数仓系列:从数仓、数据湖、湖仓一体、数据中台到 AI 中台的演进之路
定位 :面向分析型业务,结构化数据的集中存储与处理平台。数据高度结构化(Schema-on-write);强调数据一致性、准确性、历史版本管理;通常用于BI报表、OLAP分析;架构经典如Kimball/Inmon模型。Hive (传统数仓)Oracle Exadata(传统/一体机数仓)Teradata(传统/MPP数仓)Snowflake(云原生数仓)ClickHouse(开源OLAP引擎)D
引言
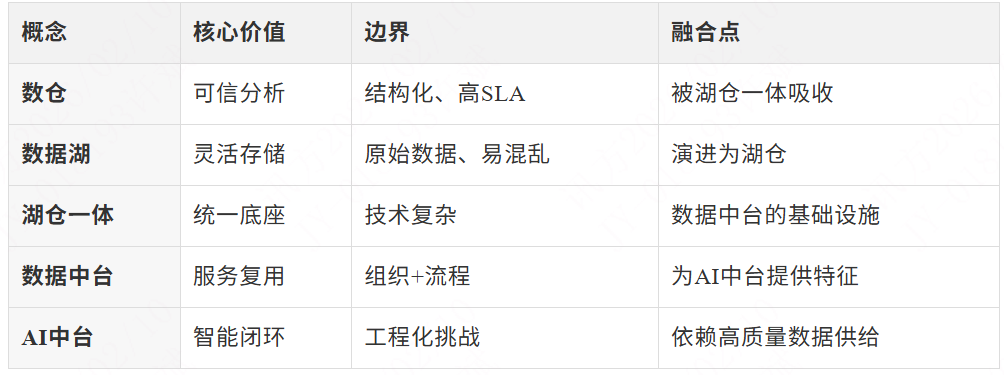
在企业数据智能架构的演进过程中,“数仓(Data Warehouse)”、“数据湖(Data Lake)”、“湖仓一体(Lakehouse)”、“数据中台”和“AI中台”等概念频繁出现,它们既相互关联又各有侧重。理解它们的边界、演进逻辑与协同方式,有助于企业在数字化转型中构建高效、灵活、可扩展的数据智能体系。
