AI与数据工程:数据工程师的角色到底发生了什么变化
AI与数据工程:数据工程师的角色到底发生了什么变化
摘要:本文讨论 AI 正在如何改变数据工程师的职责边界。亮点在于把“更快产出”和“更难负责”的张力讲清:schema、质量、性能与对齐依旧需要人决策。适合做职业与架构复盘的读者。
1、引言
1.1 核心观点
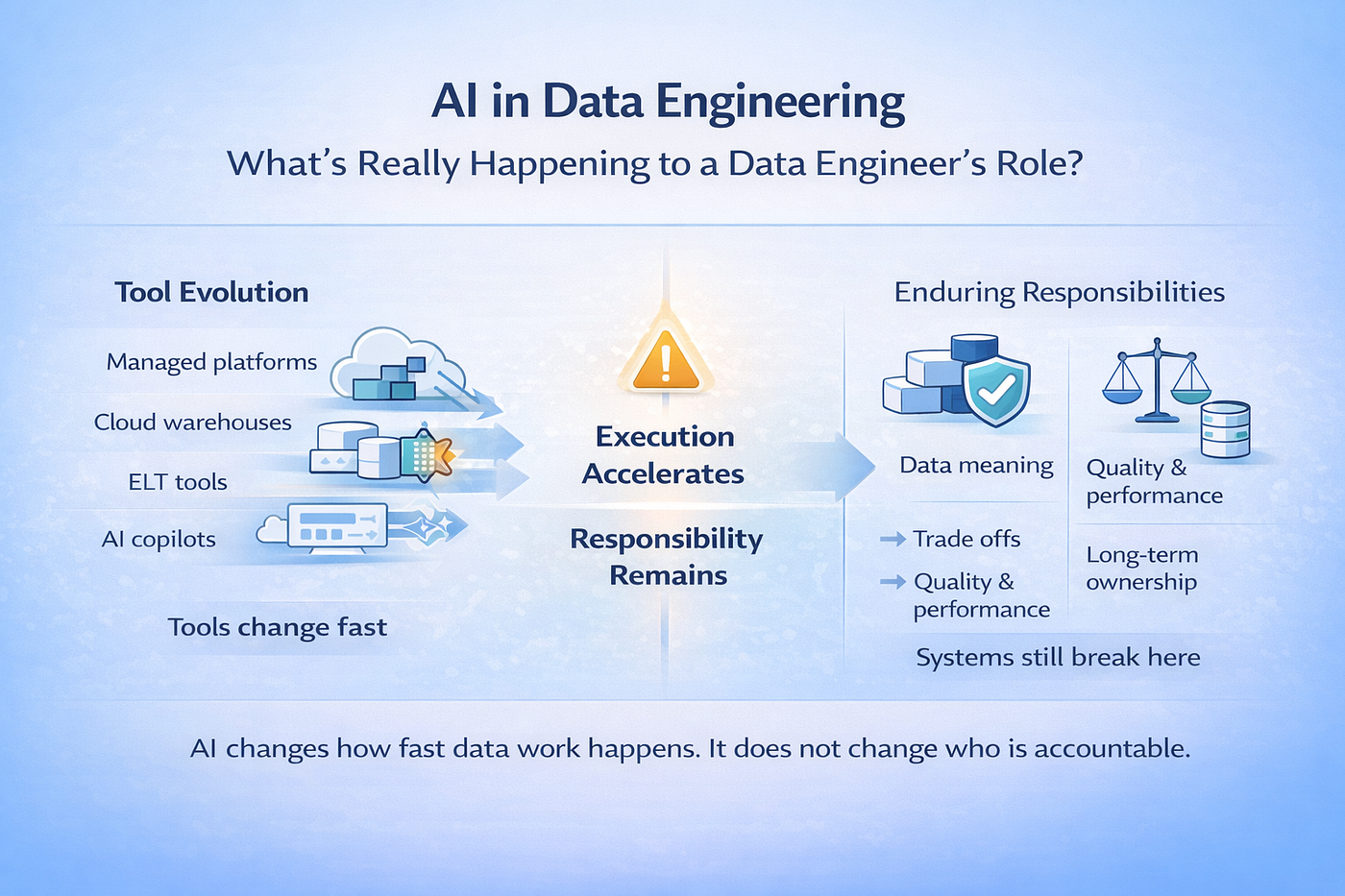
AI 并没有把数据工程师从闭环中移除。它把这个角色拉得更靠近那些会带来真实后果的决策。本文解释这种变化对你的角色意味着什么,不是从头衔或工具的角度,而是从责任的角度。
每隔几年,数据工程师的角色就会被宣告“过时”。托管 Hadoop 本来被认为能移除运维复杂度。云数据仓库承诺能消除基础设施层面的担忧。ELT 工具把流水线变成配置。现在,人们又期待 AI copilot 彻底完成这件事,让这个角色本身都变得不必要。预测一直在变,但工作没有变。
即便平台在变化、厂商名字在轮换,数据系统的底层约束依然顽固地保持一致。数据仍然需要结构;仍然需要校验;仍然需要能在规模上被查询;仍然需要支撑真实企业做出的真实决策。炒作周期很快,但基本面很慢。
AI 在数据工程中擅长产出输出,但“所有权”仍然在别处。上下文不住在 prompt 里。权衡不能从语法里被推断出来。长期责任从自动化停止的地方开始。
大多数数据系统失败,并不是因为代码很难写。它们失败,是因为决策做得太快,却没有弄清楚未来会由谁来依赖这些决策。AI 通过压缩时间改变了这一动态。相同的选择仍然会被做出,只是更快,而它们的影响会传播得更远。
这些失败点并不新。它们在今天这些工具出现之前就存在,并且在它们之后也会继续存在。AI 改变了数据工作的节奏,但它不改变系统通常会在哪里破裂。
