Vibe Coding - 给 Claude Code 装一块“长期记忆”:深入解析 Claude-Mem 持久化上下文系统
Claude-Mem:AI编程助手的长期记忆解决方案 当前AI编程助手普遍存在"健忘症"问题,每次会话都需要重复介绍项目背景。Claude-Mem作为Claude Code的插件,通过自动记录、压缩存储和智能检索,为AI助手构建长期记忆系统。它能自动捕获工具调用、代码操作等"观察"数据,存入本地数据库和向量库,并支持跨会话的智能检索。核心功能包括持久化内存、
文章目录
一、先把问题说清楚:为什么需要 Claude-Mem?
现在常见的 AI 编程助手,有一个共同的“硬伤”:记性太差。
会话一关,之前改过的文件、踩过的坑、讨论过的方案,全都没了。下一次你只能重新复读机式讲一遍项目背景。
典型几个痛点:
- 长期项目,要反复介绍“这是个啥项目、技术栈是啥、现在做到哪一步了”
- 想问“上次我们是怎么实现登录的来着?”模型根本没有记忆,只能重新读代码
- 复杂改动(重构、大范围重命名)跨很多次会话,没有一条完整“时间线”,回溯超级费劲
Claude-Mem 想解决的,就是这个问题:让 Claude Code 对你的项目“有记性”,而且记得还挺聪明。
一句话总结它的定位:
给 Claude Code 加上一层“自动记录 + 压缩总结 + 智能检索”的长期记忆系统,让项目上下文可以跨会话持续被利用。
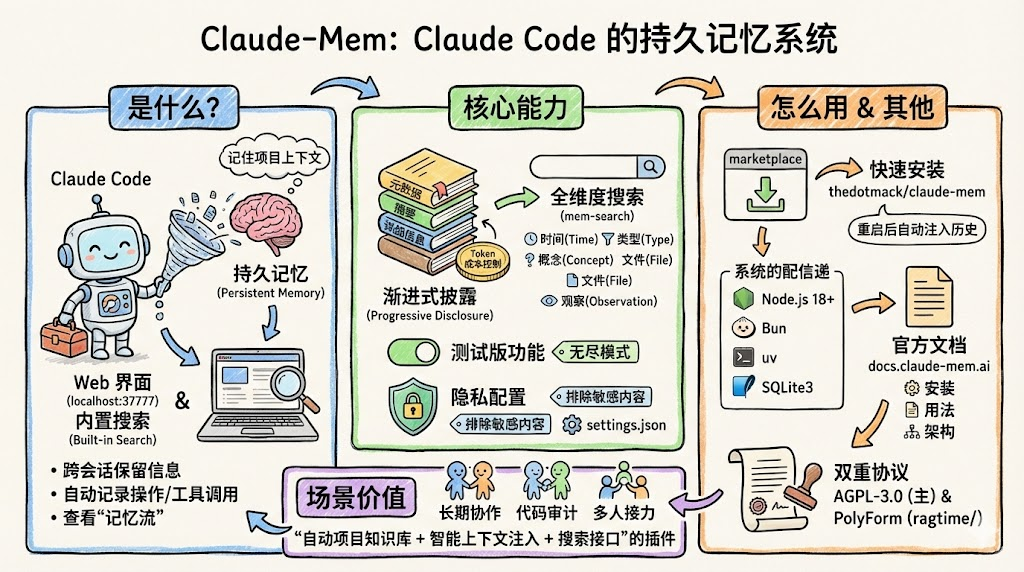
二、Claude-Mem 是什么?一句话 + 功能全景
2.1 一句话介绍
Claude-Mem 是一个为 Claude Code 打造的插件,专门负责:
- 捕获你的工具调用、对话、代码操作等“观察”
- 按会话和语义做压缩、打标签、写摘要
- 存到本地数据库 + 向量库里
- 在之后的会话按需检索、按层级注入回上下文
你不需要手动记笔记、建知识库,它在后台自动记录、管理和调用这些记忆。
2.2 功能速览:它都帮你干啥
官方列的核心特性,可以拆成九块:
