多智能体神话破灭?人多不一定力量大,一个模型可能更聪明
当整个AI行业都在狂热堆叠Agent数量、构建越来越庞大的多智能体系统时,本期两篇论文却泼来一盆冷水:团队协作正在拖垮你的专家模型。如果你正在设计Agent架构、搭建多智能体系统,或者对AI协作的本质感到好奇,这两篇论文抛出一个核心问题:我们真的需要那么多Agent吗?
多智能体神话破灭?人多不一定力量大,一个模型可能更聪明
开篇导读
当整个AI行业都在狂热堆叠Agent数量、构建越来越庞大的多智能体系统时,本期两篇论文却泼来一盆冷水:团队协作正在拖垮你的专家模型。如果你正在设计Agent架构、搭建多智能体系统,或者对AI协作的本质感到好奇,这两篇论文抛出一个核心问题:我们真的需要那么多Agent吗?
- 论文1《Multi-Agent Teams Hold Experts Back》:这篇论文最吸引人的地方在于它挑战了“多智能体必然更强”的认知。多智能体 LLM 团队无法实现 “强协同”(匹配或超越团队中最优个体表现),核心瓶颈是专家知识利用不足而非专家识别,且存在团队规模越大性能越差的 “专业知识稀释效应”,但这种共识寻求行为同时提升了对抗鲁棒性。
- 论文2《AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent》:本文由卡内基梅隆大学、亚马逊等机构联合提出 AgentArk 框架,核心目标是解决多智能体系统(MAS)在实际部署中面临的高计算成本与误差传播问题,通过蒸馏技术将多智能体的推理能力迁移至单个大语言模型(LLM),在保留单智能体高效性的同时,复刻多智能体的推理与自我修正能力。
论文1:Multi-Agent Teams Hold Experts Back
基本信息
- 资讯条目:1. Multi-Agent Teams Hold Experts Back ⭐⭐⭐
- 论文链接:https://arxiv.org/abs/2602.01011
- 作者:Aneesh Pappu,Batu El,Hancheng Cao,Carmelo di Nolfo,Yanchao Sun,Meng Cao 等7位
- 发表时间:2026-02-01T04:34:36Z
- 发表来源:arXiv
这篇论文在解决什么难题
多智能体 LLM 系统日益普及,但现有研究多通过固定角色、工作流或聚合规则实现协同,难以适应无预设结构的真实协作场景。人类团队在明确专家身份后可实现强协同,但 LLM 团队能否在无外部约束下自主识别并利用专家知识尚不明确。文章探讨以下核心问题:
Q1:异质 LLM 团队能否自主组织实现强协同,还是会系统性落后于最优个体?
Q2:若无法实现强协同,瓶颈是专家识别还是专家知识利用?
Q3:哪些结构和交互因素导致强协同缺失?
它最有价值的创新点
该研究最核心的创新点在于首次系统揭示了自组织多智能体 LLM 团队在 “强协同”(性能匹配或超越团队最优个体)上的固有缺陷,通过跨经典心理学任务与前沿 ML 基准的对比实验,拆解出 “专家识别” 与 “专家知识利用” 的双重差距,明确指出团队性能不足的核心瓶颈是后者而非前者,同时发现了 “专业知识稀释效应”(团队规模越大性能越差)与 “协同 - 鲁棒性权衡”(共识寻求行为虽削弱专家知识利用,但提升对抗性攻击鲁棒性)两大关键规律,其创新还体现在构建了角色无预设、沟通无约束的贴近真实协作场景的实验框架,并开源了多任务协同性评估工具包,为多智能体系统设计中平衡共识与专业知识利用提供了全新的理论依据和实践参考。
核心方法详解
这篇论文为了探究自组织多智能体LLM团队的协同问题,设计了可控心理学任务+真实ML基准任务结合的双层实验方法,搭配清晰的变量控制、量化指标和行为分析手段,整体方法通俗来说就是"先定研究问题→搭实验框架→控变量测性能→析原因找规律",全程用可量化的指标和结构化分析验证结论,数学公式仅用于核心指标计算,整体方法易懂、可复现,下面分实验设计核心逻辑、具体任务与模型设置、关键量化指标、变量控制、深层行为分析五部分,通俗详细拆解,公式也会结合含义说明:
实验设计的核心逻辑:对标人类团队,解决3个核心问题
研究的核心是搞清楚"LLM团队能不能像人类一样靠自组织用好专家能力",所以先定了3个要回答的问题,所有方法都围绕这3个问题设计:
- LLM团队能不能做到强协同(性能追上/超过团队里的专家个体),还是永远比专家差?
- 若做不到强协同,问题是认不出专家,还是认出了也不会用?
- 哪些团队结构(如规模)、交互行为(如沟通方式)导致了协同失败?
