DeepSeek-OCR 2:视觉因果流
26年1月来自DeepSeek AI的论文“DeepSeek-OCR 2: Visual Causal Flow”。DeepSeek-OCR 2,旨在研究一种改进编码器——DeepEncoder V2——的可行性。该编码器能够根据图像语义动态地重新排列视觉tokens。传统的视觉-语言模型(VLM)在输入到大语言模型(LLM)时,总是以固定的位置编码,按照僵化的光栅扫描顺序(从左上到右下)处理视觉
26年1月来自DeepSeek AI的论文“DeepSeek-OCR 2: Visual Causal Flow”。
DeepSeek-OCR 2,旨在研究一种改进编码器——DeepEncoder V2——的可行性。该编码器能够根据图像语义动态地重新排列视觉tokens。传统的视觉-语言模型(VLM)在输入到大语言模型(LLM)时,总是以固定的位置编码,按照僵化的光栅扫描顺序(从左上到右下)处理视觉token。然而,这与人类视觉感知相悖。人类视觉感知遵循灵活但语义连贯的扫描模式,这种模式由其固有的逻辑结构驱动。尤其对于布局复杂的图像,人类视觉会表现出基于因果关系的顺序处理能力。受此认知机制的启发,DeepEncoder V2 的设计旨在赋予编码器因果推理能力,使其能够在基于 LLM 的内容解释之前智能地重新排列视觉token。这项工作探索一种新的范式:能否通过两个级联的一维因果推理结构有效地实现二维图像理解,从而提供一种新的架构方法,有可能实现真正的二维推理。
人类视觉系统与基于Transformer的视觉编码器[14, 16]非常相似:中央凹注视点作为视觉token,局部清晰且具有全局感知能力。然而,与现有编码器从左上到右下刚性扫描token不同,人类视觉遵循由语义理解引导的因果驱动流程。以追踪螺旋为例——眼球运动遵循内在逻辑,其中每一次后续注视都因果依赖于之前的注视。类似地,模型中的视觉token也应该根据视觉语义而非空间坐标进行选择性处理。
