用 "deepseek" 或 "qwen"
PROVIDER = "deepseek"
def init_llm():
"""
初始化 DeepSeek 或 Qwen(均为 OpenAI 兼容接口)
"""
if PROVIDER == "deepseek":
return ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com/v1"),
temperature=0,
)
elif PROVIDER == "qwen":
return ChatOpenAI(
model="qwen-omni-turbo",
api_key=os.getenv("QWEN_API_KEY") or os.getenv("DASHSCOPE_API_KEY"),
base_url=os.getenv("QWEN_BASE_URL", "https://dashscope.aliyuncs.com/compatible-mode/v1"),
temperature=0,
)
else:
raise ValueError("未知 PROVIDER,请使用 deepseek 或 qwen")
llm = init_llm()
print("✔ 大模型初始化完成!")
# =========================================================
# 2. 定义本地工具
# =========================================================
def search_information(query: str) -> str:
"""
一个简单的“本地知识库查询工具”,支持中英文关键词。
"""
print(f"\n[工具] search_information 被调用,查询: {query}")
q = query.strip().lower()
database = {
# 英文
"france capital": "法国的首都是巴黎。",
"weather london": "伦敦目前多云,气温大约 15°C。",
"earth population": "地球人口大约 80 亿。",
# 中文
"法国的首都": "法国的首都是巴黎。",
"伦敦天气": "伦敦目前多云,气温大约 15°C。",
"地球人口": "地球人口大约 80 亿。",
}
# 先精准匹配
if q in database:
return database[q]
# 再做一点简单的模糊匹配
if "法国" in query and "首都" in query:
return "法国的首都是巴黎。"
if "伦敦" in query and ("天气" in query or "气温" in query):
return "伦敦目前多云,气温大约 15°C。"
if "地球" in query and ("人口" in query or "人数" in query):
return "地球人口大约 80 亿。"
return f"没有找到关于「{query}」的本地信息。"
# 需要接自己的服务
def search_information(query: str) -> str:
"""
示例:调用一个假想的天气/知识 API。
这里用伪代码结构,你替换成自己真正在用的接口即可。
"""
print(f"\n[工具] search_information 被调用,查询: {query}")
# 这里假设 query 已经是英文关键词,比如 "weather london"
if query.lower().startswith("weather "):
city = query.split(" ", 1)[1]
# 调用你自己的天气服务
resp = requests.get(
"https://api.example.com/weather",
params={"city": city, "apikey": os.getenv("WEATHER_API_KEY")},
timeout=5,
)
data = resp.json()
# 根据真实返回结构组织一下结果:
return f"{city} 当前气温 {data['temp']}°C,天气 {data['description']}。"
# 其他类型的查询也可以在这里扩展
return f"暂时不支持「{query}」类型的查询。"
TOOLS = {
"search_information": search_information
}
# =========================================================
# 3. ChatOpenAI 新版接口:必须使用 invoke / ainvoke
# =========================================================
async def call_llm(messages):
"""
新版本 ChatOpenAI 的正确调用方式:
- 支持异步
- 必须传入 messages(列表)
- 最终返回 resp.content
"""
resp = await llm.ainvoke(messages)
return resp.content
# =========================================================
# 4. 手写“工具调用 Agent”
# =========================================================
async def agent_call(query: str):
print(f"\n==============================")
print(f"--- 🏃 用户提问:{query}")
print("==============================")
# -----------------------------
# 第一步:让模型判断是否需要使用工具
# -----------------------------
decision_messages = [
{"role": "system", "content": """
你是一名智能助手,拥有以下一个工具:
工具:search_information(query: str)
说明:用于查询事实性信息,例如首都、天气、人口等。
你的任务:
1)如果用户的问题涉及“事实查询”,请严格按以下格式回答(不能多字):
TOOL: search_information
QUERY: <需要查询的内容>
2)如果不需要工具,请直接用自然语言回答用户。
"""},
{"role": "user", "content": query}
]
decision = await call_llm(decision_messages)
print("\n[模型判断]:")
print(decision)
lower = decision.strip().lower()
# -----------------------------
# 第二步:模型决定使用工具
# -----------------------------
if lower.startswith("tool:"):
# 解析两行格式
lines = [l for l in decision.split("\n") if l.strip()]
tool_name = lines[0].split(":", 1)[1].strip()
tool_query = lines[1].split(":", 1)[1].strip()
print(f"\n[Agent] 模型选择调用工具:{tool_name}('{tool_query}')")
# 调用本地工具
if tool_name not in TOOLS:
print("❌ 工具名称不存在,直接回答。")
fallback = await call_llm([
{"role": "assistant", "content": f"无法找到工具 {tool_name},请直接回答用户:{query}"}
])
print("最终回答:", fallback)
return
tool_result = TOOLS[tool_name](tool_query)
print("[工具返回]:", tool_result)
# -----------------------------
# 第三步:将工具结果回传给模型,让它组织最终回答
# -----------------------------
final_messages = [
{"role": "system", "content": "你是一个专业、简洁的中文智能助手。"},
{"role": "assistant", "content": f"工具结果:{tool_result}"},
{"role": "user", "content": f"请基于工具结果,用中文回答最初的问题:{query}"}
]
final_answer = await call_llm(final_messages)
print("\n✨ 最终回答:")
print(final_answer)
else:
# -----------------------------
# 不使用工具
# -----------------------------
print("\n✨ 最终回答(未使用工具):")
print(decision)
# =========================================================
# 5. 并发执行多个提问
# =========================================================
async def main():
await asyncio.gather(
agent_call("法国的首都是哪里?"),
agent_call("伦敦的天气怎么样?"),
agent_call("给我讲一个关于猫的有趣知识。"),
)
nest_asyncio.apply()
asyncio.run(main())
以上代码就是:用 DeepSeek 或 Qwen 作为大模型,手写了一个“先判断要不要用工具→需要就调用本地函数→再让模型把工具结果组织成最终回答”的简易 Agent,并且用 asyncio 并发跑多个问题。
整体流程:
-
初始化大模型
从 .env 读 Key/BaseURL,根据 PROVIDER 选择 DeepSeek(deepseek-chat)或 Qwen(qwen-omni-turbo),用 ChatOpenAI 的 OpenAI-compat 方式调用。 -
定义一个工具(search_information)
代码里想把它当作“查事实信息”的工具(首都、天气、人口等)。Agent 通过 TOOLS = {“search_information”: search_information} 注册它,后面用名字去调用。 -
LLM 异步调用封装
call_llm(messages) 里用 llm.ainvoke(messages) 调模型,返回 resp.content 文本。 -
手写 Agent:三段式
-
决策阶段:先把用户问题喂给模型,让模型按你规定的格式回答:
要用工具就输出TOOL: search_information QUERY: ...
