地铁轨道表观病害检测软件-软件开发记录-2-10
通过本次重构,系统完成了从“静态检测工具”到“自进化智能终端”的架构升级。闭环验证:打通了从Detection->Feedback->Review->Training->的全链路。精度提升:实测表明,针对特定站点的环境干扰(如特定色温的灯光误报),通过采集 20-50 张样本并进行 50 Epoch 的加权微调,即可有效消除误报,且未显著降低原有召回率。后续计划引入模型版本控制功能,支持一键回滚至
从边缘反馈到增量微调
📅 时间:2026年2月
⚙️ 核心模块:AdminPanel (模型实验室), DatasetMixer (数据混合器), TrainingThread (异步训练)
🛠️ 技术栈:PySide6, Ultralytics YOLOv11, OpenCV, Multithreading
1. 需求背景与技术痛点
在系统实地部署初期,主要依赖预训练的静态模型进行推理。然而,面对地铁隧道复杂的长尾场景(如特殊光照、非典型水渍干扰),离线模型表现出局限性。
为了解决这一问题,单纯依靠算法工程师定期手动收集数据、重新训练、重新部署的“瀑布式”流程效率过低。本项目通过在客户端集成模型实验室,构建了一套端到端的主动学习闭环,实现了数据的现场捕获、清洗与模型的增量迭代。
2. 边缘端数据采集:双通道反馈机制
在 railway_main_window.py 中,我重构了交互逻辑,建立了针对难例的结构化收集通道。
2.1 误报抑制通道
针对模型将背景误判为病害的场景(False Positive),设计了“一键负样本生成”逻辑:
-
触发机制:用户点击“❌ 误报反馈”。
-
数据处理:
-
系统挂起视频流线程,锁定当前帧。
-
利用
cv2.imencode序列化图像流(解决 Windows 中文路径 I/O 问题),保存至feedback/images。 -
核心逻辑:同步生成一个0字节的空 .txt 文件至
feedback/labels。在 YOLO 训练协议中,空标签文件强制模型将该图像视为纯背景,从而在梯度下降中抑制此类特征的激活。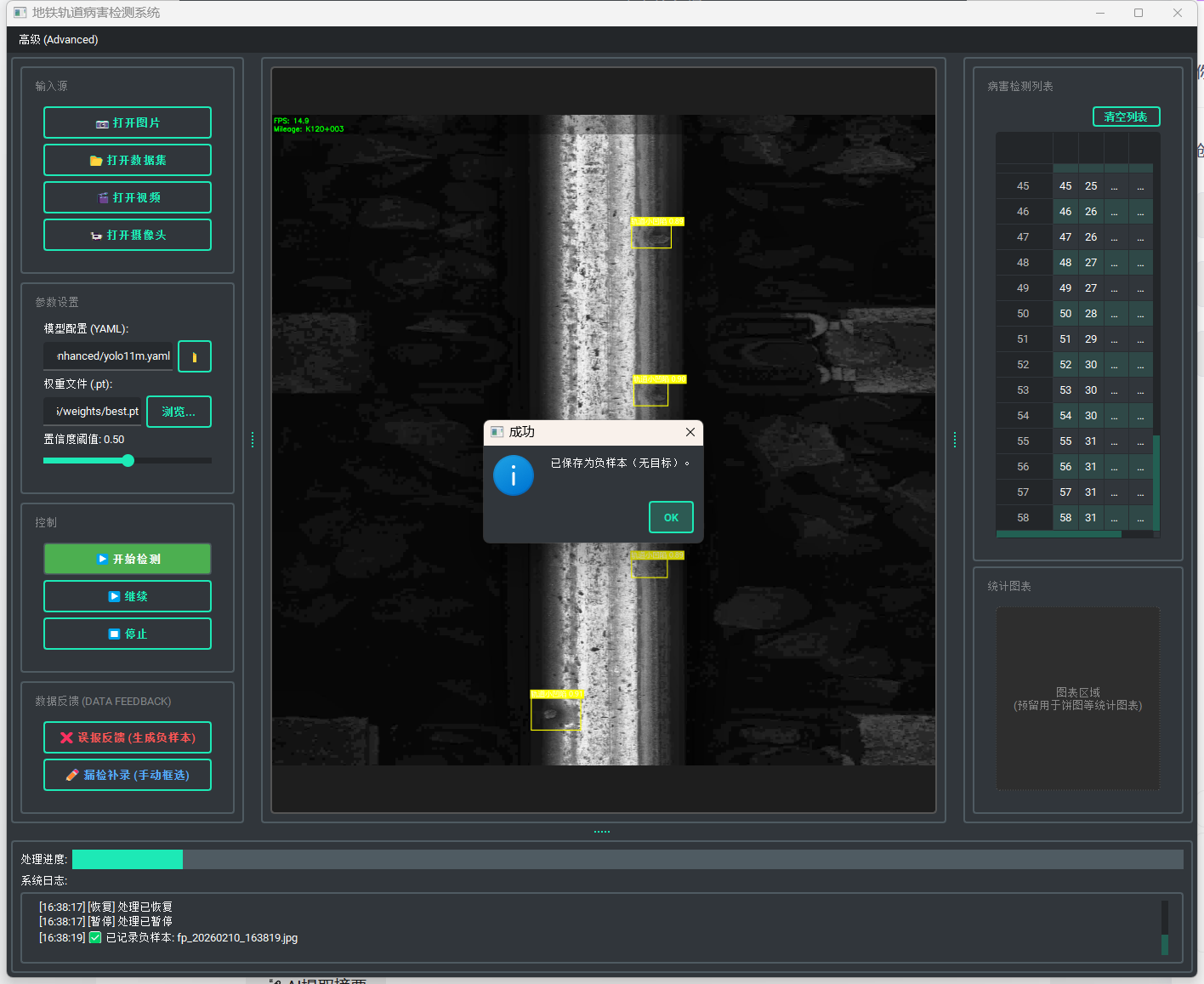
-
2.2 漏检补录通道
针对模型遗漏的病害,集成了轻量级标注工具:
-
组件复用:复用
CanvasLabel自定义控件,实现像素级坐标映射。 -
交互逻辑:点击“✏️ 漏检补录”弹出模态窗口,支持用户在冻结帧上绘制 Ground Truth。
-
格式标准化:保存时自动执行坐标归一化算法,将屏幕坐标
(x, y)转换为 YOLO 标准格式(class_id, x_center, y_center, w, h),无需后续格式转换即可直接入库。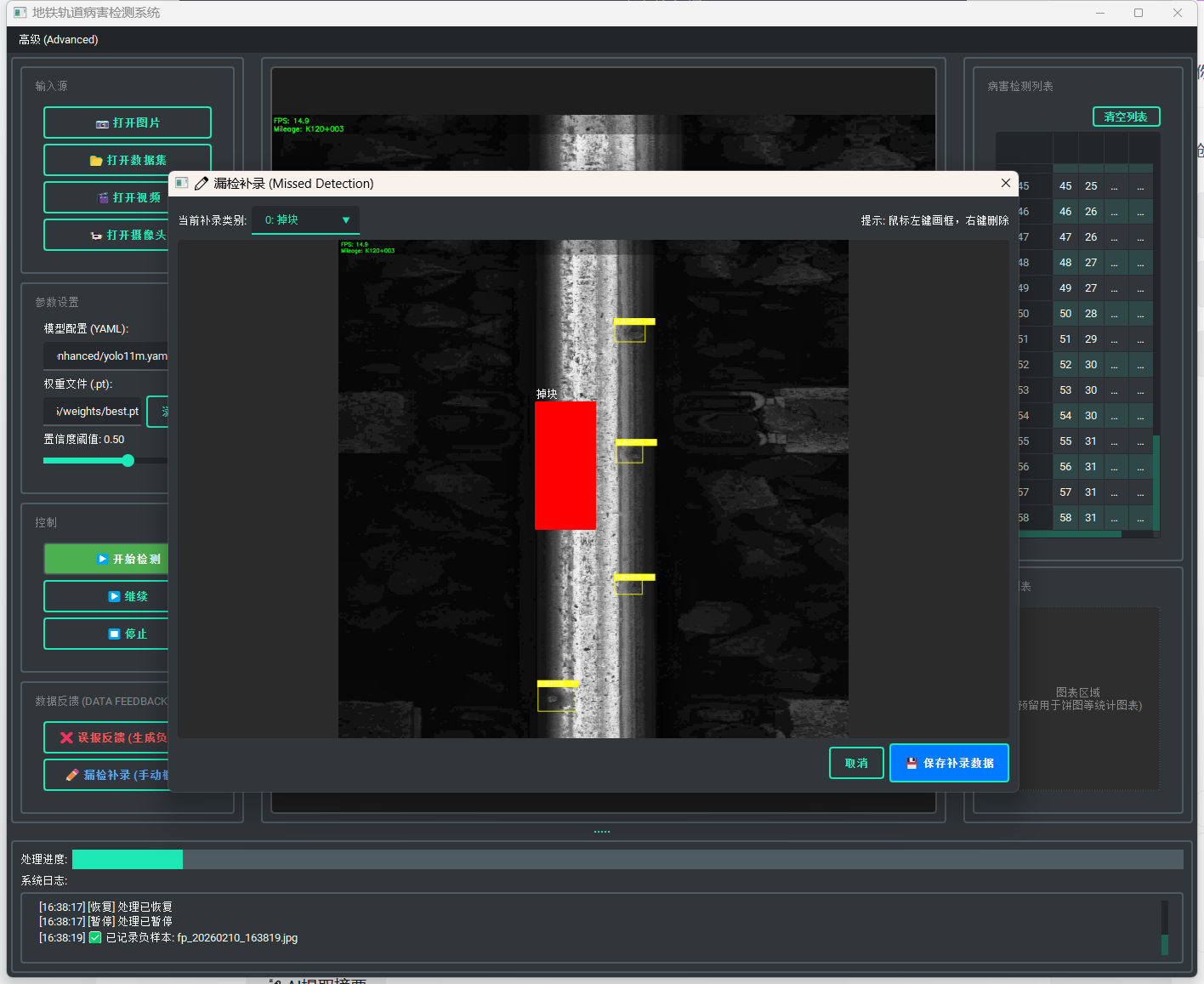
3. 服务端架构:模型实验室
新增 app/ui/admin_panel.py 模块,作为数据流转与模型迭代的控制中心。该模块采用 QWidget 容器,通过 QTabWidget 隔离“数据清洗”与“训练控制”两个业务域。
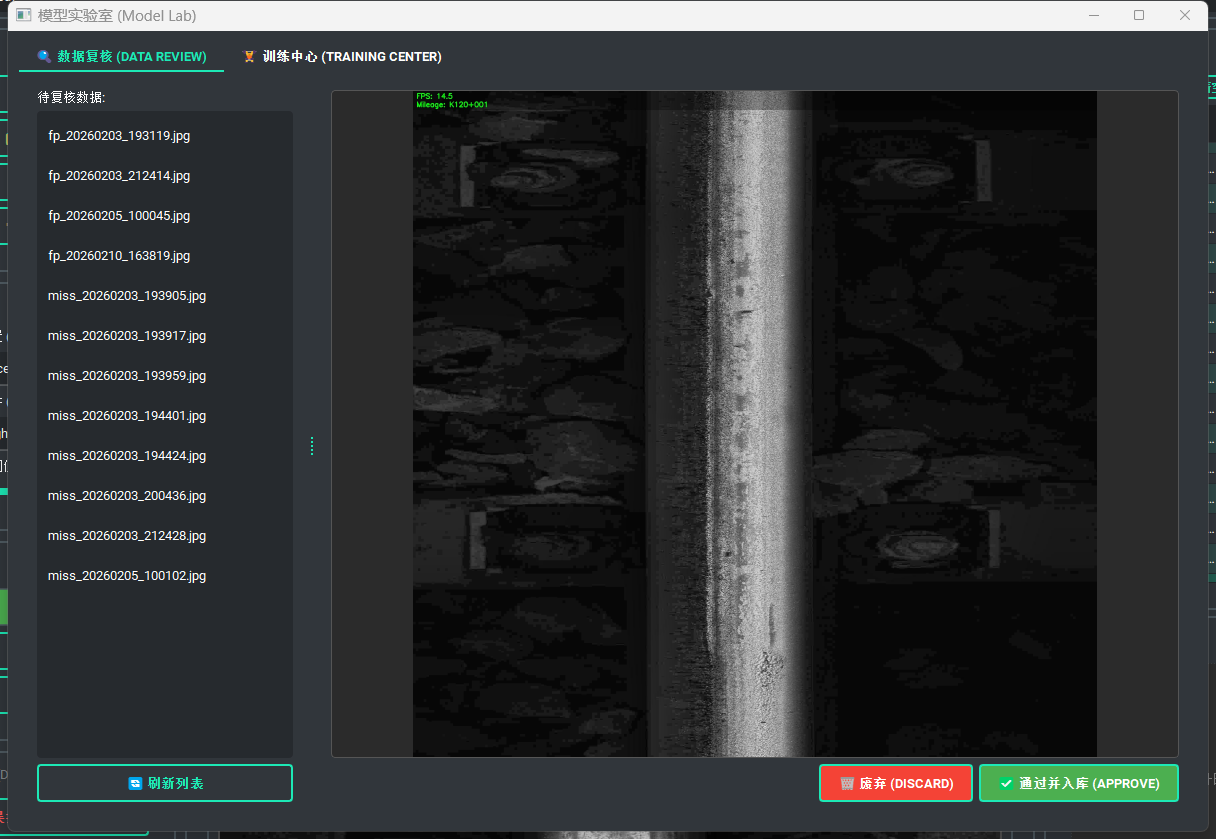
