大模型从0到精通:千人绘一图 —— 如何将千亿参数的巨兽拆解到上万张显卡上训练
大模型训练面临单卡显存不足的核心矛盾,分布式并行技术成为关键解决方案。数据并行通过复制模型、分发数据实现计算加速,但不减少单卡内存;模型并行拆分模型层到多卡,但存在流水线瓶颈。实践中采用混合并行(数据+模型+张量并行)结合ZeRO优化器的分片策略,显著降低显存需求。实际案例显示,通过合理配置并行策略,30亿参数模型可在32张GPU上高效训练,吞吐量提升26倍。分布式训练仍需解决通信开销、容错性等挑
GPT-4有上万亿参数,一个参数占4字节,仅加载模型就需要数千GB显存,远超任何单张显卡。这个"不可拆"的庞然大物,是如何被训练出来的?
本文是《从零到精通大模型》系列第14章,深入解析分布式并行训练技术:数据并行、模型并行、混合并行及ZeRO优化器,如何让训练千亿参数大模型成为可能。
一、我们的"显存噩梦"
2021年,公司决定自研一个10亿参数的中文预训练模型。
当时我们最好的显卡是NVIDIA A100(40GB显存)。
第一次尝试:单卡训练
我们加载模型:
- 模型参数:10亿 × 4字节 = 4GB
- 优化器状态(Adam):4GB × 3 = 12GB(m、v、参数)
- 激活值:约8GB
- 梯度:4GB
总计:4 + 12 + 8 + 4 = 28GB
好消息:刚好能放进40GB显存!
第二次尝试:增大批次大小
为了提高训练效率,我们想增大批次大小(batch size):
- 批次大小从32增加到64
- 激活值从8GB增加到16GB
总计:4 + 12 + 16 + 4 = 36GB
仍然OK:还有4GB余量。
第三次尝试:100亿参数模型
2022年,老板说:“我们要做100亿参数模型!”
我们计算:
- 模型参数:100亿 × 4字节 = 40GB
- 优化器状态:40GB × 3 = 120GB
- 激活值:约20GB
- 梯度:40GB
总计:40 + 120 + 20 + 40 = 220GB
问题:单张A100只有40GB,差180GB!
这就是大模型训练的根本矛盾:
- 模型越来越大(千亿、万亿参数)
- 单卡显存有限(几十GB)
- 如何训练?
答案:分布式并行训练。
二、并行训练的基本思想
核心洞察
如果一个东西太大,拆开它。
三种拆法
- 数据并行:复制模型,分发数据
- 模型并行:拆解模型,分发层
- 混合并行:两者结合,再加其他技巧

三、数据并行:复制模型,分发数据

原理
- 把模型完整复制到多张显卡上
- 每张卡用不同的数据批次训练
- 定期同步梯度,更新所有副本
生动比喻:百人临摹名画
任务:临摹《蒙娜丽莎》
数据并行做法:
- 雇100个画师(100张GPU)
- 每人发一份《蒙娜丽莎》复制品(复制模型)
- 把画分成100个区域(数据分片)
- 每人专注临摹自己的区域(本地训练)
- 每天结束时,大家开会交流心得(梯度同步)
- 统一调整绘画方法(模型更新)
- 每人更新自己的复制品(模型同步)
技术细节
前向传播
每张卡:
- 读取自己的数据批次
- 前向计算,得到loss
反向传播
每张卡:
- 计算本地梯度
- 等待所有卡完成
梯度同步
关键步骤:All-Reduce
- 所有卡把梯度发送到中心
- 计算平均梯度
- 把平均梯度广播给所有卡
参数更新
每张卡:
- 用平均梯度更新参数
- 现在所有卡有相同的模型
我们的实践:8卡数据并行
训练100亿参数模型:
- 单卡需求:220GB → 不可能
- 8卡数据并行:每卡220GB/8?不对!
误区:数据并行不减少单卡内存!