不用工具就直接自然语言回答。
-
执行阶段:如果检测到 TOOL: 开头,就解析出工具名和 QUERY,调用对应 Python 函数拿到工具结果。
-
总结阶段:把“工具结果”再喂给模型,让模型基于结果生成最终中文答复。
-
-
并发执行多个提问
main() 用 asyncio.gather(…) 同时跑 3 个 agent_call,让三个问题并发处理。
nest_asyncio.apply() 是为了解决在 Jupyter/某些环境里重复启动事件循环的问题,然后 asyncio.run(main()) 启动运行。
这是一个用“文本协议”模拟 Tool Calling 的极简 Agent Demo:模型负责决定是否需要工具,Python 负责真正调用工具,然后模型负责把工具结果写成最终回答;最后用 asyncio 并发跑多个问题。
运行输出:

实战代码:CrewAI
以下代码展示了使用 CrewAI 框架实现函数调用的实际示例。场景很简单:为智能体配备用于查找信息的工具,并通过该智能体和工具来获取模拟的股票价格。
# pip install crewai langchain-openai python-dotenv
# 使用 CrewAI 框架实现函数 为智能体配备用于查找信息的工具,并通过该智能体和工具来获取模拟的股票价格。
import os
import logging
from dotenv import load_dotenv
from crewai import Agent, Task, Crew
from crewai.tools import tool
# =========================================================
# 1. 日志配置
# =========================================================
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# =========================================================
# 2. 加载 .env,并选择使用 DeepSeek 或 Qwen
# =========================================================
load_dotenv()
# 可选值:"deepseek" 或 "qwen"
PROVIDER = "deepseek"
def setup_llm_env():
"""
根据 PROVIDER 将 DeepSeek / Qwen 映射为 OpenAI 兼容环境变量,
方便 CrewAI 和 langchain-openai 直接使用。
"""
if PROVIDER.lower() == "deepseek":
ds_key = os.getenv("DEEPSEEK_API_KEY", "")
ds_base = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com/v1")
if not ds_key:
raise RuntimeError("未找到 DEEPSEEK_API_KEY,请在 .env 中配置。")
# 映射到 OpenAI 兼容变量
os.environ["OPENAI_API_KEY"] = ds_key
os.environ["OPENAI_BASE_URL"] = ds_base
os.environ["OPENAI_MODEL_NAME"] = "deepseek-chat"
logging.info("已使用 DeepSeek 作为底层 LLM(OpenAI 兼容模式)。")
elif PROVIDER.lower() == "qwen":
qwen_key = os.getenv("QWEN_API_KEY") or os.getenv("DASHSCOPE_API_KEY", "")
qwen_base = os.getenv(
"QWEN_BASE_URL",
"https://dashscope.aliyuncs.com/compatible-mode/v1"
)
if not qwen_key:
raise RuntimeError("未找到 QWEN_API_KEY 或 DASHSCOPE_API_KEY,请在 .env 中配置。")
os.environ["OPENAI_API_KEY"] = qwen_key
os.environ["OPENAI_BASE_URL"] = qwen_base
os.environ["OPENAI_MODEL_NAME"] = "qwen-omni-turbo"
logging.info("已使用 Qwen 作为底层 LLM(OpenAI 兼容模式)。")
else:
raise ValueError(f"未知 PROVIDER: {PROVIDER}")
# 在定义 Agent 之前先设置好环境
setup_llm_env()
# =========================================================
# 3. 工具定义:股票价格查询(本地模拟)
# =========================================================
@tool("Stock Price Lookup Tool")
def get_stock_price(ticker: str) -> float:
"""
获取指定股票代码的【模拟】最新股价。
参数:
ticker: 股票代码,例如 "AAPL"、"GOOGL"。
返回:
股票价格(float)。
说明:
- 如果找不到该代码,将抛出 ValueError。
- 这里使用的是本地模拟数据,真实项目中可以改成调用行情 API。
"""
logging.info(f"Tool Call: get_stock_price for ticker '{ticker}'")
simulated_prices = {
"AAPL": 178.15,
"GOOGL": 1750.30,
"MSFT": 425.50,
}
price = simulated_prices.get(ticker.upper())
if price is not None:
return price
else:
# 抛出明确错误,交给 Agent 自己决定怎么描述给用户
raise ValueError(f"Simulated price for ticker '{ticker.upper()}' not found.")
# =========================================================
# 4. 定义智能体(Agent)
# =========================================================
financial_analyst_agent = Agent(
role='资深金融分析师',
goal='使用提供的工具分析股票数据,并报告关键股价信息。',
backstory=(
"你是一名经验丰富的金融分析师,擅长使用多种数据来源获取股票信息,"
"并用简洁清晰的语言向非专业人士解释结果。"
),
verbose=True,
tools=[get_stock_price],
allow_delegation=False,
)
# =========================================================
# 5. 定义任务(Task)
# =========================================================
analyze_aapl_task = Task(
description=(
"请查询苹果公司(股票代码:AAPL)当前的【模拟股价】是多少。\n"
"必须调用工具 'Stock Price Lookup Tool' 来获取价格。\n"
"如果工具抛出错误或找不到该股票代码,你需要明确说明无法获取价格。"
),
expected_output=(
"输出一条简洁的中文句子,说明 AAPL 的模拟股价。\n"
"例如:“AAPL 的模拟股价为 178.15 美元。”\n"
"如果无法获取价格,则需要明确说明原因。"
),
agent=financial_analyst_agent,
)
# =========================================================
# 6. 组装 Crew(相当于一个“小团队”)
# =========================================================
financial_crew = Crew(
agents=[financial_analyst_agent],
tasks=[analyze_aapl_task],
verbose=True # 需要少一点日志可以改为 False
)
# =========================================================
# 7. 主入口:运行 Crew
# =========================================================
def main():
"""运行股票分析 Crew 的主函数。"""
# 这里再检查一次,防止上面环境未正确设置
if not os.environ.get("OPENAI_API_KEY"):
print("ERROR: OPENAI_API_KEY 环境变量未设置。")
print("请在 .env 中配置 DEEPSEEK_API_KEY 或 QWEN_API_KEY,并确保 PROVIDER 设置正确。")
return
print("\n## 启动金融分析 Crew ...")