为了回答这些问题,研究没有用传统"给智能体定固定角色/流程"的方式,而是模拟人类真实无约束协作场景:让智能体自由讨论、自组织,不预设谁是专家、不规定沟通顺序,只要求最终给出团队答案,以此测试LLM团队的自然协作能力。
两类实验任务:可控场景测规律,真实场景验普适性
研究选了两类互补的任务,一类是能人工操控"专家是谁、知识怎么分"的经典心理学任务(可控),另一类是贴近实际应用的前沿ML基准任务(真实),确保结论不是某类任务的特例,而是普遍规律:
经典人类心理学任务(3个):NASA月球生存、海上遇险、学生会主席选举
这类任务的核心是排序任务(比如给月球生存的15件物品按重要性排序),优势是专家知识可人工操控:
- 能定专家分布:要么集中式(一个智能体掌握所有正确知识),要么分布式(多个智能体各掌握一部分正确知识);
- 能定专家答案:有明确的官方标准答案(如NASA给的月球生存物品排序、美国海岸警卫队的海上遇险排序),结果可精准量化。
前沿ML基准任务(5个):MMLU Pro、SimpleQA、GPQA Diamond、HLE文本版、MATH-500
这类任务是LLM实际应用中会遇到的推理/问答任务,优势是专家是动态的:不同模型在不同问题上各有优势(比如A模型擅长数学、B模型擅长常识),更贴近真实的多智能体协作场景,测试结论的实际价值。
模型与团队设置:兼顾异质性和可对比性
实验用的都是主流前沿LLM(如Anthropic的Claude系列、OpenAI的GPT系列),团队设置分基础版和拓展版,确保结果稳健:
- 基础团队规模:4个智能体为核心(后续拓展到2/8个,测试团队规模的影响);
- 团队构成:分同质团队(全Claude/全GPT)和异质团队(Claude+GPT混合),排除"模型单一导致的协同失败";
- 讨论规则:无预设沟通顺序(随机发言)、固定4轮讨论(确保所有团队的沟通时间一致)、先收集每个智能体的独立答案再讨论(能对比"独立做"和"团队做"的差异),最后随机选一个智能体出团队答案(避免某一智能体"一言堂")。
核心量化指标:用数学公式精准测"协同差距",无模糊空间
研究设计了3个核心量化指标,其中2个用简单数学公式定义,把"协同好不好""团队比专家差多少"变成可计算的数字,公式通俗易理解,先明确两个前提:
- 对准确率任务(如ML问答,越高越好):f(⋅)f(\cdot)f(⋅) 表示模型/团队的准确率;
- 对误差任务(如心理学排序,越低越好):f(⋅)f(\cdot)f(⋅) 表示模型/团队的排序误差(用L1误差,即答案与标准答案的绝对偏差总和)。
相对协同差距(最核心指标):测团队比专家差多少
这是论文中用得最多的指标,公式分两种情况,本质都是**“团队与专家的差距/专家的表现”,结果为百分比**,数值越大,说明团队比专家差得越多:
-
准确率任务(ML基准):
Relative Synergy Gap=maxtf({at})−f({a1,...,aT})maxtf({at})Relative\ Synergy\ Gap =\frac{max _{t} f\left(\left\{a_{t}\right\}\right)-f\left(\left\{a_{1}, ..., a_{T}\right\}\right)}{max _{t} f\left(\left\{a_{t}\right\}\right)}Relative Synergy Gap=maxtf({at})maxtf({at})−f({a1,...,aT})
通俗说:(团队里专家的准确率 - 团队整体准确率)÷ 专家的准确率 -
误差任务(心理学排序):