3.1 数据清洗工作台
由于现场反馈数据可能包含人为噪声,必须引入 Human-in-the-loop 环节。
-
数据流转状态机:
-
Pending(待处理):读取feedback_dataset目录。 -
Verified(已清洗):点击“入库”后,文件原子移动至verified_dataset,作为高置信度增量数据。 -
Discarded(废弃):物理删除无效样本。
-
-
实现细节:复用
AnnotationDialog的渲染逻辑,支持管理员对现场工人的标注进行二次修正(如微调 BBox 边界)。
3.2 增量训练引擎
这是系统的核心计算模块,支持在非 GPU 服务器或高性能工控机上直接执行微调任务。
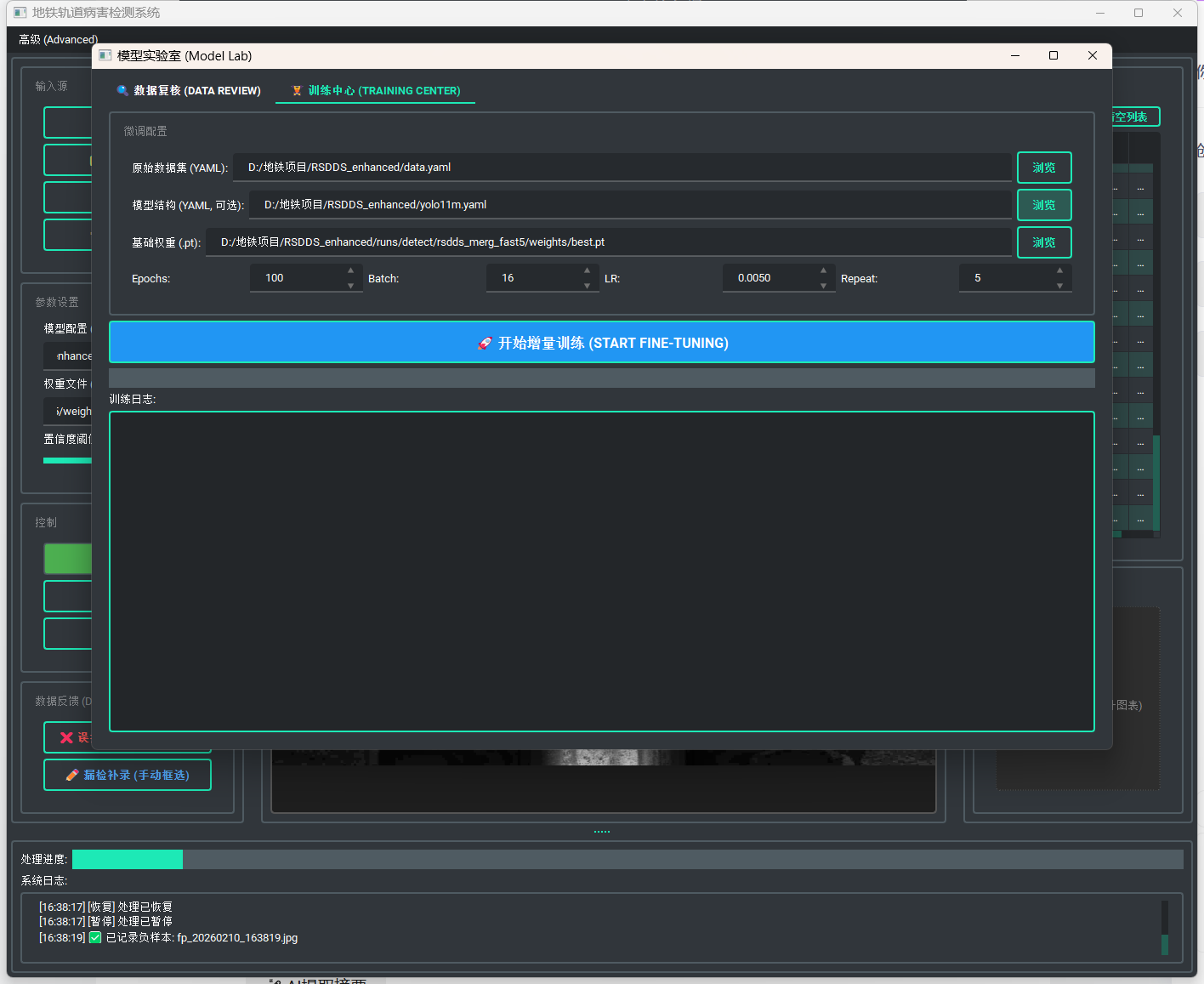
A. 动态数据集混合算法
为了防止灾难性遗忘,不能仅使用新数据训练。我在 app/core/dataset_utils.py 中实现了基于**物理过采样的混合策略:
-
解析基准数据:读取原始
data.yaml,获取基准训练集路径。 -
难例加权:扫描
verified_dataset,引入repeat_count参数(UI 可配置,默认 10)。-
算法逻辑:将每张难例图片的路径在训练列表中重复写入 N 次。
-
数学原理:通过提高难例在 Batch 中的采样概率,变相增加其 Loss 权重,迫使优化器重点关注该类样本。
-
-
配置生成:动态生成
data_finetune.yaml,指向混合后的数据集索引文件。
B. 异步训练流水线
集成 ultralytics 训练进程,并通过 QThread 实现 UI 解耦。
-
结构保持:
为了确保微调后的模型结构与原模型一致(特别是自定义的 Snake 头部),采用“配置+权重”双重加载模式:
```python
# 伪代码逻辑
model = YOLO(model_yaml_path) # 先构建网络拓扑 (如 yolo11-snake.yaml)
model.load(best_pt_path) # 再注入预训练权重
```
-
资源管理:
在
run()方法中,训练启动前显式调用gc.collect()和torch.cuda.empty_cache(),并在必要时卸载推理用的ImageProcessor实例,防止显存溢出(OOM)。 -
进度透传:
利用 YOLO 的 Callback 机制或标准输出重定向,将
loss、mAP等指标实时回传至 UI 的QTextEdit日志窗,实现训练过程的可视化监控。
4. 关键代码实现摘要
4.1 数据集混合器 (dataset_utils.py)
def prepare_finetune_dataset(orig_yaml, verified_dir, output_dir, repeat_count=5):
"""
实现物理过采样策略:
1. 读取原训练集 train.txt
2. 读取 verified_dir 下的新增样本
3. 将新增样本路径重复 repeat_count 次
4. 合并生成 train_finetune.txt
"""