print("---------------------------------")
# kickoff 会调用 Agent,执行 Task,并自动使用工具
result = financial_crew.kickoff()
print("\n---------------------------------")
print("## Crew 执行结束。")
print("\n最终结果:\n", result)
if __name__ == "__main__":
main()
运行输出:
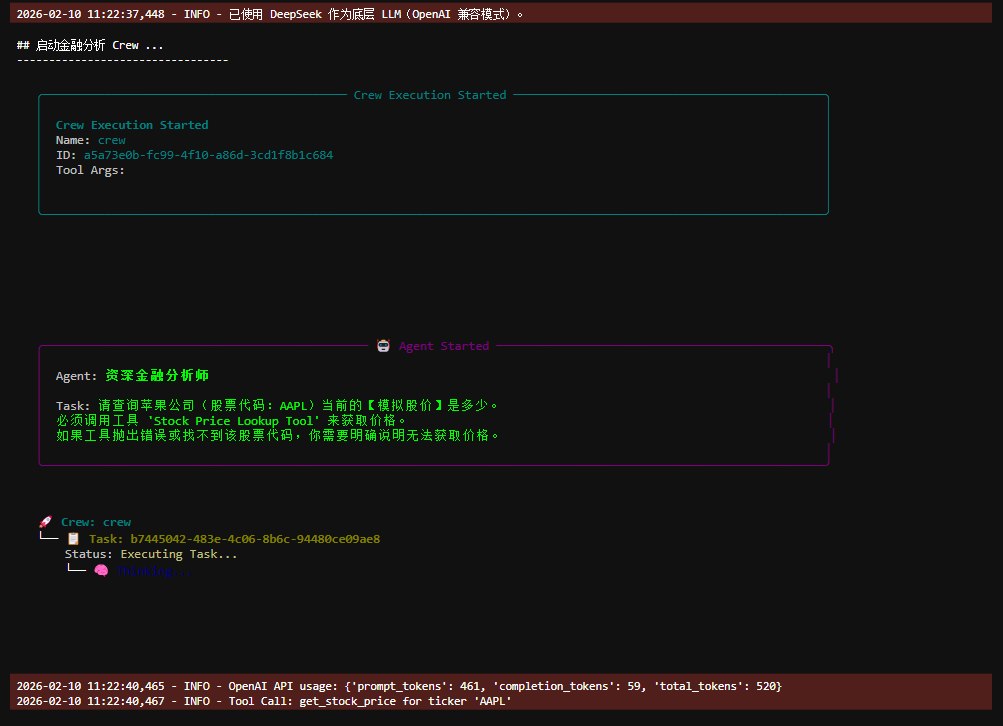
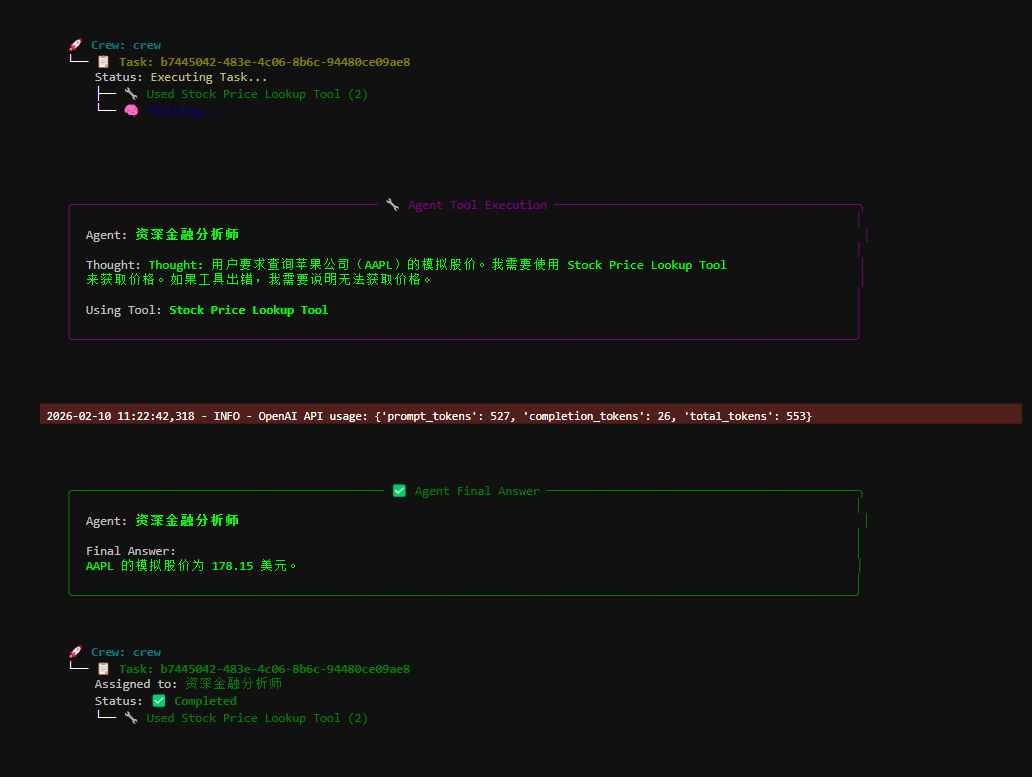
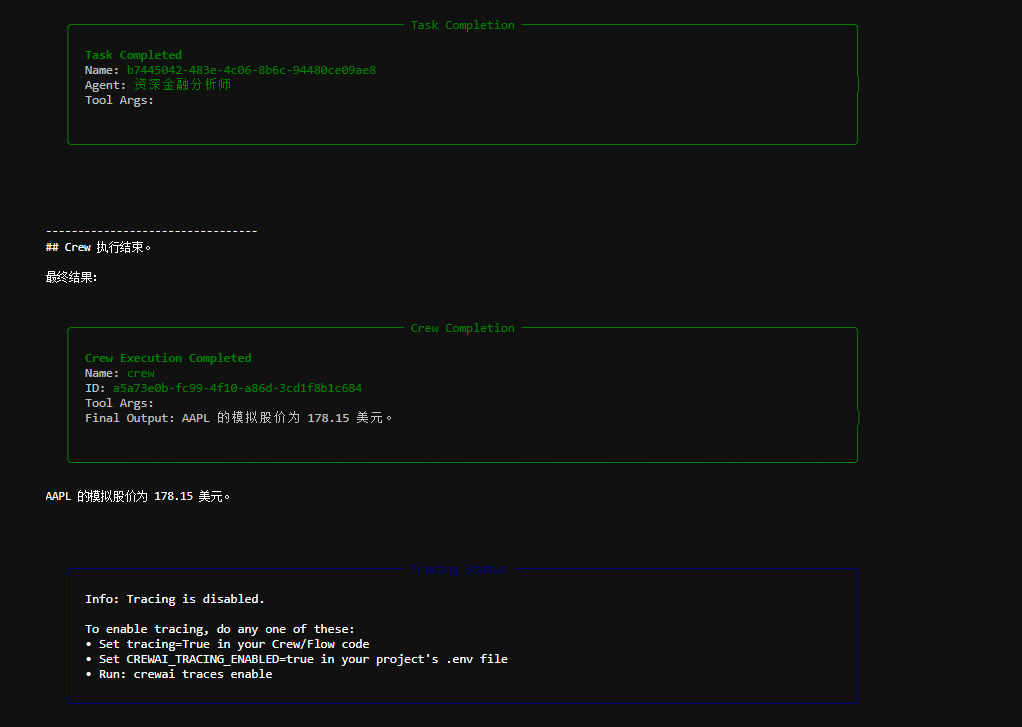
上面这段代码整体是在用 CrewAI 框架搭一个“单智能体 + 工具”的最小示例,目标是:让一个金融分析师智能体,学会调用一个股票查询工具,完成指定的分析任务。它展示的是 CrewAI 的完整标准用法闭环。
执行流程:
- 初始化阶段
-
加载 .env
-
根据 PROVIDER(DeepSeek / Qwen)设置 OpenAI 兼容环境变量
-
定义工具 get_stock_price、Agent、Task,并组装成 Crew
- 推理 + 工具调用阶段
-
调用 financial_crew.kickoff()
-
Agent 读取 Task,LLM 判断需要获取股票价格
-
CrewAI 自动调用工具 get_stock_price(“AAPL”) 获取模拟股价
- 结果生成阶段
-
工具返回股价数据
-
LLM 基于工具结果生成中文结论
-
Crew 汇总并返回最终结果给 main()
这是一个用 CrewAI 搭的“小型智能体团队”(实际上只有 1 个 Agent),该 Agent 配有一个股票价格查询工具,在 LLM(DeepSeek / Qwen)的驱动下,自动调用工具并完成任务。
Agent / Tool / LLM 执行流程图
┌────────────────────────┐
│ main() │
│ financial_crew.kickoff│
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ Crew │
│ (任务调度 / 流程控制) │
└───────────┬────────────┘
│ 分配 Task
▼
┌────────────────────────┐
│ Agent │
│ 资深金融分析师 │
│ role / goal / tools │
└───────────┬────────────┘
│ 读取 Task
▼
┌────────────────────────┐
│ LLM │
│ DeepSeek / Qwen │
│ 推理:需要股票价格? │
└───────────┬────────────┘
│ 是,需要工具
▼
┌────────────────────────┐
│ Tool │
│ get_stock_price("AAPL")│
│ 本地模拟 / 外部 API │
└───────────┬────────────┘
│ 返回价格
▼
┌────────────────────────┐
│ LLM │
│ 基于工具结果生成回答 │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ Crew │
│ 汇总最终结果 │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 输出结果 │
│ “AAPL 的模拟股价为 …” │
└────────────────────────┘
实战代码:使用 ADK
import os
import asyncio
import nest_asyncio
from dataclasses import dataclass
from typing import Any, Dict, List, AsyncGenerator, Callable
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# =========================================================
# 1. 事件结构:模仿 ADK 的 Event
# =========================================================
@dataclass
class Event:
"""简单事件结构,用于在 Runner 中传递过程信息。"""
type: str # 如: "thought", "tool_call", "tool_result", "final_response"
content: str # 文本内容(给人看的)
data: Dict[str, Any] = None # 可选数据(给程序用)