Relative Synergy Gap=f({a1,...,aT})−maxtf({at})maxtf({at})Relative\ Synergy\ Gap =\frac{f\left(\left\{a_{1}, ..., a_{T}\right\}\right)-max _{t} f\left(\left\{a_{t}\right\}\right)}{max _{t} f\left(\left\{a_{t}\right\}\right)}Relative Synergy Gap=maxtf({at})f({a1,...,aT})−maxtf({at})
通俗说:(团队的排序误差 - 团队里专家的排序误差)÷ 专家的排序误差
✅ 指标含义:0%表示团队和专家表现一样(强协同);正数表示团队比专家差,数值越大差距越大。
识别差距 vs 利用差距:拆解协同失败的原因
为了区分"认不出专家"和"认出了不会用",研究把总协同差距拆成两个子指标:
- 识别差距:(没被告知专家是谁时的团队表现 - 被告知专家是谁时的团队表现)→ 数值越小,说明团队自己认专家的能力越强;
- 利用差距:(被告知专家是谁时的团队表现 - 专家单独的表现)→ 数值越大,说明团队就算知道谁是专家,也不会用其知识,这是核心瓶颈。
L1误差:测排序任务的精准度(心理学任务专用)
排序任务的核心量化指标,公式为:
L1 Error=∑i=1n∣xi−yi∣L1\ Error = \sum_{i=1}^n|x_i - y_i|L1 Error=i=1∑n∣xi−yi∣
其中xix_ixi是团队对第iii个物品的排序位置,yiy_iyi是标准答案的排序位置,nnn是物品总数。
✅ 指标含义:数值越小,排序越接近标准答案,表现越好(比如把第1名排到第3名,偏差是2,会计入总和)。
关键变量控制:4种实验条件,对比出核心问题
为了精准找到协同失败的原因,研究设置了4种对照实验条件,唯一变量是"团队是否知道专家是谁、是否有专家知识",其余所有条件(团队构成、讨论规则、任务)完全一致,通过对比不同条件的结果,得出明确结论:
- 无信息组:没有任何智能体掌握专家知识(对照组,测模型的基础能力);
- 不指明专家组:团队里有专家,但不告诉智能体谁是专家(测团队自主识别专家的能力);
- 明确专家组:直接告诉所有智能体谁是专家(甚至用优化后的提示词强制团队听专家的,测团队利用专家知识的能力);
- 最优个体组:只有专家单独完成任务(基准组,作为团队性能的对比标杆)。
拓展实验:测试团队规模和对抗鲁棒性
在核心实验的基础上,研究做了两个拓展实验,进一步挖掘规律:
- 团队规模实验:把团队从2个扩展到8个,测试规模对性能的影响,发现规模越大,性能越差(专业知识稀释效应),且该效应在"明确专家"的条件下依然存在;
- 对抗鲁棒性实验:在团队里加一个"恶意智能体"(被指令故意给出错误答案,破坏团队表现),测试团队的抗干扰能力,发现团队表现几乎没下降,共识寻求行为有意外的抗干扰效果。
深层行为分析:从对话里找"不会用专家"的原因
核心实验发现"认出专家但不会用"是瓶颈后,研究通过对话内容分析,搞清楚智能体在讨论中到底做了什么导致不会用专家知识,步骤通俗且可复现:
- 转录对话:把所有智能体的4轮讨论完整转录成文本;
- 行为编码:用Gemini 3.0 Pro给对话中的每一句话"贴标签",按非专家和专家分成4类核心行为,标签定义简单清晰,无模糊性:
- 非专家:①认知顺从(听专家的,直接采纳专家观点);②整合妥协(和专家讨价还价,搞中间派,比如专家说排第1,非专家说排第3,最后折中排第2);
- 专家:①策略坚持(坚持自己的正确观点,不向非专家妥协);②认知灵活(迎合非专家,修改自己的正确观点);
- 相关性分析:计算"每种行为的出现次数"和"相对协同差距"的相关系数,发现整合妥协、认知灵活的出现次数越多,团队表现越差,这就是"不会用专家"的核心原因。
方法流程图与图解: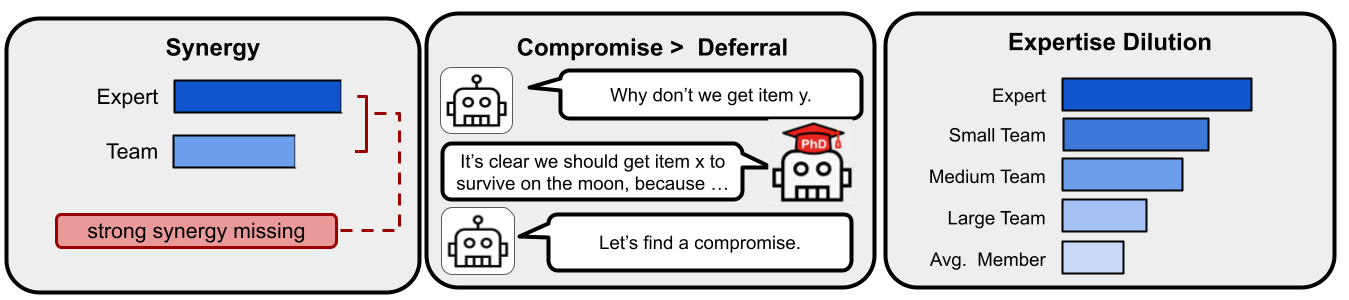
