智能体设计模式 第四章:反思
反思模式为智能体的工作流程提供了自我修正的关键手段,使其能通过多次迭代而不是一次性完成任务来持续改进。具体做法是形成一个循环:系统先生成初稿,然后按照既定标准对其进行评估,最后根据评估结果生成更完善的输出。这种评估既可以由智能体自己完成(自我反思),也可以由一个专门的评论者智能体来执行。通常后一种方式更有效,也是该模式的一个重要架构决策。
智能体设计模式 第四章:反思
智能体设计模式 第四章:反思
反思模式概述
在前面的章节中,我们探讨了智能体的基础模式:用于顺序执行的提示链(Prompt Chaining)、用于动态路径选择的路由(Routing),以及用于并发任务执行的并行模式(Parallelization)。这些模式使智能体能够更高效、更灵活地执行复杂任务。然而,即使工作流设计再精妙,智能体初始输出或计划也未必最优、准确或完整。这正是反思(Reflection)模式发挥作用之处。
反思模式是指智能体评估自己的工作、输出和内部状态,并利用评估结果改进性能和优化响应。这是一种自我纠正或自我改进的形式。通过这种形式,智能体可以根据反馈、内部剖析及与期望标准的比较,来不断地优化输出、调整方法。反思有时也可由独立的智能体来承担,其职责是专门分析初始智能体的输出。
反思模式与简单顺序链或路由模式有着本质区别。前者只是将输出直接传给下一步,或是在不同路径中做出选择;而反思模式则引入了反馈循环。在这种模式下,智能体并非简单地产出结果就结束了。它会回过头来审视自己的输出(或其生成过程),找出潜在的问题和改进空间,并依据这些洞察生成更优的版本,或是修正其后续的行动策略。
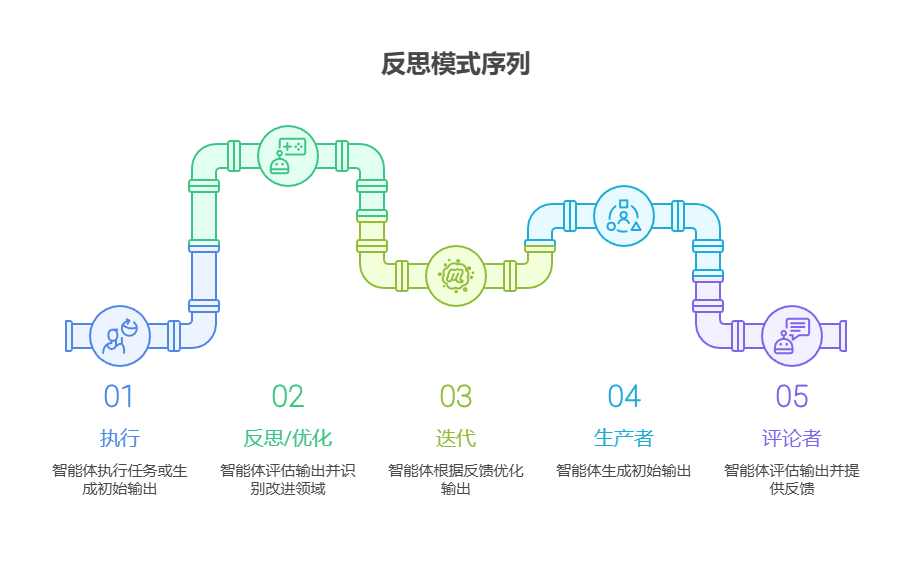
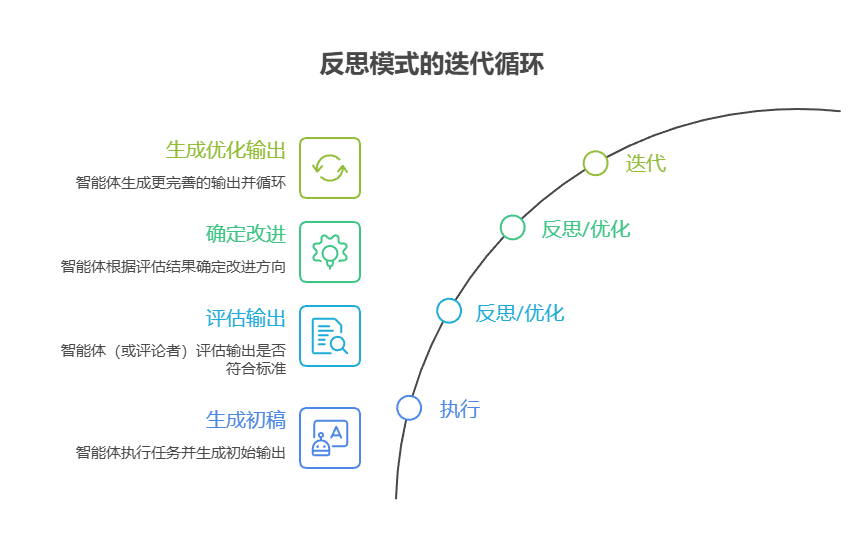
这个过程通常包括以下步骤:
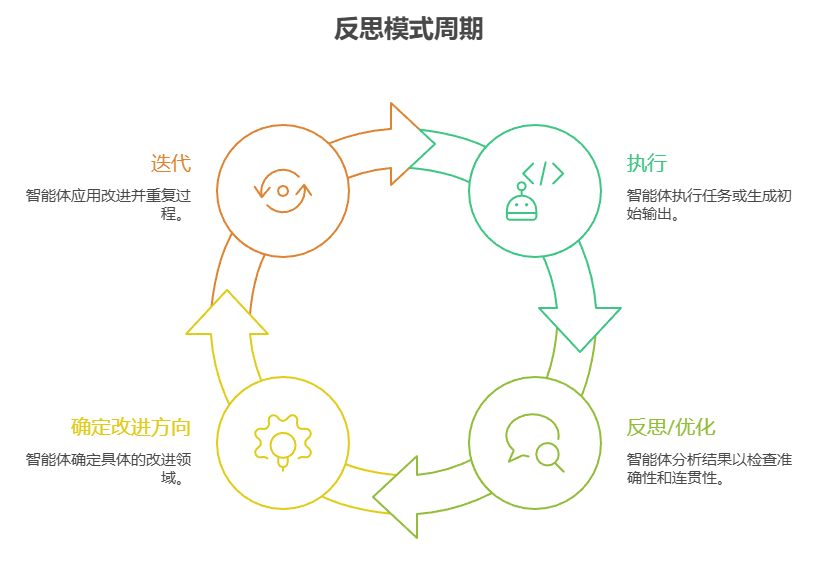
- 执行:智能体执行任务或生成初始版本的输出。
- 反思/优化 :智能体(通常借助另一个大语言模型调用或一组规则)对上一步的结果进行分析。该过程旨在检查其事实准确性、内容连贯性、风格、完整度、是否遵循指令以及其他相关标准。
- 反思/优化:根据上一轮的剖析结果,智能体将确定具体的改进方向。这可能涉及几个方面:生成一个更为精炼的输出、为后续步骤调整参数,甚至是修正整体计划。
- 迭代(可选,但很常见):随后,智能体便会将优化后的输出或调整过的方法付诸执行,并循环往复地进行整个反思过程,直到最终结果令人满意,或满足了预设的停止条件。
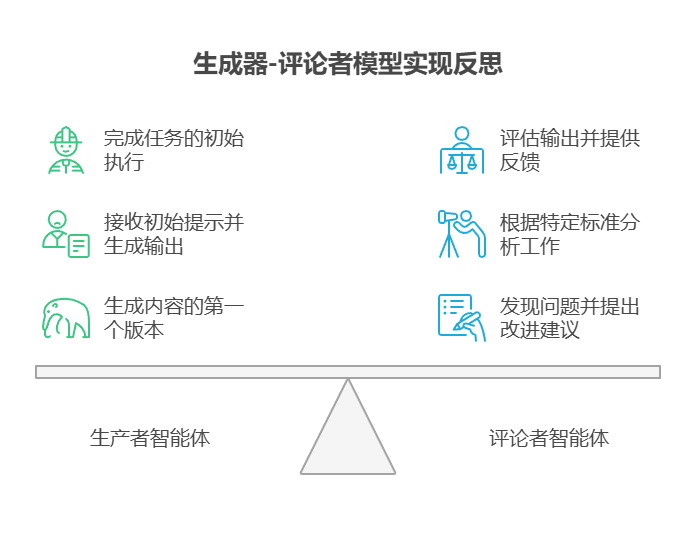
反思模式的一个关键且高效的实现方式,是将流程拆分为两个独立的逻辑角色:生产者(Producer)和评论者(Critic)。这通常被称为「生成器 - 评论者」(Generator-Critic)或「生产者 - 审查者」(Producer-Reviewer)模型。虽然单个智能体也能进行自我反思,但使用两个专用的智能体(或两个具有不同系统提示的独立大语言模型调用)通常能产出更稳健、更客观的结果。
- 生产者智能体:主要职责是完成任务的初始执行。它完全专注于生成内容,无论是编写代码、起草博客文章还是制定计划。它会接收初始提示,并据此生成输出的第一个版本。
- 评论者智能体:该智能体的唯一使命就是评估由生产者生成的输出。它会被赋予一套不同的指令,通常还包含一个独特的角色设定(例如「你是一位高级软件工程师」、「你是一位严谨的事实核查员」)。评论者的指令引导它根据特定标准分析生产者的工作,如事实准确性、代码质量、风格要求和完整性,旨在发现问题、提出改进建议并给出结构化的反馈。
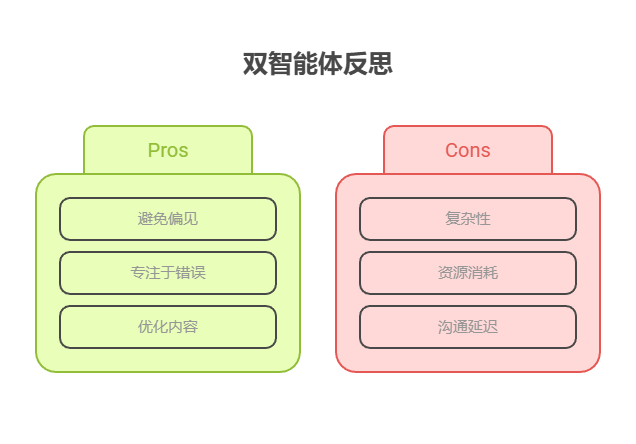
这种职责分离非常有效,因为它避免了智能体自我审查时产生的认知偏见。评论者智能体以全新视角审视输出,完全专注于发现错误和改进空间。它的反馈意见随后传回给生产者智能体,生产者据此对内容进行修改和优化。实战部分 LangChain 和 ADK 代码示例都采用了这种双智能体模型:LangChain 使用特定的 reflector_prompt 创建评论者角色,而 ADK 示例明确区分了生产者和审查者两个智能体。