def is_final_response(self) -> bool:
"""是否为最终回复事件。"""
return self.type == "final_response"
# =========================================================
# 2. 会话服务:简单版 InMemorySessionService
# =========================================================
class InMemorySessionService:
"""
用内存保存每个 session 的历史消息:
key: (app_name, user_id, session_id)
value: List[{"role": "user"/"assistant"/"system", "content": "...."}]
"""
def __init__(self):
self._sessions: Dict[str, List[Dict[str, str]]] = {}
def _make_key(self, app_name: str, user_id: str, session_id: str) -> str:
return f"{app_name}:{user_id}:{session_id}"
async def get_or_create_session(
self,
app_name: str,
user_id: str,
session_id: str
) -> List[Dict[str, str]]:
key = self._make_key(app_name, user_id, session_id)
if key not in self._sessions:
self._sessions[key] = []
return self._sessions[key]
# =========================================================
# 3. 工具定义示例:一个“模拟新闻搜索”工具
# =========================================================
def web_search(query: str) -> str:
"""
一个非常简单的“模拟搜索工具”。
真正项目中你可以:
- 调 REST API
- 调用你自己的 RAG 系统
- 查数据库 等等
"""
print(f"[工具调用] web_search('{query}')")
q = query.lower()
if "ai" in q and "news" in q:
return (
"模拟搜索结果:近期 AI 新闻包括:"
"1) 多家厂商发布新一代大语言模型;"
"2) 各国监管机构讨论 AI 合规与安全;"
"3) AIGC 在游戏、教育和影视领域应用持续扩大。"
)
return f"模拟搜索结果:关于「{query}」的一些相关新闻,这里略去具体条目。"
# =========================================================
# 4. Agent:负责调用 LLM + 工具
# =========================================================
class Agent:
def __init__(
self,
name: str,
model: ChatOpenAI,
instruction: str,
tools: Dict[str, Callable[[str], str]],
description: str = "",
):
self.name = name
self.model = model
self.instruction = instruction
self.description = description
self.tools = tools # 形如 {"web_search": web_search}
async def _call_llm(self, messages: List[Dict[str, str]]) -> str:
"""封装新版 ChatOpenAI 的 ainvoke 调用。"""
resp = await self.model.ainvoke(messages)
return resp.content
async def run(
self,
user_query: str,
history: List[Dict[str, str]],
) -> AsyncGenerator[Event, None]:
"""
核心逻辑:
1)根据用户问题 + 指令,让模型决定要不要用工具
2)如果用工具:调用工具,再让模型基于结果回答
3)中间过程通过 Event 逐步产出
"""
# 1. 把这轮用户问题加入历史
history.append({"role": "user", "content": user_query})
