AAAI‘26 Oral | 检索前先「懂用户」!PBR 框架:个性化查询扩展让 AI 应用实现千人千面
PBR的目标是对信息不充分的用户查询 q 进行扩展,生成个性化查询,使其在检索用户历史语料库 H时,不仅匹配词汇语义,更能对齐用户潜在意图。形式化来说,通过固定编码器将查询和用户历史编码为向量,最终要构建转换函数,让个性化查询,其中就是编码了用户表达风格、语料结构的个性化调整量,这也是PBR框架要解决的核心。PBR并非通用RAG的替代方案,而是个性化RAG场景的精准优化方案存在用户专属语料/历史交
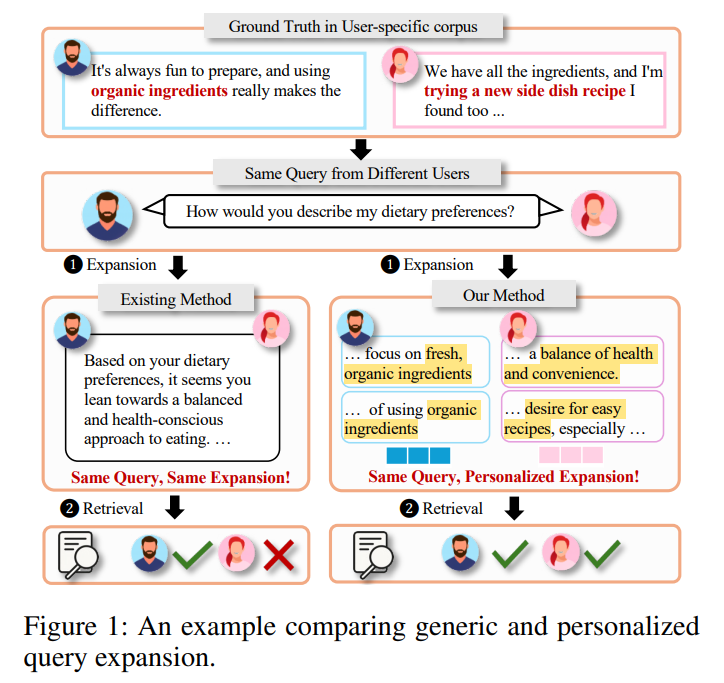
来自大连理工大学、香港城市大学、中国科学技术大学和华为的团队于2026 AAAI 提出PBR(Personalize Before Retrieve)框架,首个针对RAG系统的个性化查询扩展方案,在检索前就将用户专属信号融入查询表示,解决了通用查询扩展的“表征僵化”问题,为个性化RAG的落地提供了全新思路。

在检索增强生成(RAG)成为大模型能力提升核心范式的当下,查询扩展的质量直接决定了检索的准确性。但现有方法都采用“一刀切”的统一策略,完全忽略了用户的表达风格、个性化偏好和历史交互背景——同样一句“说说我的饮食偏好”,注重健康的用户和喜欢尝鲜的用户想表达的意图天差地别。
这种 “表征僵化” 的问题,在智能助手、私人知识库、个性化推荐等场景中尤为突出,直接导致 RAG 系统 “懂知识但不懂用户”,难以满足人们对个性化交互的核心需求。而在 AI 应用愈发强调 “用户中心” 的当下,个性化的价值早已不言而喻 —— 用户的专属需求往往隐藏在表达风格与历史交互的细节中,越早精准捕捉、越深度适配,后续的检索准确性与生成贴合度自然越突出,这也是众多开发者在打造 Memory 系统、用户画像等功能时的核心追求。
针对这一痛点,来自大连理工大学、香港城市大学、中国科学技术大学和华为的团队于2026 AAAI 提出PBR(Personalize Before Retrieve)框架,首个针对RAG系统的个性化查询扩展方案,在检索前就将用户专属信号融入查询表示,解决了通用查询扩展的“表征僵化”问题,为个性化RAG的落地提供了全新思路。
论文地址:https://arxiv.org/pdf/2510.08935
代码地址:https://github.com/Applied-Machine-Learning-Lab/PBR-code01、为什么需要个性化的查询扩展?