实现反思模式通常需要构建包含反馈循环的智能体工作流。这可以通过在编码实现迭代循环,或使用支持状态管理和根据评估结果进行条件跳转的框架来完成。虽然单步评估和优化可以在 LangChain/LangGraph、ADK 或 Crew.AI 链中实现,但真正的迭代反思通常需要更复杂的编排。
反思模式对于构建能产出高质量结果、应对复杂任务并展现自我意识与适应能力的智能体非常重要。它让智能体不再只是执行指令,而是发展出更成熟的推理与内容生成能力。
需要特别注意反思模式与目标设定和监控(见第 11 章)的联系。目标为智能体的自我评估提供最终基准,监控则跟踪其进度。在许多实际情形中,反思会充当纠偏机制:利用监控反馈分析偏离之处并据此调整策略。这样的协同作用使智能体从单纯执行者变成有目的的、自主适应以实现目标的系统。
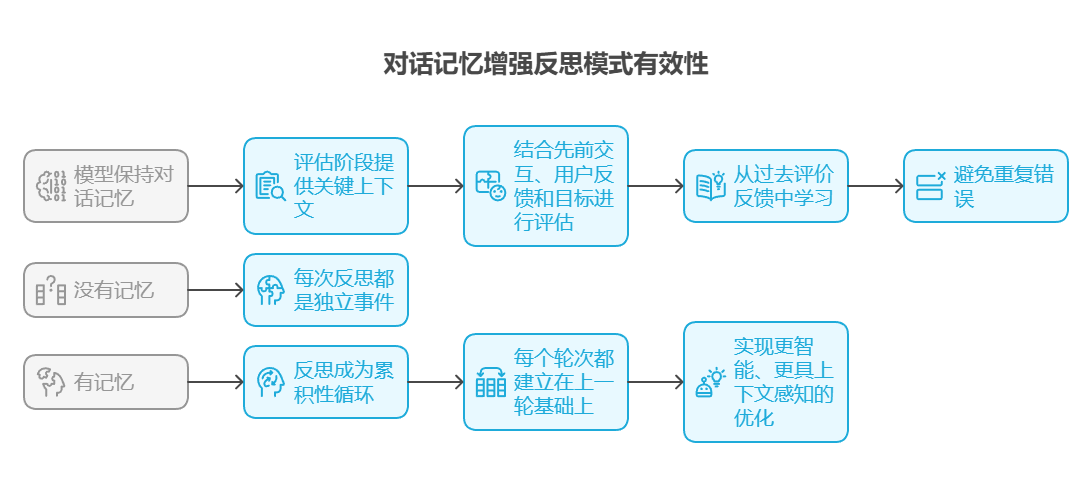
此外,当模型能保持对话记忆时,反思模式的有效性显著增强(见第 8 章)。对话历史为评估阶段提供关键上下文,使智能体不仅能孤立评估输出,还能结合先前交互、用户反馈和不断演变的目标进行评估。这使智能体能从过去的评价反馈中学习并避免重复错误。没有记忆,每次反思都是独立事件;有了记忆,反思成为累积性的循环,每个轮次都建立在上一轮基础上,从而实现更智能、更具上下文感知的优化。
实际应用场景
当输出质量、准确性或对复杂约束的遵从性至关重要时,反思模式非常有用:
- 创意写作和内容生成:
对生成的文本、故事、诗歌或营销文案进行润色和改进。
- 用例:撰写博客文章的智能体。
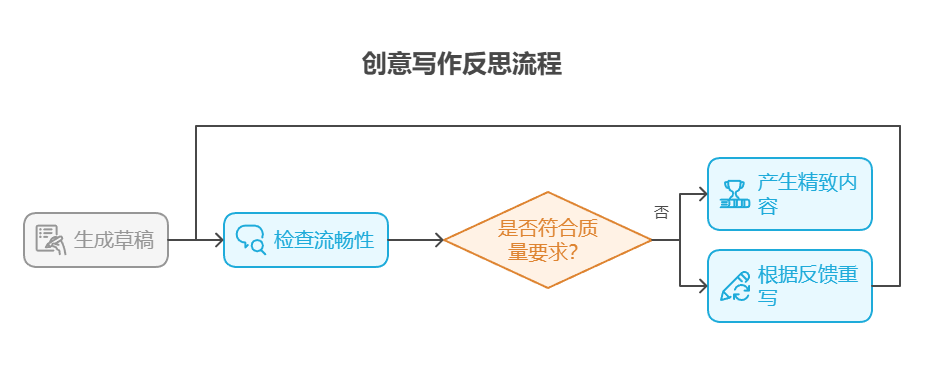
- 反思:先写一篇草稿,再从流畅性、语气和表达清晰度等方面进行检查,随后根据反馈重写草稿。反复进行,直到文章符合质量要求。
- 好处:产生更精致、更有效的内容。
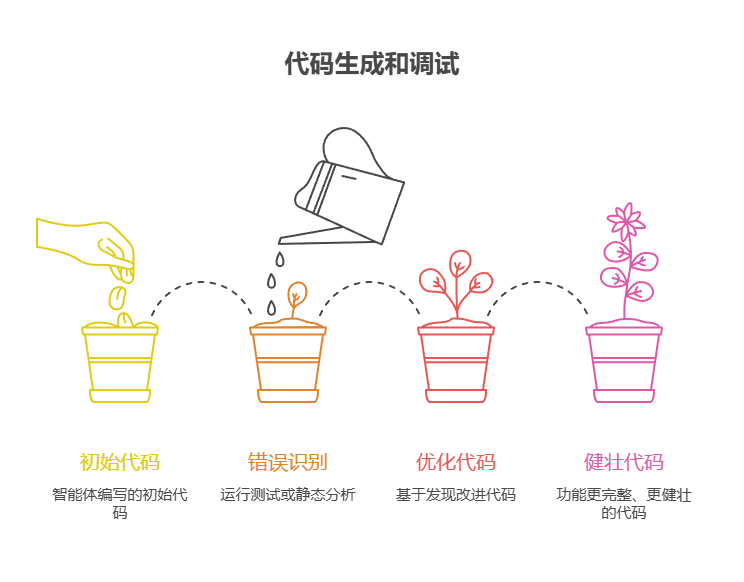
- 代码生成和调试:
编写代码、识别错误并修复它们。
-
用例:编写 Python 函数的智能体。
-
反思:编写初始代码,运行测试或静态分析,识别错误或低效之处,然后基于这些发现优化代码。
-
好处:生成更健壮、功能更完整的代码。
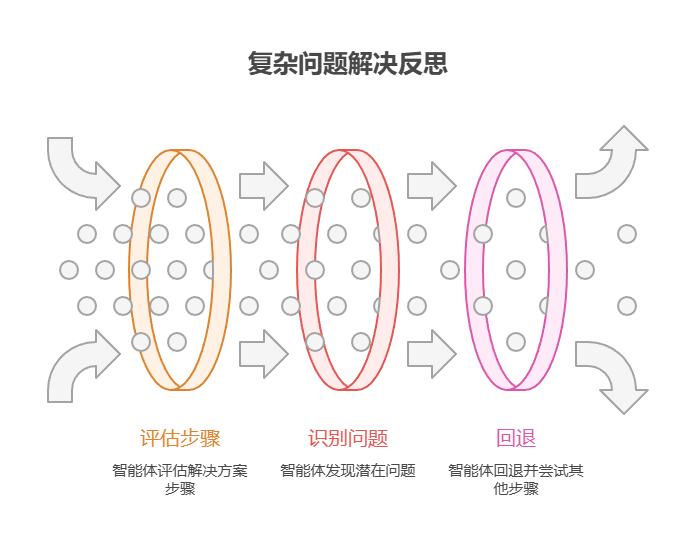
- 复杂问题解决:
在多步推理任务中,对中间步骤或所提出的解决方案进行评估和审查。
- 用例:解决逻辑推理类谜题的智能体。
- 反思:提出一个行动步骤,评估该步骤是否有助于推进问题的解决或引入矛盾;如发现问题,则回退并尝试其他步骤。
- 好处:增强智能体在复杂问题情境中分析和解决问题的能力。
- 摘要和信息综合:
评估所提计划,找出存在的问题并提出改进建议。
- 用例:规划一系列行动以实现特定目标的智能体。
- 反思:制定计划,模拟执行或根据限制评估可行性,然后根据评估结果对计划进行改进与调整。
- 好处:制定更有效、更符合实际的计划。

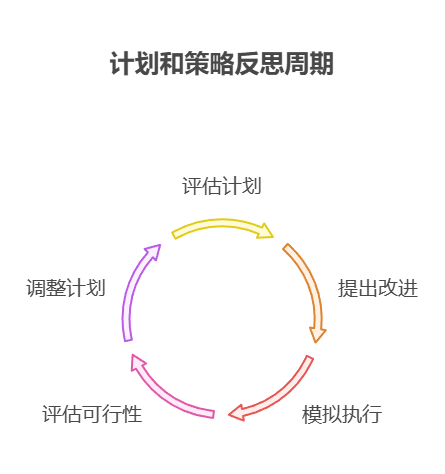
- 规划和策略:
评估所提计划,找出存在的问题并提出改进建议。
-
用例:规划一系列行动以实现特定目标的智能体。
-
反思:制定计划,模拟执行或根据限制评估可行性,然后根据评估结果对计划进行改进与调整。
-
好处:制定更有效、更符合实际的计划。
- 对话智能体:
回顾对话中的前几轮交流,以保持上下文连贯、纠正误会并提升回答的质量。
-
用例:客户支持聊天机器人。
-
反思:在用户回复后,回顾整个对话和上一次生成的内容,确认信息前后连贯并针对用户的最新输入做出准确回应。
-
好处:实现更自然、更高效的沟通。
反思模式为智能体系统增加了一层元认知能力,使其能从自己处理过程和输出中学习,从而产生更智能、更可靠、更高质量的结果。
实战示例:使用 LangChain
