LLaMA Factory微调Llama3模型(附教程)
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过Web UI界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架。
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过Web UI界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架。
- 💥GPU推荐使用24GB显存的A10(
ecs.gn7i-c8g1.2xlarge)或更高配置 - 💥镜像选择DSW官方镜像
modelscope:1.14.0-pytorch2.1.2-gpu-py310-cu121-ubuntu22.04
我们来微调llama3-8B模型尝试一下
安装LLaMA Factory
💢拉取LLaMA-Factory项目
代码语言:javascript
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
#
正克隆到 'LLaMA-Factory'...
remote: Enumerating objects: 298, done.
remote: Counting objects: 100% (298/298), done.
remote: Compressing objects: 100% (218/218), done.
remote: Total 298 (delta 76), reused 204 (delta 67), pack-reused 0 (from 0)
接收对象中: 100% (298/298), 7.85 MiB | 5.21 MiB/s, 完成.
处理 delta 中: 100% (76/76), 完成.
💢然后安装LLaMA-Factory依赖环境。
代码语言:javascript
pip uninstall -y vllm
pip install llamafactory[metrics]==0.7.1
pip install accelerate==0.30.1
安装后输入llamafactory-cli version检查一下是否安装成功:
代码语言:javascript
llamafactory-cli version
#
----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.7.1 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