通用RAG的查询扩展之所以在个性化场景失效,核心源于两个关键挑战:
- 用户表达风格的多样性:有人说话简洁,有人喜欢详细推理,这些隐含的语言模式无法被通用扩展捕捉,导致个性化意图丢失;
- 用户语料库的异构性:每个用户的历史语料在主题、内容组织、词汇使用上差异极大,通用方法难以将查询锚定到用户的专属语义空间。
举个简单的例子,两个用户都问“如何描述我的饮食偏好?”,通用扩展只会生成“注重健康和便捷”这类泛化答案,而PBR能根据用户历史,为常提“有机食材”的用户生成贴合其风格的个性化扩展,让检索结果精准匹配用户真实意图。
而现有研究要么在查询扩展中忽视个性化,要么在个性化RAG中只关注检索后阶段,检索前的个性化优化始终是空白,PBR框架恰好填补了这一缺口。
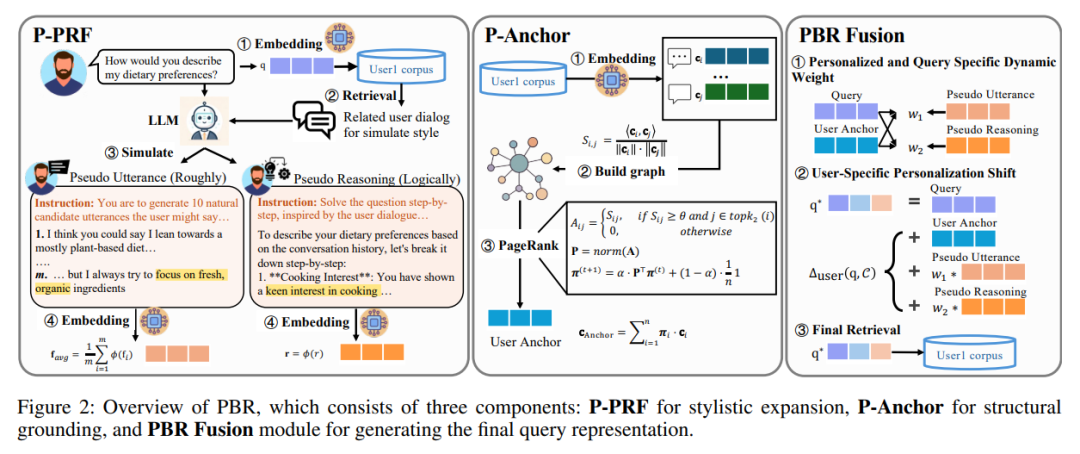
02、PBR框架:检索前的双重个性化改造
PBR的核心思路是在检索前完成查询的个性化重构,让查询既贴合用户的表达风格,又锚定到用户语料的语义结构。整个框架包含三个核心模块:P-PRF(个性化风格对齐伪相关反馈)、P-Anchor(个性化结构对齐语义锚定)和PBR Fusion(融合模块),三者协同生成最终的个性化查询表示
![]()
先明确:个性化查询扩展的问题定义
PBR的目标是对信息不充分的用户查询 q 进行扩展,生成个性化查询
![]()
,使其在检索用户历史语料库 H 时,不仅匹配词汇语义,更能对齐用户潜在意图。
形式化来说,通过固定编码器
![]()
将查询和用户历史编码为向量,最终要构建转换函数
![]()
,让个性化查询
![]()
,其中
![]()
就是编码了用户表达风格、语料结构的个性化调整量,这也是PBR框架要解决的核心。
模块1:P-PRF——让查询贴合用户的表达风格
P-PRF的作用是模拟用户的语言习惯,生成风格对齐的伪反馈,分为伪表述生成和伪推理生成两步,且只使用与当前查询语义相关的用户历史子集,避免无效信息干扰。
- 伪表述生成:基于用户相关历史
,让LLM生成多个符合用户语气、措辞风格的伪查询,比如用户喜欢说“新鲜有机食材”,就不会生成生硬的官方表述,最后对这些伪表述做嵌入平均,得到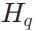
;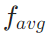
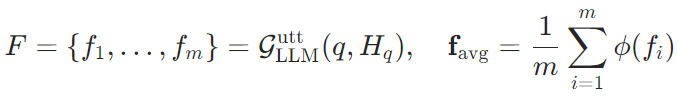