要实现完整的迭代反思流程,需要具备状态管理和循环执行的机制。虽然诸如 LangGraph 这类基于图的框架,或自定义的过程式代码可以原生支持这些功能,但通过 LCEL(LangChain 表达式语言)的组合语法,就能清晰地演示反思模式的核心原理。
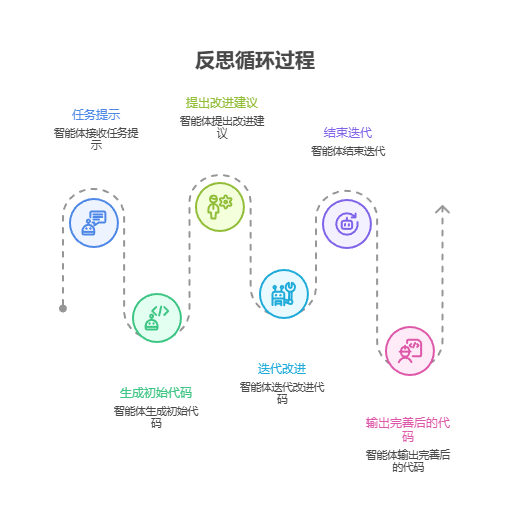
本示例使用 Langchain 库和 OpenAI 的 DeepSeek 模型实现反思循环,迭代生成并优化一个计算阶乘的 Python 函数。
流程从任务提示开始,生成初始代码,然后由扮演高级软件工程师角色的智能体提出改进建议并反复迭代,直到确定代码已无可改进或达到最大迭代次数时结束,最终输出完善后的代码。
首先确保已安装必要的库:
pip install langchain langchain-community langchain-openai
还需要为选择的语言模型(例如 OpenAI、Google Gemini、Qwen、DeepSeek)设置 API 密钥。
.env APYKEY 文件加载
# .env APYKEY 文件加载,这些代码都是jupyter 中执行的
import os
from dotenv import load_dotenv
load_dotenv() # 加载 .env 文件
api_key = os.getenv("GOOGLE_API_KEY")
print(api_key)
Qwen API 测试 代码
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.getenv("QWEN_API_KEY"),
base_url=os.getenv("QWEN_BASE_URL"),
)
resp = client.chat.completions.create(
model="qwen-omni-turbo", # 或其它模型名
messages=[
{"role": "user", "content": "你好"}
]
)
# 这里用属性,不要用下标
print(resp.choices[0].message.content)
运行输出:

DeepSeek LangChain_Openai 语言模型初始化
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI # 用 DeepSeek 时用这个而不是 Gemini
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableBranch
# ─────────────────────────────────────────────────
# 1. 载入 .env 环境变量
# ─────────────────────────────────────────────────
load_dotenv()
# ─────────────────────────────────────────────────
# 2. 初始化 DeepSeek 作为主路由 LLM
# - 使用 openai 兼容协议
# - 读取:
# DEEPSEEK_API_KEY=sk-xxxx
# DEEPSEEK_BASE_URL=https://api.deepseek.com/v1
# ─────────────────────────────────────────────────
try:
_ApiKey = os.getenv("DEEPSEEK_API_KEY")
_BaseUrl = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com/v1")
# ChatOpenAI 其实可以对接任意 OpenAI 格式的服务
llm = ChatOpenAI(
model="deepseek-chat", # DeepSeek 常用对话模型名
api_key=_ApiKey,
base_url=_BaseUrl,
temperature=0
)
print(f"[初始化] 语言模型已初始化: {llm.model_name}")