- 图1:多智能体团队未能利用专业知识。
- 图1解读:图1展示了多智能体团队无法有效利用专家知识的现象。读者应关注面板1中团队表现不及专家,面板2中非专家倾向于妥协而非采纳专家意见,以及面板3中团队规模增大导致表现下降。结论是LLM团队缺乏强协同,且规模扩大加剧了专业知识稀释。
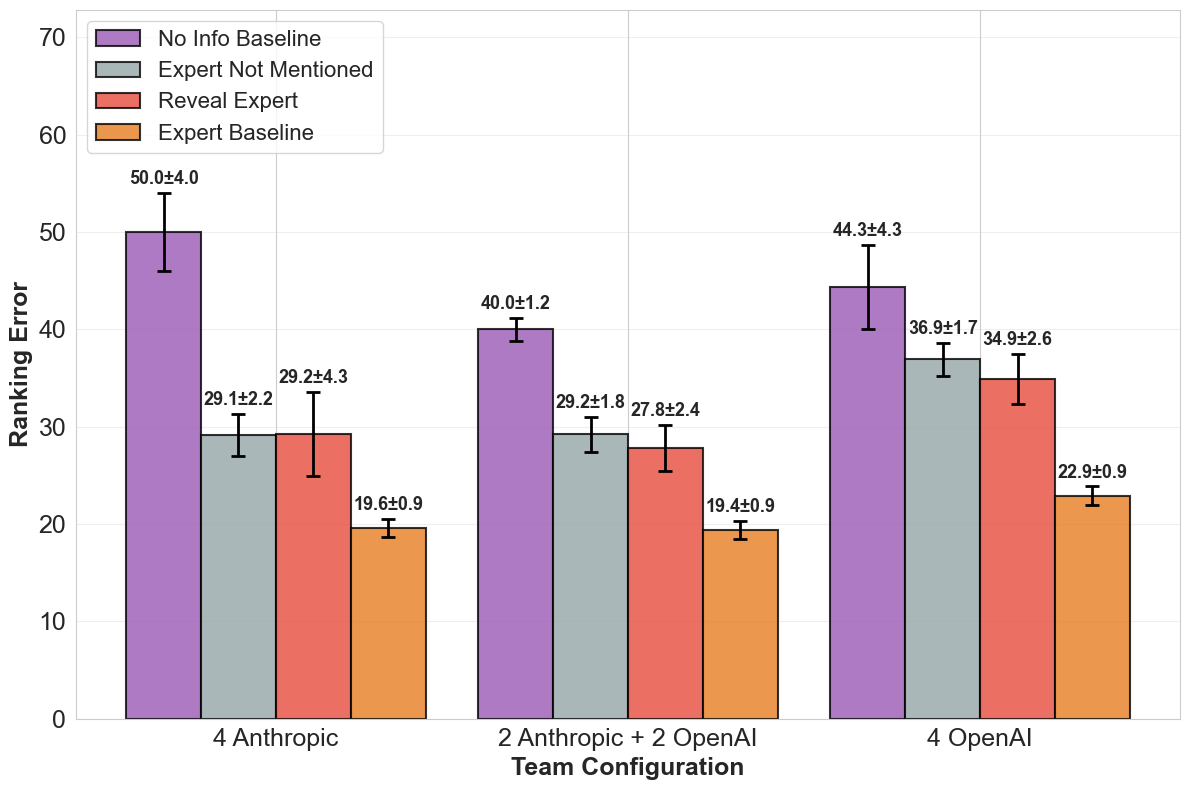
- 图2:集中专业知识性能:迷失海上。
- 图2解读:该图通过“迷失海上”任务展示了即便明确告知谁是专家,团队表现仍无法匹敌专家。读者应观察“未提及专家”与“揭示专家”两种条件下表现差异微小这一关键点。结论表明利用专业知识才是主要瓶颈,而非识别专家,这在不同团队配置中均成立。
实验与应用价值
实验主要围绕“团队是否真正优于专家个体”展开:研究在多种任务与多种团队配置下,对比了不提示专家、提示专家和强化提示等条件,并观察团队规模变化对结果的影响。实验不仅看最终准确率,还观察决策是否向专家意见收敛、不同提示策略是否改变团队行为,并考察鲁棒性提升是否伴随性能下降。整体趋势表明,团队在多数情况下难以超过最佳个体,且规模变大时更容易出现平均化妥协。
| 观察维度 | 设置/指标 | 结果/结论 |
|---|---|---|
| 实验设计 | 多任务+多团队配置 | 围绕协作有效性进行多条件对比 |
| 对比基线 | 单专家 vs 多智能体团队 | 观察团队是否真正超过最优个体 |
| 结果趋势 | 性能与鲁棒性指标 | 实验主要围绕“团队是否真正优于专家个体”展开:研究在多种任务与多种团队配… |
| 价值维度 | 解读 |
|---|---|
| 领域贡献 | 该研究对多智能体领域的核心贡献,是把“协作效果差”从模糊现象变成可诊断问题:它明确区分了专家识别与专家利用,并给出可复用的评估框架,帮助后续工作从机制层面优化协作,而不是只堆规模。 |
| 通俗理解 | 通俗来说,这项工作告诉我们:AI团队并不会天然变聪明,如果协作机制设计不好,大家讨论越久可能越偏离最优答案。 |
| 与日常生活关系 | 这和现实中的会议很像:明明有最懂的人,但团队为了统一意见不断折中,最终方案看起来“大家都同意”,却不一定是最专业、最有效的方案。 |
论文2:AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent
基本信息
- 资讯条目:2. AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent ⭐⭐⭐⭐⭐
- 论文链接:https://arxiv.org/abs/2602.03955
- 作者:Yinyi Luo,Yiqiao Jin,Weichen Yu,Mengqi Zhang,Srijan Kumar,Xiaoxiao Li 等9位
- 发表时间:2026-02-03T19:18:28Z
- 发表来源:arXiv
这篇论文在解决什么难题
多智能体系统(MAS)通过多轮辩论、批判与共识机制,在复杂推理任务中表现卓越,能够探索多元假设、发现逻辑错误并迭代优化解决方案。但存在两大关键缺陷:
- 计算开销大:推理延迟与计算量随智能体数量呈二次增长,难以满足实时场景需求;
- 鲁棒性风险:个体偏差或幻觉可能在交互中放大,导致集体推理失效。
如何让单个模型在不承担多智能体推理时成本与脆弱性的前提下,内化其推理优势?现有研究多局限于模仿多智能体的最终答案或浅层交互痕迹,未能复现其核心的 “冲突 - 修正” 迭代动态。
它最有价值的创新点