# 2. 问模型:“需不需要用工具?”
system_prompt = (
f"你是一个具备外部工具调用能力的智能体,名字是 {self.name}。\n"
f"你的职责:{self.instruction}\n\n"
"你拥有以下工具:\n"
"- web_search(query: str):用于获取互联网上与新闻、实时信息相关的内容。\n\n"
"决策规则:\n"
"1)如果用户的问题涉及“最新、近期、今天、现在”等时效性较强的信息,"
" 请使用 web_search 工具。\n"
"2)否则,可以直接回答。\n\n"
"当你决定使用工具时,必须严格按以下格式输出(不能多字):\n"
"TOOL: web_search\n"
"QUERY: <你要查询的关键词,可以是中文或英文>\n\n"
"如果你不打算用工具,就直接用自然语言回答用户。"
)
decision_messages: List[Dict[str, str]] = [
{"role": "system", "content": system_prompt},
*history, # 包含之前轮次(当前只有一轮)
]
decision_text = await self._call_llm(decision_messages)
yield Event(
type="thought",
content=f"模型决策输出:{decision_text}",
data={"raw": decision_text},
)
lower = decision_text.strip().lower()
# 3. 如果模型选择调用工具
if lower.startswith("tool:"):
# 解析格式:
# TOOL: web_search
# QUERY: xxx
lines = [l for l in decision_text.split("\n") if l.strip()]
tool_name = lines[0].split(":", 1)[1].strip()
tool_query = lines[1].split(":", 1)[1].strip()
yield Event(
type="tool_call",
content=f"调用工具 {tool_name},查询:{tool_query}",
data={"tool": tool_name, "query": tool_query},
)
if tool_name not in self.tools:
# 工具不存在,直接 fallback
final_answer = await self._call_llm([
{"role": "system", "content": "你想调用一个不存在的工具,请直接用常识回答用户。"},
{"role": "user", "content": user_query},
])
history.append({"role": "assistant", "content": final_answer})
yield Event(
type="final_response",
content=final_answer,
data={"from_tool": False},
)
return
# 真正调用工具
tool_fn = self.tools[tool_name]
tool_result = tool_fn(tool_query)
yield Event(
type="tool_result",
content=f"工具 {tool_name} 返回结果:{tool_result}",
data={"result": tool_result},
)
# 再让模型基于工具结果生成最终回答
final_messages: List[Dict[str, str]] = [
{"role": "system", "content": "你是一个会根据外部搜索结果进行总结的中文智能助手。"},
{"role": "assistant", "content": f"以下是工具返回的内容:{tool_result}"},
{"role": "user", "content": f"请结合以上内容,回答我的问题:{user_query}"},
]
final_answer = await self._call_llm(final_messages)
history.append({"role": "assistant", "content": final_answer})
yield Event(
type="final_response",
content=final_answer,
data={"from_tool": True},
)
else:
# 4. 不用工具,直接回答
final_answer = decision_text
history.append({"role": "assistant", "content": final_answer})
yield Event(
type="final_response",
content=final_answer,
data={"from_tool": False},
)
# =========================================================
# 5. Runner:类似 ADK Runner,负责调 Agent + Session
# =========================================================
class Runner:
def __init__(
self,
agent: Agent,
app_name: str,
session_service: InMemorySessionService,
):
self.agent = agent
self.app_name = app_name
self.session_service = session_service
async def run(
self,
user_id: str,
session_id: str,
user_query: str,
) -> AsyncGenerator[Event, None]:
history = await self.session_service.get_or_create_session(
app_name=self.app_name,
user_id=user_id,
session_id=session_id,
)
async for event in self.agent.run(user_query=user_query, history=history):
yield event
# =========================================================
# 6. 模型初始化(DeepSeek / Qwen 二选一)
# =========================================================
def init_llm_from_env(provider: str) -> ChatOpenAI:
load_dotenv()
if provider.lower() == "deepseek":
api_key = os.getenv("DEEPSEEK_API_KEY")
base_url = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com/v1")
if not api_key:
raise RuntimeError("未找到 DEEPSEEK_API_KEY,请在 .env 中配置")
print("使用 DeepSeek 作为底层模型")
return ChatOpenAI(
model="deepseek-chat",
api_key=api_key,
base_url=base_url,
temperature=0,
)
elif provider.lower() == "qwen":
api_key = os.getenv("QWEN_API_KEY") or os.getenv("DASHSCOPE_API_KEY")
base_url = os.getenv(
"QWEN_BASE_URL",
"https://dashscope.aliyuncs.com/compatible-mode/v1",
)
if not api_key:
raise RuntimeError("未找到 QWEN_API_KEY 或 DASHSCOPE_API_KEY,请在 .env 中配置")
print("使用 Qwen 作为底层模型")
return ChatOpenAI(
model="qwen-omni-turbo",
api_key=api_key,
base_url=base_url,
temperature=0,
)
else:
raise ValueError(f"未知 provider: {provider}")
# =========================================================
# 7. 示例主流程:类似 ADK 的 call_agent
# =========================================================
APP_NAME = "DeepSeek_Qwen_ADK_Replacement"
USER_ID = "user1234"
SESSION_ID = "session-001"
async def main():
# 选择使用 deepseek 或 qwen
provider = "deepseek" # 改成 "qwen" 即可切换
llm = init_llm_from_env(provider)
# 创建 Agent
root_agent = Agent(
name="search_agent",
model=llm,
instruction="你可以使用 web_search 工具获取最新新闻,然后用中文总结给用户。",
description="一个通过搜索工具回答问题的智能体。",
tools={"web_search": web_search},
)
# 创建 SessionService 和 Runner
session_service = InMemorySessionService()
runner = Runner(agent=root_agent, app_name=APP_NAME, session_service=session_service)
# 调用一次(你可以改成多轮)
query = "最近的人工智能新闻有哪些?"