摆在数据工程师面前的问题不再是 AI 是否会改变工作;它已经改变了。更有用的问题是:数据工程师这个角色里,哪些部分从来就不是“执行”,以及为什么这些部分现在比以往更显眼。
接下来的章节会讨论:什么在变化,什么没有变化,以及当 AI 被嵌入工作流时,数据工程师的角色正在如何变化。
AI 并没有取代数据工程师。它在暴露出这份工作里哪些部分从来就不是可选项。AI 改变了数据工作的节奏,但数据工程师责任的边界仍然与过去完全一致。
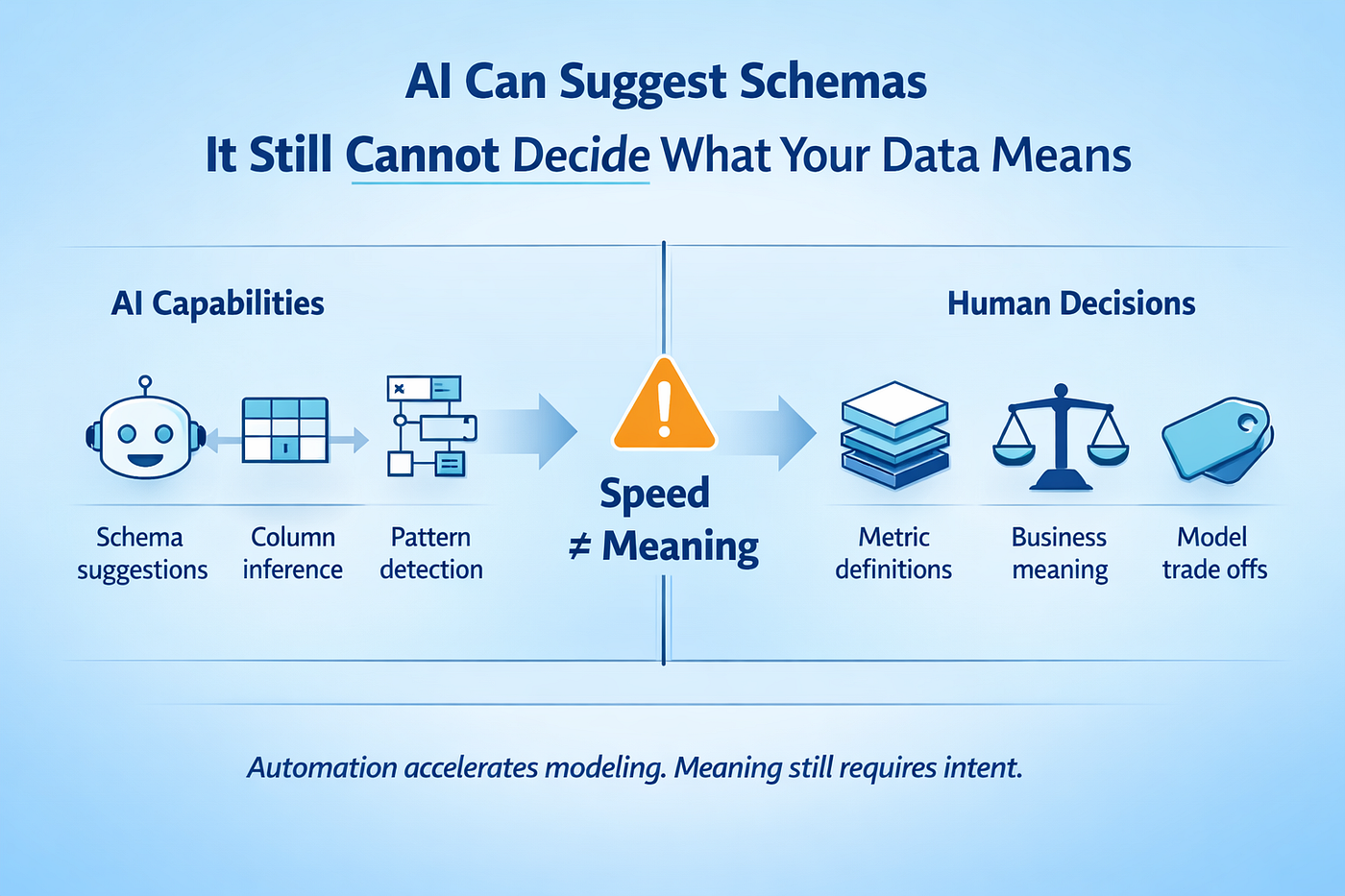
2、AI 在数据工程中可以建议 Schema,但无法决定数据的含义
2.1 现实背景
现代数据平台让 schema 创建变得很容易。表可以立刻生成。列可以被推断。关系可以根据观察到的使用方式被猜测。但这些都不能解决歧义。
随着时间推移,数据建模 从严格的规范化转向更务实的结构。快照表替代缓慢变化维度。分区事实表与覆盖策略简化历史处理。这些模式存在,是因为它们在保留分析可用性的同时,降低了运维负担。
AI 在数据工程中很好地契合了这一趋势。schema 建议能更快浮现。列分组可以从查询模式中被推断。异常与不一致能在向下游模型传播之前被标记出来。AI 在数据工程中的加速是真实的,但“理解”不是。
任何宣称智能的系统仍然依赖显式的含义。语义层必须存在于某个地方。指标定义需要一致同意。历史需要被声明成某种形状。关于粒度、归属与解释的决策,必须在自动化变得有用之前就被做出。AI 可以提出选项,但它无法裁决权衡。
正确性 vs 灵活性。性能 vs 通用性。简单性 vs 表达力。这些决策由业务上下文、数据规模,以及 6 个月后数据会如何被消费所塑造。默认情况下,没有任何一个 prompt 包含这些上下文。