AgentArk最核心的创新点在于首次提出了一套通用且可扩展的多智能体推理蒸馏框架,突破了现有多智能体蒸馏仅模仿最终答案或浅层交互痕迹的局限,通过数据生成-知识提取-分层蒸馏的全流程设计,将多智能体系统核心的迭代冲突-修正推理动态内化到单个LLM中,其创新设计的三层递进式蒸馏策略(推理增强型微调、推理轨迹数据增强、结合PRM步骤级监督与GRPO强化学习的过程感知蒸馏),不仅实现了从推理结果到推理过程的深度蒸馏,还通过优先筛选纠错型轨迹、强调推理质量而非数量、解耦PRM容量与学生模型规模等设计,让单模型在保留原有的高效推理特性的同时,充分继承多智能体的多视角推理、自我修正能力,且框架与具体多智能体策略、模型模态无关,可跨模型家族、跨模态扩展,还成功将多智能体的计算成本从推理阶段转移至训练阶段,解决了多智能体系统实际部署中高计算开销、误差传播、泛化性差的核心痛点,同时揭示了PRM容量、学生模型匹配度对蒸馏效果的关键影响,为高效、鲁棒的轻量化大模型研发提供了全新范式。
核心方法详解
AgentArk的核心方法是通过三阶段流程(数据生成与知识提取+三层分层蒸馏),把多智能体的推理能力"浓缩"到单个大语言模型中,全程不依赖特定的多智能体交互规则,且将多智能体推理时的高计算成本转移到训练阶段,推理时仅需单模型一次前向传播,兼顾效果与效率。以下从**基础准备(数据生成与知识提取)和核心蒸馏(三层策略)**两部分,结合公式和通俗语言详细讲解。
基础准备:多智能体数据生成与知识提取
这一步是为后续蒸馏准备"高质量的多智能体推理素材",核心是让多个智能体围绕问题辩论,产生多样的推理过程,再筛选出有用的内容,相当于为单模型准备"多智能体老师的解题笔记"。
多智能体辩论生成推理素材
为每个问题xxx初始化n=5n=5n=5个共享同一LLM骨干的智能体A={a1,a2,...,a5}A=\{a_1,a_2,...,a_5\}A={a1,a2,...,a5},进行最多K=3K=3K=3轮辩论:每一轮中,每个智能体aia_iai都会根据问题xxx和其他智能体上一轮的推理轨迹{τj,k−1}j≠i\{\tau_{j,k-1}\}_{j≠i}{τj,k−1}j=i,生成自己本轮的推理轨迹τi,k\tau_{i,k}τi,k。
最终会形成一个完整的辩论日志Lx\mathcal{L}_xLx,里面包含所有智能体的最终推理轨迹{r1,r2,...,rn}\{r_1,r_2,...,r_n\}{r1,r2,...,rn}和对应的答案,既有一致的共识答案,也有不同的解题思路,甚至有"初始错、后来改对"的纠错过程。
知识提取:筛选优质推理素材
不是所有辩论内容都有用,我们重点筛选**“纠错型轨迹”**(智能体一开始步骤错了,看了同伴的推理后修正,最终得到正确答案y∗y^*y∗的轨迹),同时提取两类核心内容:
- 验证过的最终共识答案y∗y^*y∗(和真实答案匹配);
- 能成功推导出y∗y^*y∗的中间推理轨迹{ri}\{r_i\}{ri}。
筛选的目的是:只保留"正确且有价值"的推理过程,避免错误素材误导单模型训练,同时保留多样性,让单模型能学到多智能体的不同解题思路。
核心:三层分层蒸馏策略
这是AgentArk的核心创新,从模仿多智能体的推理结果,到模仿多样的推理路径,再到内化多智能体的推理过程,层层递进,最终让单模型拥有多智能体的推理能力。三个策略可独立使用,也可组合,组合后效果更优。
我们将待训练的单模型称为学生模型πθ\pi_\thetaπθ(θ\thetaθ是模型参数),多智能体的推理素材为训练数据D\mathcal{D}D。
策略1:推理增强型监督微调(RSFT)—— 让单模型学会"按多智能体的思路推导出正确答案"
通俗理解
传统的监督微调只教模型"答案是什么",而RSFT不仅教答案,还教模型"多智能体是怎么一步步推理出这个答案的",相当于让学生模型模仿多智能体老师的完整解题步骤+最终答案,确保推理过程连贯、答案准确。
数学公式与核心设计