events = runner.run(
user_id=USER_ID,
session_id=SESSION_ID,
user_query=query,
)
async for event in events:
if event.type == "thought":
print(f"[过程] {event.content}")
elif event.type == "tool_call":
print(f"[工具调用] {event.content}")
elif event.type == "tool_result":
print(f"[工具结果] {event.content}")
elif event.is_final_response():
print("\n[最终回复]")
print(event.content)
# 在 Notebook 中使用 nest_asyncio 以避免事件循环冲突
nest_asyncio.apply()
asyncio.run(main())
运行输出:

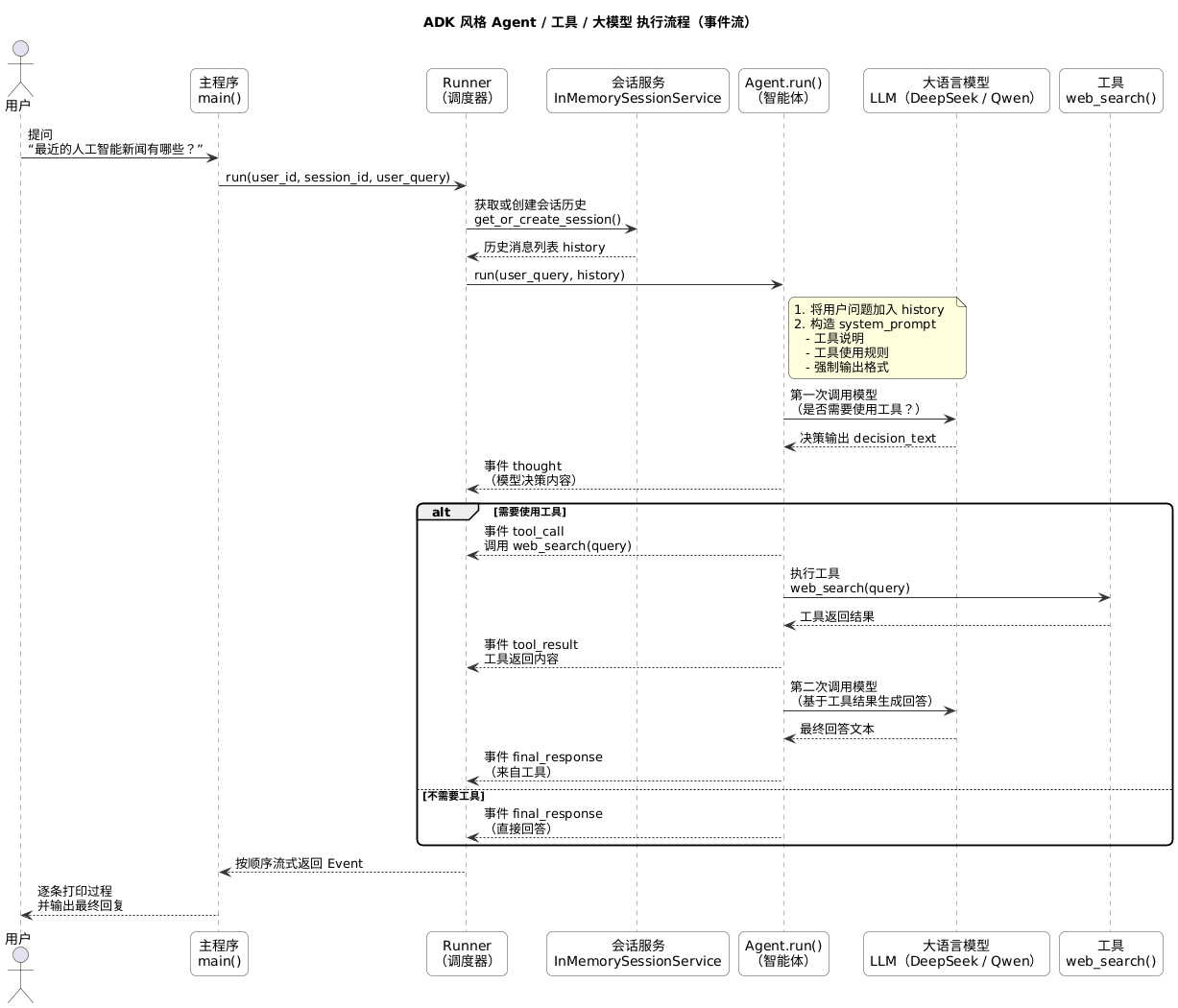
这段代码整体是用 LangChain 的 ChatOpenAI 自己手写一个类似 ADK(Agent Development Kit) 的 Runner + Session + Event 流式执行框架,让一个 Agent 能根据问题决定要不要调用工具(这里是模拟 web_search),并把过程事件一条条产出给外部打印。
模块分块说明
- Event:过程事件结构(模仿 ADK Event)
Event 是一个 dataclass,用来把执行过程“包装成事件流”:
-
type:事件类型(thought/tool_call/tool_result/final_response)
-
content:给人看的文字
-
data:给程序用的结构化数据(可选)
-
is_final_response():判断是不是最终输出事件
目的:把 Agent 的执行过程变成可观察、可流式消费的事件序列。
- InMemorySessionService:内存会话历史(模仿 ADK 的 session)
它用一个 dict 存每个会话的消息列表:
-
key:app_name:user_id:session_id
-
value:[{role, content}, …]
get_or_create_session() 会拿到该 session 的 history,没有就创建空列表。
目的:多轮对话能记住历史(虽然 demo 只跑一轮,但结构是多轮可用的)。
- 工具 web_search:模拟“外部世界能力”
web_search(query) 是一个假工具:
-
如果 query 里包含 “ai” 和 “news” 就返回固定的模拟新闻条目
-
否则返回通用模拟结果
目的:演示 工具调用接口长什么样,真实项目可替换成:
-
搜索 API
-
RAG 检索
-
数据库查询等
- Agent:核心,负责 LLM 决策 + 工具调用 + 总结
Agent 的核心逻辑在 run(),它是一个 AsyncGenerator[Event],会一路 yield 事件:
执行顺序是:
-
把用户问题追加到 history
-
构造 system prompt:告诉模型什么时候必须用工具,并规定输出格式:
TOOL: web_search
QUERY: ...
