计算机毕业设计Django+LLM大模型美食推荐系统 菜谱食谱数据分析 大数据毕业设计(源码+LW文档+PPT+讲解)
本文介绍了一个基于Django框架和LLM大模型的美食推荐系统。系统采用分层架构设计,整合了Django的Web开发能力与LLM的语义理解功能,通过用户画像构建、混合推荐算法和特征向量化等技术实现个性化推荐。关键技术包括LLM集成方案、实时推荐API和性能优化措施(异步处理、缓存策略等)。系统还考虑了安全因素,提供输入净化、API限速和数据脱敏等保护机制。部署方案支持容器化,并建议采用渐进式开发策
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + LLM大模型美食推荐系统技术说明
一、系统概述
本系统基于Django框架与大型语言模型(LLM)构建,旨在为用户提供个性化美食推荐服务。系统结合Django的快速开发能力和LLM的语义理解与生成能力,通过分析用户历史行为、偏好数据及实时输入,生成精准且富有创意的美食推荐方案。
二、技术架构
2.1 整体架构
1用户层 → Web前端 → Django后端 → LLM服务层 → 数据存储层
22.2 核心组件
- Django框架
- 提供RESTful API接口
- 用户认证与会话管理
- 业务逻辑处理
- 数据库交互
- LLM大模型
- 语义理解:解析用户查询意图
- 内容生成:创建个性化推荐文案
- 上下文推理:结合用户历史行为优化推荐
- 数据存储
- PostgreSQL:存储用户信息、行为日志
- Redis:缓存热门推荐、会话数据
- 向量数据库(如FAISS):存储美食特征向量
三、核心功能实现
3.1 用户画像构建
python
1# models.py 示例
2class UserProfile(models.Model):
3 user = models.OneToOneField(User, on_delete=models.CASCADE)