- 每卡仍有完整模型(40GB)
- 每卡仍有完整优化器状态(120GB)
- 只是数据批次变小了
实际:数据并行解决的是计算并行,不是内存问题。
数据并行的局限性
- 不减少单卡内存:模型必须能放进单卡
- 通信开销:梯度同步需要时间
- 扩展性有限:批次大小不能无限小
四、模型并行:拆解模型,分发层
原理
- 将模型按层拆分到不同显卡上
- 数据像流水线一样流过各卡
- 每张卡只存储部分模型
生动比喻:流水线壁画创作
任务:绘制超长壁画(100米长)
模型并行做法:
- 把壁画分成10段,每段10米
- 雇10个画师,每人负责一段
- 搭建脚手架,画师站成一排
- 画师A画第一段,传给B
- B画第二段,同时A开始画下一幅的第一段
- 如此流水线作业
技术细节
垂直切分(按层)
- 第1-5层在GPU 0
- 第6-10层在GPU 1
- 第11-15层在GPU 2
- …
前向传播流水线
- GPU 0:计算第1-5层,结果传给GPU 1
- GPU 1:计算第6-10层,结果传给GPU 2
- GPU 2:计算第11-15层,得到最终输出
反向传播流水线
反向进行,梯度从后往前传。
我们的实践:4卡模型并行
训练100亿参数模型:
- 模型分成4部分,每部分25亿参数
- 每卡存储:25亿×4字节=10GB参数
- 加上优化器状态:10GB×3=30GB
- 加上激活值、梯度:约15GB
- 每卡总计:10+30+15=55GB
问题:A100只有40GB,还是不够!
模型并行的挑战
- 流水线气泡:等待时间,利用率不高
- 通信频繁:层间需要传递激活值和梯度
- 负载不均衡:不同层计算量可能不同
五、混合并行:现实的交响乐
现实中的大模型训练,同时使用多种并行策略。
常见组合
- 数据并行 + 模型并行
- 数据并行 + 张量并行
- 数据并行 + 流水线并行 + 张量并行
张量并行:更细粒度的拆分
原理
将单层的矩阵运算拆到多卡。
例如:线性层 Y = XW + b
- W矩阵很大(8192×8192)
- 按列拆分:W = [W1, W2],分到2张卡
- 每卡计算部分结果,再合并
生动比喻:多人调色板
任务:调制复杂颜色(需要很多颜料)
张量并行做法:
- 调色板太大,一人拿不动
- 分成4个小调色板
- 4人各拿一个,分别调制
- 最后合并成完整颜色
我们的最终方案:混合并行训练100亿模型
经过多次尝试,最终方案:
硬件
- 8张A100(40GB)
- NVLink高速互联
并行策略
-
张量并行(TP=2):
- 将大矩阵运算拆到2张卡
- 减少单卡内存
-
流水线并行(PP=2):
- 模型分成2个阶段
- 减少激活值内存
-
数据并行(DP=2):
- 2个复制品同时训练
- 提高数据吞吐量
内存计算
- 总GPU数:TP×PP×DP = 2×2×2 = 8卡