- 伪推理生成:除表面表达方式外,有效的个性化还需要建模用户的隐含推理过程。因此,伪推理生成模拟用户的思考方式,生成分步的推理逻辑 r ,补充表面查询中缺失的逻辑线索,比如用户习惯从“食材选择-烹饪方式”分析饮食,推理过程也会遵循这一模式。
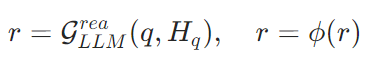

这两步分别从表层表达和深层推理复刻用户风格,让扩展后的查询不再是“通用模板”,而是用户“会说的话”。
模块2:P-Anchor——让查询锚定用户的语料结构
如果说P-PRF解决了“风格”问题,P-Anchor则解决了“结构”问题,将查询锚定到用户语料库的核心语义区域,步骤如下:
- 构建用户语义图:把用户历史语料的嵌入作为节点,节点间的余弦相似度作为边,再构建稀疏邻接矩阵,只保留相似度高于阈值 θ 的前
个邻居,过滤噪声;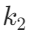
- PageRank找核心锚点:在语义图上运行PageRank算法,计算每个节点的中心性,找到用户语料的核心语义锚点
;
- 锚定个性化语义:这个核心锚点编码了用户语料的结构特征,让查询不再在通用语义空间漂移,而是牢牢扎根在用户的专属语义空间。
模块3:PBR Fusion——融合风格与结构,生成最终查询
这一步的核心是动态平衡P-PRF的风格信号和P-Anchor的结构信号,因为不同查询、不同用户下,两类信号的重要性不同。
首先计算两个动态权重
![]()
![]()
,分别量化伪表述、伪推理与“查询+锚点”融合语义的相似度;
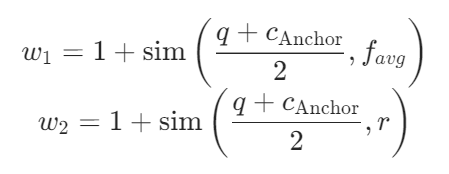
再通过权重整合锚点、伪表述、伪推理,得到个性化调整量
![]()
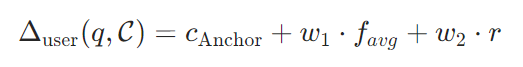
最后将原始查询与调整量相加,得到最终的个性化查询。
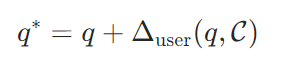
整个融合过程既保证了风格的贴合,又实现了语义的锚定,最终基于FAISS用
![]()
从用户语料中检索,大幅提升检索的精准度。
03、实验验证
为了验证PBR的有效性,团队围绕三个核心研究问题设计了实验:
PBR是否提升个性化检索性能?
两个核心模块的单独贡献是什么?
P-Anchor的参数如何影响检索效果?