4 dietary_preferences = models.JSONField(default=dict) # 饮食偏好
5 cuisine_preferences = models.ManyToManyField('Cuisine') # 菜系偏好
6 allergy_info = models.JSONField(default=list) # 过敏信息
7 last_active = models.DateTimeField(auto_now=True)
8
9class UserBehavior(models.Model):
10 user = models.ForeignKey(User, on_delete=models.CASCADE)
11 dish_id = models.IntegerField()
12 rating = models.FloatField() # 评分(0-5)
13 timestamp = models.DateTimeField(auto_now_add=True)
143.2 LLM集成方案
方案一:直接API调用
python
1# services/llm_service.py
2import openai
3from django.conf import settings
4
5class LLMRecommender:
6 def __init__(self):
7 self.model = settings.LLM_MODEL # 如"gpt-4-turbo"
8
9 def generate_recommendation(self, user_profile, context):
10 prompt = f"""
11 用户画像: {user_profile}
12 当前场景: {context}
13 请生成3个美食推荐,包含:
14 1. 菜品名称
15 2. 推荐理由(不超过50字)
16 3. 适合场景
17 使用JSON格式输出
18 """
19
20 response = openai.ChatCompletion.create(
21 model=self.model,
22 messages=[{"role": "user", "content": prompt}]
23 )
24 return self._parse_response(response.choices[0].message.content)
25方案二:本地化部署(以Llama3为例)
python
1# 使用vLLM或HuggingFace Transformers
2from transformers import AutoModelForCausalLM, AutoTokenizer
3
4class LocalLLM:
5 def __init__(self):
6 self.tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B")
7 self.model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B")
8
9 def generate(self, prompt, max_length=200):
10 inputs = self.tokenizer(prompt, return_tensors="pt")
11 outputs = self.model.generate(**inputs, max_length=max_length)
12 return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
133.3 混合推荐算法
python
1# recommenders/hybrid.py
2class HybridRecommender:
3 def __init__(self):
4 self.collaborative = CollaborativeFiltering()
5 self.content_based = ContentBasedFiltering()
6 self.llm = LLMRecommender()
