小白程序员必备:用AI数据治理Agent告别“数据沼泽”,让你的数据真正成为资产!
文章主要介绍了传统数据治理方式的局限性,并提出AI数据治理Agent架构作为解决方案。该架构通过大模型和多智能体协同,实现了数据的自动感知、决策、执行和优化,有效解决了数据质量、合规性等问题。文章详细拆解了“1+5+3+2”架构,并通过金融、政务、工业制造等案例展示了其实际应用效果。最后,文章强调了AI时代数据治理的重要性,以及未来数据团队需要从“清洁工”转变为“Agent指挥官”,掌握设计和管理
文章主要介绍了传统数据治理方式的局限性,并提出AI数据治理Agent架构作为解决方案。该架构通过大模型和多智能体协同,实现了数据的自动感知、决策、执行和优化,有效解决了数据质量、合规性等问题。文章详细拆解了“1+5+3+2”架构,并通过金融、政务、工业制造等案例展示了其实际应用效果。最后,文章强调了AI时代数据治理的重要性,以及未来数据团队需要从“清洁工”转变为“Agent指挥官”,掌握设计和管理AI治理工具的核心能力。
01 你的数据湖,是不是又变成了“数据沼泽”?
咱们开门见山,聊点扎心的。
作为一名在数据圈摸爬滚打十年的老兵,我见过太多企业喊着“数据资产化”的口号,最后干的却是“数据垃圾回收”的活儿。
场景是不是很熟悉?老板周一要看全渠道销售报表,你周五还在和财务吵架——因为你的销售额是 1 亿,财务那边只有 8000 万。为什么?因为你的系统里,同一个客户“张三”,在电商平台叫“ZhangSan”,在CRM里叫“三哥”,在物流单上写的是“张先生”。

这就是典型的 OneID(唯一标识)识别失败。
这时候,你只能祭出传统的“人海战术”:拉上几个刚毕业的实习生,盯着 Excel 表格一行行人工比对,或者让这帮“SQL Boy”写几百行正则表达式去清洗数据。
朋友们,这不叫数据治理,这叫“电子劳改”。
传统的数据治理,就像是用牙刷去刷一个足球场。规则永远跟不上数据的变化,质量校验全靠人工抽检,合规审计全靠事后补救。面对现在动辄 PB 级、非结构化数据满天飞的局面,传统的“人工主导+工具辅助”模式,已经彻底崩盘了。
痛点很明确:数据量在爆炸,治理能力在爬行。
怎么办?最近我也在研究行业里的新风向,发现了一个能彻底改变游戏规则的东西——AI 数据治理 Agent(智能体)架构。
今天,咱们不整虚的,直接把这套《AI数据治理Agent架构白皮书》里的硬核干货拆开了、揉碎了讲给你们听。
02 为什么你需要一个“有脑子”的治理工?
以前我们用的 ETL 工具、数据质量工具,充其量是“义肢”——你动一下,它动一下。它没有脑子,只会死板地执行你写好的规则。一旦数据格式变了(比如身份证号字段突然混进了护照号),程序立马报错,或者干脆给你产出一堆垃圾数据。
而 AI Agent(智能体) 的出现,相当于雇了一个“24小时不睡觉、懂业务、能自学”的超级员工。
它不再是被动执行指令,而是具备了 “感知-决策-执行-优化” 的完整闭环能力。
传统工具是“手套”,Agent 是“大脑+手脚”。
它能自己“看”到数据脏了(感知),自己“想”该怎么洗(决策),自己“动手”洗干净(执行),还能顺便把由于操作不当产生的合规风险给挡回去(风控)。
这背后,是一套严密的“1+5+3+2”架构。别被数字吓到,听我给你翻译翻译。
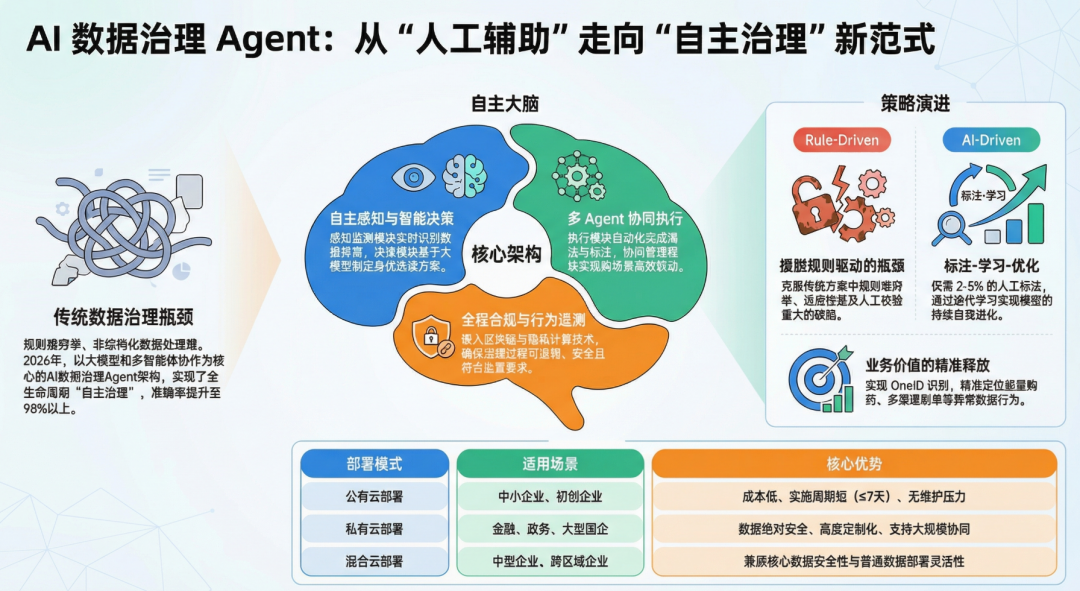
03 拆解“1+5+3+2”:给数据治理装上“核动力”
这套架构,就是把一个资深数据专家的脑子,通过代码和模型复刻了下来。
1个底座:这是内功心法
一切的基础,在于技术底座。这里面最核心的不是别的,是 大模型(LLM)+ 多智能体协同(Multi-Agent)。
以前处理非结构化数据(比如合同扫描件、客服录音),那是天方夜谭。现在有了多模态大模型,Agent 能读懂 PDF 里的条款,能听懂录音里的投诉情绪。
而且,我们不再是指望一个超级 AI 干所有事,而是用 多智能体协同。就像装修队,有管水电的、管木工的、管油漆的。Agent 也是如此,有的负责清洗,有的负责合规,有的负责调度,大家各司其职。
5大核心模块:五脏俱全
这是架构的躯干,每一个模块都对应着你现在的一个痛点:
-
