Agentic RAG到底值不值?四大维度实测给你答案!
RAG系统对比研究:Enhanced与Agentic架构的实测分析 研究对比了两种检索增强生成(RAG)架构:规则化的Enhanced RAG与自主决策的Agentic RAG。实验显示,在金融等特定领域,Agentic的意图识别准确率高达98.8%,查询改写环节NDCG指标平均提升2.8点;但在开放域任务中,Enhanced的固定流程更稳定。成本方面,Agentic的token消耗是Enhanc
RAG系统大对决:让AI自己做决策真的更香吗?Enhanced vs Agentic全方位实测揭秘!
研究背景
想象一下,你问ChatGPT一个问题,它不仅要从自己的"大脑"里找答案,还要翻遍外部知识库,然后再给你回复。这就是RAG(检索增强生成)系统做的事情。但问题来了:是让系统按照固定流程一步步走,还是让AI自己当"项目经理",自主决定每一步该干什么?
这篇论文就是要回答这个问题。研究团队把RAG系统分成了两大阵营:
- Enhanced RAG(增强型RAG):就像一条精心设计的流水线,有专门的"查询改写工"、"文档排序工"等模块,各司其职
- Agentic RAG(智能体RAG):让大语言模型当总指挥,它自己决定要不要检索、要不要改写查询,完全自主控制
目前业界对这两种方案各有追捧,但到底哪个更好用?在什么场景下该选哪个?成本和性能怎么平衡?这些问题都没有明确答案。于是研究团队决定做一次"华山论剑"式的全面对比。
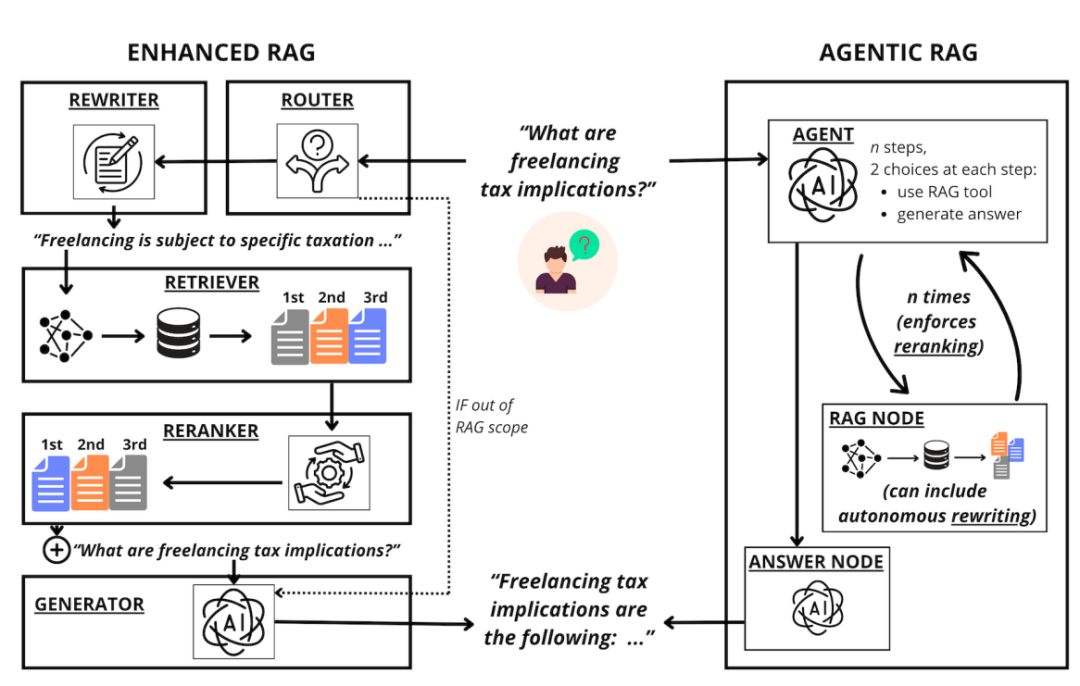
他们的核心贡献有两点:第一,从四个关键维度评估了两种系统的实际表现;第二,详细分析了成本和计算时间的差异,给实际应用提供了非常实用的参考。

相关工作:RAG技术的演进脉络
RAG这个概念最早由Lewis等人在2020年提出,最初的设计非常简单:收到查询→检索相关文档→把文档和查询一起喂给模型→生成答案。但这种"裸RAG"(论文里叫Naïve RAG)问题多多:有时候明明不需要检索也要检索一遍,浪费资源;有时候检索到的文档质量不高,都是些不相关的内容;用户问题和知识库文档的表述方式差异太大,匹配效果差。