7
8 def recommend(self, user, context=None):
9 # 1. 协同过滤基础推荐
10 cf_recs = self.collaborative.get_recommendations(user)
11
12 # 2. 内容过滤优化
13 content_recs = self.content_based.refine(cf_recs, user.profile)
14
15 # 3. LLM生成个性化描述
16 final_recs = []
17 for dish in content_recs[:5]: # 取前5个
18 reasoning = self.llm.generate_recommendation(
19 user.profile,
20 f"当前场景: {context or '日常用餐'}\n推荐菜品: {dish.name}"
21 )
22 final_recs.append({
23 'dish': dish,
24 'reason': reasoning['reason'],
25 'scenario': reasoning['scenario']
26 })
27
28 return final_recs
29四、关键技术实现
4.1 美食特征向量化
python
1# 使用Sentence-BERT提取美食特征
2from sentence_transformers import SentenceTransformer
3
4class DishEmbedding:
5 def __init__(self):
6 self.model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
7
8 def get_embedding(self, dish_text):
9 """
10 dish_text格式: "菜品名称|主要食材|烹饪方式|口味|文化背景"
11 """
12 return self.model.encode(dish_text).tolist()
134.2 实时推荐API
python
1# views.py
2from rest_framework.decorators import api_view
3from rest_framework.response import Response
4
5@api_view(['POST'])
6@permission_classes([IsAuthenticated])
7def get_recommendations(request):
8 context = request.data.get('context', '')
9 user = request.user
10
11 try:
12 recommendations = HybridRecommender().recommend(user, context)
13 return Response({
14 'status': 'success',
15 'data': recommendations
16 }, status=200)
17 except Exception as e:
18 return Response({
19 'status': 'error',
20 'message': str(e)
21 }, status=500)
224.3 性能优化措施
- 异步处理:使用Celery处理LLM生成任务
python
1# tasks.py
2from celery import shared_task
3
4@shared_task
5def generate_llm_recommendation(user_id, context):
6 user = User.objects.get(id=user_id)
7 return HybridRecommender().recommend(user, context)
8- 缓存策略:
python
1# 使用django-cacheops缓存热门推荐