核心概念定义与边界
数据仓库(Data Warehouse)
定位 :面向分析型业务,结构化数据的集中存储与处理平台。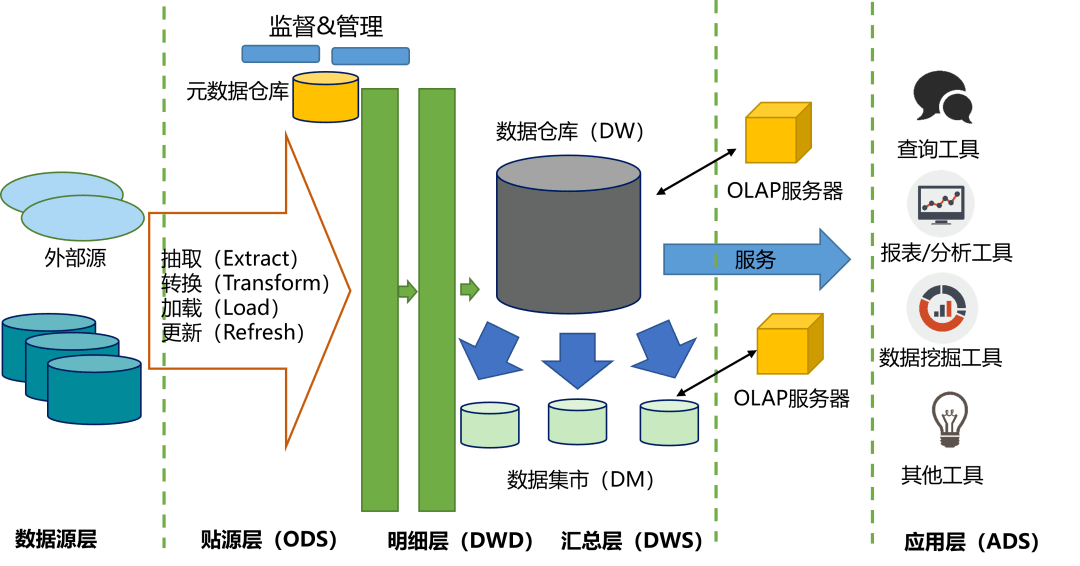
特点:
- 数据高度结构化(Schema-on-write);
- 强调数据一致性、准确性、历史版本管理;
- 通常用于BI报表、OLAP分析;
- 架构经典如Kimball/Inmon模型。
代表技术 :
- Hive (传统数仓)
- Oracle Exadata(传统/一体机数仓)
- Teradata(传统/MPP数仓)
- Snowflake(云原生数仓)
- ClickHouse(开源OLAP引擎)
- Doris(开源OLAP引擎)
边界 :适用于已知分析需求、高SLA(数据可用性保障)要求的场景,但对非结构化数据支持弱、扩展成本高。