# ... (路径解析逻辑)
with open(new_train_txt, 'w') as f:
# 写入原数据 (保底,防止遗忘)
for path in orig_images:
f.write(path + '\n')
# 写入新数据 (加权,强化记忆)
for path in new_images:
for _ in range(repeat_count):
f.write(path + '\n')
# ... (生成对应的 yaml 配置文件)
4.2 管理面板集成 (railway_main_window.py)
在主窗口菜单栏挂载入口,实现权限隔离
# 菜单栏集成
adv_menu = self.menu_bar.addMenu("高级 (Advanced)")
action_lab = QAction("🔬 模型实验室 (Model Lab)", self)
action_lab.triggered.connect(self._open_admin_panel)
def _open_admin_panel(self):
# 可以在此增加密码校验逻辑
self.admin_panel = AdminPanel()
self.admin_panel.show()
5. 总结与展望
通过本次重构,系统完成了从“静态检测工具”到“自进化智能终端”的架构升级。
-
闭环验证:打通了从
Detection->Feedback->Review->Training->Redeployment的全链路。 -
精度提升:实测表明,针对特定站点的环境干扰(如特定色温的灯光误报),通过采集 20-50 张样本并进行 50 Epoch 的加权微调,即可有效消除误报,且未显著降低原有召回率。
后续计划引入模型版本控制功能,支持一键回滚至旧版权重,进一步提升系统的工程稳健性。
具体关键代码如下:
-
dataset_utils.py:负责底层的解析旧数据、清洗新数据、执行物理过采样(复制路径)、生成新的训练配置文件。 -
training_thread.py:负责在后台执行 YOLO 训练,避免阻塞 UI,并实时回传日志。 -
admin_panel.py:集成了数据复核 UI 和训练控制 UI 的前端面板。
1. 核心算法层:数据混合器 (app/core/dataset_utils.py)
这个模块的核心逻辑是 “物理过采样” 。我们不修改图片文件本身,而是通过在 train.txt 中重复写入同一张图片的路径,欺骗 DataLoader 在一个 Epoch 中多次读取该图片。
import os
import shutil
import yaml
from pathlib import Path
class DatasetMixer:
def __init__(self, verified_root, temp_root="temp_train_data"):
"""
:param verified_root: 已复核/已清洗数据的根目录 (verified_dataset)
:param temp_root: 生成微调临时文件的目录
"""