LLaMA-Factory项目内置了丰富的数据集,放在了data目录下,我们也可以准备自定义数据集,将数据处理为框架特定的格式,放在data下,并且修改dataset_info.json文件。
我们看一下官方给出的格式:
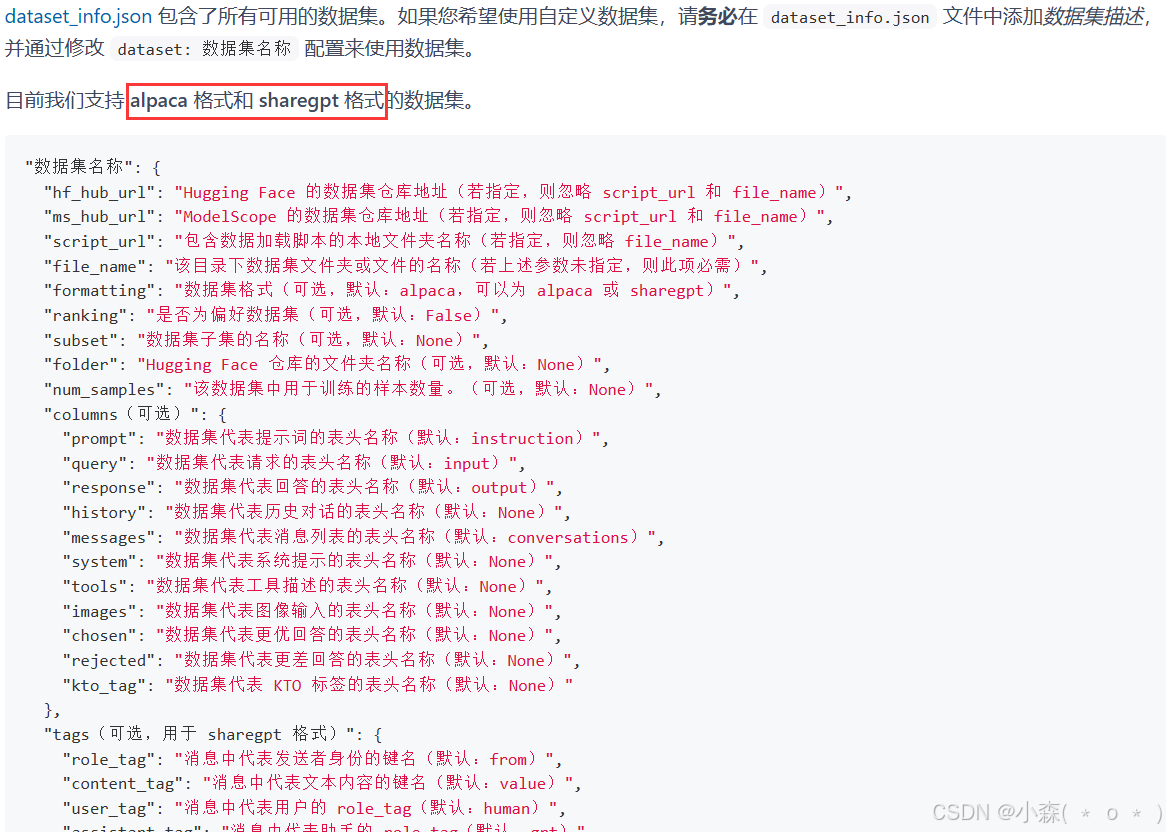
Alpaca 格式
代码语言:javascript
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
💫对于上述格式的数据,dataset_info.json 中的_数据集描述_应为:
代码语言:javascript
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
我们去官方寻找一份数据集来下载(notebook运行):
代码语言:javascript
%cd LLaMA-Factory
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
!mv data rawdata && unzip data.zip -d data
数据:
代码语言:javascript
[
{
"conversations": [
{
"from": "human",