训练的目标是最小化损失函数LSFT(θ)\mathcal{L}_{SFT}(\theta)LSFT(θ),让模型尽可能生成和多智能体一致的推理轨迹与答案,公式为:
LSFT(θ)=−E(x,r,y∗)∼D(Lres+Lans)\mathcal{L}_{SFT}(\theta)=-\mathbb{E}_{\left(x, r, y^{*}\right) \sim \mathcal{D}} \left(\mathcal{L}_{res} + \mathcal{L}_{ans}\right)LSFT(θ)=−E(x,r,y∗)∼D(Lres+Lans)
其中:
- E(x,r,y∗)∼D\mathbb{E}_{\left(x, r, y^{*}\right) \sim \mathcal{D}}E(x,r,y∗)∼D:对训练数据集中的所有(问题xxx,推理轨迹rrr,正确答案y∗y^*y∗)取期望,保证训练的通用性;
- Lres=∑t=1∣r∣logpθ(rt∣r<t,x)\mathcal{L}_{res}=\sum_{t=1}^{|r|} log p_{\theta}\left(r_{t} | r_{<t}, x\right)Lres=∑t=1∣r∣logpθ(rt∣r<t,x):推理损失,让模型能根据问题xxx和前面的推理步骤r<tr_{<t}r<t,准确生成下一个推理步骤rtr_trt,确保推理过程的连贯性和逻辑性;
- Lans=logpθ(y∗∣r,x)\mathcal{L}_{ans}=log p_{\theta}\left(y^{*} | r, x\right)Lans=logpθ(y∗∣r,x):答案损失,让模型能根据问题xxx和完整的推理轨迹rrr,准确生成最终正确答案y∗y^*y∗,确保推理过程和答案的一致性。
关键作用
是最基础的蒸馏策略,让单模型初步掌握多智能体的推理风格,保证"推理有逻辑,答案不出错"。
策略2:推理轨迹数据增强(DA)—— 让单模型学会"同一道题的多种解法"
通俗理解
RSFT是让模型模仿多智能体的一套优质推理步骤,而DA是让模型模仿多套优质推理步骤:从多智能体的辩论日志中,为同一个问题提取1-3条正确但思路不同的推理轨迹(比如解数学题,有的用代数法,有的用几何法),构建"增强数据集"Daug\mathcal{D}_{aug}Daug,让模型学习同一问题的多种有效解题路径,避免只会一种思路,提升鲁棒性(换个问法也会做)和泛化能力。
数学公式与核心设计
训练的目标是最小化增强数据集上的损失函数LAug(θ)\mathcal{L}_{Aug}(\theta)LAug(θ),公式为:
LAug(θ)=−1k∑i=1k∑t=1Tlogpθ(yt∣y<t,ri,x)\mathcal{L}_{Aug }(\theta)=-\frac{1}{k} \sum_{i=1}^{k} \sum_{t=1}^{T} log p_{\theta}\left(y_{t} | y_{<t}, r_{i}, x\right)LAug(θ)=−k1i=1∑kt=1∑Tlogpθ(yt∣y<t,ri,x)
其中:
- k∈{1,2,3}k\in\{1,2,3\}k∈{1,2,3}:为每个问题提取的多样推理轨迹数量;
- rir_iri:第iii条推理轨迹,每条轨迹都能推导出正确答案,但思路不同;
- 内层求和∑t=1T\sum_{t=1}^{T}∑t=1T:对单条轨迹的所有步骤做推理损失优化,外层求和∑i=1k\sum_{i=1}^{k}∑i=1k:对所有多样轨迹做平均优化。
关键作用
突破了单一路径的推理局限,让模型拥有"多视角思考"的能力,解决了RSFT可能存在的"思路单一"问题,进一步提升模型应对不同问题的能力。
策略3:过程感知蒸馏(PAD)—— 让单模型学会"像多智能体一样辩证思考、自我纠错"
通俗理解