- 每卡模型参数:100亿 / (TP×PP) = 25亿参数 = 10GB
- 每卡优化器状态:10GB×3 = 30GB
- 激活值:流水线并行减少,约8GB
- 梯度:约5GB
- 每卡总计:10+30+8+5 = 53GB
还是超了!A100只有40GB。
解决方案:ZeRO优化器
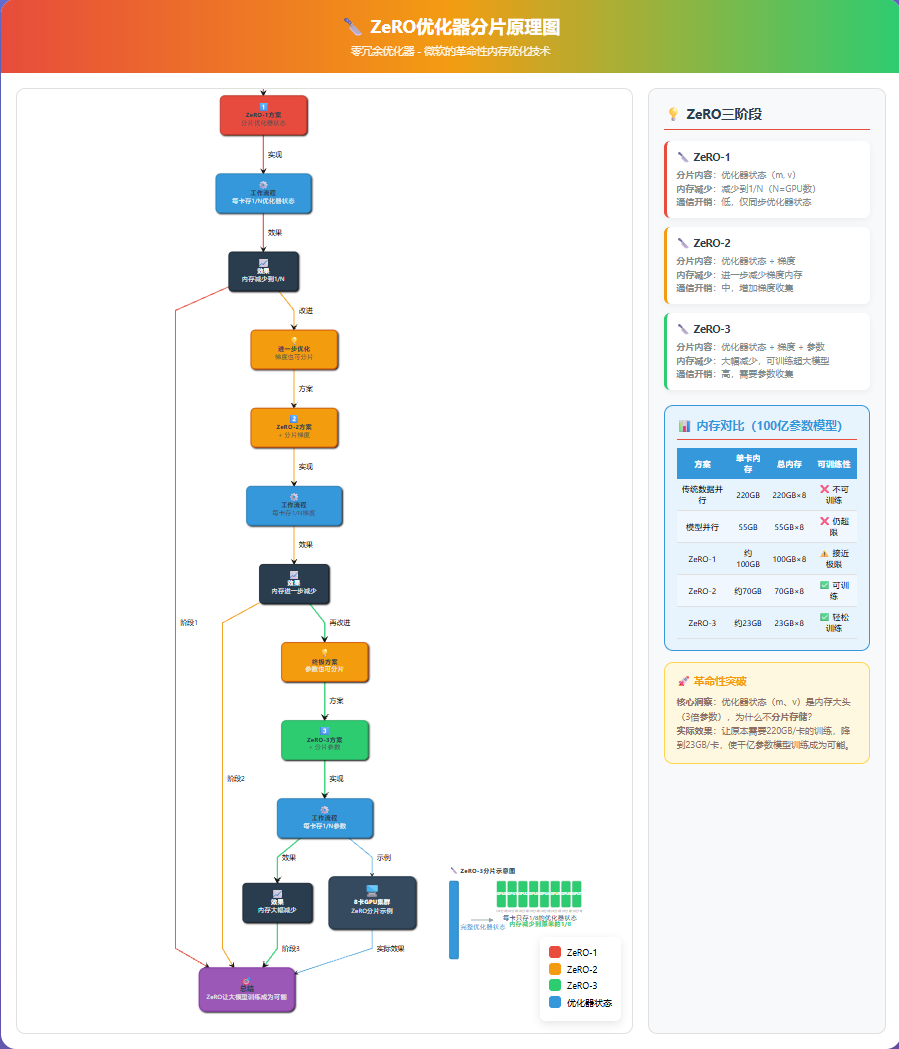
微软提出的ZeRO(Zero Redundancy Optimizer) 解决了这个问题。
ZeRO的核心思想
优化器状态(m、v)是内存大头(3倍参数)。
为什么不分片存储?
ZeRO的三个阶段
ZeRO-1:分片优化器状态
- 每卡只存1/N的优化器状态
- 内存减少到1/N
ZeRO-2:分片优化器状态+梯度
- 每卡只存1/N的梯度
- 内存再减少
ZeRO-3:分片优化器状态+梯度+参数
- 每卡只存1/N的参数
- 内存大幅减少
ZeRO-Offload
甚至可以把部分状态offload到CPU内存,进一步节省GPU显存。
最终成功方案:ZeRO-3 + 混合并行
使用ZeRO-3后:
- 每卡模型参数:100亿 / 8 = 12.5亿参数 = 5GB
- 每卡优化器状态:5GB(分片后)
- 激活值:8GB
- 梯度:5GB(分片后)
- 每卡总计:5+5+8+5 = 23GB
成功!23GB < 40GB,可以训练了。
六、实际项目:训练30亿参数模型
2023年,我们主导了一个30亿参数模型的训练。
硬件配置
- 32张A100(40GB)
- 8台服务器,每台4卡
- InfiniBand高速网络
并行配置
Tensor Parallelism: 4 # 张量并行,4卡一组
Pipeline Parallelism: 2 # 流水线并行,2阶段
Data Parallelism: 4 # 数据并行,4个复制品
总GPU数: 4×2×4 = 32卡
训练过程
第1阶段:小规模测试(4卡)
- 测试代码正确性
- 调试通信问题
- 测量单步时间
第2阶段:中规模测试(16卡)
- 测试扩展性
- 优化通信模式
- 调整超参数
第3阶段:全规模训练(32卡)
- 7×24小时训练
- 监控系统状态
- 定期保存检查点
性能数据
| 指标 | 单卡 | 32卡 | 加速比 |
|---|---|---|---|
| 每步时间 | 3200ms | 120ms | 26.7倍 |
| 吞吐量 | 100样本/秒 | 2667样本/秒 | 26.7倍 |
| 内存使用 | OOM(溢出) | 28GB/卡 | - |
关键:不仅实现了并行加速,还让原本不可能的训练成为可能。
七、分布式训练的挑战
1. 通信开销
- 梯度同步:All-Reduce
- 参数同步:Broadcast
- 激活值传递:点对点
优化:重叠计算与通信
2. 容错性
- 32张卡,训练1个月