在星型 schema 与宽表之间做选择,重要性不如模型背后的目的清晰。AI 降低了产出时间,但上下文决定了产出在真实生产工作负载下是否仍然有用。
3、AI 在数据工程中的真正风险是不完整的数据
3.1 风险描述
现代数据生态会放大小错误。组织接入更多来源时,定义会倍增。流水线增长时,转换路径会分叉。消费者增加时,解释会漂移。数据质量问题很少以明显故障的形式到来;它们会以细微不一致的形式出现,并在系统中悄悄复利式累积。
AI 在数据工程中改善检测:异常会更快被标记;校验规则可以自动生成;分布漂移能在仪表盘崩溃前被发现。可见性提高了,但含义没有。
记录可以在技术上正确,但仍然不可用:没有时间戳的交易、没有地区的客户、没有分类的产品。schema 检查通过了,但空值阈值仍在限制内。决策就会停滞。用不完整数据训练的 AI 系统会毫不犹豫地继承这些缺口。模型会自信地在“部分现实”上做优化,强化那些在采集点从未被验证的假设。这就是数据工程师的工作仍然必不可少的地方。
质量不是在下游强制出来的,而是在上游被设计进去的。字段选择、定义对齐与归属清晰度,决定了数据是否能支撑未来的问题。有些属性无论处理层多先进,之后都无法被重建。
AI 加速了反馈回路,但也加速了歧义的成本。没有有意的捕获与校验,不确定性会原封不动地向下游流动,只是现在速度更快、规模更大。

4、AI 能写查询,但无法让仪表盘始终快速
4.1 性能不会自动保持
仪表盘很少在上线时就很慢,但性能退化会悄悄发生。随着使用增长,筛选扩展,join 累积,访问模式漂移。曾经几秒返回的查询会拖到几分钟,不是因为系统坏了,而是因为假设过期了。
AI 在数据工程中改善查询生成。SQL 可以立刻写出来,执行计划可以被自动分析,优化建议能比以前更快浮现。速度改善了,但稳定性不会自己保证。
