AIAgent应用开发——人工智能通识基础(三)
监督学习通过标注数据训练模型,实现图像识别、医疗诊断等应用,但面临数据标注成本高和过拟合问题。无监督学习则自主发现数据内在规律,用于客户分群和异常检测。强化学习通过奖励机制引导学习,适用于动态决策场景。大数据与云计算的结合推动了机器学习发展,深度学习则借助反向传播算法实现多层神经网络训练。这些方法各有特点,在不同领域发挥重要作用。
·
一、监督学习基本概念与工作机制
1、监督学习基本概念
监督学习是一种将“间题”和“答案”一起提供给机器,让它学会如何解决问题的方法。
以图像识别为例,一张人脸或猫的照片就相当于“问题”,“答案”则是这张图像所对应的人名或动物名称。
监督学习通过大量标注数据训练模型,使其能够从输入中推理出正确输出的能力。
2、监督学习的流程
- 收集带有标签的数据:准备大量的训练数据,每条数据祁附带正确的标签。
- 提取输入特征:从数据中提取有意义的信息作为模型的输入。
- 训练模型:利用算法让模型学习数据中的规律。
- 评估效果:测试模型在未见过的数据上的表现。
- 应用到实际预测中:将训练好的模型用于解决实际问题。
3、评估模型的表现
- 准确率:预测正确的比例。
- 召回率:真正的目标有多少被识别出来。
- F1分数:准确率和召回率的综合评价,更全面反映模型表现。
4、监督学习的优势与挑战
- 优势:即使研究人员不手动干预,模型也能自动优化学习策略,提升判断能力。
- 挑战:高质量的标注数据是基础,获取这些数据既耗时又费力。
- 挑战:模型过拟合问题,即在训练数据上表现很好,但在新数据上表现不佳。
5、提升模型的泛化能力
- 数据增强:通过对已有数据做“微调”来模拟更多样的情况。
- 正则化:给模型加一点“约束”,防止它一味地记住训练数据。
- 不同问题适合不同的模型:决策树、支持向量机(SVM)、神经网络等。
6、监督学习的应用领域
- 图像识别、语音识别、垃圾邮件分类、医疗诊断、情感分析等。
- 在医疗诊断中,监督学习模型可以通过分析医学影像数据,辅助医生诊断疾病。
- 在金融领域,监督学习可用于信用评估和欺诈检测,提高风险管理效率。
二、无监督学习与监督学习的区别
1、无监督学习的基本概念
- 无监督学习是在没有提供“标准答案”的情况下,机器通过分析大量数据之间的关系、相似性和隐藏结构,自主发现数据中潜在的规律和模式。
- 无监督学习的目标是发现数据的内在结构,而不是预测特定的输出。
- 无监督学习常用于数据探索和特征提取,为后续分析提供基础。
2、无监督学习与监督学习的区别
- 无监督学习没有“标准答案”可以参考,无法直接判断“对还是错”。
- 监督学习依赖标注数据,而无监督学习完全依赖数据本身的特点。
- 无监督学习的输出通常是数据的分组或特征表示,而不是具体的预测结果。
3、无监督学习的学习方法
- 聚类:找出数据中“相似的一群”。
- 降维:把数据中冗余的信息压缩掉,只保留最核心的内容。
- 关联规则挖掘:发现数据中频繁出现的模式和规则。
4、无监督学习的应用场景
- 客户分群、推荐系统、异常检测、文本主题分析等。
- 在推荐系统中,无监督学习可以通过用户行为数据进行聚类,为不同用户群体提供个性化推荐。
- 在网络安全领域,无监督学习可用于异常检测,发现网络流量中的异常行为。
5、无监督学习与监督学习的结合
- 半监督学习:大多数数据没有标签、小部分数据有标签的情况下进行训练。
- 自监督学习:一种“自我制造标签”的方式,让模型自我训川练。
- 无监督学习可以为监督学习提供特征提取和数据预处理,提升监督学习的效果。
三、强化学习基本概念与特点
1、强化学习的基本概念
- 强化学习通过设置奖励机制来引导学习过程,智能体通过尝试和反馈逐步学会哪些行为有效,哪些应该避免。
- 强化学习的目标是让智能体在环境中最大化累积奖励。
- 强化学习适用于需要动态决策的场景,如机器人控制和游戏AI。
2、强化学习的核心要素
智能体、环境、状态、动作、奖励。智能体:执行动作的学习主体;环境:智能体所处的的外部世界、提供反馈;状态:描述当前环境的特征;动作:智能体在特定状态下可采取的行动;奖励:衡量行为优劣的标准。
智能体根据当前状态选择动作,环境根据动作给出新的状态和奖励。
通过不断试错,智能体学习最优策略,以最大化累积奖励。
3、强化学习的特点
- 强化学习不依赖教师示范,而是依靠奖励信号来自我评估和学习。
- 适用于没有明确正确答案的问题,如路径规划和资源分配。
- 强化学习强调动态交互,智能体需要在不断变化的环境中学习。
4、强化学习的应用实例
- 谷歌数据中心冷却系统优化、游戏AI(如AlphaGo)等。
- 在游戏AI中,强化学习让AI通过不断试错,学会最优的游戏策略。
- 在自动驾驶中,强化学习可用于路径规划和决策制定,提高驾驶安全性。
5、强化学习的问题
- 延迟奖励问题:智能体需要等待较长时间才能获得奖励,导致学习效率降低。
- 环境不稳定问题:环境动态变化会影响智能体的学习过程。
- 探索与利用的平衡:智能体需要在探索新策略和利用已知策略之间找到平衡。
四、大数据的运用和机器学习的发展
1、大数据的出现和扩张
- 第二次人工智能浪潮的兴起与专家系统的局限性。
- 互联网与大数据时代的到来,数据量呈爆炸式增长。
- 大数据的特征是数据量大、类型多样、处理速度快。
2、大数据与云计算的协同作用
- 研究人员利用云计算在多个服务器上同时处理海量信息,提升模型训练效率。
- 云计算提供了强大的计算资源,支持大数据的存储和处理。
- 大数据与云计算的结合推动了机器学习模型的快速发展。
3、大数据的实际应用
- 商业和社会中的广泛用途,如淘宝的用户购买倾向预测、微博的流行趋势捕捉等。
- 在金融领域,大数据可用于风险评估和市场预测。
- 在医疗领域,大数据可用于疾病预测和个性化治疗方案制定。
五、深度学习的诞生与发展过程
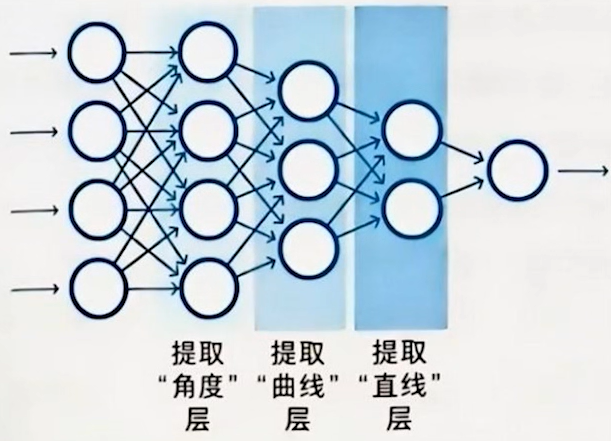
反向传播算法、神经认知机、自编码器==》深度学习
- 反向传播算法的发现克服了单层感知机的局限。
- 反向传播算法通过计算误差梯度,优化神经网络的权重。
- 反向传播算法的出现使得多层神经网络的训练成为可能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 25
25 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)