SePer: 用语义困惑度评估检索/RAG效用的一种可操作框架(ICLR 2025 Spotlight)
本文介绍ICLR 2025论文《SePer》,提出用语义困惑度(SePer)评估检索增强生成(RAG)中检索对答案的实际效用。该方法通过对比检索前后语义簇分布的不确定性变化,比传统相关性指标更准确反映检索对答案生成的实质性帮助。实验显示SePer与检索效用的相关性(平均0.778)显著优于ROUGE-L/NDCG等基线,且采样10次即可稳定。研究发现无关检索会对大模型产生显著负面影响,SePer可
SePer: 用语义困惑度评估检索效用的一种可操作框架(ICLR 2025)
1. 我关心的问题:RAG 里“检索相关”不等于“对答案有用”
这篇工作最有价值的地方,不是再做一个相关性指标,而是把评估对象从“文档与问题是否相关”转成“检索是否实质性降低了模型对正确语义答案的不确定性”。
在实际系统里,这个区分很关键:
- 检索文档可能语义相关,但不一定支持最终答案。
- 检索文档甚至可能引入干扰,让模型更不稳定。
- 传统 IR 指标(如 NDCG)和生成指标(如 ROUGE/BLEU)通常不能直接刻画“检索带来的答案级增益”。
SePer(Semantic Perplexity)提出了一个可计算的中间层:先把多次采样得到的答案映射到“语义簇”,再在簇分布上度量不确定性变化。
2. 方法框架:从 token 概率转到语义概率
论文的流程可以概括为四步:
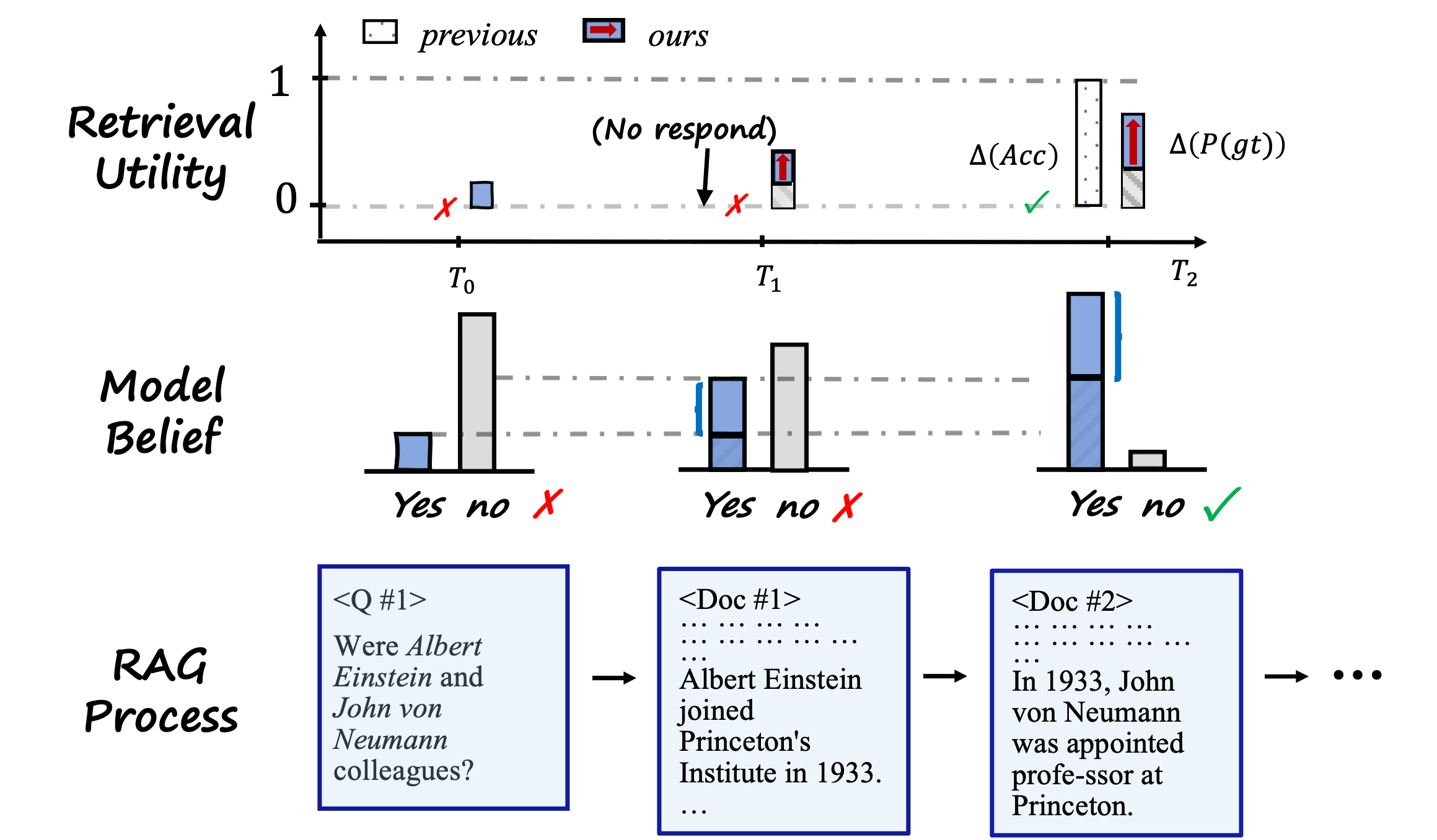
- 在“无检索”和“有检索”两种条件下,对同一问题进行多次采样(文中实验常用
k=10)。 - 用蕴含关系(entailment)构建答案间语义关系矩阵。
- 用贪心聚类把语义等价/近等价答案归并为语义簇。
- 基于簇概率分布计算语义困惑度,并比较检索前后差值(即“语义困惑度降低量”)。
关键点在于:它不把不同表述的同义答案当成冲突样本,而是在语义层面做概率聚合。这比直接用字符串重叠更贴近 RAG 的真实行为。
3. 论文里最有信息量的实证结果
3.1 主结果:与检索真实效用的相关性更高
在 NQ / HotpotQA / SQuAD 上,ΔSePer_S 与检索效用的 Pearson 相关性分别为:
- NQ:
0.769 - HotpotQA:
0.660 - SQuAD:
0.905 - 平均:
0.778
作为对照,ROUGE-L 的平均相关性为 0.671,NDCG 为 0.578,PROMETHEUS2 为 0.621。这个差距说明 SePer 更接近“检索是否真的帮到了答案生成”。
3.2 采样稳定性:k=10 已经接近饱和
附录实验显示,当采样数从 10 增加到 20 时,整体性能变化小于 1%。