前两个策略都是让模型模仿多智能体的推理结果/路径,而PAD是让模型内化多智能体的推理过程:多智能体的核心优势是互相批判、发现错误、修正答案,PAD通过**过程奖励模型(PRM)给单模型的每一步推理"打分"(对的步骤给高分,错的给低分),再结合强化学习(GRPO)**让模型学会"自己检查步骤、发现错误、修正推理",实现单模型内部的"辩证推理",这是最贴近多智能体核心能力的蒸馏策略。
PAD分为两个核心步骤:**训练过程奖励模型(PRM)**做步骤级打分、用GRPO强化学习训练学生模型。
步骤1:训练过程奖励模型(PRM)RϕR_\phiRϕ(ϕ\phiϕ是PRM参数)
PRM的核心作用:对学生模型生成的每一步推理,判断其是否和多智能体的共识一致,给出步骤级的奖励分数,相当于给单模型配了一个"实时批改作业的老师",能指出每一步对不对,而不是只看最终答案。
- 两阶段训练:避免丢失预训练的语言能力,先冻结PRM的模型骨干,只训练最后一层和奖励头(学习给推理步骤打分);再解冻整个骨干,全量微调(让PRM更精准地识别逻辑错误)。
- 对比损失设计:不采用简单的"对=1,错=0"二分类,而是让PRM学会相对正确——对和多智能体共识一致的推理步骤rt+r_t^+rt+给高分,对矛盾的错误步骤{rt−}\{r_t^-\}{rt−}给低分,损失函数采用对比损失,鼓励PRM区分"优质步骤"和"劣质步骤"。
步骤2:用GRPO强化学习训练学生模型πθ\pi_\thetaπθ
传统强化学习需要单独的"价值函数"预测奖励,GRPO无需额外价值函数,通过组内对比优化模型,更高效、更稳定。核心是让学生模型生成一组推理结果,通过PRM打分后,在组内对比奖励高低,让模型向"高分推理步骤"靠拢。
训练的目标是最大化目标函数J(θ)\mathcal{J}(\theta)J(θ),公式为:
J(θ)=Ex∼D,{oi}∼πold[1G∑i=1GLi(θ)−βDKL(πθ∥πref)]\mathcal{J}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{o_{i}\right\} \sim \pi_{old }}\left[\frac{1}{G} \sum_{i=1}^{G} \mathcal{L}_{i}(\theta)-\beta \mathbb{D}_{KL}\left(\pi_{\theta} \| \pi_{ref}\right)\right]J(θ)=Ex∼D,{oi}∼πold[G1i=1∑GLi(θ)−βDKL(πθ∥πref)]
其中各部分通俗解释:
- x∼Dx \sim \mathcal{D}x∼D:从训练集取问题,{o1,o2,...,oG}∼πold\{o_1,o_2,...,o_G\}\sim\pi_{old}{o1,o2,...,oG}∼πold:学生模型基于当前参数(πold\pi_{old}πold)生成GGG个推理结果(一组);
- Li(θ)=min(ρi(θ)A^i,clip(ρi(θ),1−ϵ,1+ϵ)A^i)\mathcal{L}_{i}(\theta)=min \left(\rho_{i}(\theta) \hat{A}_{i}, clip\left(\rho_{i}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{i}\right)Li(θ)=min(ρi(θ)A^i,clip(ρi(θ),1−ϵ,1+ϵ)A^i):裁剪后的代理目标,避免模型参数更新幅度过大,其中ρi(θ)=πθ(oi∣x)πold(oi∣x)\rho_{i}(\theta)=\frac{\pi_{\theta}(o_{i} | x)}{\pi_{old }(o_{i} | x)}ρi(θ)=πold(oi∣x)πθ(oi∣x)是模型生成第iii个推理结果的概率比;