于是Enhanced RAG应运而生,研究者们开始往这条流水线上加各种"增强模块":
- 查询改写模块(比如HyDE技术,把问题改写成假想的答案段落,再去匹配)
- 语义路由模块(判断这个问题到底需不需要检索)
- 重排序模块(把检索到的文档按相关性重新排序)
与此同时,随着GPT-4这类模型的推理能力暴涨,Agentic RAG开始冒头。这种方案的核心思想是:既然模型都这么聪明了,为什么不让它自己决定工作流程?于是各种Agent框架像雨后春笋般出现:LangGraph、LlamaIndex、CrewAI等等。
但有意思的是,尽管这两条技术路线都很火,学术界竟然还没有人做过系统性的对比实验。Neha和Bhati在2025年提出了一些理论上的区分,但没有真刀真枪地测试。这篇论文就是要填补这个空白。
核心方法:四大维度的"拳拳到肉"对比
研究团队选了四个关键维度来PK这两种系统,每个维度都对应Naïve RAG的一个痛点:
1. 用户意图处理:该不该检索的判断力
问题情境:用户问"今天天气怎么样",系统不应该去知识库里翻文档;但问"公司Q3销售报告的关键数据是什么",就必须检索。这个判断能力很重要。
Enhanced的做法:用semantic-router框架,提前准备一堆"有效问题"和"无效问题"的例子,新问题来了就跟这些例子比相似度,判断属于哪一类。
Agentic的做法:让GPT-4o自己决定,它可以选择"调用RAG工具"或者"直接回答"。
测试方法:在FIQA(金融问答)、FEVER(事实验证)、CQADupStack(论坛问答)三个数据集上各准备500个有效查询和500个无效查询,看谁判断得准。
2. 查询改写:让问题和文档"说同一种语言"
问题情境:用户问"自由职业的税务影响是什么?“,知识库里的文档可能写的是"自由职业者需要缴纳以下税种……”,表述方式不一样,直接匹配效果差。
Enhanced的做法:强制执行HyDE改写——把问题改写成一段假想的答案,比如"自由职业需要缴纳特定税种……",然后用这段文本去匹配知识库。
Agentic的做法:提示词里告诉Agent可以改写查询,但Agent自己决定要不要改、怎么改。
评估指标:用NDCG@10(归一化折损累积增益)来衡量检索质量,这是信息检索领域的黄金标准。