except Exception as e:
print(f"[初始化] 初始化语言模型时出现错误: {e}")
llm = None
LangGraph DeepSeek 反思实现
运行输出:

DeepSeek 反思输出示例
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
# 安装依赖:
# pip install langchain langchain-community langchain-openai python-dotenv
# --- 配置区 ---
# 从 .env 文件加载环境变量(如 DEEPSEEK_API_KEY)
load_dotenv()
# 检查 DeepSeek API 密钥是否存在
if not os.getenv("DEEPSEEK_API_KEY"):
raise ValueError("在 .env 文件中未找到 DEEPSEEK_API_KEY,请添加后重试。")
# 初始化 DeepSeek(OpenAI 兼容 API)
llm = ChatOpenAI(
model="deepseek-reasoner", # 若你想要更快,可换 "deepseek-chat"
temperature=0.1,
openai_api_key=os.getenv("DEEPSEEK_API_KEY"),
openai_api_base=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com/v1"),
)
def run_reflection_loop():
"""
展示如何通过多轮“反思循环”,让大模型逐步优化一段 Python 代码。
"""
# --- 核心任务描述 ---
task_prompt = """
你的任务是编写一个名为 `calculate_factorial` 的 Python 函数,
要求如下:
1. 接收一个整数参数 `n`
2. 计算并返回阶乘 n! 的值
3. 必须包含清晰的 docstring 说明函数用途
4. 能正确处理边界情况:0 的阶乘是 1
5. 若输入为负数,必须抛出 ValueError 异常
"""
# --- 反思循环(Reflection Loop) ---
max_iterations = 3
current_code = ""
message_history = [HumanMessage(content=task_prompt)] # 记录对话上下文
for i in range(max_iterations):
print("\n" + "=" * 25 + f" 反思循环:第 {i + 1} 次迭代 " + "=" * 25)
# --- 1. 生成 / 优化代码阶段 ---
if i == 0:
print("\n>>> 阶段 1:生成初始代码 ……")
response = llm.invoke(message_history)
current_code = response.content
else:
print("\n>>> 阶段 1:根据上一次批注优化代码 ……")
message_history.append(HumanMessage(content="请根据上述代码审查结果进行优化。"))
response = llm.invoke(message_history)
current_code = response.content
print("\n--- 生成的代码(第 " + str(i + 1) + " 版) ---\n" + current_code)
message_history.append(response)
# --- 2. 代码反思阶段(自动代码审查) ---
print("\n>>> 阶段 2:正在审查生成的代码 ……")
reflector_prompt = [
SystemMessage(content="""
你现在是一名高级 Python 开发工程师。
请对下面的代码进行严格的代码审查(Code Review):
- 是否满足原始需求?