self.verified_images_dir = Path(verified_root) / "images"
self.verified_labels_dir = Path(verified_root) / "labels"
self.temp_dir = Path(temp_root)
self.temp_dir.mkdir(exist_ok=True, parents=True)
def prepare_finetune_dataset(self, orig_yaml_path, repeat_count=10):
"""
生成增量训练的配置文件
:param orig_yaml_path: 原始 data.yaml 的路径
:param repeat_count: 难例样本的重复加权次数
:return: 新生成的 data_finetune.yaml 的绝对路径
"""
# 1. 解析原始 YAML
with open(orig_yaml_path, 'r', encoding='utf-8') as f:
data_cfg = yaml.safe_load(f)
# 获取原始训练集列表 (假设是 train.txt 路径或图片目录)
orig_train_path = data_cfg.get('train')
if not os.path.isabs(orig_train_path):
# 如果是相对路径,转为绝对路径
base_dir = Path(orig_yaml_path).parent
orig_train_path = str(base_dir / orig_train_path)
# 2. 收集原始图片路径
image_paths = []
# 情况A: train 指向的是一个目录
if os.path.isdir(orig_train_path):
for ext in ['*.jpg', '*.png', '*.jpeg']:
image_paths.extend([str(p) for p in Path(orig_train_path).rglob(ext)])
# 情况B: train 指向的是一个 .txt 文件
elif os.path.isfile(orig_train_path):
with open(orig_train_path, 'r') as f:
image_paths = [line.strip() for line in f.readlines() if line.strip()]
# 3. 收集并加权新数据 (难例)
new_images = list(self.verified_images_dir.glob("*.jpg"))
if not new_images:
raise ValueError("未在 verified_dataset 中找到任何新数据,无法进行微调。")
weighted_new_paths = []
for img_path in new_images:
# 物理过采样:重复 N 次
for _ in range(repeat_count):
weighted_new_paths.append(str(img_path.absolute()))