- 持久化内存:上下文可以跨会话保留,不再“聊完就丢”
- 渐进式披露:不是一股脑塞入历史,而是按层级、按 token 成本,有策略地注入
- mem-search 搜索能力:用自然语言问“我们上次修啥 bug”“某文件改动历史”
- Web 查看器:本地打开
http://localhost:37777,实时看到“记忆流”和搜索结果 - Claude Desktop 技能:在 Claude Desktop 里也可以直接搜这些记忆
- 隐私控制:通过标签把敏感内容排除在存储之外
- 上下文配置:可以精细调节“注入多少、什么类型、在什么场景注入”
- 自动操作:无须手动按按钮,一切在后台运行
- 引用机制:每条观察有 ID,可以通过 API 或 Web UI 精准引用
对于日常开发,这些能力组合起来,大概就是:
把“项目历史”变成一个随时可问、可搜索、能自动辅助写代码的私有知识库。
三、从安装到上手:两分钟跑起来
3.1 快速开始:两条命令搞定
在 Claude Code 的终端里,新开一个会话,执行两条命令:
> /plugin marketplace add thedotmack/claude-mem
> /plugin install claude-mem
然后重启 Claude Code。
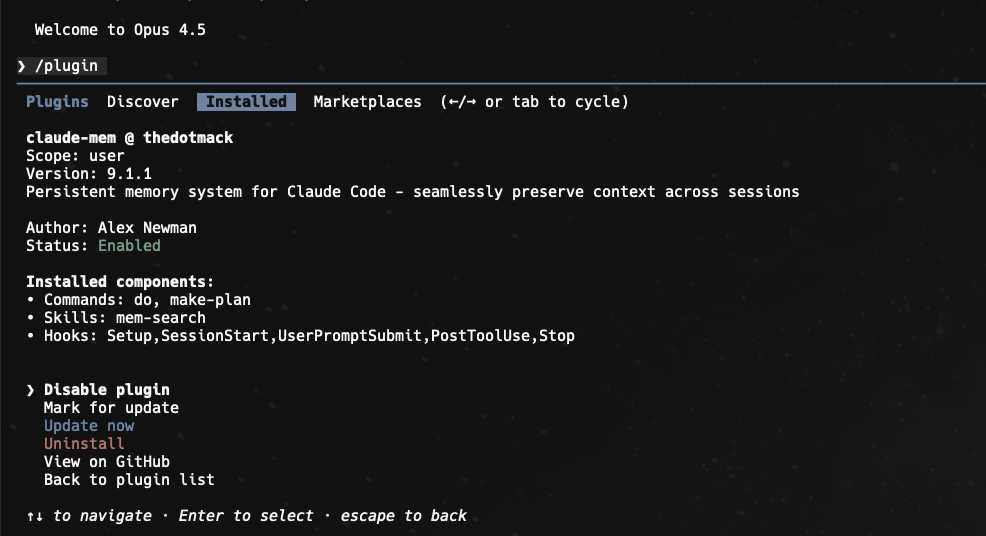
此后:你之前会话里产生的上下文,会自动开始出现在新会话中,不需要你额外调整什么。
3.2 日常使用体验长什么样?
真实体验大概是这样几种场景:
- 再次打开项目:Claude 能直接提到“我们上次重构了 X,还留下了 Y TODO”,不用你先复盘一遍
- 问历史:
- “我们之前怎么实现认证的?”
- “上一个会话修了哪些 bug?”
Claude 会自动调用mem-search从历史中捞出相关记忆。
- 大改动回溯:想看某个文件的演进,可以通过“按文件搜索”看到相关观察列表与时间线。
四、核心能力拆解:持久化、检索、控制
这一部分集中讲“这货到底能做什么”,偏使用层面。
4.1 持久化内存:记住什么?怎么记?