数据湖(Data Lake)
定位 :原始数据的“中央存储池”,支持多源异构数据统一存储。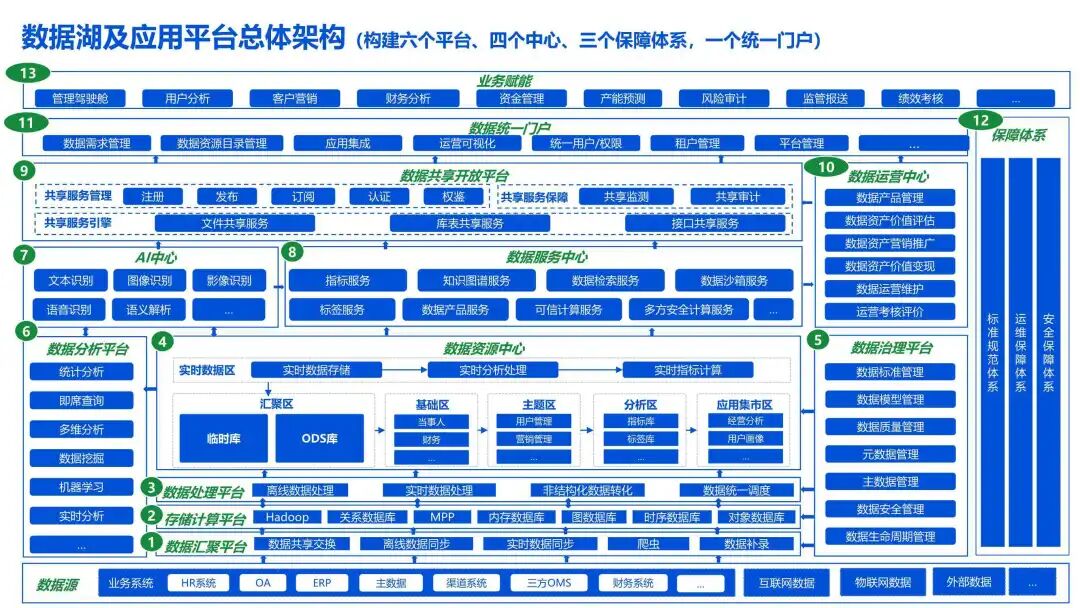
特点 :
- 支持结构化、半结构化、非结构化数据(如日志、图像、视频);
- Schema-on-read(读时建模),灵活性强;
- 成本低(常基于对象存储如S3/HDFS);
- 初期易陷入“数据沼泽”(缺乏治理)。
代表技术 :
- Delta Lake(Databricks)
- Apache Iceberg
- Apache Hudi
边界 :适合探索性分析、机器学习原始数据准备,但缺乏事务支持、数据质量难保障。
湖仓一体(Lakehouse)
定位 :融合数据湖的灵活性与数据仓库的可靠性。
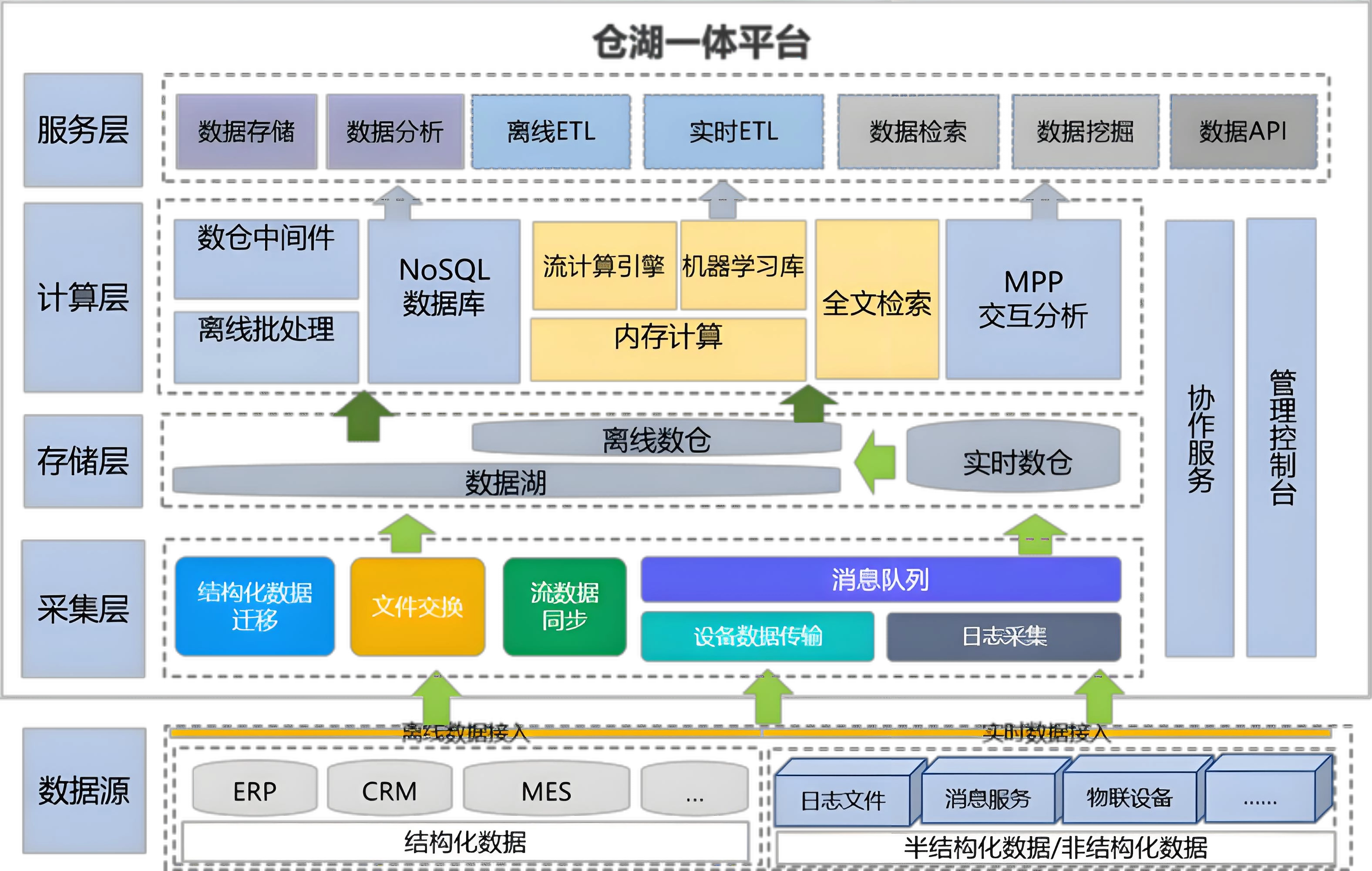