- 是否有 bug?
- 是否缺少边界处理?
- 是否需要结构或风格改进?
若代码已经完全满足所有需求,请只回复:
CODE_IS_PERFECT
否则请给出详细的改进建议列表。
"""),
HumanMessage(content=f"原始任务要求:\n{task_prompt}\n\n需要审查的代码:\n{current_code}")
]
critique_response = llm.invoke(reflector_prompt)
critique = critique_response.content
# --- 3. 停止条件:如果代码完美则退出循环 ---
if "CODE_IS_PERFECT" in critique:
print("\n--- 代码审查结果 ---\n代码已经满足所有要求,无需继续优化。")
break
print("\n--- 代码审查结果(Critique) ---\n" + critique)
# 将批注加入下一轮迭代的上下文
message_history.append(HumanMessage(content=f"上一轮代码的批注如下:\n{critique}"))
print("\n" + "=" * 30 + " 最终结果 " + "=" * 30)
print("\n反思循环后的最终版本代码如下:\n")
print(current_code)
if __name__ == "__main__":
run_reflection_loop()
正确运行之后会出现这样的输出:
实战示例:使用 Google ADK
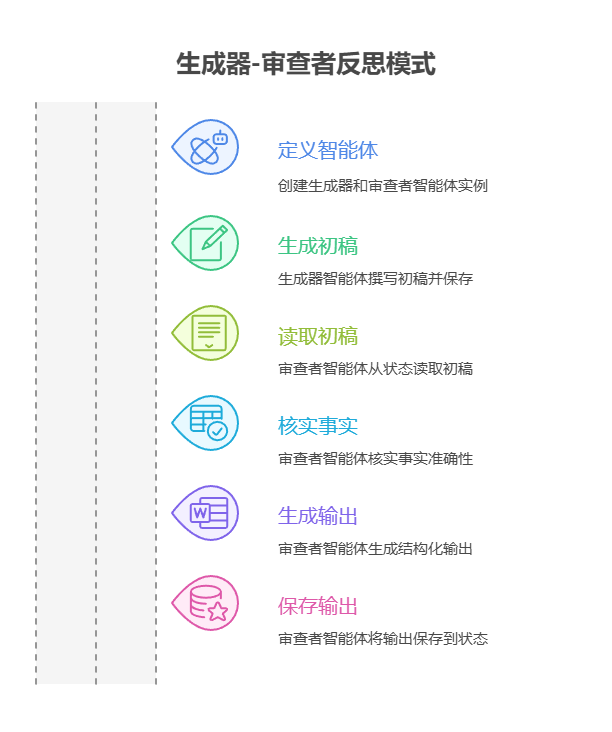
现在我们来看一个使用 Google ADK 实现的示例。具体来说,代码采用「生成器 - 评论者」架构来演示反思模式,其中一个组件(生成器)产生初始结果或方案,另一个组件(评论者)提出反馈建议,帮助生成器不断改进,最终得到更完善、更准确的输出。
定义两个 LlmAgent 实例:generator 和 reviewer。
生成器智能体负责根据指定主题撰写一段简短且信息量高的初稿,并将结果存为状态键 draft_text。
审查者智能体则作为事实核查者,从 draft_text 读取内容并核实事实准确性。审查者的输出是一个结构化字典,包含两个键:status 和 reasoning,其中状态的值包括 ACCURATE 和 INACCURATE,而 reasoning 字段是对状态判断的补充说明,具体的值保存在状态键 review_output。
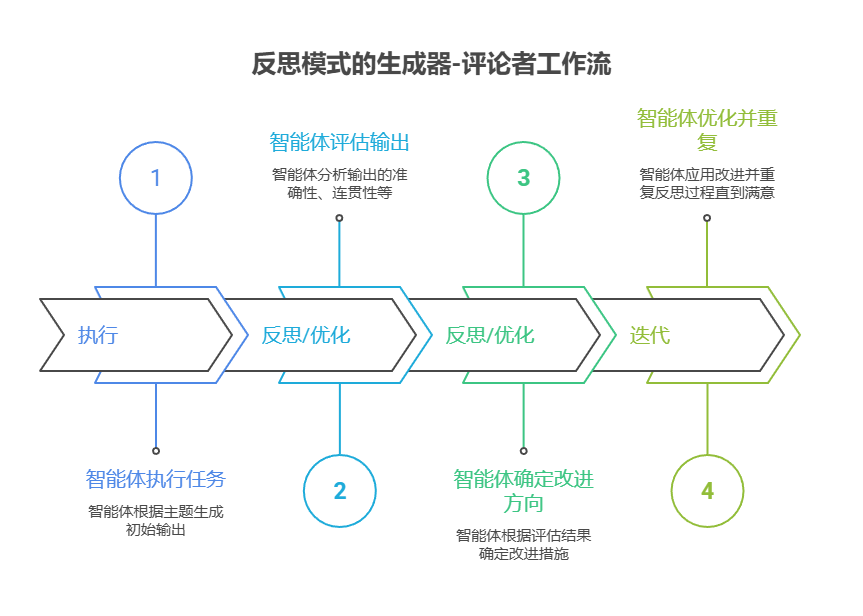
然后通过名为 review_pipeline 的 SequentialAgent 来控制两个智能体的执行顺序,确保先执行生成器智能体,再执行审查者智能体。
from google.adk.agents import SequentialAgent, LlmAgent
# Colab 示例链接:https://colab.research.google.com/drive/1nwE2GH6c08dGlvAv7T28uF1xe2qeu2q_
# 第一个智能体:负责生成主题草稿内容
generator = LlmAgent(
name="DraftWriter",
description="根据用户提供的主题生成一段初始草稿内容。",
instruction="请根据用户给定的主题,写一段简短且信息明确的说明性段落。",
output_key="draft_text" # 生成的草稿内容将保存到此状态键
)
# 第二个智能体:负责审查草稿内容的事实准确性
reviewer = LlmAgent(
name="FactChecker",
description="对生成的文本进行事实核查,并给出结构化评审结果。",
instruction="""
你是一名严谨的事实核查专家。
请执行以下任务:
1. 阅读保存在状态键 'draft_text' 中的文本内容。
2. 对文中的每一项陈述进行事实准确性检查。
3. 最终输出必须是一个包含以下两个键的字典(dictionary):
- "status": 字符串,取值必须是 "ACCURATE"(准确) 或 "INACCURATE"(不准确)。
- "reasoning": 字符串,用清晰、逐条说明的方式解释你的判断理由。
若发现错误,请指出具体段落或句子。
""",
output_key="review_output" # 结构化评审结果保存到此状态键
)
# 使用序列智能体:保证生成器先运行,然后审查器运行
review_pipeline = SequentialAgent(
name="WriteAndReview_Pipeline",
sub_agents=[generator, reviewer]
)
# 执行流程说明(中文):
# 1. generator 运行 → 产生一段草稿 → 保存到 state['draft_text']
# 2. reviewer 运行 → 读取 state['draft_text'] → 输出评审字典到 state['review_output']
整体流程是生成器先生成并保存文本,然后审查者读取状态并执行事实核查,再将核查发现的内容保存回状态。这种管道化的设计便于用独立的智能体完成结构化的内容创作与审查。注意:对于感兴趣的用户,还可使用 ADK 的 LoopAgent 实现类似功能。