这一洞见从根本上重新思考视觉-语言模型(VLM)的架构设计,特别是编码器组件。LLM本质上是基于一维序列数据进行训练的,而图像是二维结构。直接按照预定义的栅格扫描顺序展平图像块会引入不必要的归纳偏差,忽略语义关系。为了解决这个问题,提出 DeepSeek-OCR 2,并采用一种编码器设计——DeepEncoder V2——以期实现更接近人类视觉的编码。与 DeepSeek-OCR [54] 类似,选择文档阅读作为主要实验平台。文档具有丰富的挑战性,包括复杂的布局顺序、复杂的公式和表格。这些结构化元素本身就蕴含着因果视觉逻辑,需要强大的推理能力,这使得文档 OCR 成为验证方法的理想平台。
如图所示,用紧凑的 LLM [48] 架构替换 DeepEncoder [54] 中的 CLIP [37] 组件,以实现视觉因果流。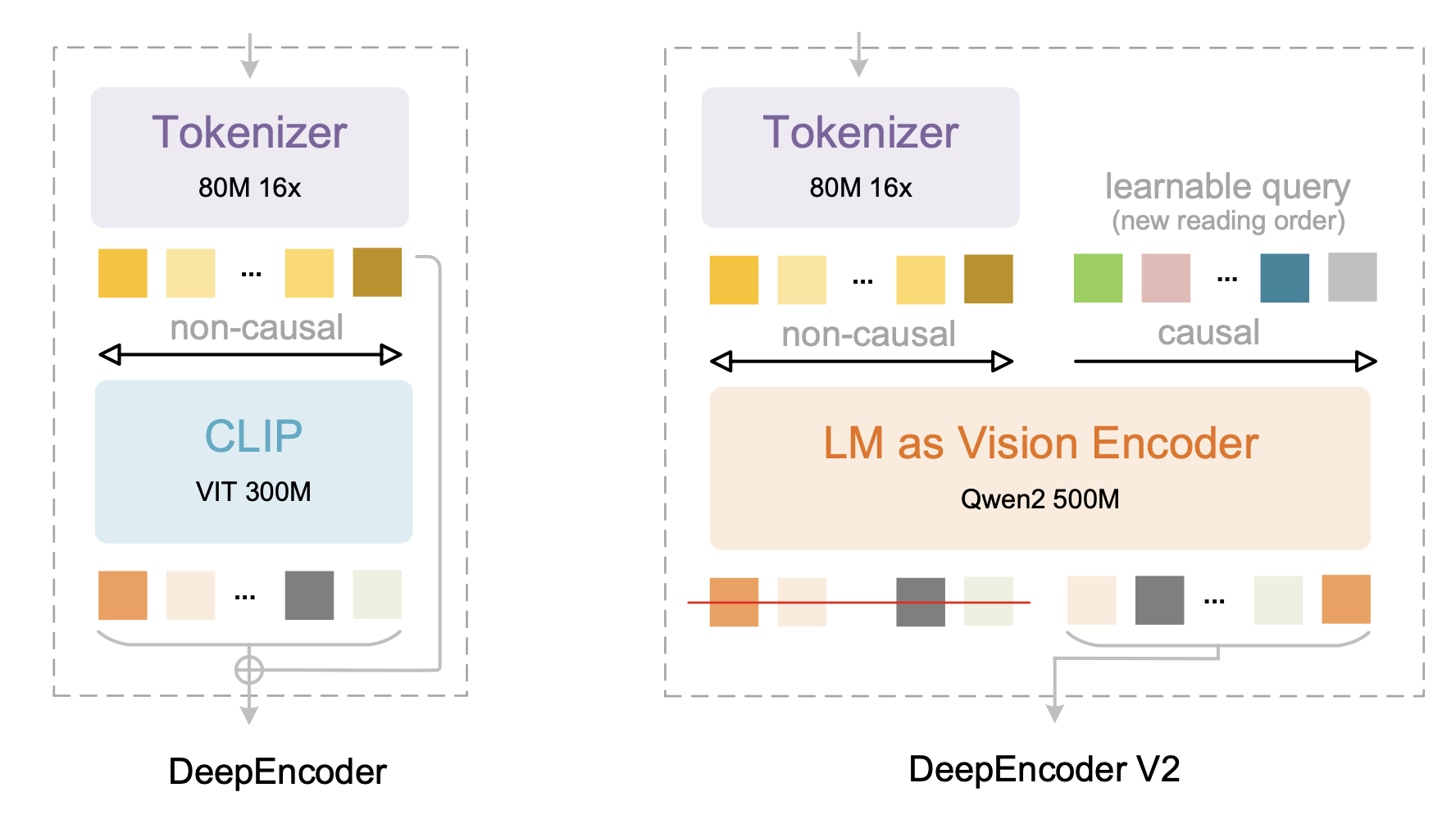
为了实现并行处理,引入可学习查询 [10],称为因果流token,其前面添加视觉token作为前缀——通过定制的注意掩码,视觉token保持全局感受野,而因果流token可以获得视觉token的重排序能力。保持因果token和视觉token之间的基数相等(通过填充和边界等冗余),以提供足够的容量进行重新注视。只有因果流token(编码器输出的后半部分)被送入 LLM [24] 解码器,从而实现级联因果感知视觉理解。
如图所示两种采用并行查询的计算机视觉模型:1)DETR 的解码器 [10] 用于目标检测,2)BLIP2 的 Q-former [22] 用于视觉token压缩。两者都采用查询间的双向自注意机制。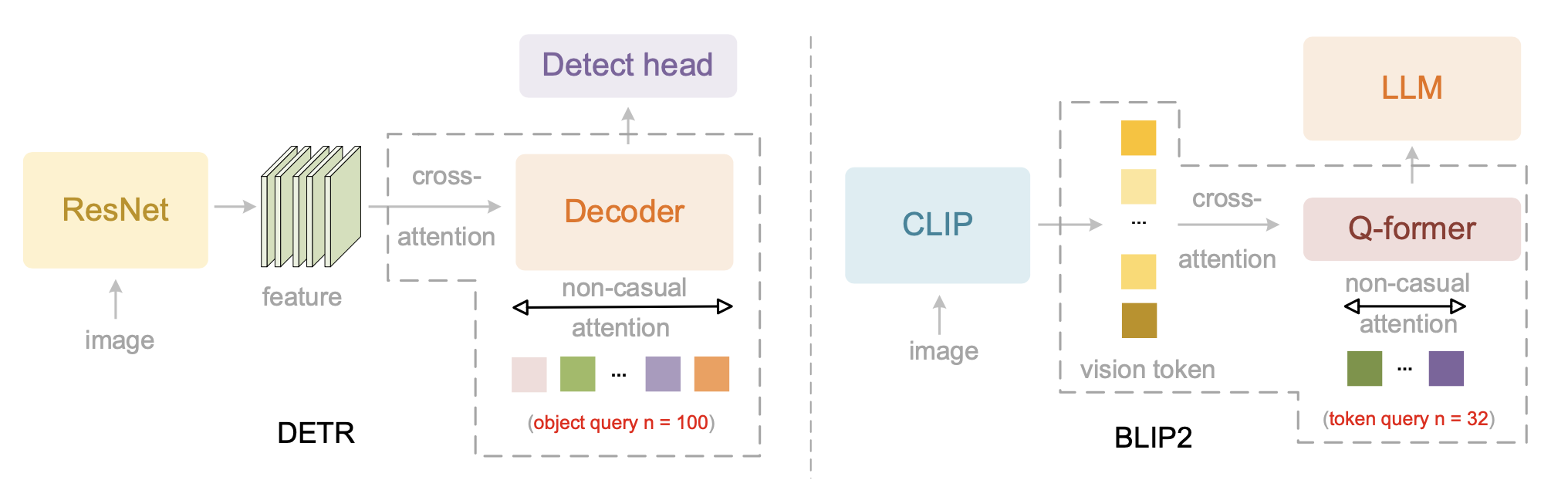
架构