-
调一次 LLM 得到 decision_text
- 先 yield 一个 thought 事件,记录模型决策输出
-
如果 decision 以 TOOL: 开头:
-
解析 tool_name 和 tool_query
-
yield tool_call
-
执行 tool_fn(tool_query) 得到 tool_result
-
yield tool_result
-
再调一次 LLM,让模型基于工具结果生成最终回答
-
yield final_response(from_tool=True)
-
否则:
-
直接把 decision_text 当最终答案
-
yield final_response(from_tool=False)
一句话:这是“文本协议式 tool calling”的两段式闭环:先决策,再执行工具,再总结。
- Runner:把 Agent + Session 串起来(模仿 ADK Runner)
Runner 的 run():
-
先从 session_service 拿到当前会话的 history
-
再 async for event in agent.run(…): yield event
目的:让外部调用者只关心 Runner,就能拿到事件流。
- init_llm_from_env:DeepSeek / Qwen 二选一
和你前面例子类似:
-
从 .env 读 key/base_url
-
返回 ChatOpenAI(model=…, api_key=…, base_url=…, temperature=0)
目的:用 OpenAI-compat 的方式切换供应商。
- main:演示一次调用,并消费事件流打印
-
创建 LLM
-
创建 Agent(带 web_search 工具)
-
创建 SessionService 和 Runner
-
runner.run(…) 得到事件生成器
-
async for event in events: 按类型打印过程与最终回复
最后 nest_asyncio.apply() + asyncio.run(main()):
- 主要是为了在 Notebook/Jupyter 环境避免事件循环冲突。
一句话总结:
这段代码是在用 LangChain 的 ChatOpenAI 手写一个“ADK 风格”的 Agent 执行框架:
Runner 管会话与调度,Agent 管决策与工具调用,Event 把全过程变成可流式输出的事件流。
要点速览
问题所在:大语言模型是强大的文本生成器,但它们本质上与外部世界脱节。它们的知识是静态的,仅限于训练时所用的数据,并且缺乏执行操作或检索实时信息的能力。这种固有的局限性使它们无法完成需要与外部接口、数据库、服务进行交互的任务。如果没有连接这些外部系统的桥梁,它们在解决实际问题的能力将大打折扣。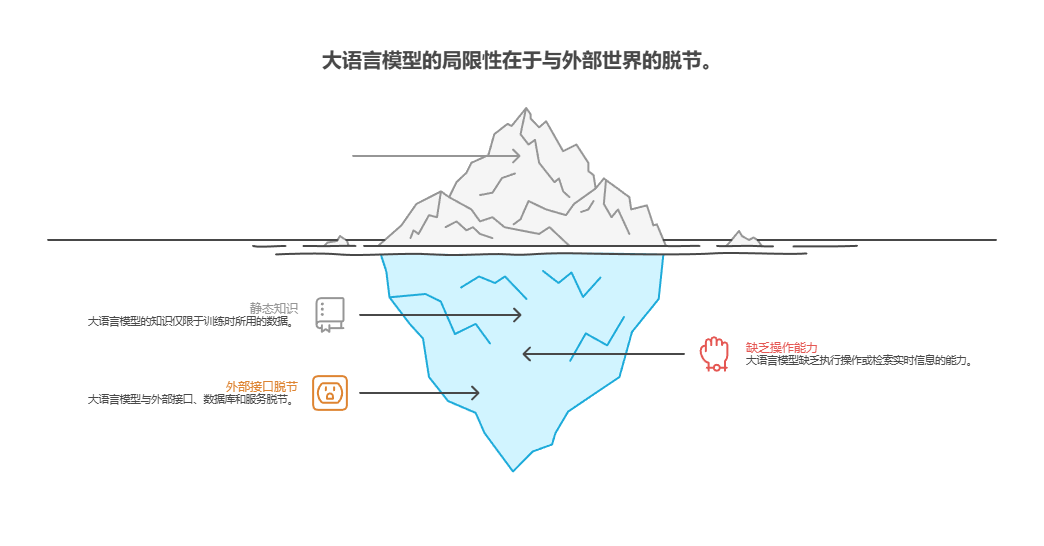