在结束前需要注意,虽然反思模式能显著提升输出质量,但也有重要的权衡。其迭代过程虽有效,却可能带来更高的成本和更长的延迟,因为每次改进往往都要发起一次新的模型调用,因此对时间敏感的场景并不适合。另外,该模式占用的内存也会较多,因为随着每轮迭代的进行,会话历史会不断增长,包含最初的输出、评价意见和后续的改进内容。
Qwen ADK 反思示例
from dotenv import load_dotenv
import os
import asyncio
from google.adk.agents import SequentialAgent, LlmAgent
from google.adk.runners import InMemoryRunner
from google.adk.models.lite_llm import LiteLlm
from google.genai import types
# ===========================================
# 1. 读取 .env 并准备环境变量
# ===========================================
load_dotenv()
_dashscope_key = os.getenv("DASHSCOPE_API_KEY")
_qwen_base = os.getenv("QWEN_BASE_URL") # 例如:https://dashscope.aliyuncs.com/compatible-mode/v1
if not _dashscope_key:
raise RuntimeError("未找到 DASHSCOPE_API_KEY,请在 .env 中配置。")
if not _qwen_base:
raise RuntimeError("未找到 QWEN_BASE_URL,请在 .env 中配置。")
# LiteLlm 的 openai 提供方会读取 OPENAI_API_KEY / OPENAI_API_BASE 等环境变量
os.environ["OPENAI_API_KEY"] = _dashscope_key
os.environ["OPENAI_API_BASE"] = _qwen_base
# 有些版本也会读 OPENAI_BASE_URL,顺手一起设一下
os.environ.setdefault("OPENAI_BASE_URL", _qwen_base)
# ===========================================
# 2. 配置 Qwen 模型(通过 OpenAI 兼容端点)
# ===========================================
# 这里的 "openai/..." 表示:使用 LiteLlm 的 openai provider,
# 实际请求会发到我们刚刚设定的 OPENAI_API_BASE(也就是 QWEN_BASE_URL)
_qwen_model = LiteLlm(model="openai/qwen-omni-turbo")
# ===========================================
# 3. 构建 ADK 多智能体
# ===========================================
# 智能体 1:负责生成主题草稿内容
generator = LlmAgent(
model=_qwen_model,
name="DraftWriter",
description="根据用户提供的主题生成一段初始草稿内容。",
instruction="请根据用户给定的主题,写一段简短且信息明确的说明性段落。",
output_key="draft_text"
)
# 智能体 2:负责审查草稿内容的事实准确性
reviewer = LlmAgent(
model=_qwen_model,
name="FactChecker",
description="对生成的文本进行事实核查,并给出结构化评审结果。",
instruction="""
你是一名严谨的事实核查专家。
请执行以下任务:
1. 阅读保存在状态键 'draft_text' 中的文本内容。
2. 对文中的每一项陈述进行事实准确性检查。
3. 最终输出必须是一个包含以下两个键的字典:
- "status": 字符串,取值必须是 "ACCURATE"(准确) 或 "INACCURATE"(不准确)。
- "reasoning": 字符串,用清晰、逐条说明的方式解释你的判断理由。
若发现错误,请指出具体段落或句子。
""",
output_key="review_output"
)
# 顺序执行:先生成草稿,再进行审查
review_pipeline = SequentialAgent(
name="WriteAndReview_Pipeline",
sub_agents=[generator, reviewer]
)
# ===========================================
# 4. Runner 入口
# ===========================================
async def run_pipeline():