核心思想 :
- 在低成本对象存储上实现ACID事务、Schema管理、数据版本控制;
- 同一份数据同时支持BI、ETL、ML等多种负载;
- 统一元数据、统一访问接口。
关键技术 :
- Delta Lake(Databricks)
- Apache Iceberg
- Apache Hudi
优势 :
- 打破“湖”与“仓”的割裂;
- 降低数据冗余与同步成本;
- 支持实时+批处理混合负载。
边界 :是当前主流演进方向,但对技术栈整合与运维能力要求较高。
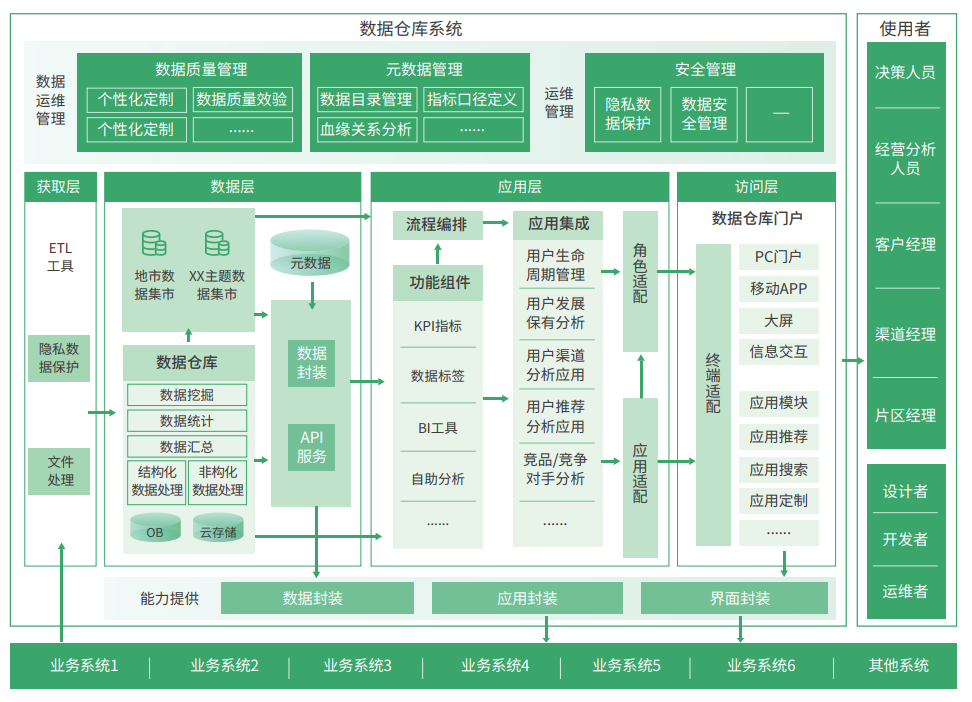
数据中台(Data Middle Platform)
定位 :企业级数据能力复用平台,强调“服务化”与“资产化”。
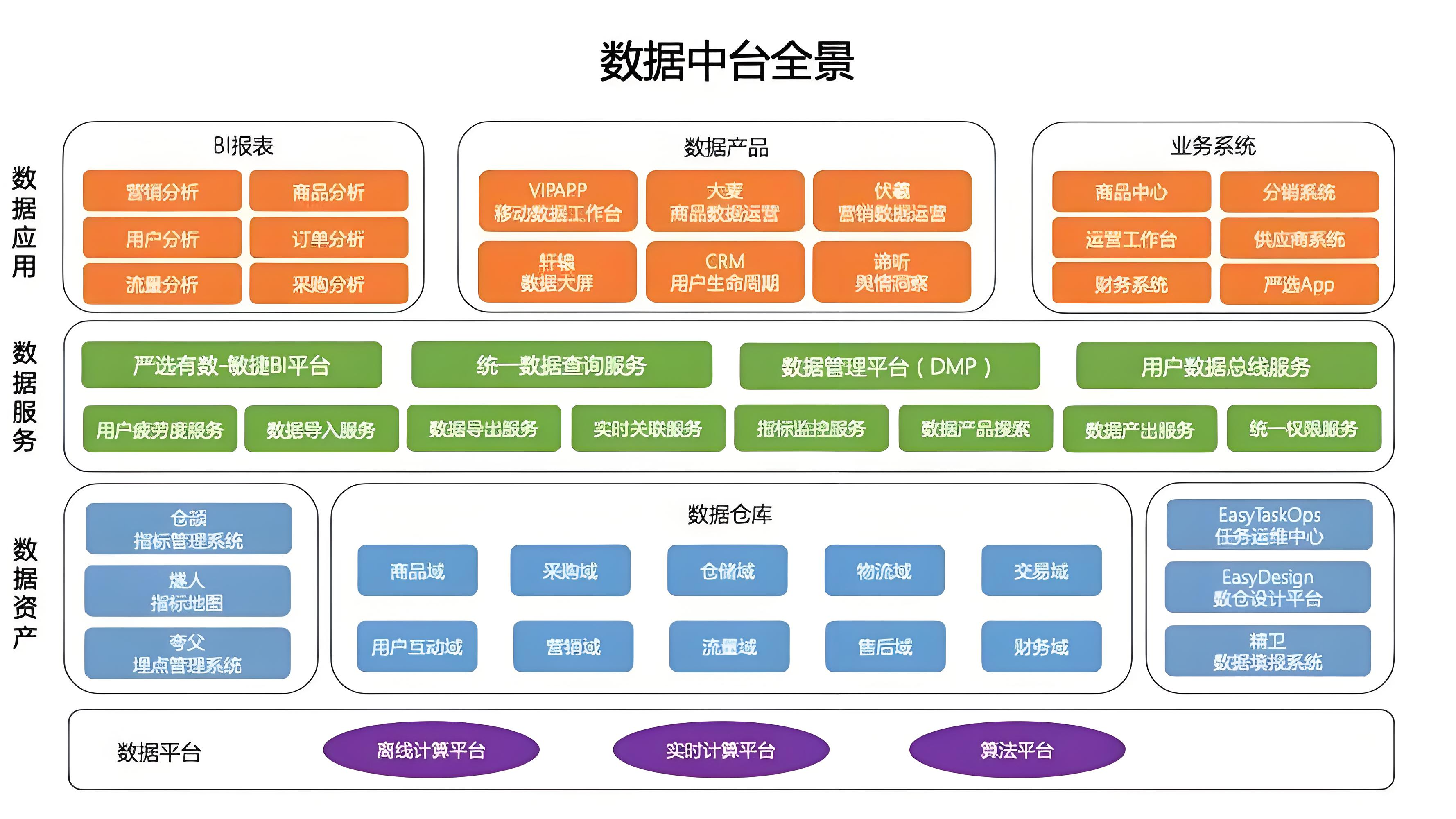
核心组成 :
- 统一数据底座 (可能基于湖仓一体);