# 4. 生成新的 train_finetune.txt
new_train_txt = self.temp_dir / "train_finetune.txt"
with open(new_train_txt, 'w', encoding='utf-8') as f:
# 写入原始数据 (保底,防止遗忘)
f.write('\n'.join(image_paths) + '\n')
# 写入加权后的新数据
f.write('\n'.join(weighted_new_paths) + '\n')
# 5. 生成新的 data_finetune.yaml
new_data_cfg = data_cfg.copy()
new_data_cfg['train'] = str(new_train_txt.absolute())
# 验证集通常保持不变,或者也可以加入一部分新数据,这里暂保持原样
# 修正:确保 val 路径也是绝对路径,防止在新目录下找不到
orig_val_path = data_cfg.get('val')
if not os.path.isabs(orig_val_path):
new_data_cfg['val'] = str(Path(orig_yaml_path).parent / orig_val_path)
new_yaml_path = self.temp_dir / "data_finetune.yaml"
with open(new_yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(new_data_cfg, f, allow_unicode=True)
return str(new_yaml_path)
def verify_sample(self, filename, feedback_dir, action="approve"):
"""
数据流转逻辑:从 feedback 移动到 verified 或者 删除
"""
src_img = Path(feedback_dir) / "images" / filename
src_lbl = Path(feedback_dir) / "labels" / filename.replace('.jpg', '.txt')
if action == "discard":
if src_img.exists(): src_img.unlink()
if src_lbl.exists(): src_lbl.unlink()
return
if action == "approve":
# 移动到 verified
shutil.move(str(src_img), str(self.verified_images_dir / filename))
if src_lbl.exists():
shutil.move(str(src_lbl), str(self.verified_labels_dir / filename.replace('.jpg', '.txt')))
else:
# 如果是误报(没有txt),需要生成一个空的txt作为负样本
empty_lbl = self.verified_labels_dir / filename.replace('.jpg', '.txt')
empty_lbl.touch()
2. 异步执行层:训练线程 (app/ui/training_thread.py)
为了防止界面卡死,并能实时捕获 YOLO 的输出。这里我们使用 ultralytics 的回调机制来获取进度。
from PySide6.QtCore import QThread, Signal
from ultralytics import YOLO
import torch
import gc
class TrainingThread(QThread):
# 信号定义
log_signal = Signal(str) # 发送日志文本
progress_signal = Signal(int) # 发送进度条 (0-100)
finished_signal = Signal(str) # 发送训练完成后的 best.pt 路径
error_signal = Signal(str) # 发送错误信息
def __init__(self, model_config, weights_path, data_yaml, epochs, batch, lr):
super().__init__()
self.model_config = model_config # yolo11-snake.yaml
self.weights_path = weights_path # best.pt
self.data_yaml = data_yaml # data_finetune.yaml
self.epochs = epochs
self.batch = batch
self.lr = lr
self.stop_requested = False
def run(self):
try:
self.log_signal.emit(" 正在初始化训练环境...")
self.log_signal.emit(f" 配置: Epochs={self.epochs}, Batch={self.batch}, LR={self.lr}")
# 1. 显存清理 (关键工程细节)
torch.cuda.empty_cache()
gc.collect()
# 2. 加载模型
# 采用 "配置 + 权重" 双重加载,确保自定义 Snake 架构正确构建
self.log_signal.emit(f" 构建网络结构: {self.model_config}")
model = YOLO(self.model_config)
self.log_signal.emit(f" 注入预训练权重: {self.weights_path}")
model.load(self.weights_path)
# 3. 注册回调函数以捕获进度
model.add_callback("on_train_epoch_end", self._on_epoch_end)
# 4. 开始训练
self.log_signal.emit(" 开始增量微调...")