实验设置
- 数据集:选用两个个性化检索专属基准
PersonaBench:6个用户的专属语料库,共263个意图模糊的个性化查询,侧重软个性化(偏好、社交特征);
LongMemEval:500个事实性查询,分稀疏历史(LME-s)和密集历史(LME-m)子集,侧重长语境下的硬事实锚定; - 基线方法:对比6种主流查询扩展/检索方法(Base、HyDE、Query2Term、MILL、CoT、ThinkQE);
- 评估指标:采用检索领域标准的Recall@K(R@K)和NDCG@K(N@K),衡量检索的召回率和排序质量。
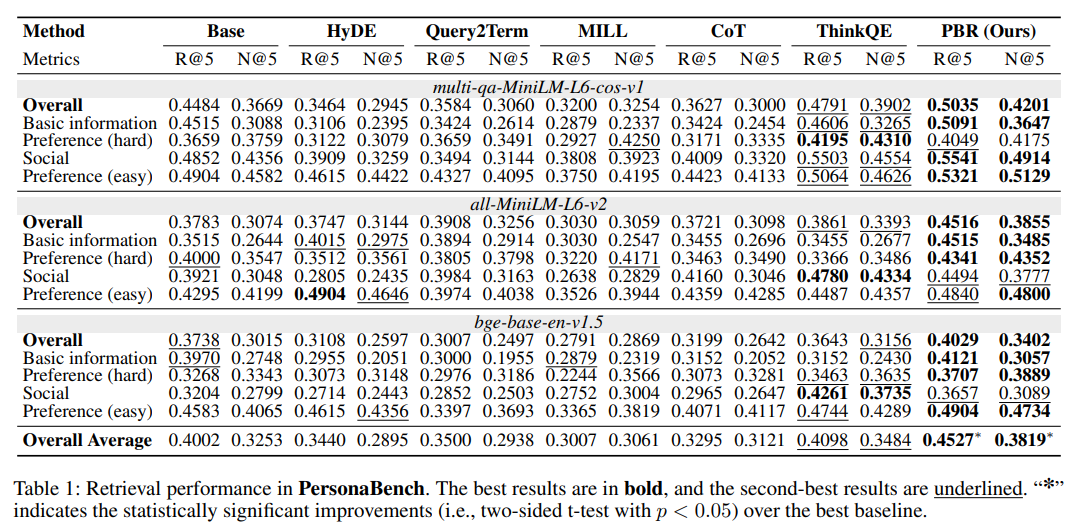
RQ1:整体性能
PBR在两个基准数据集上均取得了最优的整体性能,且显著优于所有基线方法(p<0.05):
- 在PersonaBench上,PBR的整体R@5达到0.4527、N@5达到0.3819,远超最优基线ThinkQE(0.4098/0.3484),成功解决了查询的语义歧义问题;
- 在LongMemEval上,PBR的top-1精度提升尤为突出:bge骨干下,LME-s的R@1达0.2315、LME-m达0.1408,均高于最优基线,即使在长语境密集历史下,也能精准将正确答案推至top-1。
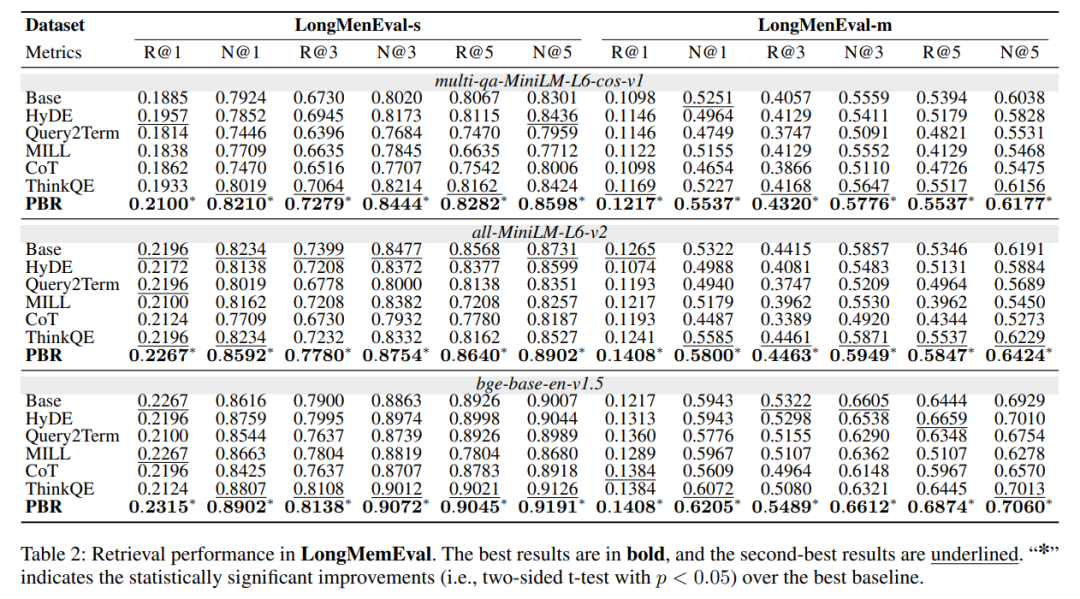
这一结果证明,检索前的个性化改造能从根本上提升RAG在个性化场景的检索能力。
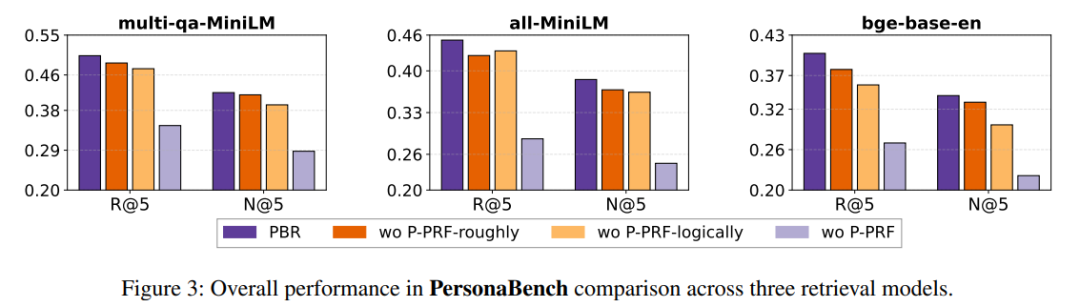
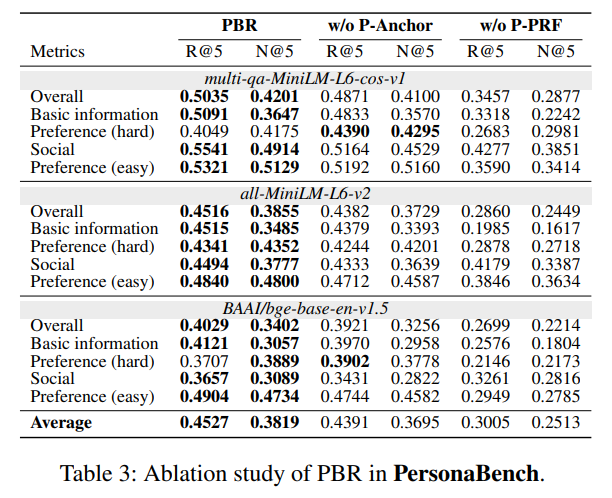
RQ2:消融实验
为了验证P-PRF和P-Anchor的单独贡献,团队做了全面的消融实验,结果十分明确:
- P-PRF是性能核心:移除P-PRF后,所有骨干模型的性能大幅暴跌(如all-MiniLM的R@5从0.4516降至0.2860),且伪表述和伪推理的任一组件缺失,都会导致性能下降——前者损失词汇覆盖,后者削弱推理能力;
- P-Anchor是性能保障:移除P-Anchor后,性能出现持续下降,尤其在用户语料结构清晰的任务(基础信息、社交特征)中更明显;但在非聚类的硬性偏好任务中,效果有限,避免了过拟合;
- 两者互补:同时移除两个模块,性能会进一步下降,证明风格模拟和结构锚定是个性化查询扩展的两大支柱,缺一不可。
RQ3:参数敏感性
针对P-Anchor的两个核心参数(语义阈值 θ 、邻居数
![]()
)做敏感性分析,得到了实用的调参结论:
- 当 θ∈[0.65,0.75] 且
=5时,检索性能达到峰值,适度的语义邻域传播能实现最优的锚定效果;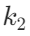
- 当 θ 和
过大时,性能会饱和甚至下降,因为过度传播会引入噪声,削弱语义对齐的特异性。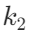
这一结论为PBR的实际落地提供了明确的参数设置参考。
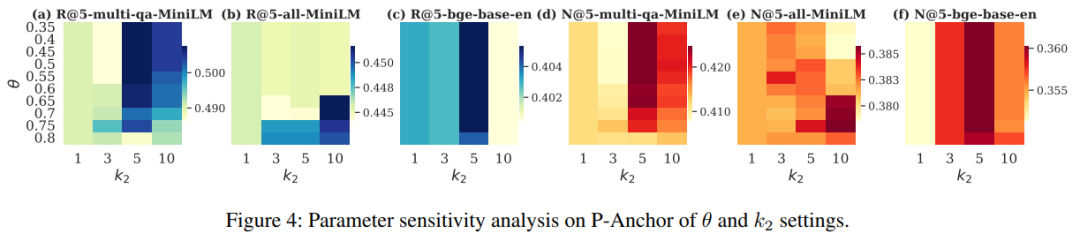
可视化验证:PBR让查询精准匹配用户专属语义
通过t-SNE可视化用户查询、真实标签和不同方法生成查询的分布,能直观看到PBR的优势:
- 传统方法(如HyDE)生成的查询高度聚集,无法区分不同用户的语义空间;
- PBR生成的查询能精准落在对应用户的真实标签附近,实现了用户语义空间的有效分离,余弦相似度也远高于原始查询和HyDE,证明其真正融入了用户的个性化语义。
此外,PBR的生成性能也得到了验证:在LongMemEval-s上,其精确匹配(EM)分数达42.6%,高于所有基线,说明个性化检索的提升最终也能带动下游生成质量的改善。