其中:
是第个文档的相关性标签。
3. 文档列表优化:检索完还能再精选
问题情境:第一次检索可能拿到20个文档,但其中有些不太相关,需要进一步筛选。
Enhanced的做法:用基于ELECTRA的重排序模型,把20个文档重新排序,选出最相关的10个。
Agentic的做法:Agent可以多次调用检索工具,每次都能调整查询策略,自己迭代优化。
4. 底层模型影响:换个"大脑"性能差多少
实验设计:用Qwen3系列的四个模型(0.6B、4B、8B、32B参数)分别测试,看模型大小对两种系统的影响是否一致。
评估方式:用Selene-70B作为"AI裁判",评价生成答案的质量。这个模型在LLM-as-a-Judge竞技场排名很高,而且在金融问答任务上跟人类评价高度一致。
实验效果:谁更强?要看具体场景
用户意图处理:Enhanced在复杂场景更稳
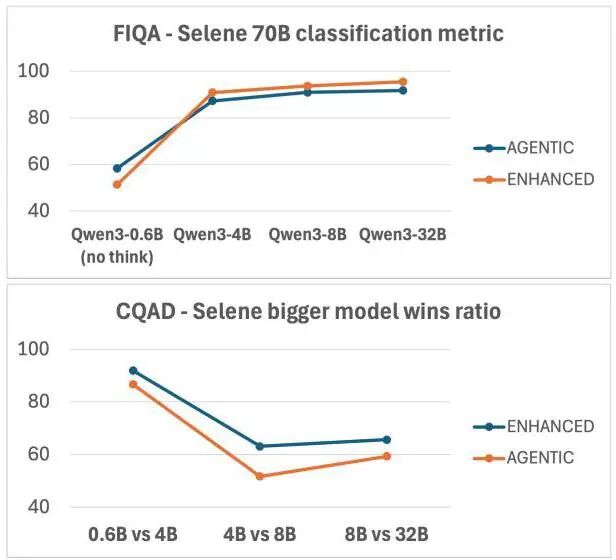
结果很有意思:在FIQA(金融)和CQADupStack(英语语法)这种领域边界清晰的场景,Agentic RAG表现更好,F1分数分别达到98.8和99.8。但在FEVER(事实验证)这种开放域任务上,Agentic的召回率只有49.3%,比Enhanced低了35个百分点!
原因很明确:当任务边界模糊时,Agent经常"过度热情",本不该检索的也去检索了。而Enhanced的基于示例的路由系统,在这种情况下反而更稳定。
查询改写:Agent的灵活性胜出
在所有数据集上,Agentic RAG的检索质量平均高出Enhanced RAG 2.8个NDCG@10点。特别是在NQ(自然问题)数据集上,Agentic达到51.7,比Enhanced的43.9高了近8个点。
这说明什么?Agent能根据具体问题灵活决定改写策略,而Enhanced是"一刀切"的强制改写,有时候反而画蛇添足。
文档优化:Enhanced的重排序完胜
这个结果出人意料:Enhanced RAG通过重排序模块,在FIQA上从45.0提升到51.0(提升6个点),在CQADupStack上从46.0提升到48.0。