"value": "模仿西游记的孙悟空的语气和我聊天。如果你把水冻住,你会得到什么?"
},
{
"from": "gpt",
"value": "哈哈,这问题还难倒俺老孙吗?把水冻住就是变成冰啦!不过若是在取经的路上用得着这冰来做啥,比如过火焰山时,那可就是解渴消暑的好东西了!你觉得呢?还有没有更有趣的问题让俺老孙来解答?"
},
{
"from": "human",
"value": "那怎么做才可以把水冻住"
},
{
"from": "gpt",
"value": "哈哈,对俺老孙来说,这可是轻而易举的事情!只需将水放在凉快的地方,或者使用法力,一吹仙气,水便能迅速结冰啦!当然,在你的世界里,把水放进冰箱的冷冻室里等一阵子,水就会变成冰块了。要是嫌慢,可以尝试用点干冰或液氮什么的,不过得小心使用哈!毕竟不像俺老孙有抗寒法力。"
}
]
}
]
模型微调
我们不光可以通过命令行进行微调,还可以启动一个webui来微调推理
代码语言:javascript
!export USE_MODELSCOPE_HUB=1 && \
llamafactory-cli webui
USE_MODELSCOPE_HUB设为1,表示模型来源是ModelScope
然后就进入到了web界面:
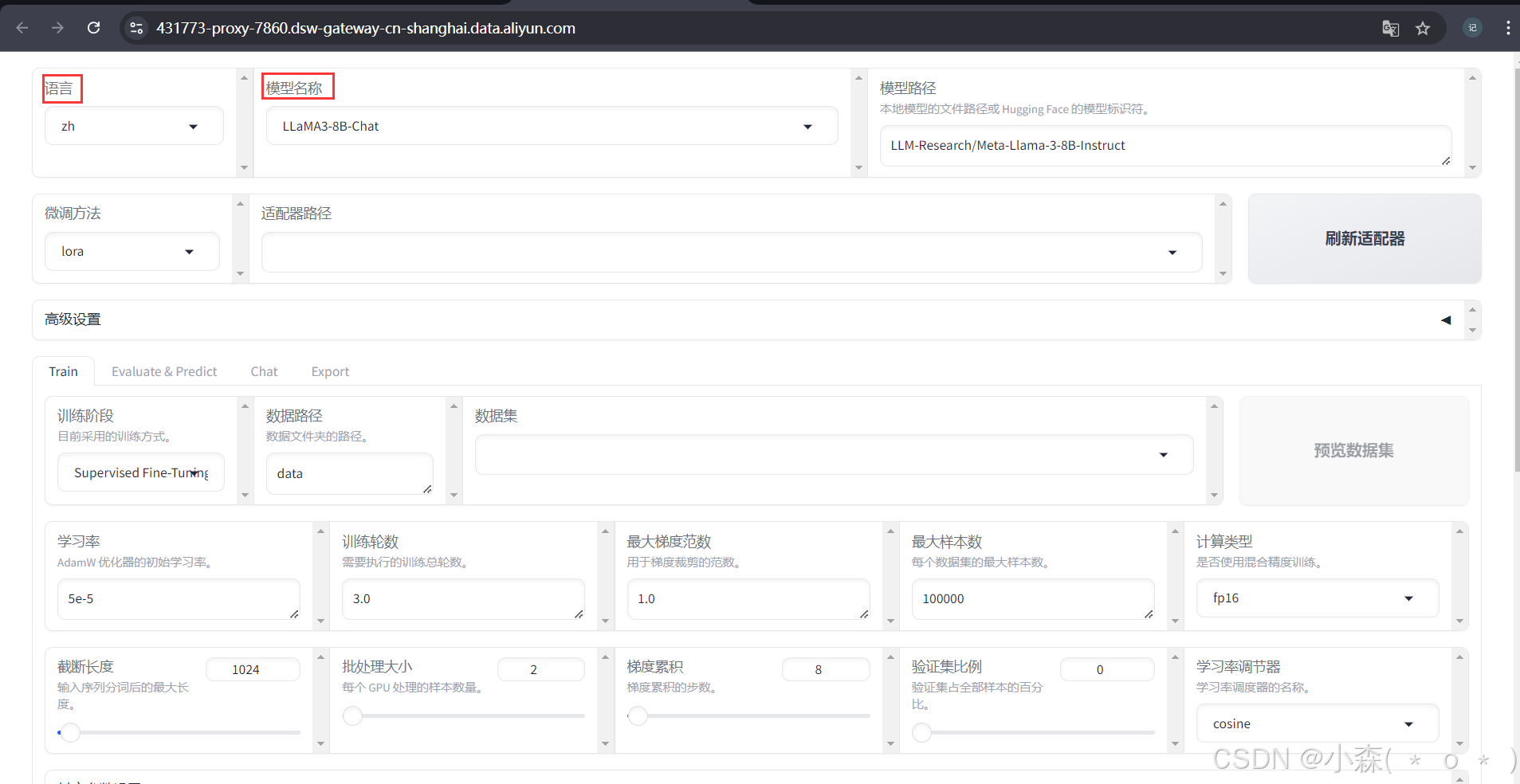