runner = InMemoryRunner(
agent=review_pipeline,
app_name="write_and_review_demo"
)
session_service = runner.session_service
user_id = "demo_user"
session_id = "demo_session"
# 创建会话
await session_service.create_session(
app_name="write_and_review_demo",
user_id=user_id,
session_id=session_id,
)
# 用户输入:触发流水线
user_content = types.Content(
role="user",
parts=[types.Part(text="请帮我写一段关于人工智能在教育中的应用的简介。")]
)
print("请帮我写一段关于人工智能在教育中的应用的简介。\n")
print("开始运行流水线...\n")
async for event in runner.run_async(
user_id=user_id,
session_id=session_id,
new_message=user_content,
):
if event.is_final_response() and event.content:
text = event.content.parts[0].text
print("=== 流水线最终输出 ===")
print(text)
print("====================\n")
# 在 Jupyter / VSCode Notebook 里用 await
await run_pipeline()
运行输出:



DeepSeek ADK 反思示例
from dotenv import load_dotenv
import os
from google.adk.agents import SequentialAgent, LlmAgent
from google.adk.runners import InMemoryRunner
from google.adk.models.lite_llm import LiteLlm
from google.genai import types
import asyncio
# 读取 .env
load_dotenv()
# 确保 DeepSeek 的 key 存在
if not os.getenv("DEEPSEEK_API_KEY"):
raise RuntimeError("未找到 DEEPSEEK_API_KEY,请在 .env 中配置。")
# if not os.getenv("DASHSCOPE_API_KEY"):
# raise RuntimeError("未找到 DASHSCOPE_API_KEY,请在 .env 中配置。")
# 用 LiteLLM 封装 DeepSeek 模型
# 可选:deepseek/deepseek-chat 或 deepseek/deepseek-reasoner
_deepseek_model = LiteLlm(model="deepseek/deepseek-reasoner")
_qwen_model = LiteLlm(model="dashscope/qwen-plus") # 或 qwen-max、qwq-32b 等
# 第一个智能体:负责生成主题草稿内容
generator = LlmAgent(
model=_deepseek_model,
# model=_qwen_model,
name="DraftWriter",
description="根据用户提供的主题生成一段初始草稿内容。",
instruction="请根据用户给定的主题,写一段简短且信息明确的说明性段落。",
output_key="draft_text"
)
# 第二个智能体:负责审查草稿内容的事实准确性
reviewer = LlmAgent(
model=_deepseek_model,
# model=_qwen_model,
name="FactChecker",
description="对生成的文本进行事实核查,并给出结构化评审结果。",
instruction="""
你是一名严谨的事实核查专家。
请执行以下任务:
1. 阅读保存在状态键 'draft_text' 中的文本内容。
2. 对文中的每一项陈述进行事实准确性检查。
3. 最终输出必须是一个包含以下两个键的字典:
- "status": 字符串,取值必须是 "ACCURATE"(准确) 或 "INACCURATE"(不准确)。
- "reasoning": 字符串,用清晰、逐条说明的方式解释你的判断理由。
若发现错误,请指出具体段落或句子。
""",
output_key="review_output"
)
# 这里不需要再写 model,子 Agent 已经各自有 model 对象了
review_pipeline = SequentialAgent(
name="WriteAndReview_Pipeline",
sub_agents=[generator, reviewer]
)
async def run_pipeline():
_runner = InMemoryRunner(