2from cacheops import cached_as
3
4@cached_as(Dish, timeout=3600)
5def get_popular_dishes():
6 return Dish.objects.order_by('-rating')[:10]
7- 向量检索优化:
python
1# 使用FAISS进行快速相似度搜索
2import faiss
3import numpy as np
4
5class VectorSearch:
6 def __init__(self, dim=384):
7 self.index = faiss.IndexFlatIP(dim)
8 self.dish_ids = []
9
10 def add_dishes(self, embeddings, dish_ids):
11 self.index.add(np.array(embeddings))
12 self.dish_ids.extend(dish_ids)
13
14 def search(self, query_embedding, k=5):
15 distances, indices = self.index.search(
16 np.array([query_embedding]), k
17 )
18 return [self.dish_ids[i] for i in indices[0]]
19五、部署方案
5.1 开发环境配置
dockerfile
1# Dockerfile示例
2FROM python:3.9-slim
3
4WORKDIR /app
5COPY requirements.txt .
6RUN pip install --no-cache-dir -r requirements.txt
7
8COPY . .
9CMD ["gunicorn", "--bind", "0.0.0.0:8000", "config.wsgi:application"]
105.2 生产环境架构
1Nginx → Gunicorn → Django应用
2 ↑
3LLM服务集群(可选GPU节点)
4 ↑
5PostgreSQL + Redis + FAISS
65.3 监控方案
- Prometheus + Grafana:监控API响应时间
- Sentry:错误跟踪
- 自定义LLM监控:
python
1# metrics.py
2from prometheus_client import Counter
3
4LLM_REQUESTS = Counter(
5 'llm_requests_total',
6 'Total LLM API requests',
7 ['status']
8)
9
10LLM_LATENCY = Counter(
11 'llm_latency_seconds',
12 'LLM API latency',
13 ['model']
14)
15六、安全考虑
- 输入净化:
python
1# utils/sanitizer.py
2import re
3from bleach import clean
4
5def sanitize_llm_input(text):
6 # 移除潜在危险字符
7 text = re.sub(r'[;|\'"<>]', '', text)
8 # 净化HTML标签
9 return clean(text, tags=[], attributes={}, strip=True)
10- API速率限制:
python
1# settings.py
2REST_FRAMEWORK = {
3 'DEFAULT_THROTTLE_CLASSES': [
4 'rest_framework.throttling.AnonRateThrottle',
5 'rest_framework.throttling.UserRateThrottle'
6 ],
7 'DEFAULT_THROTTLE_RATES': {
8 'anon': '100/day',
9 'user': '1000/day'
10 }
11}