- 数据资产目录 (元数据、血缘、标签);
- 数据服务层 (API、指标、标签、画像);
- 数据治理与安全体系 。
目标 :让前端业务快速调用高质量数据服务,避免重复建设。
中国特色 :源于阿里“大中台、小前台”战略,强调组织+技术双轮驱动。
边界 :不是技术产品,而是“技术+流程+组织”的综合体;依赖底层数据基础设施(如湖仓)。
AI中台(AI Middle Platform / MLOps Platform)
定位 :支撑AI模型全生命周期管理的平台。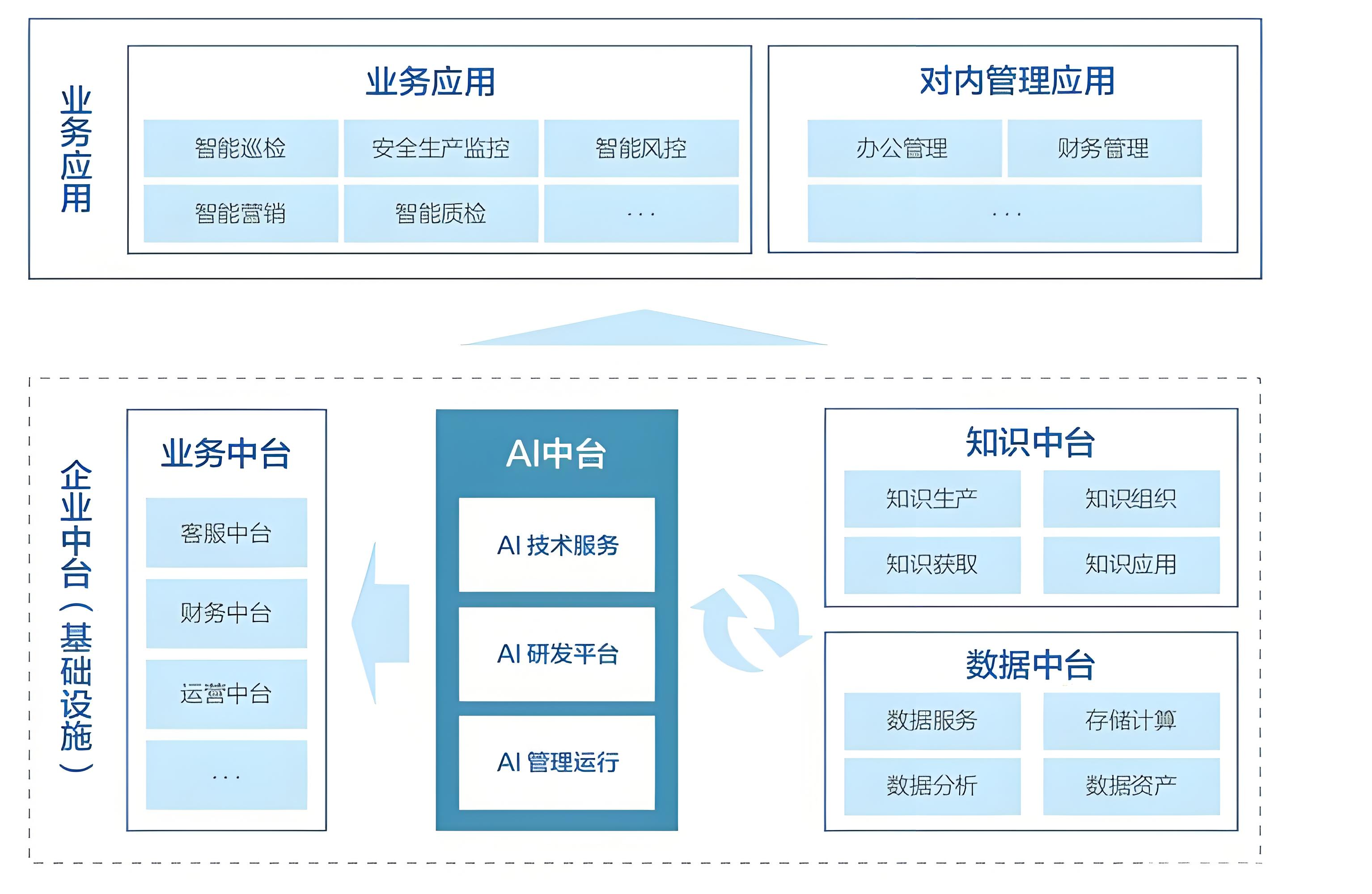
核心能力 :
- 特征工程与特征存储(Feature Store);
- 模型训练、部署、监控、回滚;
- 实验管理(Experiment Tracking);
- 自动化ML(AutoML);
- 与数据中台紧密集成(获取高质量特征数据)。