DeepSeek-OCR 2 继承 DeepSeek-OCR 的整体架构,该架构由编码器和解码器组成,如图所示。编码器将图像离散化为视觉tokens,而解码器则根据这些视觉tokens和文本提示生成输出。关键区别在于编码器:将 Deep-Encoder 升级为 DeepEncoder V2,它保留前代的所有功能,并通过一种全新的架构设计引入因果推理。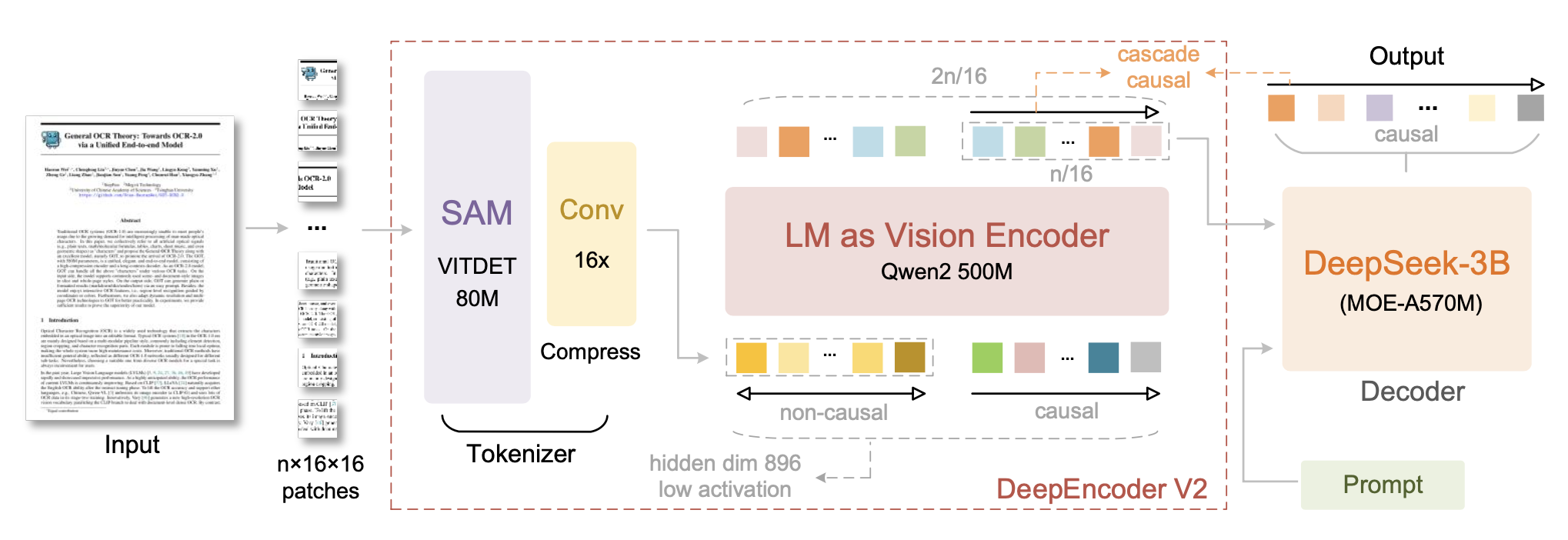
DeepEncoder V2
原始编码器是一个重要的组件,它通过注意机制提取和压缩图像特征。在这个机制中,每个token都会关注其他所有token,从而实现类似于人类中央凹和周边视觉的全图像感受野。然而,将二维图像块展平为一维序列会通过面向文本的位置编码(例如 RoPE [42])引入一种僵化的排序偏差。这与自然的视觉阅读模式相悖,尤其是在光学文本、表单和表格等非线性布局中。
视觉token化器
DeepEncoder V2 的第一个组件是视觉token化器。与 DeepEncoder 类似,采用一种架构结合一个 8000 万参数的 SAM 基模型 [21] 和两个卷积层 [50]。为了与后续流程保持一致,将最后一个卷积层的输出维度从 Deep-Encoder 中的 1024 降低到 896。需要注意的是,这种基于压缩的token化器并非必需,可以用简单的块嵌入来替代。保留它是因为它可以通过窗口注意机制以最少的参数实现 16 倍的token压缩 [19, 46, 51, 52],从而显著降低后续全局注意模块的计算成本和激活内存。此外,它的参数数量(8000 万)与 LLM 中用于文本输入嵌入的典型 1 亿参数相当。
DeepEncoder V2 中的 Token 数目的计算如图所示。DeepEncoder V2 使用多重裁剪策略,每个图像输出 256 到 1120 个 tokens,局部视图数量为 0 到 6 个。当局部视图数量为 0 时,仅全局视图产生 256 个 tokens;当局部视图数量为 6 时,Token 数量达到 1120 (6×144+256)。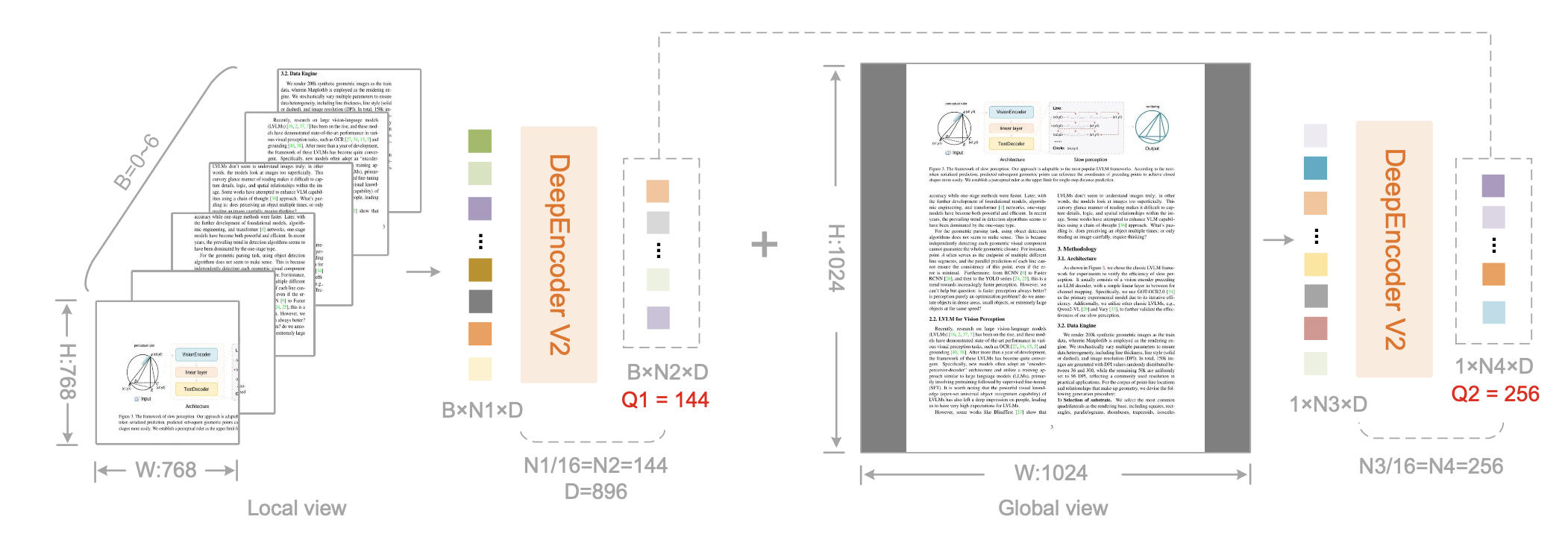