但Agentic RAG呢?即使允许它多次调用检索工具,性能反而比基线还差(FIQA降到43.4,CQADupStack降到44.4)。看来Agent虽然能自主决策,但在"精挑细选文档"这件事上,还是不如专门训练的重排序模型靠谱。
模型大小影响:两者表现趋同
无论Enhanced还是Agentic,随着底层模型从0.6B增大到32B,性能都稳步提升,而且提升曲线几乎一致。这说明模型能力的影响是跨系统的,选哪种架构和选多大的模型可以独立考虑。
成本分析:Agentic的"奢侈税"不容忽视
这部分数据可能是最让实际应用者关注的:
Token消耗对比(FIQA数据集):
- Agentic比Enhanced多消耗2.7倍的输入token
- 输出token多1.7倍
- 整体耗时增加1.5倍
在CQADupStack数据集上差距更大:
- 输入token多3.9倍
- 输出token多2.0倍
换算成真金白银:如果你用OpenAI的API,Agentic RAG的成本可能是Enhanced的3-4倍。对于大规模应用,这不是小数目。
为什么会这样?因为Agentic需要不断"思考"——每一步都要推理要不要调用工具、怎么调用,这些中间步骤都要消耗token。而Enhanced是固定流程,该干啥干啥,不用额外"思考"。
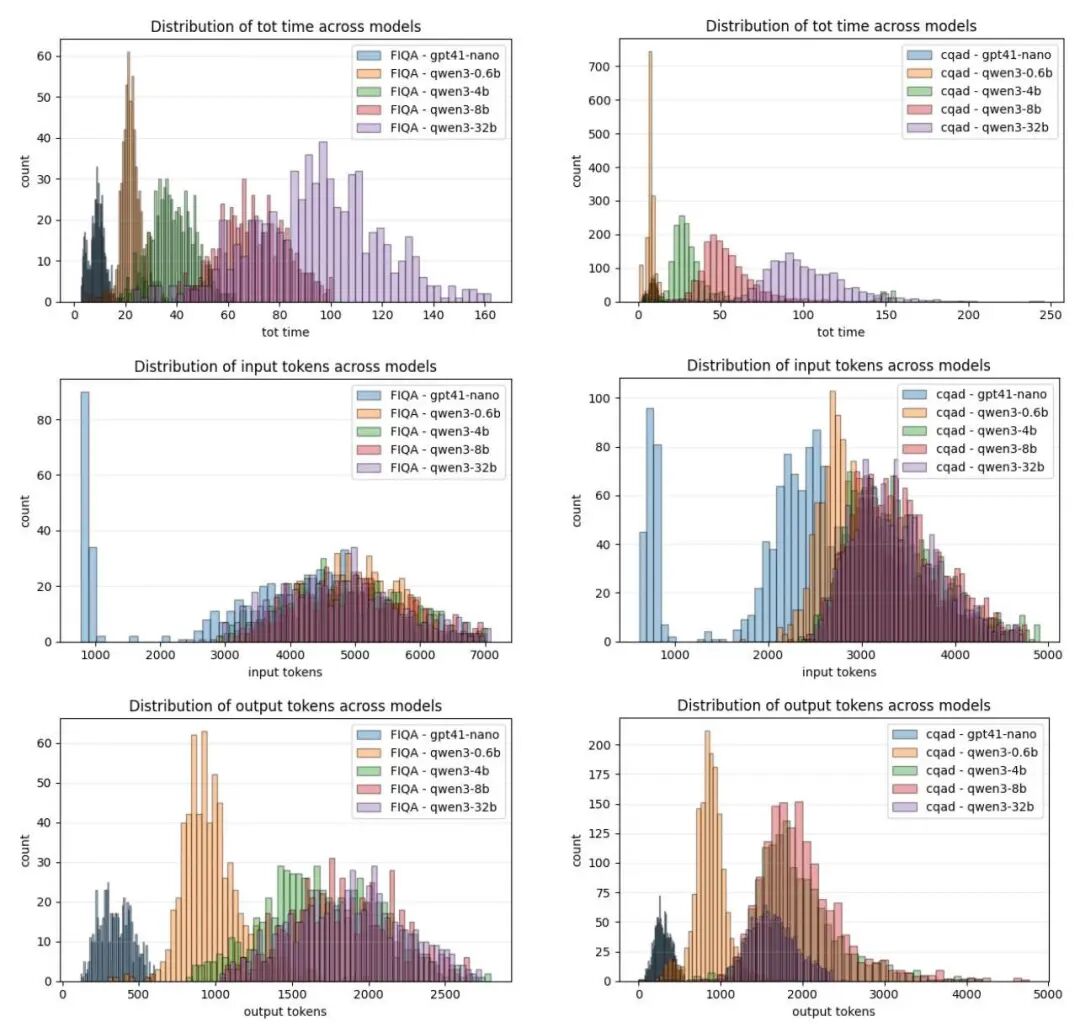
从分布图可以看出,Agentic的token消耗和耗时都有明显的"长尾"现象——有些查询特别费劲,Agent要反复调用工具好几次。
论文总结:没有银弹,只有权衡
这篇论文最大的价值在于:打破了"新技术一定更好"的神话。
主要发现可以总结为:
- 窄领域任务选Agentic,开放域任务选Enhanced:在金融、语法这种边界清晰的场景,Agent的理解力能发挥优势;但在FEVER这种"什么都能问"的场景,基于规则的路由反而更可靠。
- 查询改写环节Agentic占优:灵活的改写策略确实能提升检索质量,平均提升2.8个NDCG点,这个优势是实打实的。
- 文档精选必须上重排序:Agent多次检索的策略没有Enhanced的专用重排序模型好用,这可能是Agentic架构的最大短板。论文建议:为什么不在Agentic里也加个重排序工具?