agent=review_pipeline,
app_name="write_and_review_demo"
)
_session_service = _runner.session_service
_user_id = "demo_user"
_session_id = "demo_session"
# 创建会话
await _session_service.create_session(
app_name="write_and_review_demo",
user_id=_user_id,
session_id=_session_id,
)
# 发送一条用户消息,触发流水线
_user_content = types.Content(
role="user",
parts=[types.Part(text="请帮我写一段关于人工智能在教育中的应用的简介。")]
)
print("请帮我写一段关于人工智能在教育中的应用的简介。\n\n")
print("开始运行流水线...\n")
async for _event in _runner.run_async(
user_id=_user_id,
session_id=_session_id,
new_message=_user_content,
):
# 这里只简化展示最终回复
if _event.is_final_response() and _event.content:
_text = _event.content.parts[0].text
print("=== 流水线最终输出 ===")
print(_text)
print("====================\n")
# 在 Jupyter / VSCode Notebook 里用 await,而不是 asyncio.run(...)
await run_pipeline()
运行输出:

要点速览
问题所在:智能体的初始输出通常不够理想,存在不准确、不完整或未能满足复杂要求的问题。基本智能体工作流缺乏内置过程让智能体识别和修复自己的错误。为了解决这一点,可以让智能体先自我评估,或通过引入独立的智能体来审查和指出问题,确保初始回答不会直接作为最终结果。
解决之道:反思模式通过引入自我纠错和改进机制来解决问题。它建立反馈循环,其中「生产者」智能体生成输出,然后「评论者」智能体(或生产者本身)根据预定义标准评估输出。相关的反馈建议随后用于生成改进版本。这种生成、评估和优化的迭代过程逐步提高最终结果的质量,产生更准确、连贯和可靠的结果。
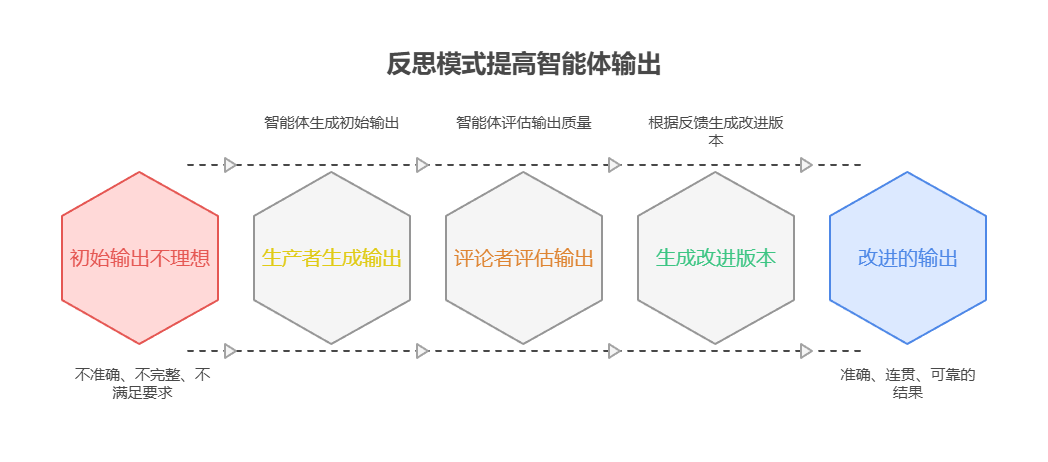
经验法则:当最终输出的质量、准确性和细节比速度和成本更重要时应考虑使用反思模式。它对于生成高质量的长篇内容、编写和调试代码、创建详细计划等任务非常有效。当任务需要更高的客观性或涉及专业评估(常规生产者可能会遗漏),建议采用独立的评论者智能体以提高输出质量。
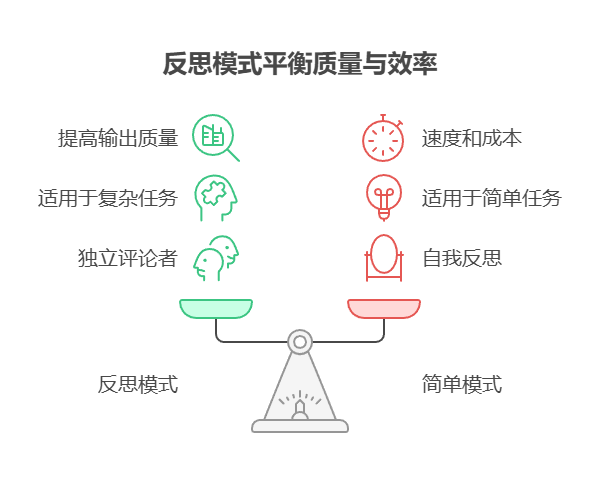
可视化总结
1. 反思设计模式之自我反思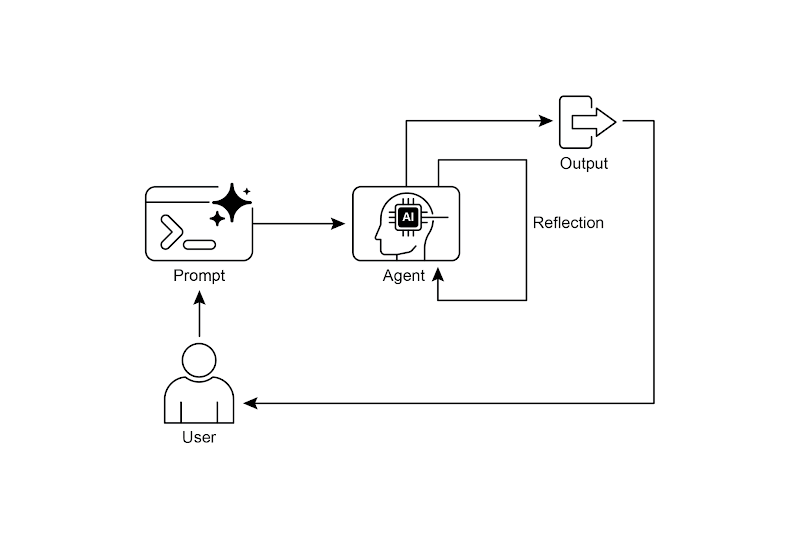
2. 反思设计模式之生产者和评论者智能体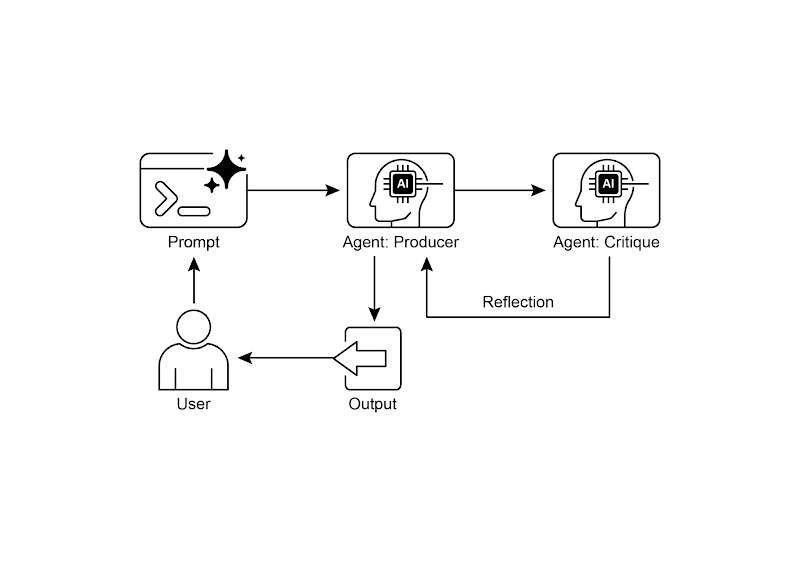
核心要点
- 反思模式的主要优势在于它可以通过反复自我修正和改进输出,显著提高质量、准确性和遵循更复杂的指令。
- 它包括执行、评估/评价和改进的反馈循环。对于需要高质量、准确性或细腻表述的任务,反思是不可或缺的。 一个有效的方法是采用「生产者 -
- 评论者」模型,由一个独立的智能体(或基于提示的不同角色)来评估初始输出。通过职责分离可以提高评判的客观性,并提供更专业、更有条理的反馈。
- 然而,这些好处以增加延迟和成本为代价,同时还有超出模型上下文窗口或被 API 服务限流的风险。
- 虽然完整的迭代反思通常依赖有状态的工作流(例如 LangGraph),但在 LangChain 中也可以用 LCEL
- 实现一次性的反思步骤,将生成的输出传给评论者以进行评审并据此改进。 Google ADK
- 可以通过一系列串联的工作流程来促进反思:一个智能体生成输出,另一个智能体对其进行评审,并据此进行后续改进。
- 该模式使智能体能够自我修正,并随着时间不断提高表现。
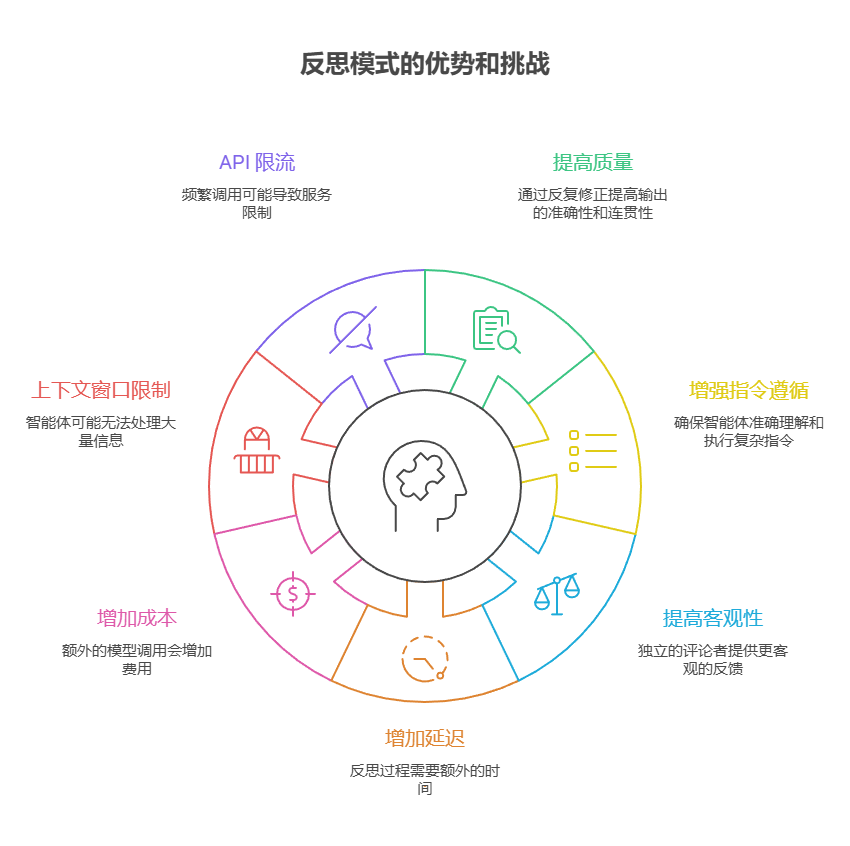
结语
反思模式为智能体的工作流程提供了自我修正的关键手段,使其能通过多次迭代而不是一次性完成任务来持续改进。具体做法是形成一个循环:系统先生成初稿,然后按照既定标准对其进行评估,最后根据评估结果生成更完善的输出。这种评估既可以由智能体自己完成(自我反思),也可以由一个专门的评论者智能体来执行。通常后一种方式更有效,也是该模式的一个重要架构决策。
虽然要实现完全自主的多步骤反思需要可靠的状态管理架构,但其核心思想可以通过「生成—评审—改进」的循环清晰地呈现。作为一种控制结构,反思可以与其他基础模式结合使用,从而构建更稳健、功能更强大的智能体系统。
参考文献
以下是有关反思模式和相关概念的进一步阅读资源:
暂时先这样吧,如果实在看不明白就留言,看到我会回复的。希望这个教程对您有帮助!
路漫漫其修远,与君共勉。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)