04、总结
PBR并非通用RAG的替代方案,而是个性化RAG场景的精准优化方案,其核心适用场景需满足三个特征:
- 存在用户专属语料/历史交互数据(如智能助手的对话记录、私人文档、个性化使用轨迹),为个性化建模提供数据基础;
- 用户查询依赖个性化特征才能准确理解(如“我的喜好”“我的习惯”类模糊查询),通用扩展易产生歧义;
- 核心需求是提升检索的用户适配性,而非通用相关性,最终目标是让RAG的响应更贴合用户的个性化需求。
从落地实践来看,资源消耗优化仍是 PBR 需要重点突破的方向。目前其额外开销主要集中在两部分:一是 P-PRF 模块生成伪表述与伪推理的 LLM 调用成本,二是 P-Anchor 模块构建语义图与执行 PageRank 计算的算力开销。
但即便如此,PBR 的设计思路仍高度契合当前 AI 应用的发展趋势 —— 以用户为中心,深度挖掘个性化价值。
结合当下大火的智能体记忆系统,PBR 的落地价值尤为突出:智能体需持续捕捉并调用用户的长期记忆,而 PBR 通过风格模拟与结构锚定,能让检索过程始终贴合用户的表达习惯与长期记忆特征,完美解决了个性化智能体交互中 “检索结果与用户记忆不一致” 的核心痛点,成为支撑个性化智能体落地的关键技术之一。
在 AI 应用愈发强调 “用户中心” 的当下,PBR 将个性化前置到检索环节的创新思路,与 Memory 系统、用户画像等场景的核心需求高度契合。毕竟用户的个性化需求往往隐藏在表达风格与历史交互的细节中,越早精准捕捉、越深度适配,后续的检索准确性与生成贴合度自然越突出,这也是 PBR 框架最核心的价值所在。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献232条内容
已为社区贡献232条内容

所有评论(0)