- A^i=Rϕ(oi)−μRσR\hat{A}_{i}=\frac{R_{\phi}\left(o_{i}\right)-\mu_{R}}{\sigma_{R}}A^i=σRRϕ(oi)−μR:优势函数,将PRM给第iii个推理结果的总分数Rϕ(oi)R_\phi(o_i)Rϕ(oi)做标准化,让组内的奖励对比更公平(μR\mu_RμR是组内分数均值,σR\sigma_RσR是标准差);
- βDKL(πθ∥πref)\beta \mathbb{D}_{KL}\left(\pi_{\theta} \| \pi_{ref}\right)βDKL(πθ∥πref):KL散度正则项,β\betaβ是系数,避免训练后的模型πθ\pi_\thetaπθ和原始参考模型πref\pi_{ref}πref偏差过大,保证模型的稳定性。
关键作用
让单模型实现步骤级的自我检查、错误修正,真正内化了多智能体"辩论-批判-修正"的核心推理动态,是三个策略中效果最稳定、提升最显著的一个。
三层蒸馏策略的核心逻辑总结
AgentArk的三层蒸馏策略是由浅入深、层层递进的关系,核心目标从"模仿结果"到"模仿路径",最终到"内化过程",完美复刻了多智能体的推理能力:
- RSFT:基础层,保证单模型能生成连贯的推理轨迹并得到正确答案,是后续蒸馏的基础;
- DA:提升层,让单模型学会多视角推理,解决思路单一问题,提升鲁棒性;
- PAD:核心层,让单模型实现步骤级的自我纠错,内化多智能体的辩证推理过程,是效果最优、最能体现多智能体核心能力的策略。
三个策略可独立使用,也可组合使用(如RSFT+DA、PAD+DA),组合后能实现更稳定的性能提升,且整个框架对模型家族、数据集、任务类型的兼容性极强,还能扩展到多模态大模型,具有广泛的应用价值。
方法流程图与图解:
- 图1:AgentArk将多智能体系统的推理能力提炼为一个单一智能体,使得该单一单元能够模拟思考过程并提升性能。
- 图1解读:该图展示了AgentArk的核心思想,即将多智能体系统的复杂交互过程提炼为单一模型的内部能力。读者应关注左侧多智能体辩论与右侧单智能体模仿过程的对比。结论表明,通过这种提炼,单个智能体在保持低计算成本的同时,能够获得媲美多智能体系统的推理性能与自我修正能力,实现了效率与效果的平衡。
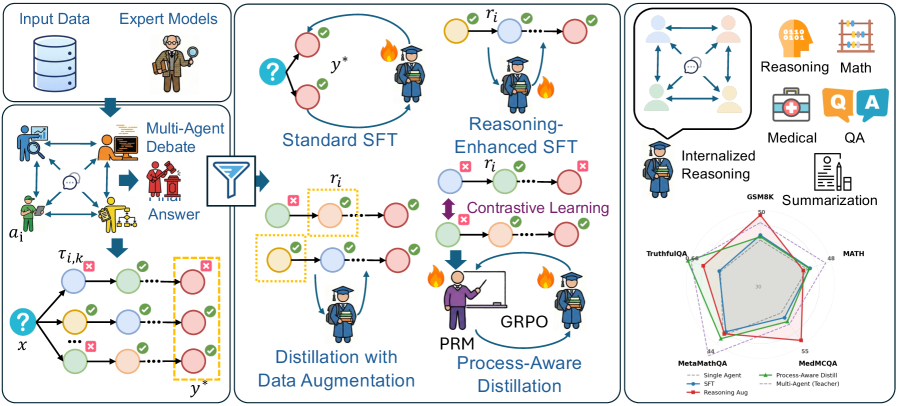
- 图2:AgentArk总览。该流程分为三个阶段:(1) 通过多智能体辩论进行数据生成,产生多样化的推理轨迹;(2) 知识提取,筛选高质量的修正轨迹;(3) 蒸馏,利用标准SFT、推理增强SFT、数据增强蒸馏和过程感知蒸馏。
- 图2解读:此图详述了AgentArk的三阶段流水线,读者应重点关注数据生成、知识提取及模型蒸馏三个模块的具体流程。图示展示了从多智能体辩论生成轨迹,到筛选高质量样本,最后通过多种策略进行知识蒸馏的全过程。结论指出,最终得到的学生模型能够在保证推理优化的同时,具备跨领域的泛化能力和低延迟特性,有效提升了实用性。
总结
当前多智能体系统研究已打破“数量越多、性能越强”的行业误区,相关研究表明,自组织多智能体团队常因专家知识利用不足、过度妥协共识产生专业知识稀释效应,难以实现超越最优个体的强协同,而AgentArk等蒸馏框架则为解决多智能体计算成本高、误差传播等问题提供了可行路径,通过将多智能体的辩论、纠错与推理能力内化到单个LLM中,实现了效果与效率的统一;未来,多智能体领域将从盲目堆叠规模转向更理性的协同机制设计与知识高效利用研究,在平衡协同性能与对抗鲁棒性的同时,持续推动轻量化、可部署、高泛化的智能系统落地,为复杂推理与实际应用提供更稳健高效的技术支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)