数据集使用上述下载的train.json,点击「预览数据集」可以预览一下数据
设置学习率为1e-4,梯度累积为2,有利于模型拟合,其他的可以按需调整;
将输出目录修改为train_llama3,训练后的LoRA权重将会保存在此目录中。点击「预览命令」可展示所有已配置的参数,点击「开始」启动模型微调!
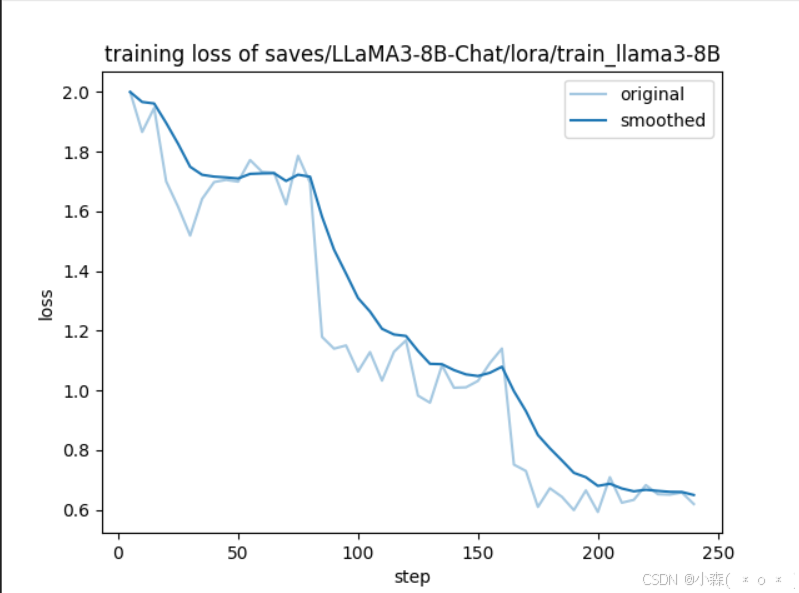
选择「Evaluate&Predict」栏,在数据集下拉列表中选择「eval」(验证集)评估模型。
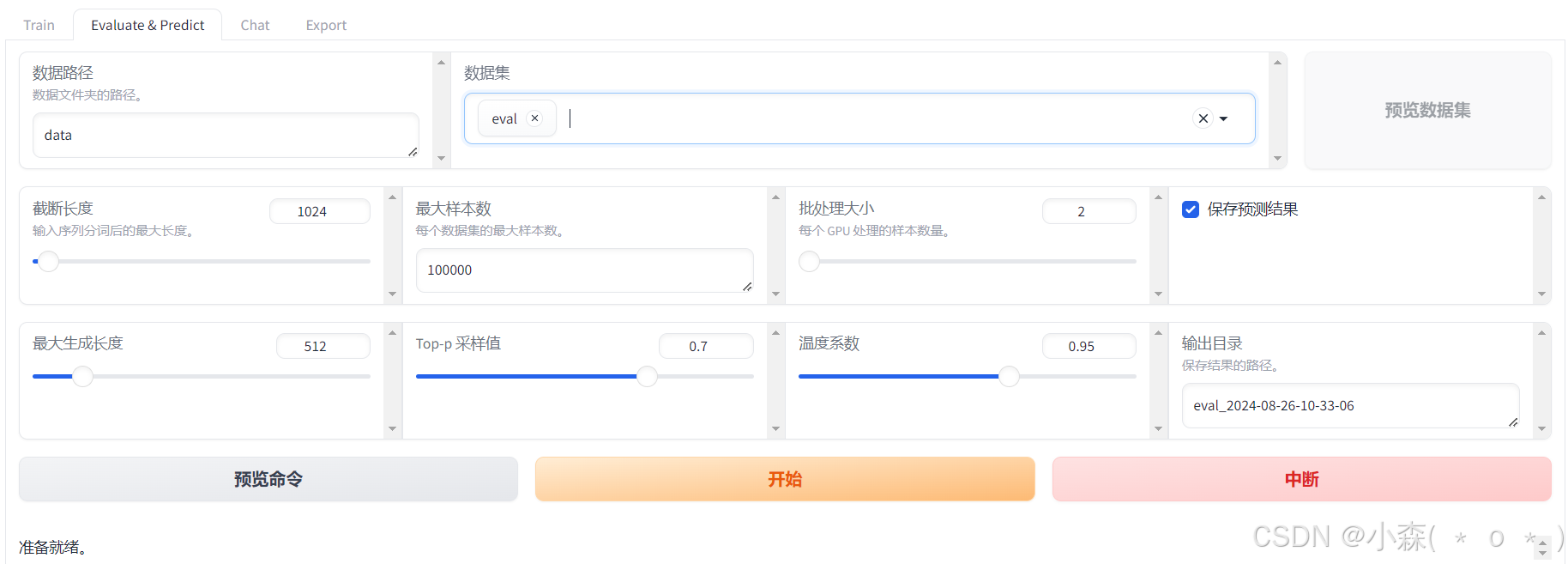
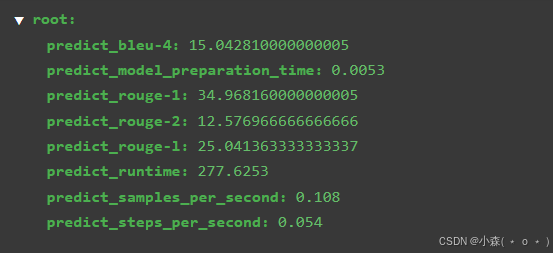
点击开始然后开始评估模型,大概三分钟,这里跳过。。。
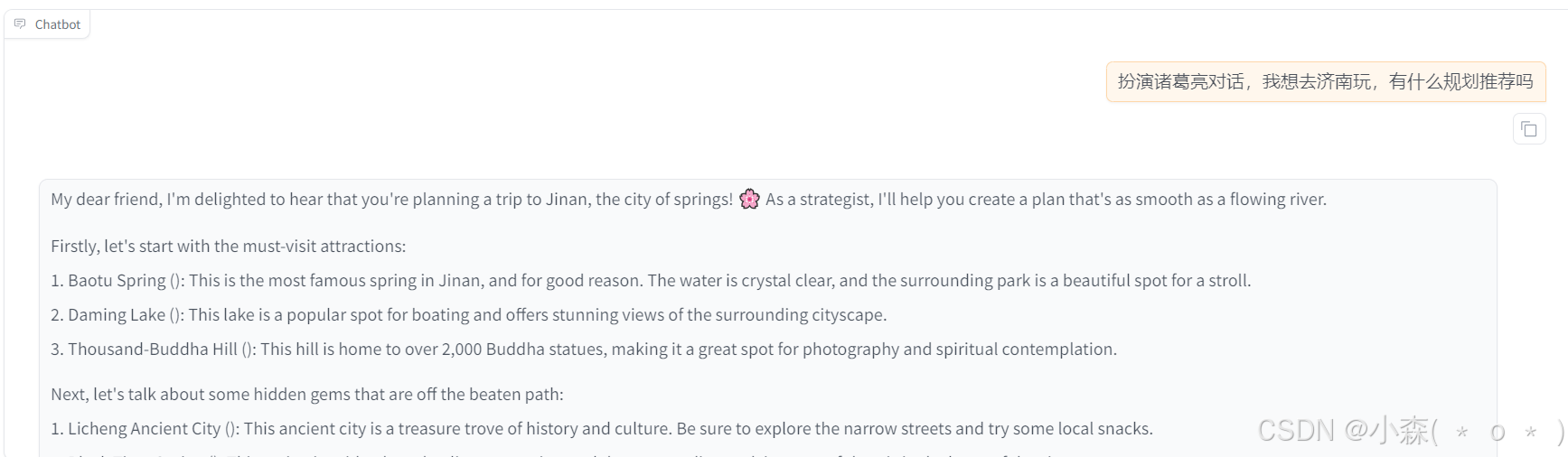
选择「Chat」栏,确保适配器路径是train_llama3,点击「加载模型」即可在Web UI中和微调模型进行对话。
模型微调之前的对话:
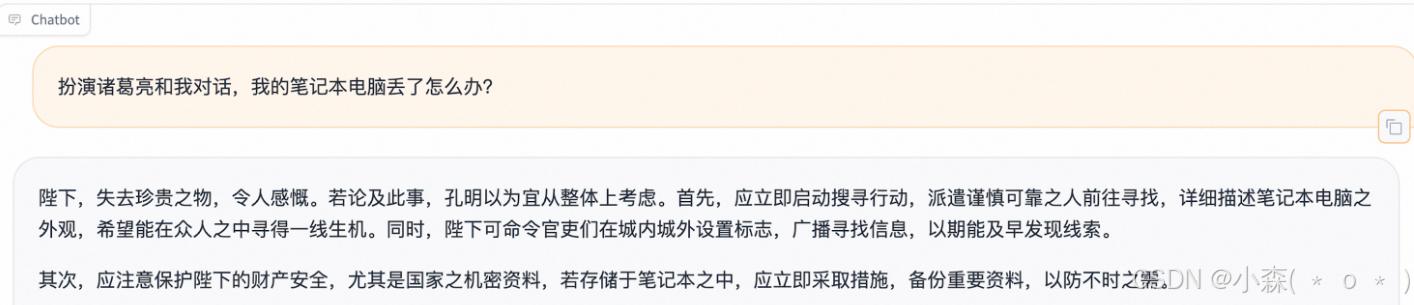
微调之后:
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献643条内容
已为社区贡献643条内容

所有评论(0)