索引仍然需要被刻意选择。当查询模式稳定下来时,预聚合表仍然重要。物化视图仍然存在,是因为工作负载会以可预测的方式重复。弹性算力会暂时掩盖低效,直到成本把它们暴露出来。性能仍然是设计问题,不是语法问题。
理解数据如何被访问,比查询能多快被产出更重要。随着消费方式演变,性能需要干预。AI 加速迭代,但它不阻止性能漂移。
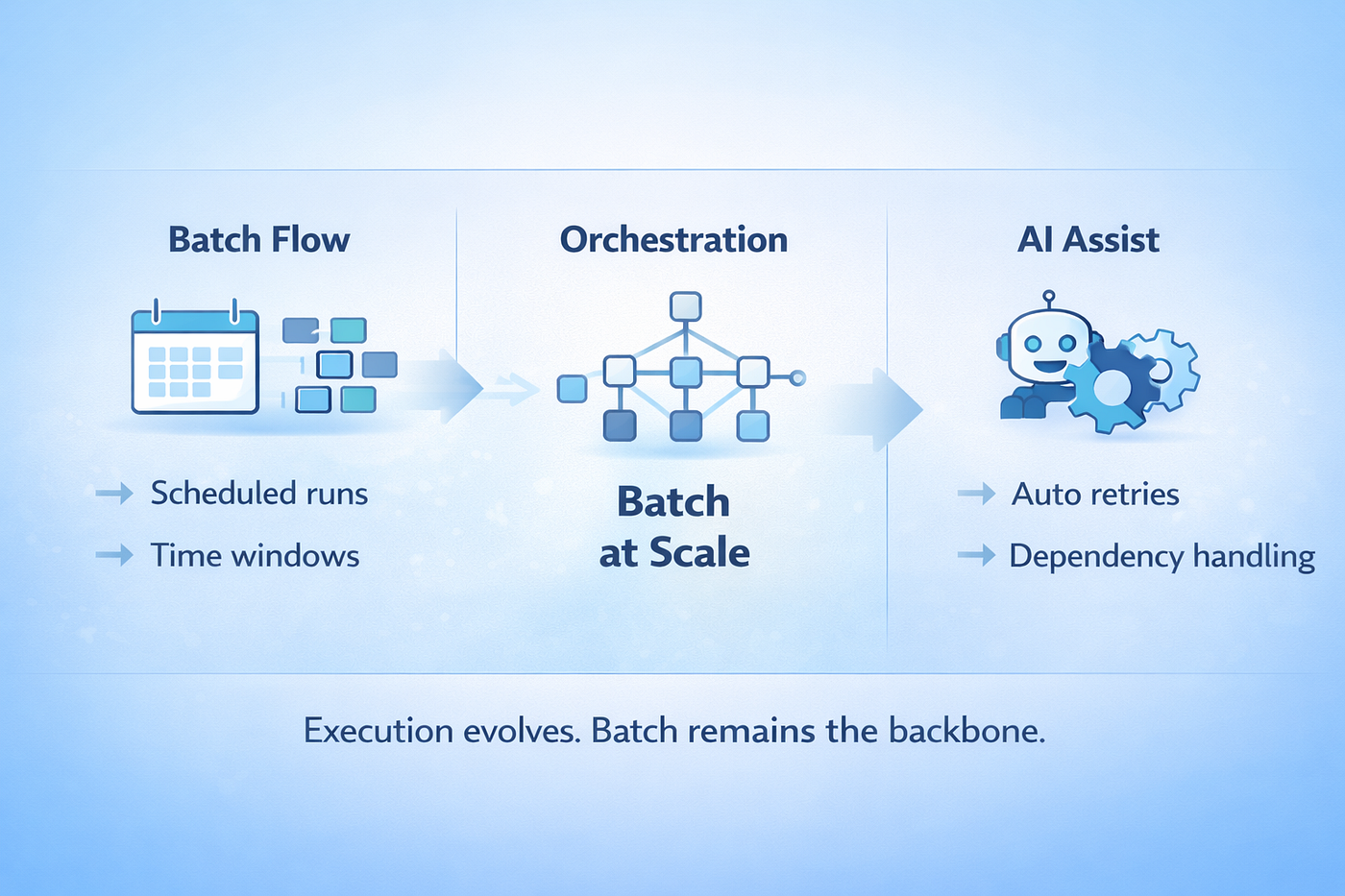
5、AI 没有杀死批处理,但强化了它
5.1 批处理仍是主流执行模式
数据流水线数量已经爆炸。大型组织经常运行数百甚至数千个工作流。编排平台存在,是因为多年前手动协调就不再可扩展。AI 在数据工程中通过生成 DAG、处理重试、以及更高效地管理依赖,进一步降低摩擦。执行改善了,但底层模型没有变。
大多数分析型数据仍然以批的方式移动:计划性摄取、窗口化转换,以及周期性刷新到仓库与湖。流式系统已经成熟,并服务于明确的运营用例。分析、报表与规划继续与批处理对齐,因为企业在周期中运作,而不是在事件流中运作。调度技术变了,但执行模式没变。
AI 改善了可靠性与速度,但它不消除对可预测、可重复数据移动的需要。
6、AI 让错误的工作更快
6.1 加速也会放大副作用
执行很少是限制因素,但相关性一直是、也将永远是限制因素。AI 在数据工程中降低了构建流水线、模型与查询的成本。交付在全局上加速,但错位也会随之加速。
AI 在数据工程中让“快速构建东西”变得更容易。它不让“构建正确的东西”更容易,也不让“6 个月后仍能运行”更容易。
AI 可能让数据工程师的工作看起来出奇地简单。SQL 立刻出现;数据流水线从 prompt 被脚手架化;schema 建议在团队对定义充分达成一致之前就到来。从外部看,会感觉这份工作最难的部分终于被自动化了。