- 任何一张卡故障,整个训练失败
- 检查点机制:定期保存,故障后恢复
3. 负载均衡
- 不同层计算量不同
- 不同卡性能可能有差异
- 需要动态调度
4. 数值一致性
- 不同卡计算顺序可能不同
- 浮点误差累积
- 需要确保所有卡结果一致
八、前沿技术
1. 3D并行
- 张量并行 + 流水线并行 + 数据并行
- 目前最主流的方案
2. 专家混合(MoE)
- 只有部分参数激活
- 大幅减少计算和内存
- 但增加通信复杂度
3. 异步训练
- 不同卡不同步更新
- 提高利用率
- 但可能影响收敛
4. 联邦学习
- 数据不离开本地
- 只同步模型更新
- 隐私保护
九、从工程到艺术
分布式训练不仅是技术,更是艺术。
艺术1:权衡的艺术
- 并行度 vs 通信开销
- 内存 vs 计算
- 速度 vs 稳定性
艺术2:调优的艺术
- 找到最优的并行配置
- 调整批次大小、学习率
- 平衡各种开销
艺术3:故障处理的艺术
- 预测性维护
- 快速恢复
- 损失最小化
十、成本考量
训练GPT-3(1750亿参数)的成本
- GPU数量:约10,000张A100
- 训练时间:约3个月
- 电费:约数百万美元
- 总成本:约1200万美元
为什么还要训练?
因为大模型的规模定律:
- 模型越大,能力越强
- 能力增强带来商业价值
- 价值远超训练成本
十一、关键要点总结
-
根本矛盾:模型太大,单卡太小。
-
三大并行策略:
- 数据并行:复制模型,分发数据(不解决内存)
- 模型并行:拆解模型,分发层(解决内存)
- 混合并行:现实方案,组合使用
-
ZeRO革命:分片优化器状态,大幅减少内存。
-
实际训练:3D并行(TP+PP+DP)是主流。
-
工程挑战:通信、容错、负载均衡、数值一致性。
-
成本巨大:但规模定律证明其价值。
-
不仅是技术:更是权衡、调优、故障处理的艺术。
十二、第四卷总结
第4卷"工程篇"我们学习了如何锻造千亿参数的"巨兽":
- 过拟合与正则化:防止模型死记硬背
- 优化器进化史:从蒙眼走路到智能越野
- 分布式并行训练:拆解不可拆的巨兽
通过这些工程技术,我们解决了大模型训练的核心挑战:
- 如何学得好(正则化)
- 如何学得快(优化器)
- 如何学得了(分布式训练)
十三、下一步预告
有了强大的工程基础,下一步是让大模型真正有用。
第5卷"前沿篇",我们将探索大模型的最新应用:
- 思维链:让模型"把心算步骤念出来"
- 智能体:让模型从"先知"变成"全能助理"
- RLHF:人类如何教会AI"好"与"坏"
你会发现,技术的最终目标是创造价值,而大模型正在重塑我们与AI的交互方式。
思考题:你能想到生活中哪些需要"分布式协作"的例子?比如,一个大型项目如何拆解给多人同时进行?有什么挑战和技巧?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)