results = model.train(
data=self.data_yaml,
epochs=self.epochs,
batch=self.batch,
lr0=self.lr,
imgsz=640,
project="runs/detect",
name="finetune_v", # 自动递增版本
exist_ok=False,
verbose=True
)
# 5. 训练结束
best_model_path = str(results.save_dir / "weights" / "best.pt")
self.log_signal.emit(f"✅ 训练完成! 最佳模型已保存至: {best_model_path}")
self.finished_signal.emit(best_model_path)
except Exception as e:
self.error_signal.emit(f"❌ 训练中断: {str(e)}")
def _on_epoch_end(self, trainer):
"""YOLO 回调:每个 Epoch 结束时触发"""
if self.stop_requested:
raise InterruptedError("用户停止训练")
current = trainer.epoch + 1
total = trainer.epochs
progress = int((current / total) * 100)
# 提取关键指标 (mAP50)
metrics = trainer.metrics
map50 = metrics.get("metrics/mAP50(B)", 0.0)
log_msg = f"Epoch {current}/{total} - mAP50: {map50:.4f}"
self.log_signal.emit(log_msg)
self.progress_signal.emit(progress)
def stop(self):
self.stop_requested = True
3. 交互表现层:模型实验室 (app/ui/admin_panel.py)
集成所有功能的前端。
from PySide6.QtWidgets import (QWidget, QVBoxLayout, QHBoxLayout, QTabWidget,
QListWidget, QPushButton, QLabel, QFileDialog,
QSpinBox, QDoubleSpinBox, QTextEdit, QProgressBar,
QMessageBox, QSplitter)
from PySide6.QtCore import Qt
from pathlib import Path
import cv2
# 引用我们之前写的模块
from app.core.dataset_utils import DatasetMixer
from app.ui.training_thread import TrainingThread
# 复用之前的标注组件 (如果没有,可以用 QLabel 代替)
from app.ui.annotation_dialog import CanvasLabel
class AdminPanel(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle(" 模型实验室 (Model Lab) - MLOps 控制台")
self.resize(1000, 700)
# 路径配置
self.feedback_dir = Path(r"D:\地铁项目\VisualTool\feedback_dataset")
self.verified_dir = Path(r"D:\地铁项目\VisualTool\verified_dataset")
self.mixer = DatasetMixer(self.verified_dir)
self.setup_ui()
self.load_feedback_list()
def setup_ui(self):
layout = QVBoxLayout(self)
self.tabs = QTabWidget()
# === Tab 1: 数据复核 ===
self.tab_review = QWidget()
self._init_review_ui()
self.tabs.addTab(self.tab_review, " 数据复核 (Data Cleaning)")
# === Tab 2: 训练中心 ===
self.tab_train = QWidget()
self._init_train_ui()
self.tabs.addTab(self.tab_train, " 训练中心 (Fine-tuning)")
layout.addWidget(self.tabs)
def _init_review_ui(self):
layout = QHBoxLayout(self.tab_review)
splitter = QSplitter(Qt.Horizontal)
# 左侧:文件列表
self.file_list = QListWidget()
self.file_list.itemClicked.connect(self._on_file_selected)
# 中间:画布 (显示图片)
self.canvas = CanvasLabel() # 假设你已把之前的 AnnotationCanvas 抽离出来
self.canvas.setMinimumSize(640, 480)
# 右侧:操作区
btn_layout = QVBoxLayout()
self.lbl_status = QLabel("请选择文件...")