现实在生产中看起来不同。AI 加速执行,但加速会带来副作用。更快的迭代降低摩擦,却在悄悄增加糟糕决策的成本。数据系统仍需要一致性;指标仍需要共享含义;捷径仍会产生利息,只是现在速度更快、规模更大。这就是“替代叙事”开始变弱的地方。
脱离活跃业务优先级的数据系统会很快衰败。更快的流水线无法弥补不清晰的目的。更大的模型也不会在孤立中创造价值。
每个组织都会同时运行多个计划。支撑决策的数据工作会持续存在;不支撑决策的工作会悄悄失去优先级,不论技术质量如何。AI 放大生产力,但它不创造对齐。成功的数据团队把业务问题翻译成可持续的系统。工具会变,但人类判断仍是核心。

7、AI 会取代数据工程师吗?
7.1 结论
AI 改变了数据工程的节奏:执行更快、迭代更便宜、更多工作流被自动化。AI 不会、也将不会取代数据工程师。决定成功或失败的数据系统部分仍然没有改变:含义仍需要被定义;质量仍需要被设计进去;性能仍需要意图;对齐仍然决定输出是否会影响真实决策。AI 确实压缩了时间,但数据工程师仍然、也将继续对结果负责。
当 AI 被嵌入日常工作流时,数据工程师的角色会更靠近这些决策,而不是离它们更远。工作会从“手写一切”转向“决定什么值得稳定、什么值得信任,以及系统能承受哪些权衡”。
在这种环境中保持有效,更少是追逐每个新工具,更多是建立正确的心智模型。这份 AI Data Engineering Roadmap 用来框定这种进阶:不是一份要学的技术清单,而是一种理解 AI 适合什么、不适合什么,以及你的责任如何随之演进的方式。工具会继续变化,但角色会继续移动。保持相关性的,是那些理解“为什么”的数据工程师。
参考文献

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)