Claude-Mem 会记录的东西,统一叫“观察(observation)”,包括但不限于:
- 工具调用
- 重要的对话片段
- 关键决策、重构说明、 bug 修复描述
- 和具体文件相关的操作与生成内容
它会把这些观察以及每次会话的摘要,写入本地 SQLite 数据库中。
这意味着:
- 会话结束不会“清空”
- 你换个会话继续聊同一个项目,Claude 有机会把这些历史读出来用
- 不需要你显式说“帮我记一下这段”
4.2 渐进式披露:解决“上下文太大塞不完”的老问题
传统做法是:要用历史,就把尽量多的历史丢给模型。
问题是:
- token 浪费严重
- 模型会迷失在无关内容里
- 重要信息容易被淹没
Claude-Mem 的思路是:“一层一层地打开记忆,而不是一次性全给”。
它会考虑:
- 哪些记忆最相关
- 这些记忆有多长(token 成本)
- 当前任务到底需要多少历史才够用
然后渐进式注入:
先给高层摘要,不够再展开局部细节,类似“先目录后内容”的风格。
4.3 mem-search:把项目历史当搜索引擎用
mem-search 是这套系统的入口技能,负责各种检索需求。
你只需要自然地问,例如:
- “上次我们改了哪些表结构?”
- “worker-service.ts 做过哪些改动?”
- “最近和支付相关的工作有哪些?”
底层会路由到不同的搜索动作(你不用记名字,但理解下有助于设计提问方式):
- 搜索观察:对“观察”全文检索
- 搜索会话:对“会话摘要”全文检索
- 搜索提示:找原始用户请求
- 按概念搜索:比如“发现”“问题-解决方案”“模式”等
- 按文件搜索:限定某个文件相关的记录
- 按类型搜索:bug 修复、重构、功能、决策等
- 最近上下文:取最近几次会话的整体背景
- 时间线:围绕某个时间点拉一段上下文
- 按查询的时间线:类似“把相关片段 + 上下文一并拿出来”
- API 帮助:用于开发者查接口说明
这套能力的意义在于:
你不再是在“搜代码”,而是在“搜我们之前对这个项目做过的事情”。
五、架构视角:Claude-Mem 背后这套系统怎么运转?
这一节给研发同学看,方便你评估:
- 是否适合集成到自己的工具链
- 是否能作为“Agent 记忆模块”的参考实现
5.1 整体结构:几块主骨架
在官方文档里,Claude-Mem 的核心组件被拆成 6 块:
-
生命周期钩子(Hooks)
- SessionStart
- UserPromptSubmit
- PostToolUse
- Stop
- SessionEnd
再加上若干脚本,总共 6 个钩子脚本。
这些钩子负责:在关键节点捕获信息、生成摘要、触发存储或检索。
-
智能安装脚本
- 充当“依赖检查器”,在真正运行前把运行环境准备好
- 虽然也是脚本,但不算生命周期钩子本身
-
Worker 服务
-
在 37777 端口暴露 HTTP API
-
提供 Web 查看器(你在浏览器里看到的 UI 就是它)

-
暴露 10 个搜索端点
-
由 Bun 来管理运行进程
-
-
SQLite 数据库
- 用来存储会话、观察、摘要
- 用 FTS5 做全文检索
-
mem-search 技能
- 对外是“一个技能”,内部会组合不同搜索方式
- 支持渐进式披露,把检索结果转成“可注入上下文”
-
Chroma 向量数据库
- 提供语义搜索能力
- 和关键词检索结合,做混合搜索(更稳更准)
从系统设计角度看,它是一个:
“钩子驱动的数据采集 + 本地数据库 + 向量库 + HTTP API + Web UI”的小型记忆服务。
5.2 Web 查看器与 API:不是只给 Claude 用的
除了在 Claude 里被自动使用外,人类也可以直接使用它的接口:
-
浏览器打开
http://localhost:37777:- 实时看到“记忆流”
- 可以手动搜索、过滤
- 切换稳定 / 测试版渠道(比如开启“无尽模式”)
-
通过 API:
- 访问单条观察:
/api/observation/{id} - 结合内部 ID 做“引用追踪”
- 有 10 个搜索端点可以调用
- 访问单条观察:
如果你想把 Claude-Mem 当成“项目知识 API”来用,这块非常关键。
5.3 数据流:从“一次对话”到“可检索记忆”
大致流程可以抽象为:
- 钩子捕获:某个事件发生(用户输入、工具调用结束等)
- 生成观察:把关键信息整理成结构化记录
- 写入存储:
- SQLite:结构化数据 + 摘要 + FTS5 索引
- Chroma:把文本嵌入成向量,补充语义检索能力
- 后续会话里,当你提问或任务需要上下文:
- mem-search 调用数据库 + 向量库
- 根据相关度和 token 预算做渐进式披露
- 把合适片段串成上下文,注入当前对话
这基本就是一套可复用的“Agent 记忆子系统”通用蓝本。
六、配置、隐私与“可控的记忆”
再强的记忆,如果不可控,就会变成“隐私炸弹”。Claude-Mem 在这块做了几件事。
6.1 配置文件:settings.json 能改什么?
配置文件位置:~/.claude-mem/settings.json,第一次运行会自动生成。
你可以在里面调整:
- 使用哪个 AI 模型
- worker 服务端口
- 数据目录(想放到加密盘或特定路径可以改这里)
- 日志等级
- 上下文注入策略(比如注入的最大长度、不同类型信息的优先级)
官方文档里提供了更详细的说明和示例,可以按团队规范来固定一版配置。
6.2 隐私控制:哪些东西不想被存?
Claude-Mem 支持通过标签来排除敏感内容的存储。
简单理解就是:
- 给某些内容打上特定标签
- 配置里声明“带这些标签的,不要持久化”
- 既能保证日常开发自动记忆,又不会把敏感数据写入本地库
对企业环境来说,这一步非常关键,可以结合安全规范来设计一套“敏感标签策略”。
七、系统要求与运行环境:落地前要确认的几件事
如果你打算在团队里推广,就要关心“装得上、跑得动”这两个问题。
7.1 系统依赖
官方列出来的依赖如下:
- Node.js:18.0.0 及以上
- Claude Code:支持插件的最新版
- Bun:作为 JS 运行时和进程管理器(如果没有会自动安装)
- uv:作为 Python 包管理器,主要用于向量搜索依赖(没有也会自动安装)
- SQLite 3:内置用于持久化存储
整体看下来,对个人开发者来说门槛不高,对企业环境则需要:
- 确认是否允许本机安装这些运行时
- 有需要的话提前打成镜像 / 自定义开发环境镜像
7.2 稳定版与测试版:正式项目 vs. 折腾新功能
Claude-Mem 提供了一个“测试版渠道”,专门放实验功能,比如“无尽模式”,主打扩展会话记忆能力的高级玩法。
切换方式也很简单:
- 进入 Web 查看器
http://localhost:37777 - 打开设置,选择稳定版或测试版
建议做法:
- 正式项目:用稳定版
- 个人折腾、新功能评估:用测试版,看看对你的场景有没有价值
八、开发者视角:二次开发、排错与贡献
8.1 想自己扩展或集成?从这些文档看起
文档入口集中在一个站点:https://docs.claude-mem.ai/,其中几块对开发者特别重要:
- 安装指南:基础安装 + 高级安装(适合定制环境)
- 使用指南:各种场景下 Claude-Mem 的行为模式
- 搜索工具:mem-search 各种模式的详细说明
- 上下文工程 / 渐进式披露:系统背后的策略理念
- 架构相关:
- 架构概览
- 架构演进(从 v3 到 v5)
- 钩子及其使用方式
- worker 服务的 HTTP API
- 数据库结构(SQLite + FTS5)
- 搜索架构(和 Chroma 的集成)
如果你想把这套记忆系统接入自己的 agent 框架,这些文档基本就是“设计说明书”。
8.2 故障排查:让模型自己当“运维工程师”
遇到问题时,不一定要先去翻日志,可以直接问 Claude。
插件里有一个 troubleshoot 技能,会尝试自动诊断并给出修复建议。
当然,如果要深入排查,官方也有完整的故障排除指南,记录了常见错误和解决办法。
8.3 Bug 报告与贡献流程
项目鼓励社区贡献,流程很标准:
- Fork 仓库
- 建功能分支
- 实现改动并补上测试
- 更新文档
- 提 PR
另外还有一个自动化脚本帮你生成 bug 报告:
cd ~/.claude/plugins/marketplaces/thedotmack
npm run bug-report
它会收集必要信息,生成比较规范的报文,方便维护者排查。
九、版权与协议:能怎么用、能不能商用?