语言模型作为视觉编码器
在 DeepEncoder 中,CLIP ViT 紧随视觉token化器之后,用于压缩视觉知识。DeepEncoder V2 将此组件重新设计为具有双流注意机制的 LLM 式架构。视觉token利用双向注意来保持 CLIP 的全局建模能力,而新引入的因果流查询则采用因果注意。这些可学习的查询作为后缀附加在视觉token之后,每个查询都关注所有视觉token及其前面的查询。通过保持查询和视觉token之间的基数相等,这种设计在不改变token数量的情况下,对视觉特征施加语义排序和提炼。最后,只有因果查询的输出被送入 LLM 解码器。
用 Qwen2-0.5B [48] 实例化此架构,其 5 亿个参数与 CLIP ViT(3 亿个参数)相当,且不会引入过多的计算开销。仅解码器架构采用视觉token的前缀连接方式,其效果至关重要:在类似 mBART [30] 的编码器-解码器结构中,使用交叉注意机制进行的额外实验未能收敛。这种失败源于视觉token在独立编码器中隔离时交互不足。相比之下,前缀连接设计使视觉token在所有层级中保持活跃,从而促进与因果查询的有效视觉信息交换。
该架构实际上建立两阶段级联因果推理:编码器通过可学习的查询对视觉token进行语义重排序,而 LLM 解码器则对排序后的序列执行自回归推理。与通过位置编码强制执行严格空间顺序的传统编码器不同,我们基于因果顺序的查询能够适应平滑的视觉语义,同时自然地与 LLM 的单向注意力模式保持一致。这种设计有望弥合二维空间结构和一维因果语言建模之间的鸿沟。
因果流查询
因果查询token的数量等于视觉token的数量,计算公式为 𝑊×𝐻/16^2×16,其中 𝑊 和 𝐻 分别表示编码器输入图像的宽度和高度。为了避免为不同分辨率维护多个查询集,采用一种多裁剪策略,在预定义的分辨率下使用固定的查询配置。