代表平台 :
- Feast
- Tecton
- Databricks MLflow
- PAI(阿里)
- ModelArts(华为)
边界 :聚焦AI工程化,依赖数据中台提供“干净、一致、实时”的特征数据。
演进逻辑:从割裂到融合
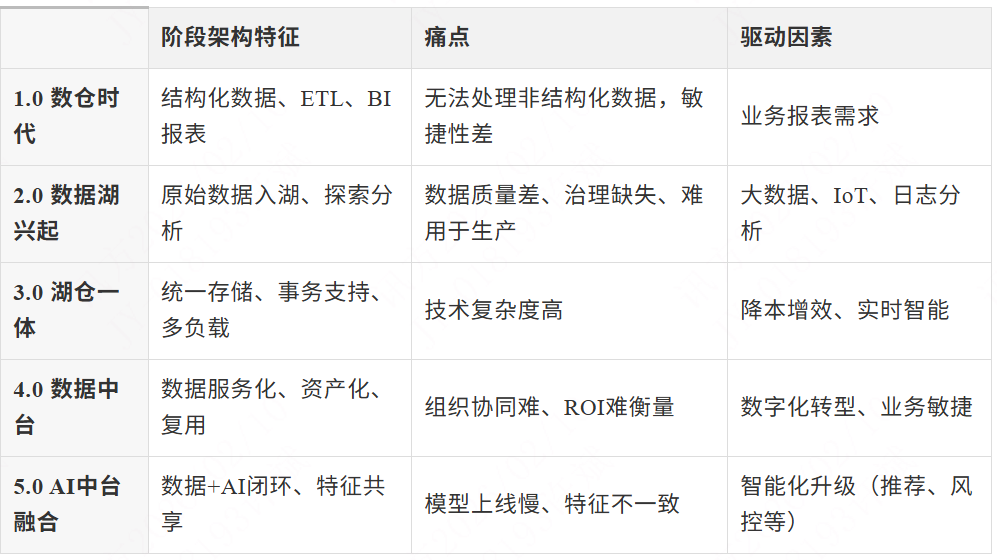
演进主线 :
数据可用 → 数据好用 → 数据智能 → 数据驱动业务
如何协同?—— 构建一体化数据智能架构
一个现代化的企业数据智能架构: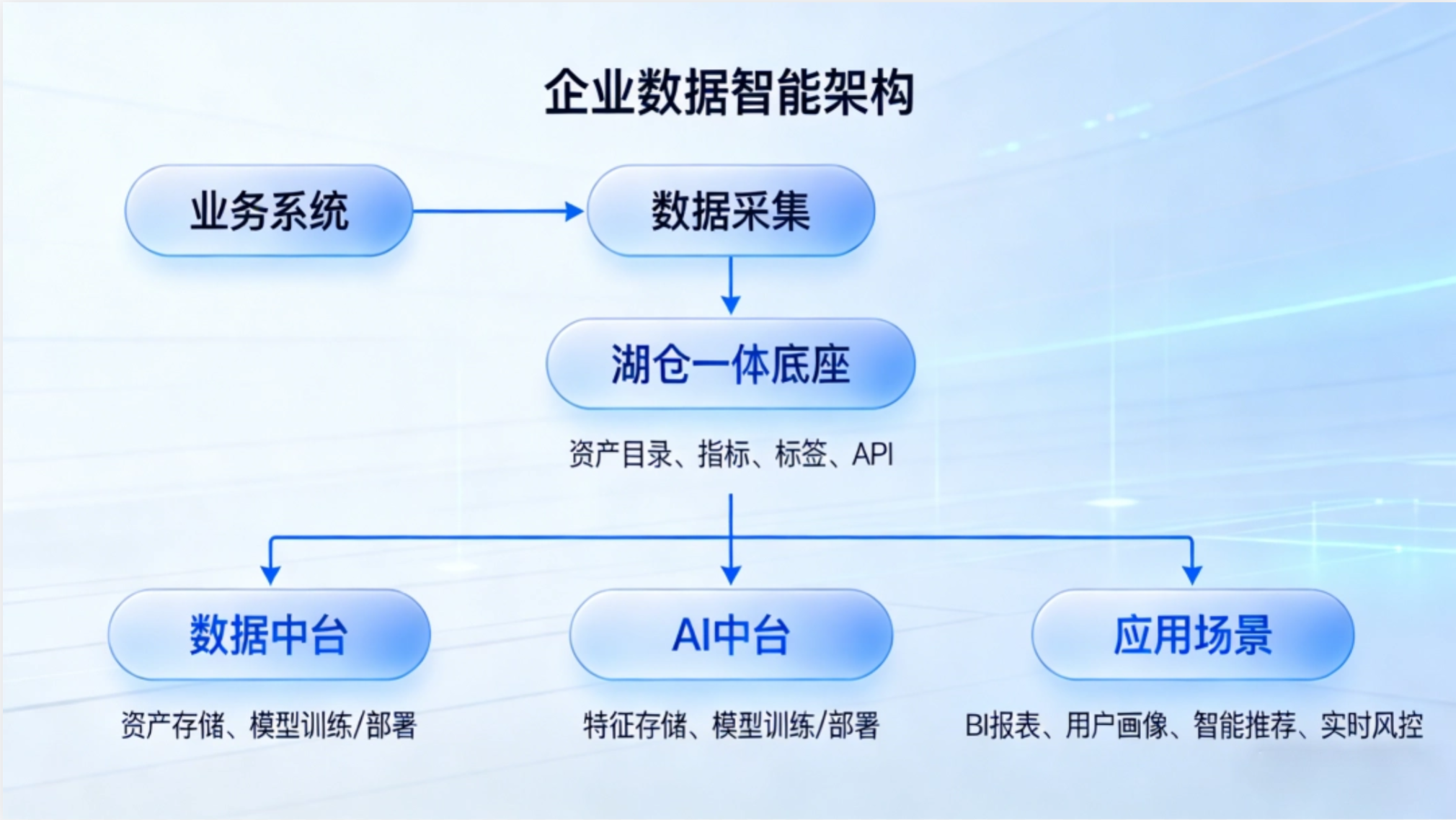
协同要点:
湖仓一体作为统一底座
- 承载所有原始数据与加工数据
- 通过Iceberg/Delta等格式保证一致性
- 支持批流一体
- SQL+ML统一访问
数据中台构建“数据产品”
- 将湖仓中的表转化为可复用的指标、标签、画像
- 通过API或服务网关供业务调用
- 内嵌数据质量、血缘、权限控制
AI中台依赖数据中台的特征供给
- 特征工程结果注册到特征库
- 训练与推理使用同一套特征,避免“训练-上线偏差”
- 模型效果反哺数据中台优化标签体系
治理贯穿始终
- 元数据统一管理(如Apache Atlas)
- 数据血缘追踪(从源系统到AI模型)
- 成本与性能监控(如查询优化、存储分层)
选型建议与落地路径

关键成功因素 :
- 避免“为建中台而建中台”,以业务价值为导向
- 技术选型需考虑团队能力(如是否熟悉Spark/Flink)
- 建立数据文化与跨部门协作机制
总结:边界与融合的本质
最终目标 :
构建一个 “采、存、管、用、智”一体化 的数据智能体系,让数据从“资源”变为“资产”,再进化为“智能生产力”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)