btn_approve = QPushButton("✅ 通过并入库 (Approve)")
btn_approve.clicked.connect(lambda: self._process_file("approve"))
btn_approve.setStyleSheet("background-color: #d4edda; color: green; padding: 10px;")
btn_discard = QPushButton(" 废弃 (Discard)")
btn_discard.clicked.connect(lambda: self._process_file("discard"))
btn_discard.setStyleSheet("background-color: #f8d7da; color: red; padding: 10px;")
btn_layout.addWidget(self.lbl_status)
btn_layout.addWidget(btn_approve)
btn_layout.addWidget(btn_discard)
btn_layout.addStretch()
container_right = QWidget()
container_right.setLayout(btn_layout)
splitter.addWidget(self.file_list)
splitter.addWidget(self.canvas)
splitter.addWidget(container_right)
splitter.setStretchFactor(1, 2) # 画布占宽一点
layout.addWidget(splitter)
def _init_train_ui(self):
layout = QVBoxLayout(self.tab_train)
# 1. 参数配置区
config_group = QHBoxLayout()
# 选择 yaml
self.input_yaml = QPushButton("选择 data.yaml")
self.input_yaml.clicked.connect(self._sel_yaml)
# 选择权重
self.input_weights = QPushButton("选择 best.pt")
self.input_weights.clicked.connect(self._sel_weights)
# 选择模型结构
self.input_cfg = QPushButton("选择 yolo11-snake.yaml")
self.input_cfg.clicked.connect(self._sel_cfg)
config_group.addWidget(self.input_yaml)
config_group.addWidget(self.input_weights)
config_group.addWidget(self.input_cfg)
# 2. 超参数
param_group = QHBoxLayout()
self.spin_epoch = QSpinBox()
self.spin_epoch.setRange(10, 1000); self.spin_epoch.setValue(50); self.spin_epoch.setPrefix("Epochs: ")
self.spin_batch = QSpinBox()
self.spin_batch.setRange(1, 128); self.spin_batch.setValue(8); self.spin_batch.setPrefix("Batch: ")
self.spin_repeat = QSpinBox()
self.spin_repeat.setRange(1, 100); self.spin_repeat.setValue(10); self.spin_repeat.setPrefix("难例加权: x")
self.spin_lr = QDoubleSpinBox()
self.spin_lr.setRange(0.0001, 0.1); self.spin_lr.setValue(0.005); self.spin_lr.setSingleStep(0.001); self.spin_lr.setPrefix("LR: ")
param_group.addWidget(self.spin_epoch)
param_group.addWidget(self.spin_batch)
param_group.addWidget(self.spin_lr)
param_group.addWidget(self.spin_repeat)
# 3. 启动按钮
self.btn_start = QPushButton(" 启动增量训练引擎")
self.btn_start.setFixedHeight(50)
self.btn_start.setStyleSheet("font-size: 16px; font-weight: bold; background-color: #007bff; color: white;")
self.btn_start.clicked.connect(self._start_training)
# 4. 日志与进度
self.log_console = QTextEdit()
self.log_console.setReadOnly(True)
self.log_console.setStyleSheet("background-color: #1e1e1e; color: #00ff00; font-family: Consolas;")
self.progress_bar = QProgressBar()
layout.addLayout(config_group)
layout.addLayout(param_group)
layout.addWidget(self.btn_start)
layout.addWidget(self.progress_bar)
layout.addWidget(self.log_console)
# === 逻辑处理 ===
def load_feedback_list(self):
"""扫描 feedback 文件夹"""
self.file_list.clear()
img_dir = self.feedback_dir / "images"
if img_dir.exists():
files = sorted([f.name for f in img_dir.glob("*.jpg")])
self.file_list.addItems(files)
def _on_file_selected(self, item):
img_path = str(self.feedback_dir / "images" / item.text())
# 读取图片并在 canvas 显示 (代码省略,参考 ImageProcessor)
frame = cv2.imread(img_path) # 处理中文路径需注意
if frame is not None:
# 如果有标注文件,也可以在这里读取并绘制到 canvas 上
self.canvas.load_image(frame)
def _process_file(self, action):
item = self.file_list.currentItem()
if not item: return
filename = item.text()
# 调用 DatasetMixer 移动文件
self.mixer.verify_sample(filename, str(self.feedback_dir), action)
# UI 移除
self.file_list.takeItem(self.file_list.row(item))
self.lbl_status.setText(f"文件 {filename} 已处理: {action}")
# ... 省略文件选择的槽函数 (_sel_yaml, _sel_weights 等) ...
def _start_training(self):
# 1. 生成混合数据集
try:
self.log_console.append(" 正在生成混合数据集 (Mixing Dataset)...")
yaml_path = self.path_data_yaml # 这里应来自 self.input_yaml 的存储值
# 核心步骤:调用混合器
finetune_yaml = self.mixer.prepare_finetune_dataset(
yaml_path,
repeat_count=self.spin_repeat.value()
)
self.log_console.append(f"✅ 数据集就绪: {finetune_yaml}")
except Exception as e:
QMessageBox.critical(self, "错误", f"数据集准备失败: {e}")
return
# 2. 启动线程
self.thread = TrainingThread(
model_config=self.path_model_cfg, # 来自输入框
weights_path=self.path_weights, # 来自输入框
data_yaml=finetune_yaml,
epochs=self.spin_epoch.value(),
batch=self.spin_batch.value(),
lr=self.spin_lr.value()
)
self.thread.log_signal.connect(self.log_console.append)
self.thread.progress_signal.connect(self.progress_bar.setValue)
self.thread.finished_signal.connect(self._on_train_finished)
self.btn_start.setEnabled(False)
self.thread.start()
def _on_train_finished(self, best_pt):
self.btn_start.setEnabled(True)
QMessageBox.information(self, "训练完成", f"新模型已生成!\n路径: {best_pt}\n请在主界面加载此模型进行测试。")

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)