具体来说,全局视图使用 1024 × 1024 的分辨率,对应于 256 个查询嵌入,记为 query_global。局部裁剪采用 768 × 768 的分辨率,裁剪次数 𝑘 的范围为 0 到 6(当图像的两个尺寸均小于 768 时,不进行裁剪)。所有局部视图共享一个统一的 144 个查询嵌入集,记为 query_local。因此,输入到 LLM 的重排序视觉token总数为 𝑘 × 144 + 256,范围为 [256, 1120]。此最大token数 (1120) 低于 DeepSeek-OCR 的 1156(高达模式),并且与 Gemini-3-Pro 的最大视觉token预算相匹配。
注意掩码
为了更好地展示 DeepEncoder V2 的注意机制,如图可视化注意掩码。该注意掩码由两个不同的区域组成。左侧区域对原始视觉token应用双向注意(类似于 ViT),从而实现token间的完全可见性。右侧区域对因果流token采用因果注意(三角掩码,与仅解码器的 LLM 相同),其中每个token仅关注其前面的token。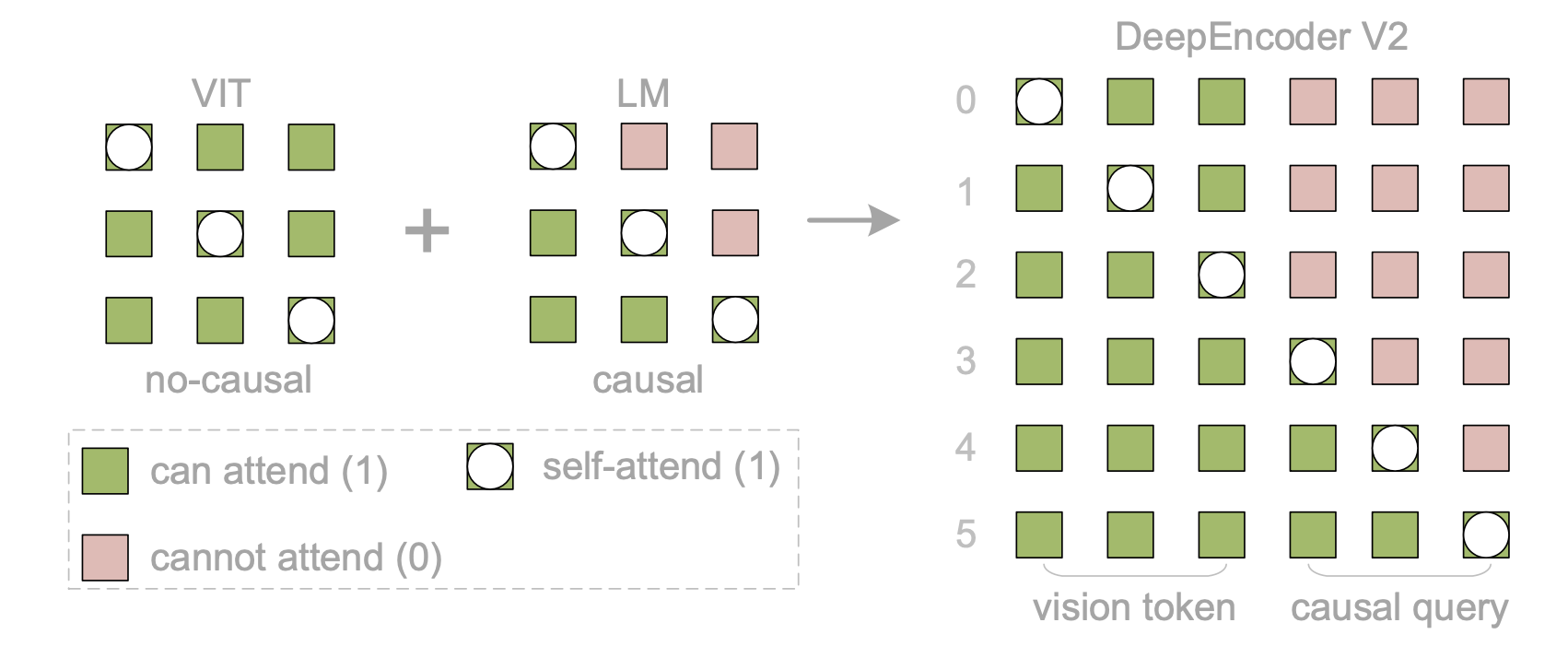
这两个组件沿序列维度连接起来,构建 DeepEncoder V2 的注意掩码 (M),如下所示: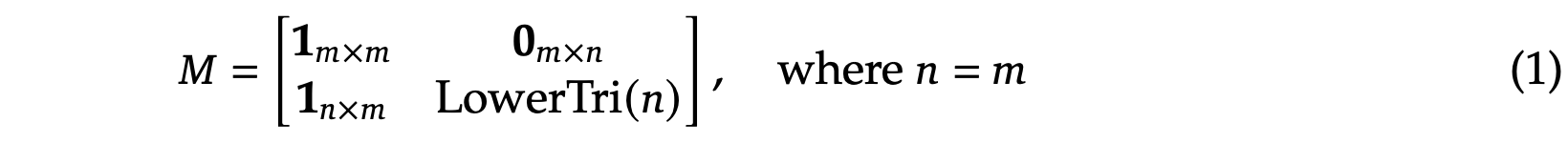
其中 𝑛 表示因果查询token的数量,𝑚 表示原始视觉token的数量,LowerTri 表示一个下三角矩阵(对角线及其下方元素为 1,上方元素为 0)。
DeepSeek-MoE 解码器
由于 DeepSeek-OCR 2 主要侧重于编码器的改进,因此没有升级解码器组件。遵循这一原则,保留 DeepSeek-OCR 的解码器——一个具有约 5 亿个有效参数的 3B 参数 MoE 结构。DeepSeek-OCR 2 的核心前向传播过程可以表述为: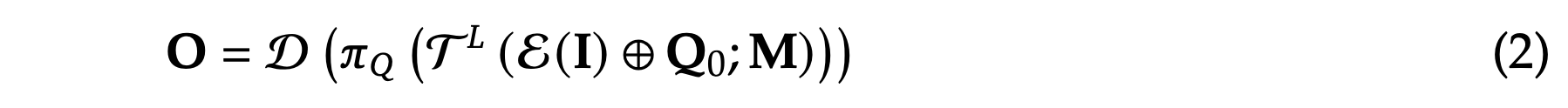
