当 wrk 遇上 Agent:一次 AI 驱动的性能测试与可视化报表的产出(Antigravity)
antigravity环境下的Agent配合wrk性能测试工具实现自动化测试并生成可视化报表
目录
性能测试往往意味着繁琐的脚本编写和数据整理。这次,我尝试了一种新的方式:让 AI 编程助手驱动命令行工具 wrk,看看这能带来怎样的效率提升。
背景:重复造轮子?
最近我在优化后端 API,引入了 Redis 缓存。为了验证优化效果,我需要做一组对比测试。
按照传统流程,我需要(真实需求):
1. 编写 4 个不同的 Lua 脚本(覆盖有无 Redis、不同接口参数)。
2. 手动运行 16 次 wrk 命令(4 个接口 × 4 个并发阶段)。
3. 把终端输出的数字复制到 Excel 做图表。
这并不难,但很繁琐。于是我产生了一个想法:既然 AI 能写代码,能不能让它直接帮我把“测试 + 分析 + 报告”的全流程自动化了?
为什么是这种组合?
wrk:依然是 HTTP 压测的神器,单机性能极强,但原生输出比较简陋,且需要 Lua 脚本支持复杂请求。
AI Agent(Antigravity):擅长理解意图、生成/执行脚本和处理文本数据。
我的目标是:用 AI 的逻辑能力去补全 wrk 的自动化和可视化短板。
向 Agent 下达指令(指令由大模型根据需求描述生成):
过程:从意图到执行
我没有直接让 AI “写个脚本”,而是描述了我的完整测试策略:
“使用 wrk,对 4 个接口进行 4 阶段的渐进式加压(10/20/60/100并发)。如果出现高延迟或高错误率,立即熔断停止。”