12- 数据脱敏:
python
1# serializers.py
2from rest_framework import serializers
3
4class UserProfileSerializer(serializers.ModelSerializer):
5 class Meta:
6 model = UserProfile
7 exclude = ['allergy_info'] # 敏感信息不返回
8七、扩展功能建议
- 多模态推荐:结合菜品图片/视频生成推荐
- AR菜单体验:使用WebXR展示3D菜品模型
- 营养分析集成:连接USDA食品数据库提供营养信息
- 社交推荐:基于好友关系的推荐增强
八、总结
本系统通过Django与LLM的有机结合,实现了:
- 实时个性化推荐
- 语义理解驱动的智能交互
- 高可扩展的架构设计
- 企业级的安全保障
实际部署时建议采用渐进式策略,先实现基础推荐功能,再逐步集成更复杂的LLM能力。对于高并发场景,可考虑使用LLM服务网格(Service Mesh)架构分散请求压力。
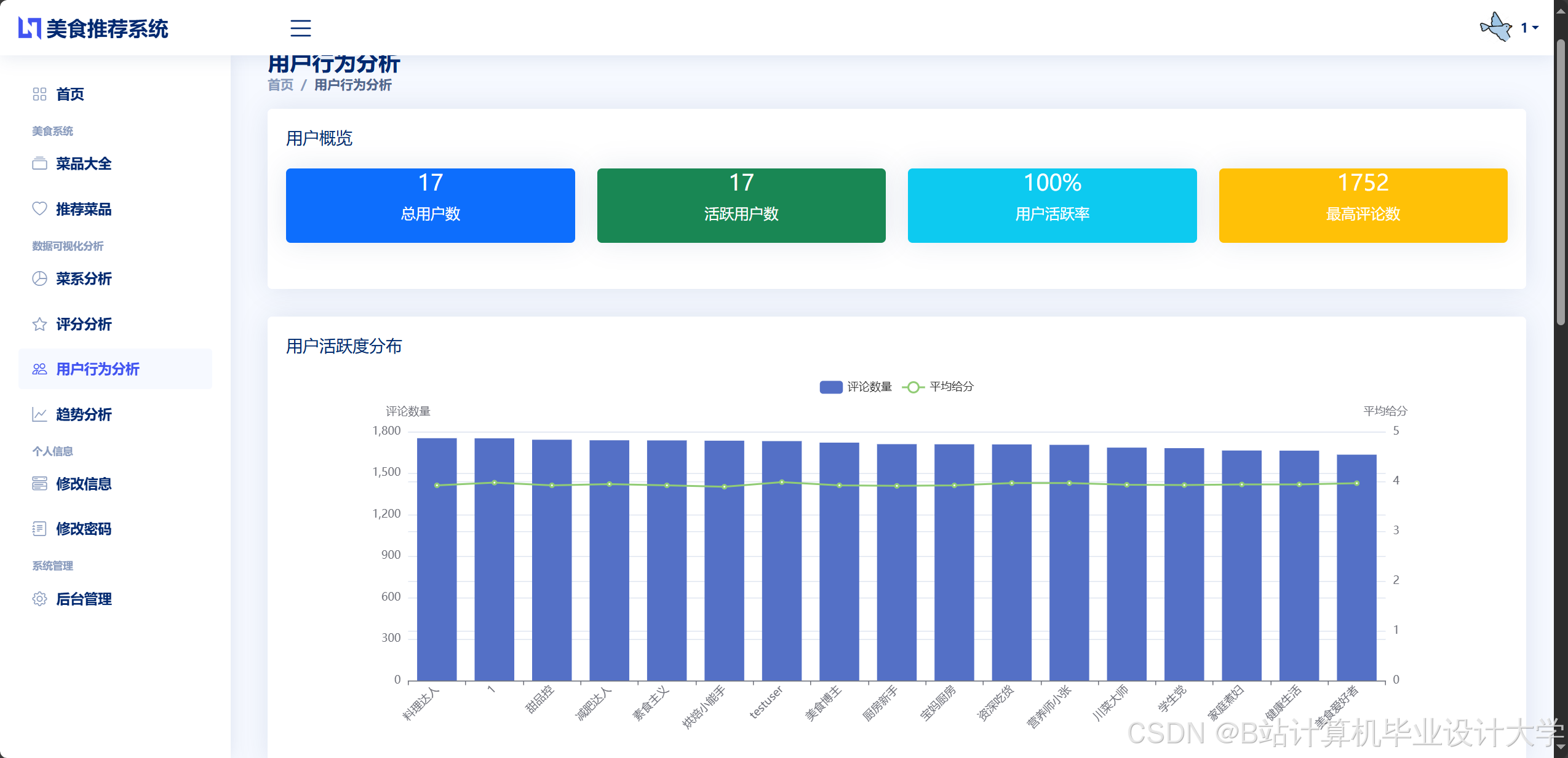
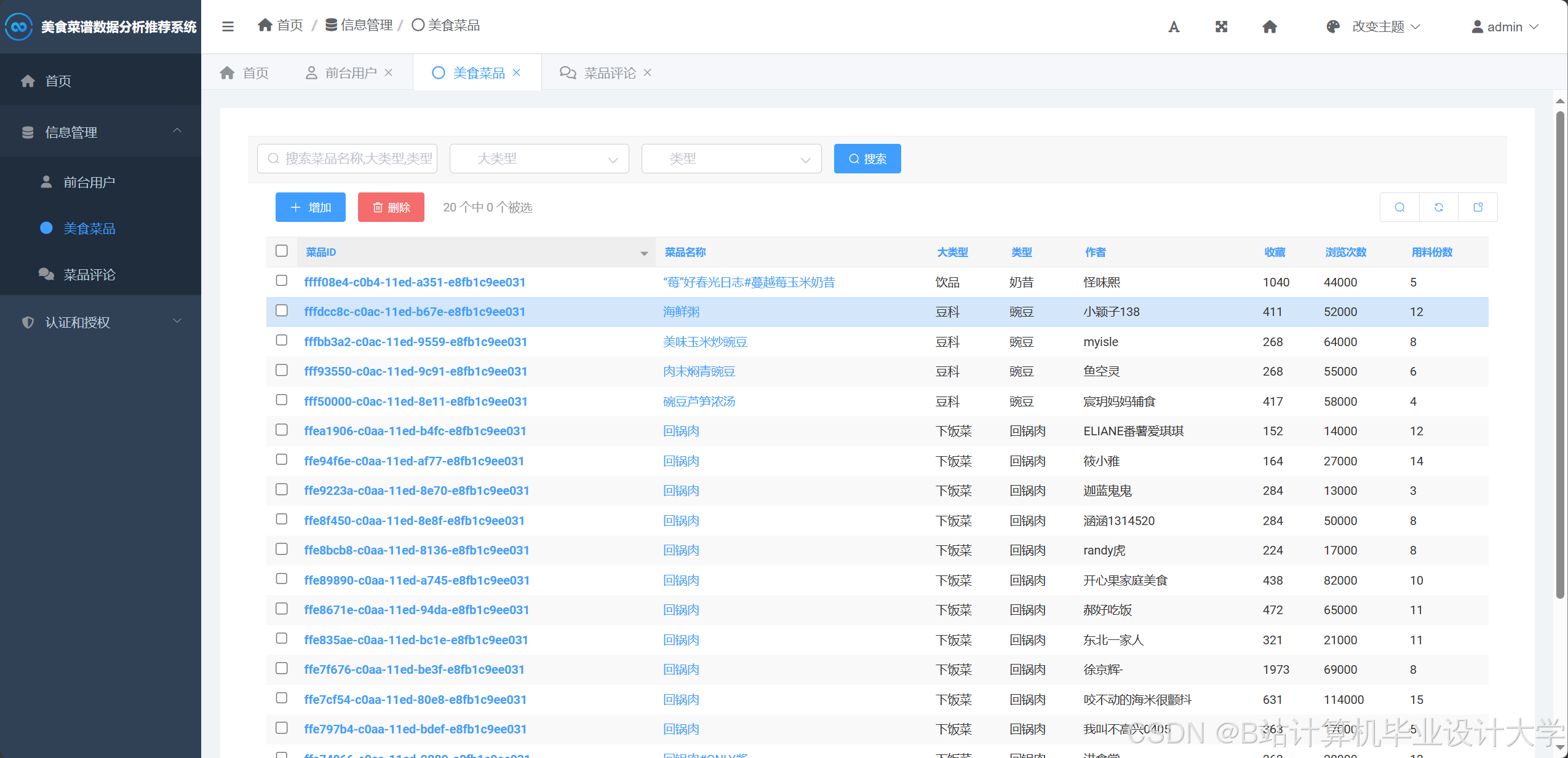
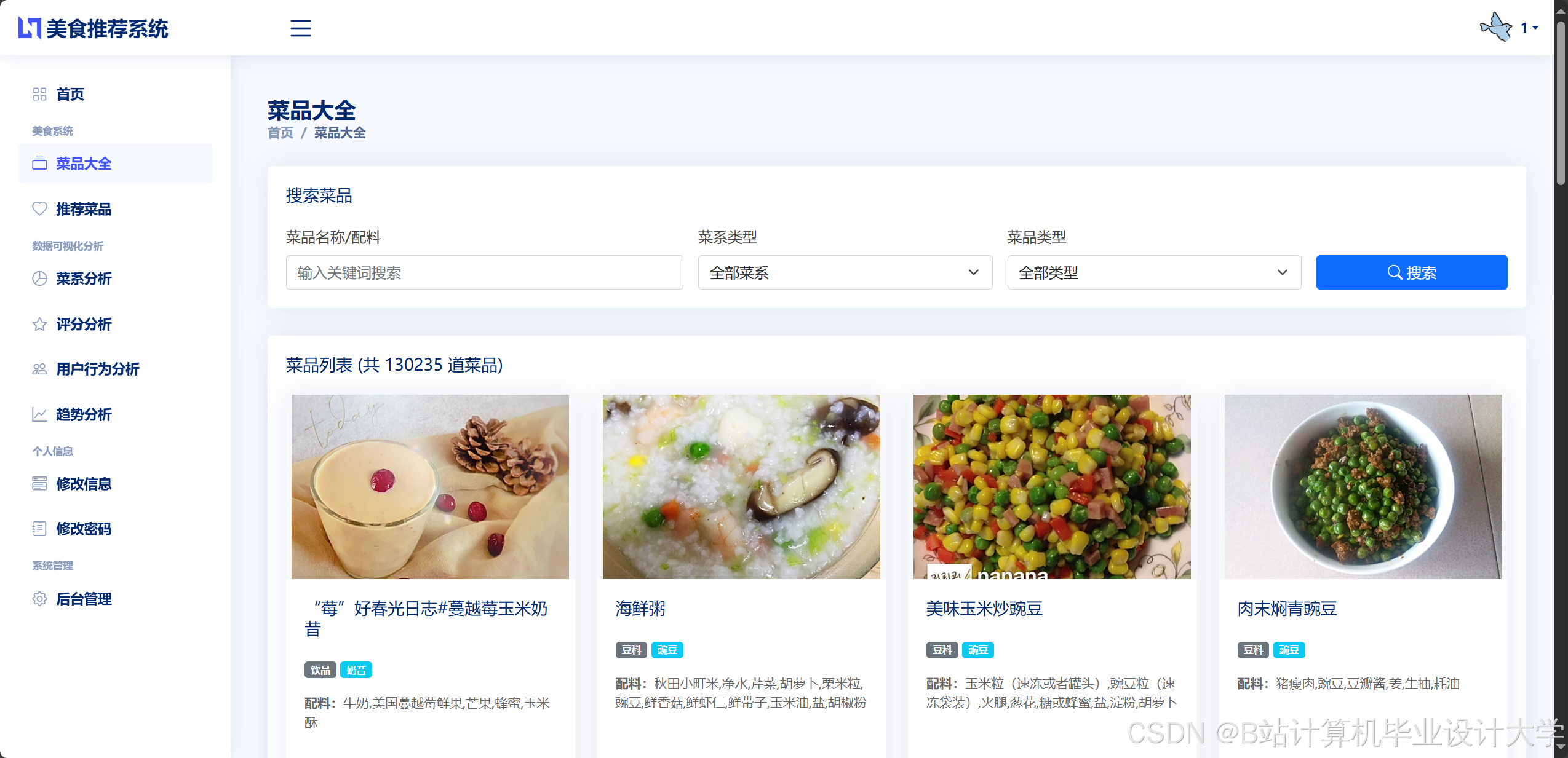
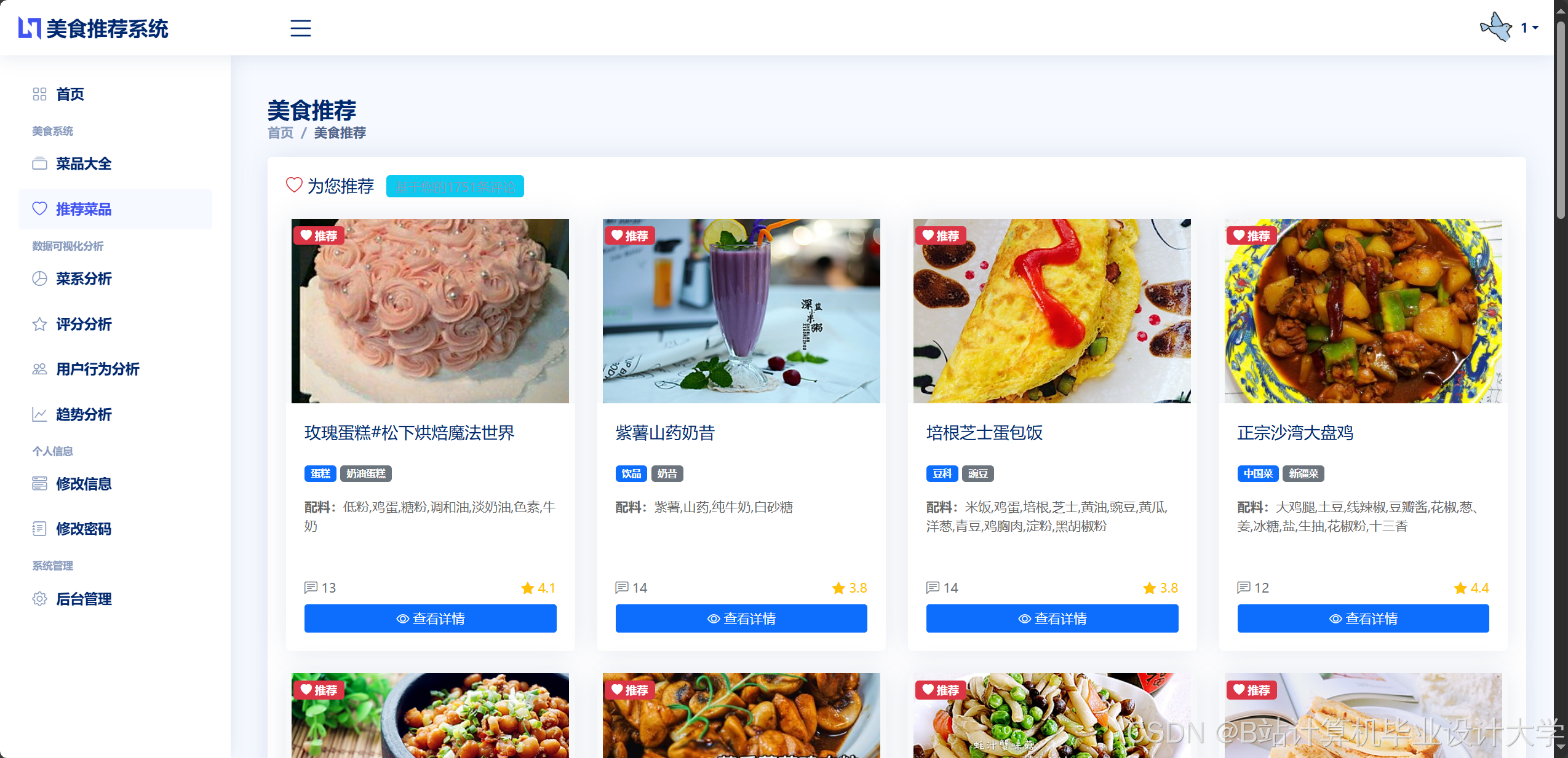
运行截图
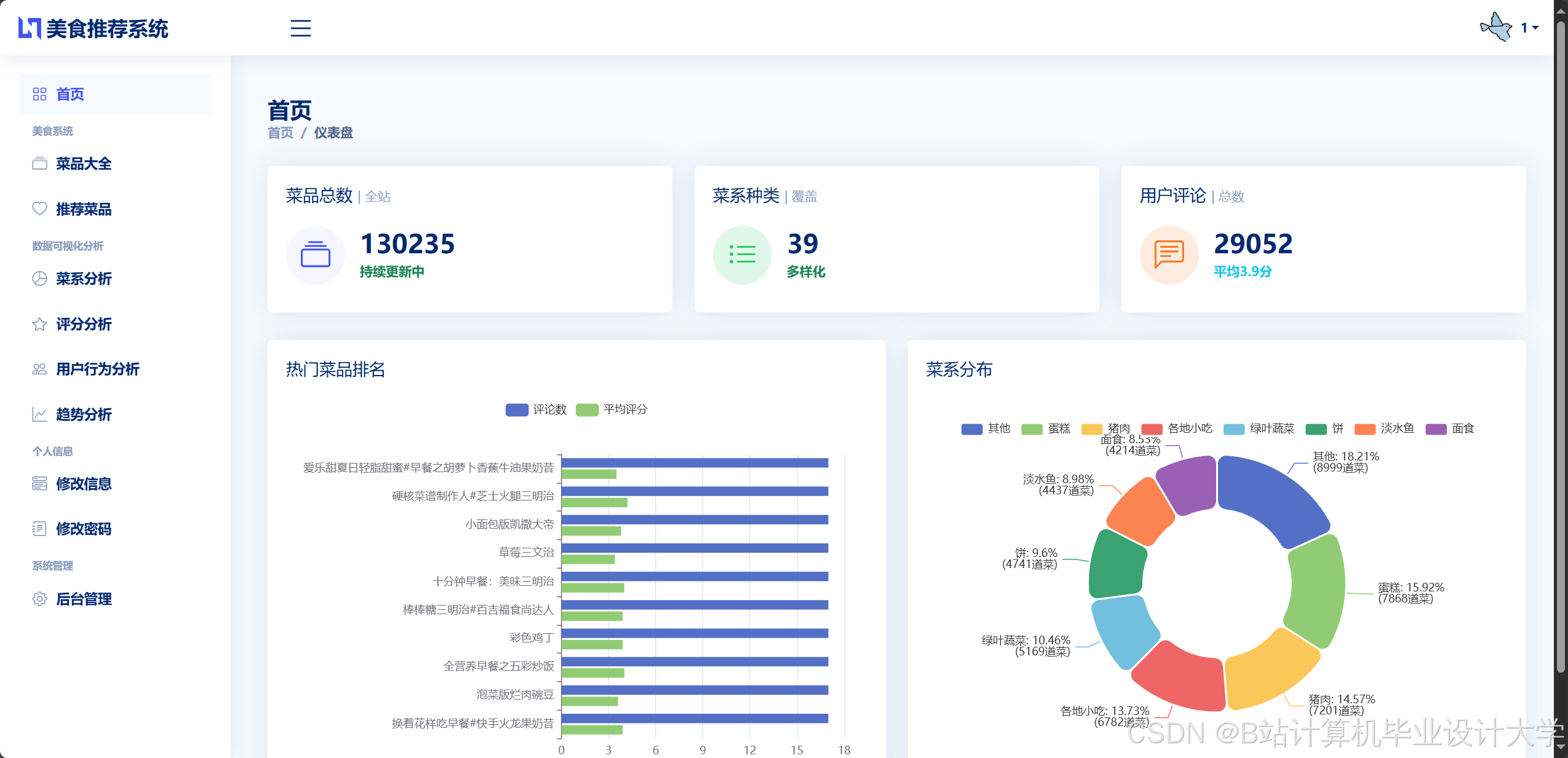
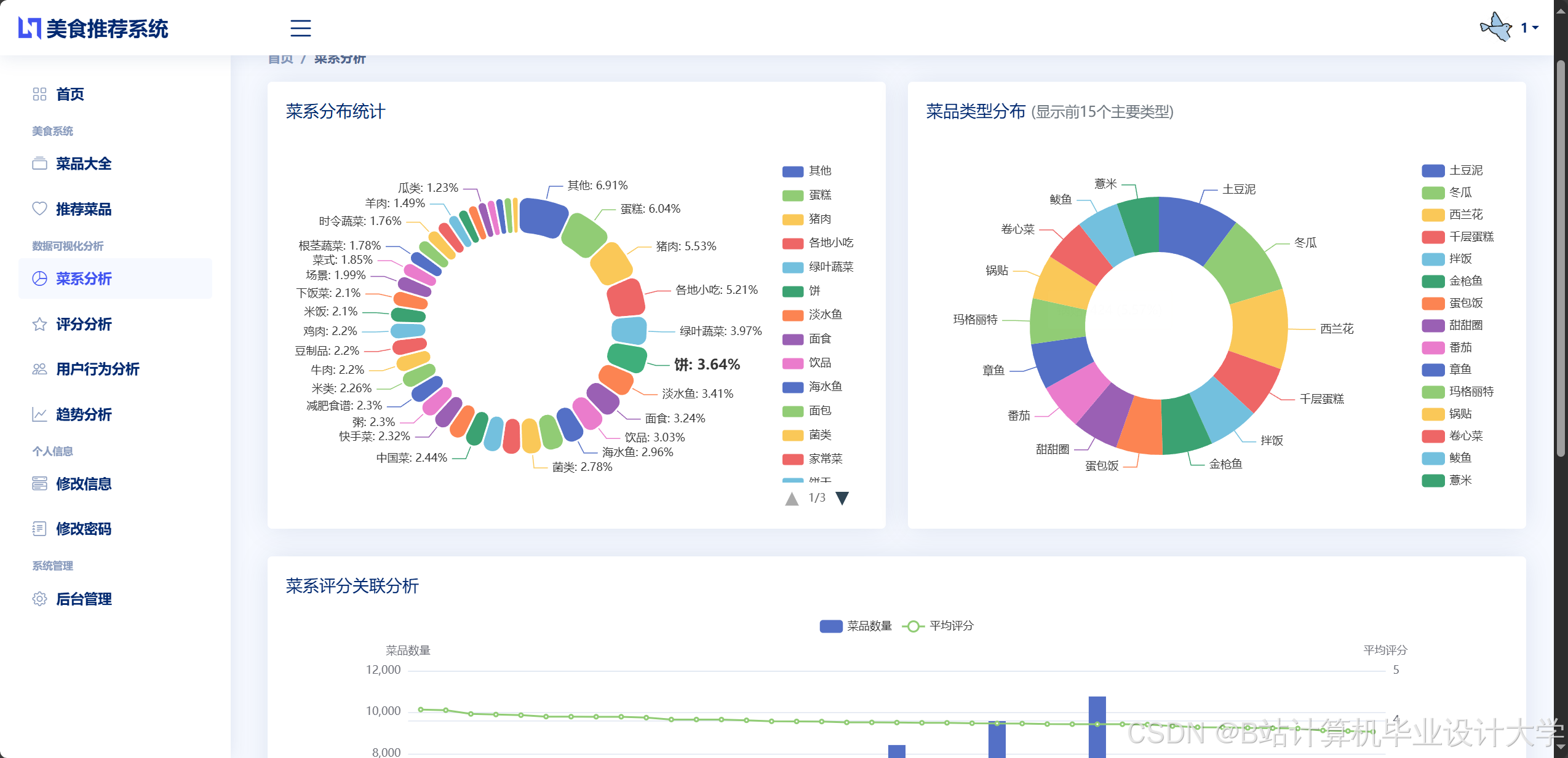
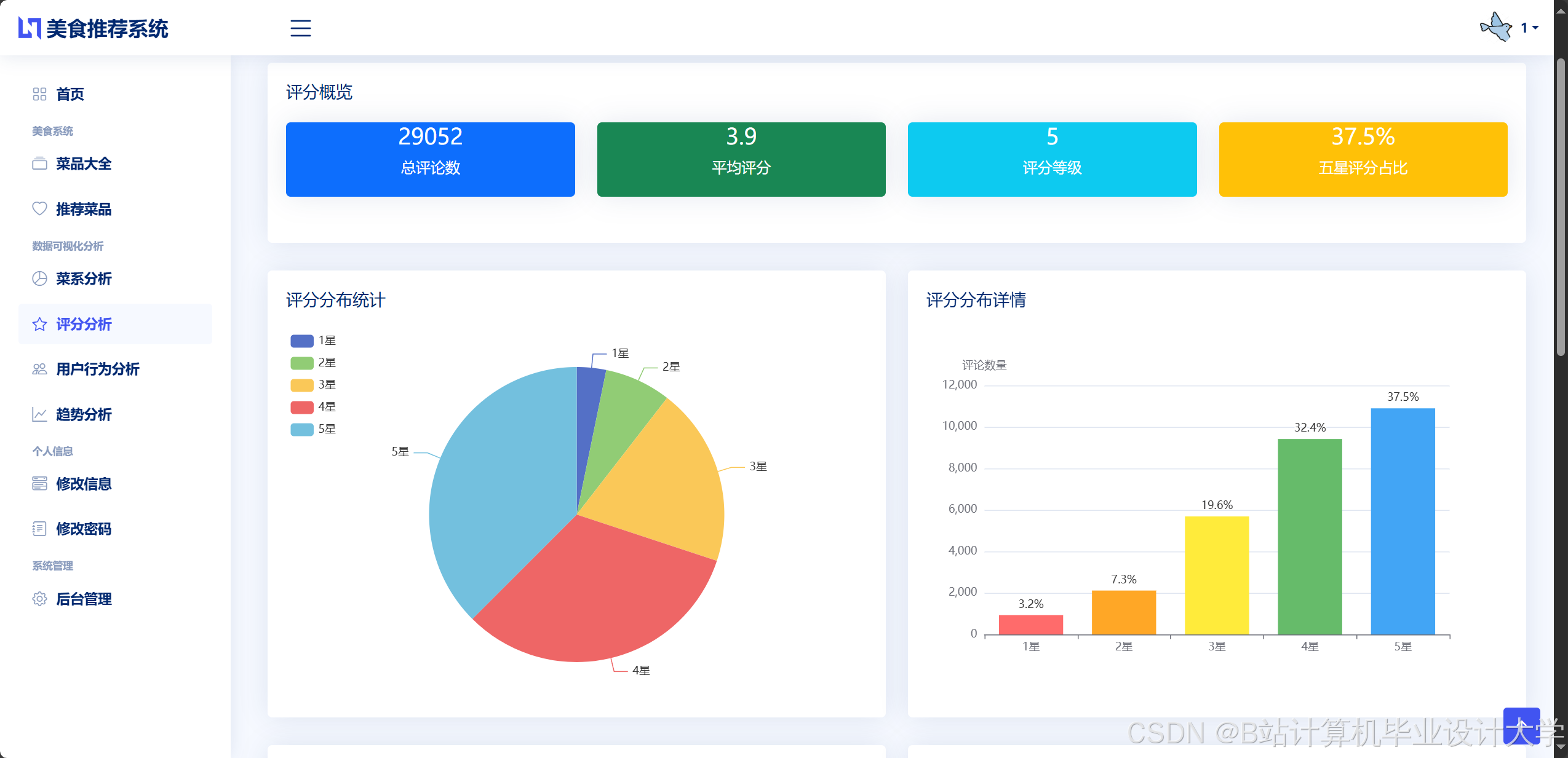
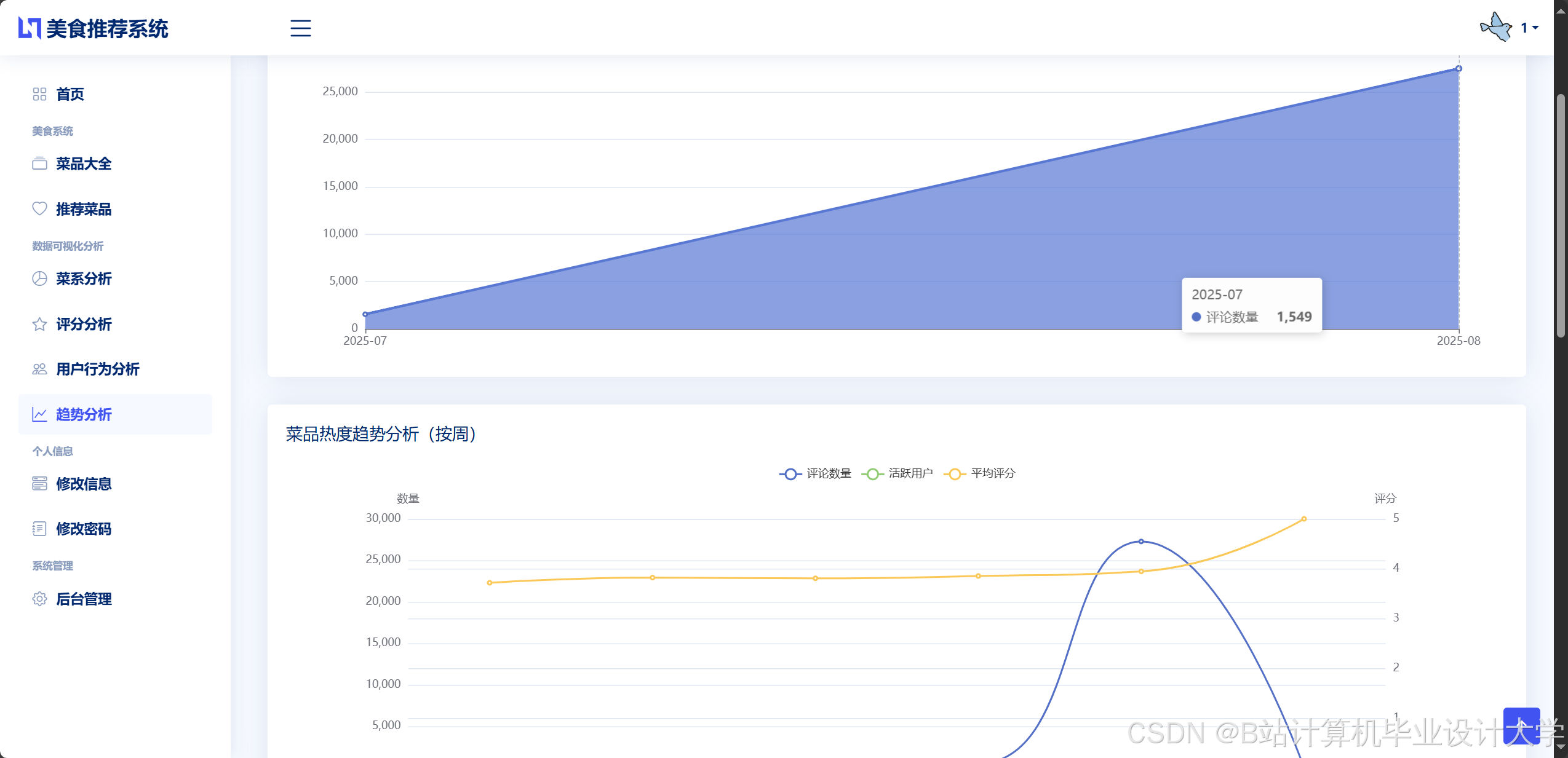
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献919条内容
已为社区贡献919条内容

所有评论(0)