其中 I 是输入图像,E 是视觉token化器,将图像映射到 𝑚 个视觉tokens V,Q_0 是可学习的因果查询嵌入,⊕ 表示序列连接,T𝐿 表示带有掩码注意的 𝐿 层 Transformer,M ∈ {0, 1} 是公式(1)中定义的块因果注意掩码,𝜋_𝑄 是投影算子,用于提取最后 𝑛 个 tokens(即 Z = X_𝑚+1:𝑚+𝑛),D 是语言解码器,O 是 LLM 词汇表的输出 logits。
数据引擎
DeepSeek-OCR 2 采用与 DeepSeek-OCR 相同的数据源,包括 OCR 1.0、OCR 2.0 [11, 27, 53] 和通用视觉数据 [54],其中 OCR 数据占训练混合模型的 80%。还引入两项改进:(1) 对 OCR 1.0 数据采用更均衡的采样策略,按内容类型(文本、公式、表格)以 3:1:1 的比例划分页面;(2) 通过合并语义相似的类别(例如,统一“图注”和“图标题”)来改进布局检测的标签。鉴于这些细微的差异,DeepSeek-OCR 是一个有效的基准模型。
训练流程
将 DeepSeek-OCR 2 的训练分为三个阶段:(1) 编码器预训练;(2) 查询增强;(3) 解码器特化。第一阶段使视觉token化器和LLM式编码器具备特征提取、token压缩和token重排序的基本能力。第二阶段进一步增强编码器的token重排序能力,同时提高视觉知识压缩率。第三阶段固定编码器参数,仅优化解码器,从而在相同浮点运算次数下实现更高的数据吞吐量。
训练 DeepEncoder V2