AI 随后不仅生成了对应的 A1.lua ~ B2.lua 脚本,还编写了一个 Python 脚本来编排整个流程。这个 Python 脚本不仅负责调用 wrk,还承担了“测试员”的角色——实时监控输出,判断是否继续。
# 自动生成的 Python 逻辑片段(为了对服务器产生实际伤害)
if error_rate > 0.03 or avg_latency > 2000:
print(f"触发熔断机制:{test_id} 在高负载下表现异常,停止后续测试")
break亮点:自动熔断机制
在实际运行中,这个“自动熔断”真的发挥了作用。
当测试进行到 B1 接口(话题列表)的 60 并发阶段时,P95 延迟突然飙升。
Python 脚本捕捉到了这一变化,判定系统已达瓶颈,自动取消了后续 100 并发的最强压力测试。
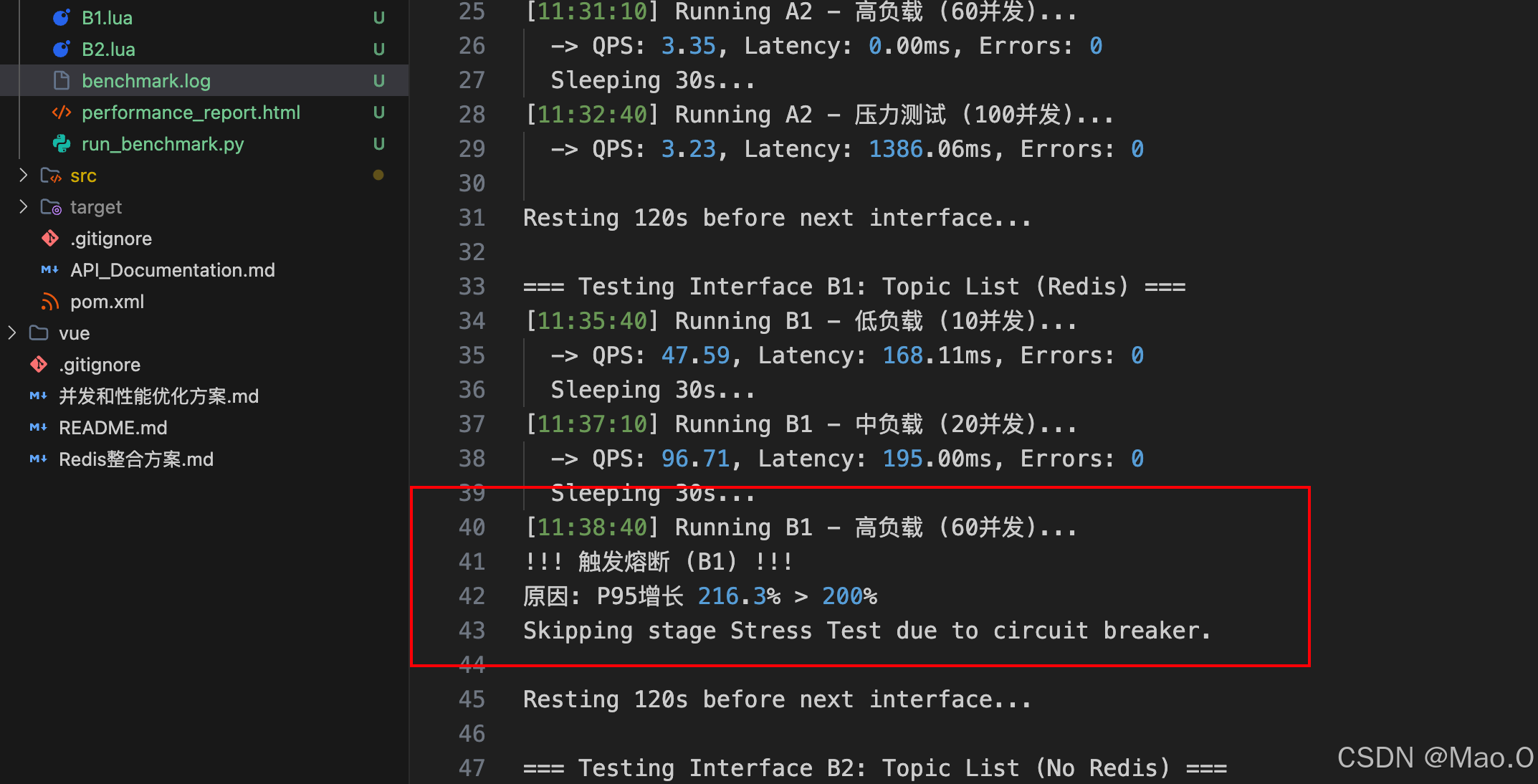
这一机制避免了无意义的等待,也保护了测试环境不被过载请求冲垮。