这一块,尤其是准备把它放进公司内部工具或对外服务时,要看仔细。
9.1 主项目:AGPL-3.0
Claude-Mem 主体采用 GNU AGPL-3.0 协议。
简单翻译成几条要点:
- 你可以自由使用、修改、分发
- 如果你做了修改,并以“网络服务”的形式对外提供(哪怕不开源部署包),也要开放你改过的源代码
- 任何衍生作品也要继续用 AGPL-3.0
- 软件本身不提供任何担保
所以:
- 个人用、团队内自用,一般没问题
- 做成 SaaS 服务给外部用,就要严格遵守“开放源代码”的要求
9.2 ragtime 子目录:非商业许可
仓库里有一个 ragtime/ 目录,使用的是 PolyForm Noncommercial License 1.0.0。
这意味着这部分代码只允许非商业使用,做商业产品时要格外注意,不要直接违规使用这一部分。
十、结合实战场景:它适合放在哪些工作流里?
最后,用几个具体场景帮你判断是否值得在团队里推一推。
10.1 长期演进的大型项目
特征:
- 项目生命周期长
- 需求反复改、多人接力
- 有很多“为什么当时这么设计”的历史背景
在这种项目里,Claude-Mem 可以作为:
- 团队“项目记忆库”
- 新人加入时的“学习向导”(问问题就能看到历史)
- 设计决策、架构演进的追溯工具
10.2 频繁重构 / 大改动的代码库
当你需要多轮重构时,常见难题是:
- 这段逻辑之前改过几次?
- 某个 bug 是在哪个阶段修掉的?
- 这个模块的职责边界是怎么变化过来的?
通过按类型、按文件搜索,以及时间线视图,你可以更快还原一条“重构历史线”。
10.3 做 Agent / AI Coding Tool 的研发团队
如果你本身在做类似的系统,Claude-Mem 值得当做:
- 一个完整的“记忆子系统”参考实现
- 研究“渐进式披露”“上下文工程”实际落地的一手实践
- 一个现成可跑的 demo,用来验证你自己模型 / 工具链
十一、写在最后:Claude-Mem 更像是一块“基础设施”
如果只把 Claude-Mem 当成一个“Claude Code 插件”,可能会低估它的价值。
从工程视角看,它其实是一块完整的“记忆基础设施”:
- 有采集(hooks)
- 有清洗与压缩(摘要、概念标签)
- 有存储(SQLite + Chroma)
- 有检索(全文 + 语义 + 时间线)
- 有投喂策略(渐进式披露 + 上下文配置)
- 有操作界面(Web 查看器 + API)
对于习惯用 AI 编程的开发者,它带来的是:
从“每次聊天都像第一次见面”,变成“我们在长期合作同一个项目”。
对于做大模型应用、Agent 系统的团队,它提供了一份很实在的“活样板”:
如何把“记忆”这件事,做得可控、可查、可配置,而不只是“多记一点上下文”。
如果你已经在用 Claude Code,不妨花几分钟装上跑跑,在自己的真实项目里体验一下这块“长期记忆”带来的区别。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)