**感知监测模块(眼睛):**它不只是盯着硬盘容量,而是像雷达一样扫描数据质量。数据一旦出现异常波动(比如某渠道流量突然归零),或者检测到敏感数据在裸奔,它立马报警。它解决了“发现慢”的问题。
-
**决策规划模块(大脑):**这是最牛的地方。它不是靠死板的
if-else规则,而是基于大模型进行推断。比如面对一堆乱码的地址数据,它会自己规划:“先做分词,再匹配标准地址库,最后做补全”。它解决了“策略死”的问题。 -
**执行操作模块(双手):**有了策略,得有人干活。清洗、脱敏、标注、归档,这些脏活累活它全包了。而且它能对接隐私计算,让数据“可用不可见”,安全地跑起来。
-
**协同管理模块(神经中枢):**当任务太复杂,一个 Agent 搞不定怎么办?这个模块负责摇人。它管理多个 Agent 的注册和通信,确保大家劲儿往一处使,别打架。
-
**合规风控模块(盾牌):**重点来了! 现在的《数据安全法》可是带牙齿的。这个模块把合规要求写进了代码里。每一次数据访问、每一次清洗操作,都会被区块链记录下来,全程可追溯。审计来了?直接甩出链上记录,这就是底气。
3大运行机制:自我进化
你可能会问:“智数哥,要是 AI 犯傻了怎么办?”
所以架构里设计了 自主迭代机制。它会根据清洗后的结果反馈,自己调整算法参数。就像一个新员工,刚开始可能手生,但干了一个月后,比老员工还熟练。还有****容错恢复机制,哪怕某个节点挂了,也能自动切换,保证治理任务不中断。
2大适配接口:拒绝“烟囱式”建设
很多企业最怕上一套新系统就要把旧的推倒重来。这套架构贴心地准备了 系统适配接口 和 场景适配接口。不管你底层是 Hadoop 还是 Oracle,是公有云还是私有云,它都能像“USB插头”一样插上去用。
04 别光听理论,看看疗效
这时候肯定有杠精要说了:“老哥,PPT 谁都会画,落地咋样?”
来看看白皮书里的真实案例,你就知道这玩意儿有多猛了。
案例一:金融风控——唯快不破某国有银行,以前信贷数据清洗要 T+1,等发现风险,骗子早跑了。上了这套 Agent 架构后,构建了“金融数据自主治理集群”。交易数据一进来,Agent 毫秒级识别异常,自动触发风控预警。信贷审批效率提升了50%,不良贷款率下降了18%。这就叫真金白银的价值。
案例二:政务数据——打通任督二脉政务数据最头疼的是“孤岛”。社保局的数据,医保局拿不到。如某省用了这套架构,搞了个“共享交换 Agent”。各部门数据在隐私计算的保护下,实现了自主共享,不需要人工层层审批。群众办事跑腿次数大幅减少,非结构化档案处理周期从15天缩短到了2天。
案例三:工业制造——老师傅的经验数字化工厂里的设备故障预警,以前全靠老师傅听声音。现在,Agent 采集设备传感器数据和故障图像,利用多模态大模型分析。设备故障预警准确率干到了 96%,直接把设备维护成本砍掉了 30%。
05 AI 时代的数据生存法则
聊到最后,智数哥想给大家泼点冷水,也是打点鸡血。
AI 数据治理 Agent 的出现,意味着“数据治理”这个行业正在经历一次彻底的物种进化。
如果你还是抱着“写规则、跑脚本、做报表”的老一套不放,那么不用等到 35 岁危机,AI 明天就能把你淘汰。因为在处理海量、复杂、即时的数据面前,碳基生物(人)永远跑不过硅基生物(Agent)。
但是,这不代表我们就要失业。
**Agent 是强大的工具,但它依然需要“架构师”。**它需要懂业务的人去定义场景,需要懂合规的人去设定边界,需要有大局观的人去设计协同机制。
未来的数据团队,将不再是“清洁工大队”,而是“Agent 指挥官”。你的核心竞争力,将从“怎么写 SQL 清洗数据”,升级为“怎么设计一个 Agent 帮我清洗数据”。
【智数哥建议】:
-
拥抱黑盒: 别纠结 Agent 具体怎么算出来的,关注它的决策逻辑和可解释性接口。
-
补齐短板: 恶补一下隐私计算和区块链知识,这是未来数据合规的“保命符。
-
场景先行: 别上来就搞全域治理,先找一个痛点(比如主数据对齐),用 Agent 跑通闭环。
未来的企业,拼的不是谁的数据多,而是谁的数据治理 Agent 跑得快、跑得稳。
不要让你的数据躺在服务器里睡觉,派个 Agent 去叫醒它们。
数据不是资产,被治理好的数据才是。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献679条内容
已为社区贡献679条内容

所有评论(0)