参照 DeepSeek-OCR 和 Vary [50] 的方法,用语言建模目标训练 DeepEncoder V2,并将编码器与轻量级解码器 [20] 相结合,通过下一个token预测进行联合优化。用两个数据加载器,分辨率分别为 768×768 和 1024×1024。视觉token化器由 DeepEncoder 初始化,而类 LLM 编码器则来自 Qwen2-0.5B-base [48]。预训练后,仅保留编码器参数用于后续阶段。用 AdamW [32] 优化器,学习率采用余弦衰减,从 1e-4 衰减到 1e-6,在 160 个 A100 GPU(20 个节点 × 8 个 GPU)上进行训练,批大小为 640,迭代次数为 4 万次(序列打包长度为 8K,约 1 亿个图像-文本对样本)。
查询增强
在 DeepEncoder V2 预训练之后,将其与 DeepSeek-3B-A500M [24, 25] 集成,作为最终的流水线。冻结视觉token化器(SAM-conv 结构),同时联合优化 LLM 编码器和 LLM 解码器以增强查询表示。在此阶段,通过多裁剪策略将两种分辨率的数据统一到一个数据加载器中。采用四阶段流水线并行化:视觉token化器 (PP0)、LLM 风格的编码器 (PP1) 和 DeepSeek-LLM 层(PP2-3 阶段每阶段 6 层)。使用 160 个 GPU(每个 GPU 40GB 内存),配置 40 个数据并行副本(每个副本 4 个 GPU),并使用相同的优化器和学习率从 5e-5 衰减到 1e-6 的 15k 次迭代进行训练,全局批大小为 1280。
持续-训练 LLM
为了快速消耗训练数据,在此阶段冻结所有 DeepEncoder V2 参数,仅更新 DeepSeek-LLM 参数。此阶段加速了训练(在相同的全局批大小下,训练速度提升超过一倍),同时帮助 LLM 更好地理解 DeepEncoder V2 的重排序视觉tokens。在此阶段,延续第二阶段,将学习率从 1e-6 衰减至 5e-8,并进行 2 万次迭代的训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)