这对工程落地很重要,意味着不需要极端采样预算就能获得稳定信号。
3.3 模型规模与检索收益不是线性关系
论文用 Qwen2.5 系列(1.5B 到 72B)做了对比。一个值得重视的现象是:
- 高质量检索通常提升 EM。
- 低质量/无关检索会显著拉低 EM。
- 在大模型(如 72B)上,无关检索仍然有可观负面影响(不是“小模型特有问题”)。
这条观察直接对应实际系统中的检索风控问题:
“检索失败”不是中性事件,而可能是显著负效用事件。
4. 这篇文章给我的可用结论
4.1 把“检索评估”改成“检索增益评估”
如果目标是提升最终答案质量,评估指标应优先刻画增益而不是相关性。SePer 的价值在于提供了一个可离线计算的近似增益信号。
4.2 在 RAG pipeline 里新增负效用告警
论文附录给了典型负例:检索到“语义相关但问题不对焦”的材料后,模型被误导,ΔSePer 变负,答案准确率下降。
这类信号可直接用于:
- 检索结果重排与拒答阈值;
- 动态决定“是否使用检索上下文”;
- 回归测试中的故障定位(检索器退化 vs 生成器退化)。
4.3 可作为 A/B 的统一离线指标
在 reranker、query rewrite、chunk 策略、索引更新等实验中,SePer 可以作为统一比较维度,减少只看单一 EM/F1 带来的误判。
5. 局限与我认为需要继续验证的点
论文也明确了限制:
- 语义聚类依赖蕴含判断质量,NLI 误判会向下游传播。
- 多跳推理下,语义等价关系可能比事实核验更难建模。
- 指标虽与人工/GPT-4 判分更一致,但并不等价于最终在线业务指标。
因此更稳妥的落地方式是:
- 把 SePer 作为“检索效用层”指标,
- 与任务指标(EM/F1/人工评审)联合监控,
- 不把单一指标直接当作优化目标。
6. 可复现入口
- 项目主页: https://sepermetric.github.io/
- OpenReview: https://openreview.net/forum?id=ixMBnOhFGd
- arXiv: https://arxiv.org/abs/2503.01478
- 代码: https://github.com/sepermetric/seper
7. 参考数据(摘自论文)
- 相关性主表(Pearson)显示
ΔSePer_S在三个数据集上总体领先基线。 - 采样消融显示
k=10到k=20的增益很小(<1%)。 - 模型规模实验显示无关检索带来的负效用在大模型上依然存在。
注:本文只复述论文中可核对的实验结论,不延伸到未经实验支持的工程承诺。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)