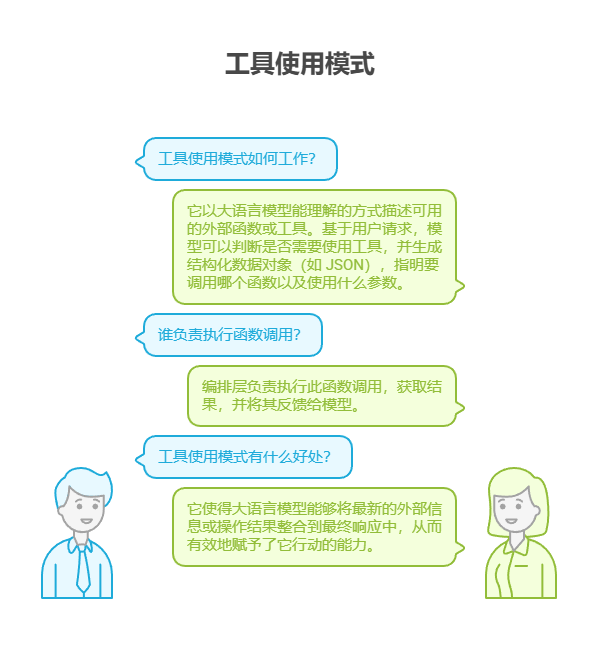
解决之道:工具使用模式(通常通过函数调用机制实现)为这个问题提供了标准化解决方案。它的工作原理是,以大语言模型能理解的方式向其描述可用的外部函数或工具。基于用户请求,具有智能能力的模型可以判断是否需要使用工具,并生成结构化数据对象(如 JSON),指明要调用哪个函数以及使用什么参数。编排层负责执行此函数调用,获取结果,并将其反馈给模型。这使得大语言模型能够将最新的外部信息或操作结果整合到最终响应中,从而有效地赋予了它行动的能力。
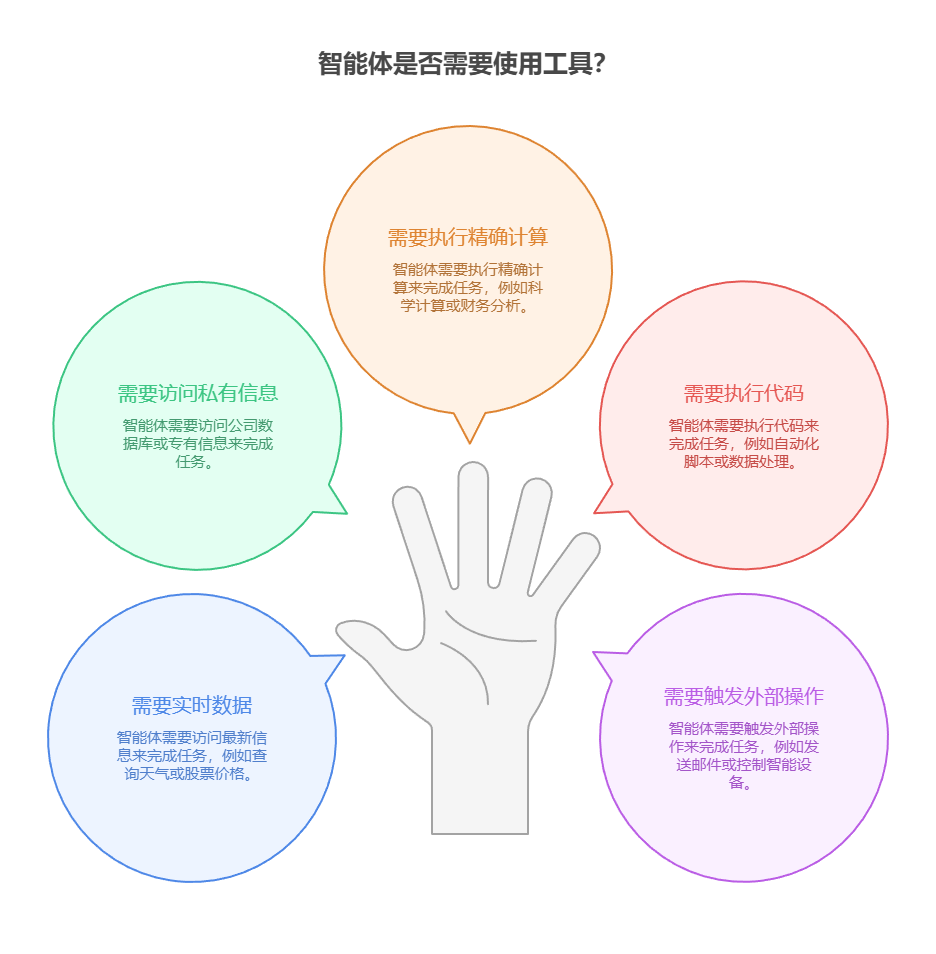
经验法则:当智能体需要突破大语言模型内部知识局限并与外部世界互动时,就应该使用工具使用模式。这对于需要实时数据(如查询天气、股票价格)、访问私有或专有信息(如查询公司数据库)、执行精确计算、执行代码或在其他系统中触发操作(如发送邮件、控制智能设备)的任务至关重要。
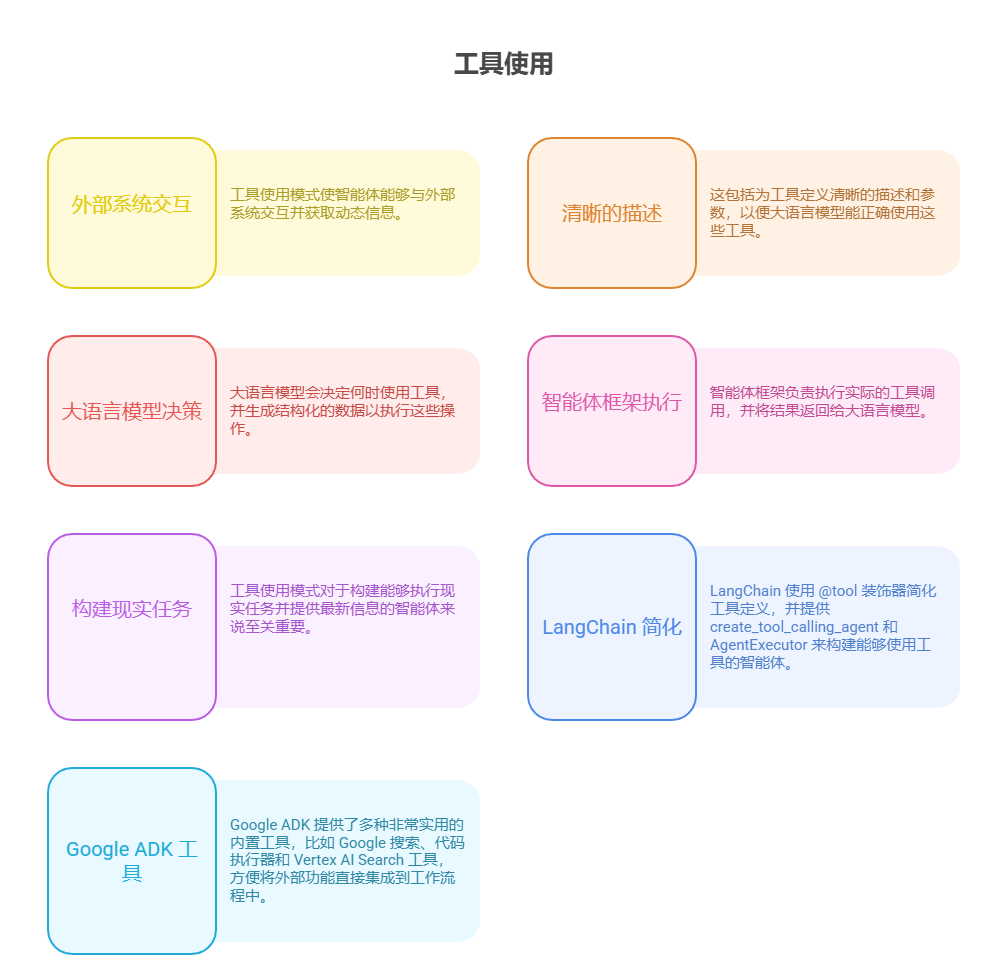
可视化总结: 工具使用模式
核心要点
-
工具使用(函数调用)模式使智能体能够与外部系统交互并获取动态信息。
-
这包括为工具定义清晰的描述和参数,以便大语言模型能正确使用这些工具。
-
大语言模型会决定何时使用工具,并生成结构化的数据以执行这些操作。
-
智能体框架负责执行实际的工具调用,并将结果返回给大语言模型。
-
工具使用模式对于构建能够执行现实任务并提供最新信息的智能体来说至关重要。
-
LangChain 使用 @tool 装饰器简化工具定义,并提供 create_tool_calling_agent 和 AgentExecutor 来构建能够使用工具的智能体。
-
Google ADK 提供了多种非常实用的内置工具,比如 Google 搜索、代码执行器和 Vertex AI Search 工具,方便将外部功能直接集成到工作流程中。
结语
工具使用模式是一种重要的架构原则,用于把大型语言模型的能力扩展到纯文本生成之外。通过让模型能够与外部软件和数据源对接,这一模式使得智能体可以执行操作、完成计算以及从其他系统获取信息。当模型判断需要调用外部工具来满足用户请求时,它会生成一个结构化的调用请求。
像 LangChain、Google ADK 和 Crew AI 这样的框架提供了便于集成外部工具的抽象层和组件,负责向模型暴露工具的定义并解析模型返回的工具调用请求。总体而言,这大大简化了能够在外部数字环境中感知、交互和行动的复杂智能体系统的开发。

参考文献
暂时先这样吧,如果实在看不明白就留言,看到我会回复的。希望这个教程对您有帮助!
路漫漫其修远,与君共勉。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)