结果:直观的可视化
测试完成后,我并没有得到一堆 CSV 文件,而是一个直接生成的 HTML 报告。
AI 在 Python 脚本中内嵌了 HTML 生成逻辑,利用 Chart.js 将测试数据直接渲染成了图表。
并且 AI 发现测试完毕后会对测试结果进行分析,将分析结果追加到 HTML 报告中。
打开浏览器,清晰的柱状图和折线图一目了然。
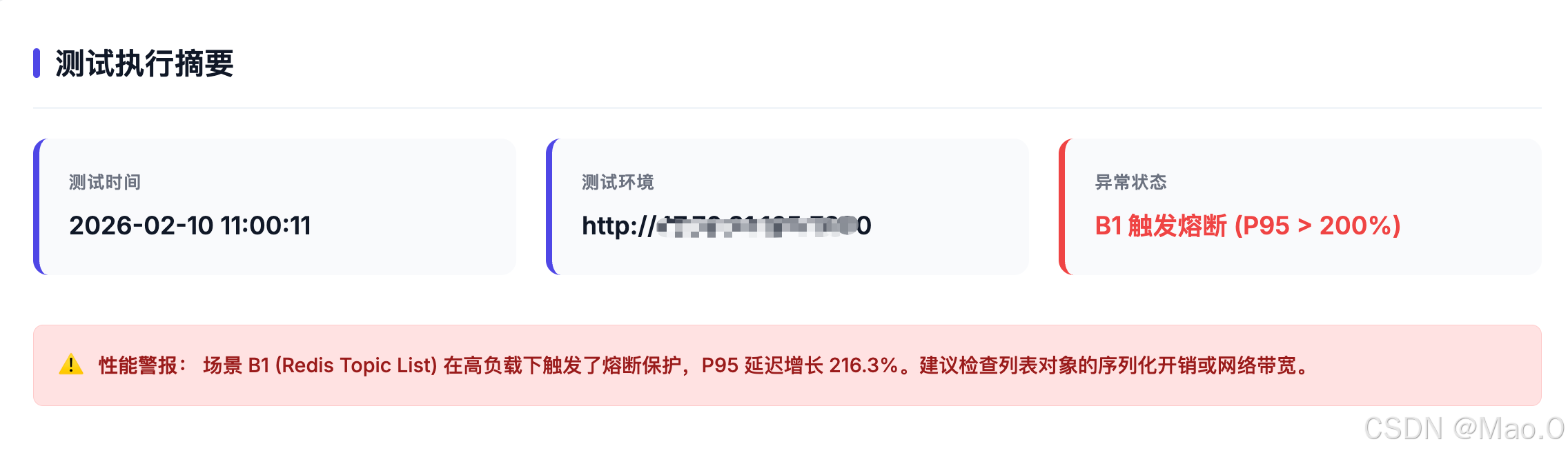
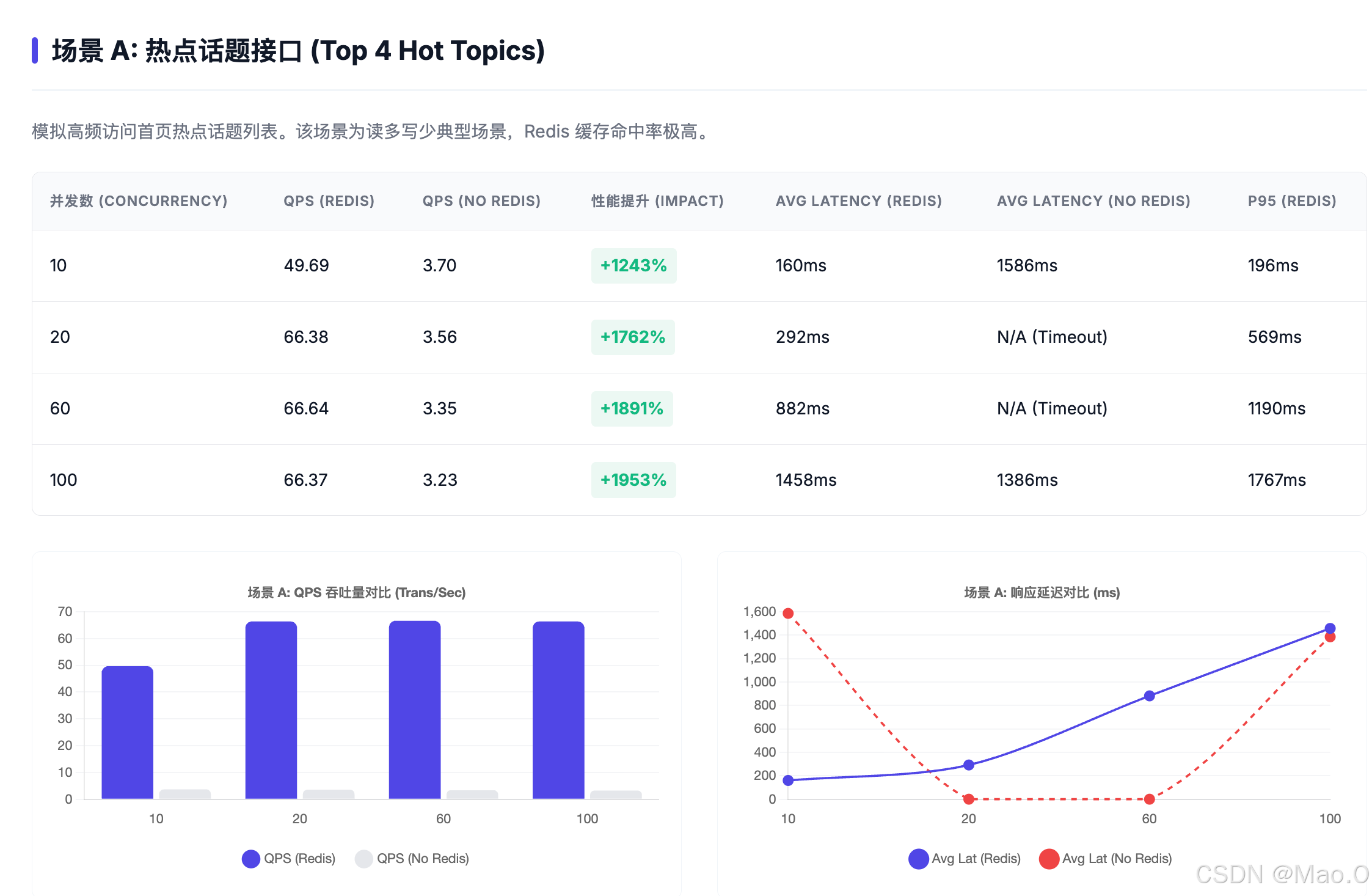
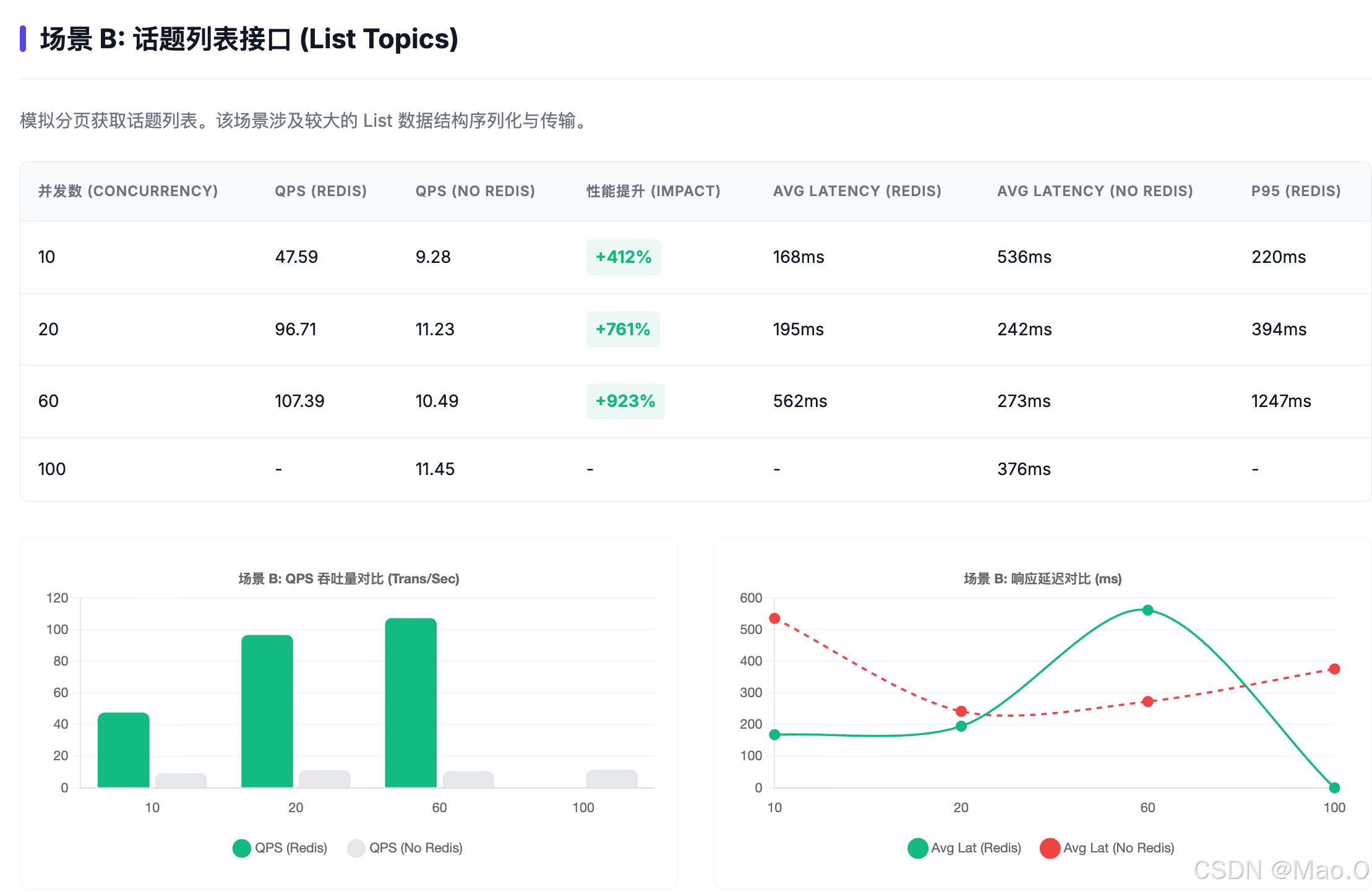
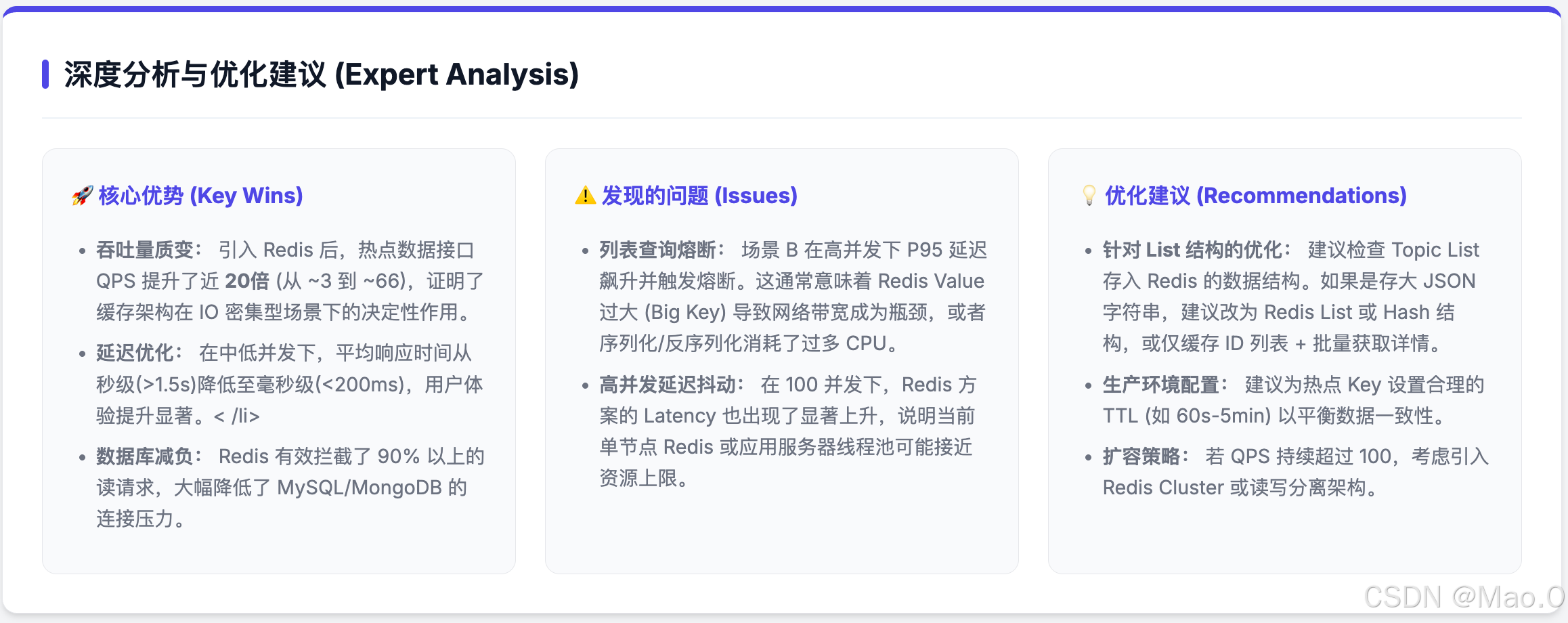
数据复盘:Redis 的实际提升
这次测试的数据也印证了缓存的重要性:
热点话题接口:QPS 从个位数提升到了 60+,不仅吞吐量大幅上涨,更重要的是解决了“响应超时”的问题。
稳定性:在未开启 Redis 时,仅 10 个并发就能让数据库查询出现大量超时;开启后,系统在 100 并发下依然能保持响应。
结语:编程习惯的微妙变化
最后,这次体验让我感到新奇的,并不是 Redis 带来了多少提升(这是预料之中的),而是我与工具的交互方式变了。
我不再是一个单纯的“命令执行者”,更像是一个能够指挥 AI 编排工具链的“架构师”。
AI 并没有替代 wrk 这样优秀的底层工具,而是成为了连接“我的意图”和“底层工具”之间的桥梁。这种协作方式,或许会让未来的开发和测试变得更加有趣且高效。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)