- 成本差异不可忽视:3-4倍的成本增加对很多应用来说是难以承受的。除非你对性能有极致要求,否则优化好的Enhanced RAG可能更实惠。
- 模型大小影响两者一致:这意味着你可以先选架构,再根据预算选模型,两个决策相对独立。
实用建议:
如果你是企业开发者,在小规模、预算有限的场景下,Enhanced RAG可能是更明智的选择——性能够用,成本可控。
如果你追求极致的用户体验,或者应用场景特别复杂多变,那Agentic RAG的灵活性值得你为之付费。
但最理想的方案可能是"混合架构":用Enhanced的重排序模块 + Agentic的灵活决策,取两者之长。研究团队也坦言,他们的Agentic实现只用了一个工具(RAG),如果给Agent配置更丰富的工具箱,结果可能完全不同。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
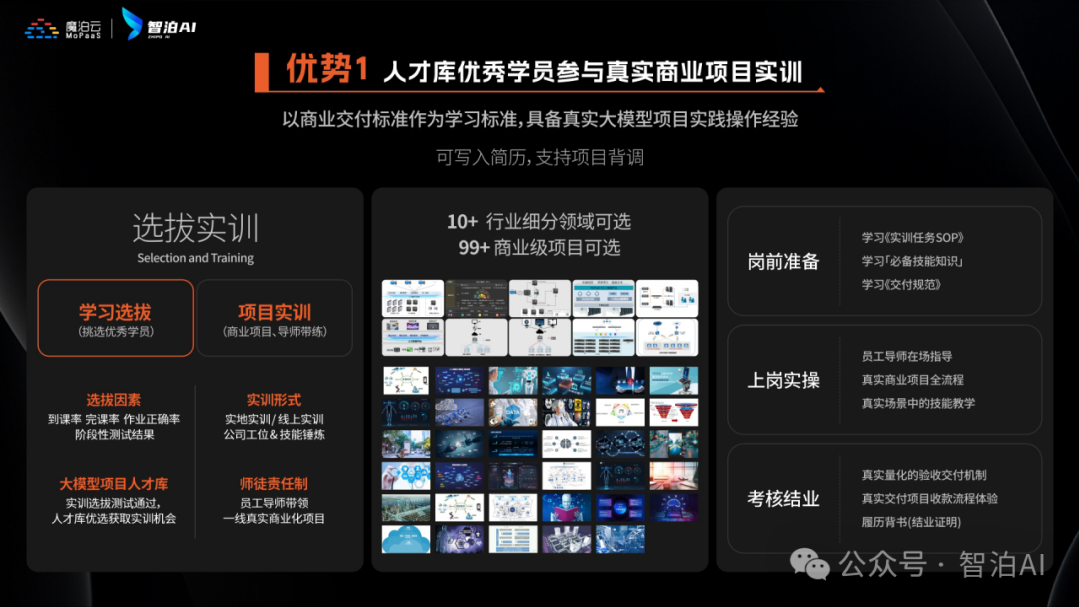
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

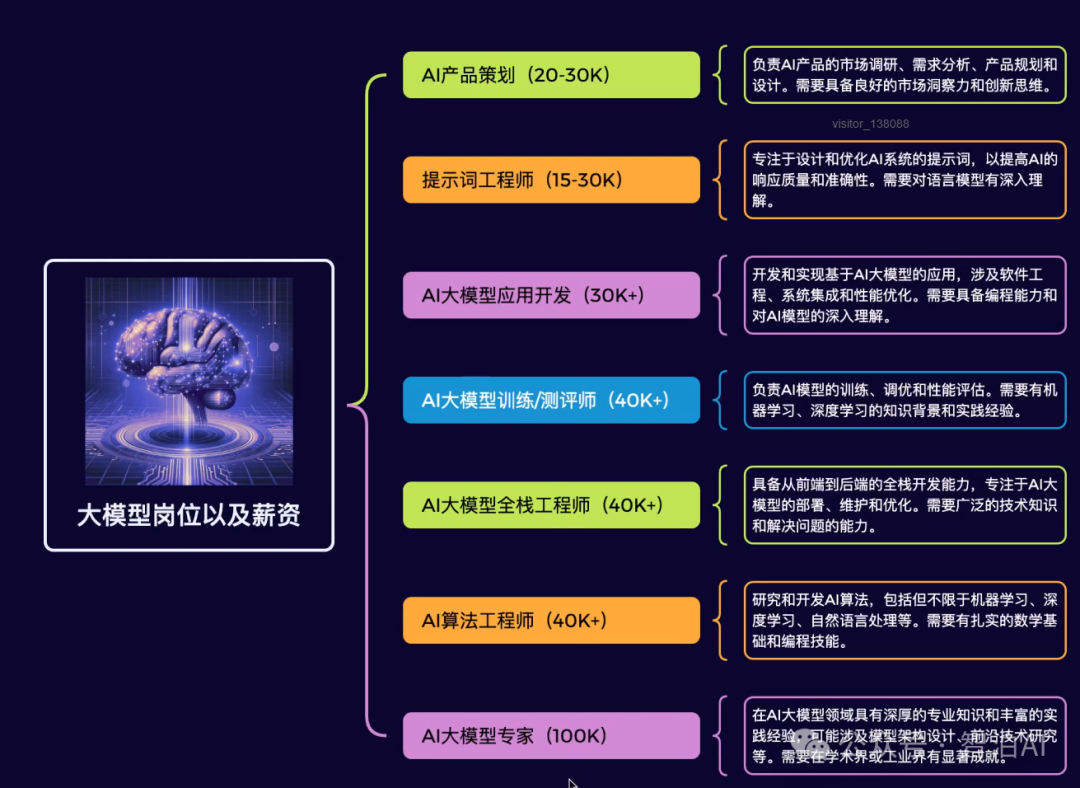
课程优势四:热门岗位全覆盖,匹配企业岗位需求
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
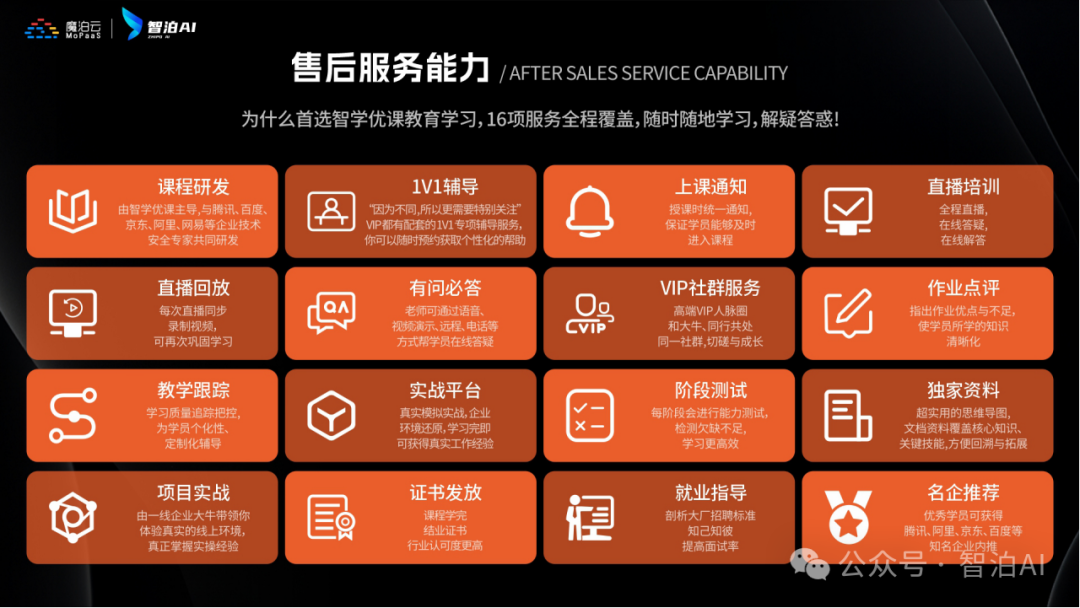
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献216条内容
已为社区贡献216条内容

所有评论(0)